python大数据挖掘和分析的套路
大数据的4V特点:
Volume(大量):数据巨大。
Velocity(高速):数据产生快,每一天每一秒全球人产生的数据足够庞大且数据处理也逐渐变快。
Variety(多样):数据格式多样化,如音频数据、文本数据等
Value(价值):通过收集大量数据不相关数据探查并证明其两者之间的关联性,所产生的价值,如买啤酒的人通常会购买尿布的案例。
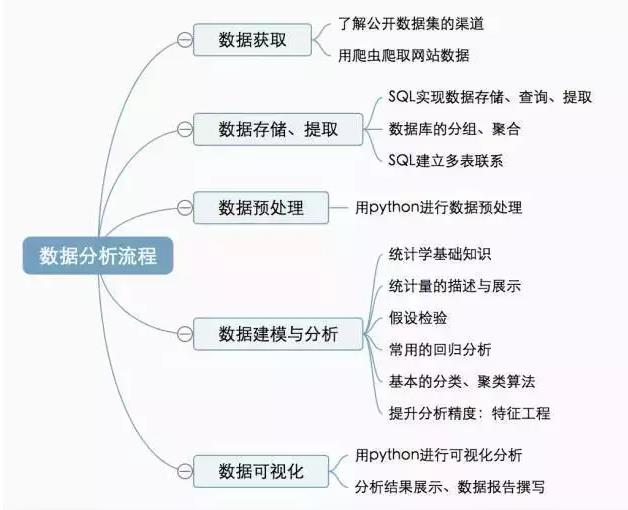
数据分析流程
一般可以按“数据获取-数据存储与提取-数据预处理-数据建模与分析-数据可视化”这样的步骤来实施一个数据分析项目。按照这个流程,每个部分需要掌握的细分知识点如下:
我们可以通过以下的工具包,来实现整个数据分析的流程:numpy(科学计算/矩阵)、Pandas(数据处理/分析)、Matplotlib(数据图表)、seaborn(数据可视化)等。
数据分析中80%的时间都是在数据清理部分,loading, clearning, transforming, rearranging。而pandas非常适合用来执行这些任务。
数据分析的模块有哪些:
- numpy 高效处理数据,提供数组支持,很多模块都依赖它,比如pandas,scipy,matplotlib都依赖他,所以这个模块都是基础。所以必须先安装numpy。
- pandas 主要用于进行数据的采集与分析
- scipy 主要进行数值计算。同时支持矩阵运算,并提供了很多高等数据处理功能,比如积分,微分方程求样等。
- matplotlib 作图模块,结合其他数据分析模块,解决可视化问题
- statsmodels 这个模块主要用于统计分析
- Gensim 这个模块主要用于文本挖掘
- sklearn,keras 前者机器学习,后者深度学习。
数据获取:公开数据、Python爬虫
外部数据的获取方式主要有以下两种。
第一种是获取外部的公开数据集,一些科研机构、企业、政府会开放一些数据,你需要到特定的网站去下载这些数据。这些数据集通常比较完善、质量相对较高。
另一种获取外部数据的方式就是爬虫。
比如你可以通过爬虫获取招聘网站某一职位的招聘信息,爬取租房网站上某城市的租房信息,爬取豆瓣评分评分最高的电影列表,获取知乎点赞排行、网易云音乐评论排行列表。基于互联网爬取的数据,你可以对某个行业、某种人群进行分析。
在爬虫之前你需要先了解一些 Python 的基础知识:元素(列表、字典、元组等)、变量、循环、函数………
以及,如何用 Python 库(urllib、BeautifulSoup、requests、scrapy)实现网页爬虫。
掌握基础的爬虫之后,你还需要一些高级技巧,比如正则表达式、使用cookie信息、模拟用户登录、抓包分析、搭建代理池等等,来应对不同网站的反爬虫限制。
数据存取:SQL语言
在应对万以内的数据的时候,Excel对于一般的分析没有问题,一旦数据量大,就会力不从心,数据库就能够很好地解决这个问题。而且大多数的企业,都会以SQL的形式来存储数据。
SQL作为最经典的数据库工具,为海量数据的存储与管理提供可能,并且使数据的提取的效率大大提升。你需要掌握以下技能:
提取特定情况下的数据
数据库的增、删、查、改
数据的分组聚合、如何建立多个表之间的联系
数据预处理:Python(pandas)
很多时候我们拿到的数据是不干净的,数据的重复、缺失、异常值等等,这时候就需要进行数据的清洗,把这些影响分析的数据处理好,才能获得更加精确地分析结果。
对于数据预处理,学会 pandas (Python包)的用法,应对一般的数据清洗就完全没问题了。需要掌握的知识点如下:
选择:数据访问
缺失值处理:对缺失数据行进行删除或填充
重复值处理:重复值的判断与删除
异常值处理:清除不必要的空格和极端、异常数据
相关操作:描述性统计、Apply、直方图等
合并:符合各种逻辑关系的合并操作
分组:数据划分、分别执行函数、数据重组
Reshaping:快速生成数据透视表
概率论及统计学知识
需要掌握的知识点如下:
基本统计量:均值、中位数、众数、百分位数、极值等
其他描述性统计量:偏度、方差、标准差、显着性等
其他统计知识:总体和样本、参数和统计量、ErrorBar
概率分布与假设检验:各种分布、假设检验流程
其他概率论知识:条件概率、贝叶斯等
有了统计学的基本知识,你就可以用这些统计量做基本的分析了。你可以使用 Seaborn、matplotlib 等(python包)做一些可视化的分析,通过各种可视化统计图,并得出具有指导意义的结果。
Python 数据分析
掌握回归分析的方法,通过线性回归和逻辑回归,其实你就可以对大多数的数据进行回归分析,并得出相对精确地结论。这部分需要掌握的知识点如下:
回归分析:线性回归、逻辑回归
基本的分类算法:决策树、随机森林……
基本的聚类算法:k-means……
特征工程基础:如何用特征选择优化模型
调参方法:如何调节参数优化模型
Python 数据分析包:scipy、numpy、scikit-learn等
在数据分析的这个阶段,重点了解回归分析的方法,大多数的问题可以得以解决,利用描述性的统计分析和回归分析,你完全可以得到一个不错的分析结论。
当然,随着你实践量的增多,可能会遇到一些复杂的问题,你就可能需要去了解一些更高级的算法:分类、聚类。
然后你会知道面对不同类型的问题的时候更适合用哪种算法模型,对于模型的优化,你需要去了解如何通过特征提取、参数调节来提升预测的精度。
你可以通过 Python 中的 scikit-learn 库来实现数据分析、数据挖掘建模和分析的全过程。
python大数据挖掘和分析的套路的更多相关文章
- 2 python大数据挖掘系列之淘宝商城数据预处理实战
preface 在上一章节我们聊了python大数据分析的基本模块,下面就说说2个项目吧,第一个是进行淘宝商品数据的挖掘,第二个是进行文本相似度匹配.好了,废话不多说,赶紧上车. 淘宝商品数据挖掘 数 ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- python大数据挖掘系列之淘宝商城数据预处理实战
数据清洗: 所谓的数据清洗,就是把一些异常的.缺失的数据处理掉,处理掉不一定是说删除,而是说通过某些方法将这个值补充上去,数据清洗目的在于为了让我们数据的可靠,因为脏数据会对数据分析产生影响.拿到数据 ...
- Hadoop大数据挖掘从入门到进阶实战
1.概述 大数据时代,数据的存储与挖掘至关重要.企业在追求高可用性.高扩展性及高容错性的大数据处理平台的同时还希望能够降低成本,而Hadoop为实现这些需求提供了解决方案.面对Hadoop的普及和学习 ...
- 《零起点,python大数据与量化交易》
<零起点,python大数据与量化交易>,这应该是国内第一部,关于python量化交易的书籍. 有出版社约稿,写本量化交易与大数据的书籍,因为好几年没写书了,再加上近期"前海智库 ...
- Python、R对比分析
一.Python与R功能对比分析 1.python与R相比速度要快.python可以直接处理上G的数据:R不行,R分析数据时需要先通过数据库把大数据转化为小数据(通过groupby)才能交给R做分析, ...
- 顶尖大数据挖掘实战平台(TipDM-H8)产品白皮书
顶尖大数据挖掘实战平台 (TipDM-H8) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: http: ...
- 常用排序算法的python实现和性能分析
常用排序算法的python实现和性能分析 一年一度的换工作高峰又到了,HR大概每天都塞几份简历过来,基本上一天安排两个面试的话,当天就只能加班干活了.趁着面试别人的机会,自己也把一些基础算法和一些面试 ...
随机推荐
- MongoDB 4.2 新特性解读 (转载)
MongoDB World 2019 上发布新版本 MongoDB 4.2 Beta,包含多项数据库新特性,本文尝试从技术角度解读. Full Text Search MongoDB 4.2 之前,全 ...
- WinDbg常用命令系列---显示加载的模块列表lm
lm (List Loaded Modules) lm命令显示指定的加载模块.输出包括模块的状态和路径. lmOptions [a Address] [m Pattern | M Pattern] 参 ...
- 14-ESP8266 SDK开发基础入门篇--上位机串口控制 Wi-Fi输出PWM的占空比,调节LED亮度,8266程序编写
https://www.cnblogs.com/yangfengwu/p/11102026.html 首先规定下协议 ,CRC16就不加了哈,最后我会附上CRC16的计算程序,大家有兴趣自己加上 上 ...
- 洛谷 SP740 TRT - Treats for the Cows 题解
SP740 TRT - Treats for the Cows 题目描述 FJ has purchased N (1 <= N <= 2000) yummy treats for the ...
- 2019qbxt游记
Day 1 2019.8.6 来到qbxt的第一天,虽然早就对宾馆的等级做好了准备,但是还是十分的失望,外观是真的很简陋,不过里面还好的,,可以凑合. 我竟然和lbh一个宿舍!!!这次外出学习必将不安 ...
- 通过phoenix导入数据到hbase出错记录
解决方法1 错误如下 -- ::, [hconnection-0x7b9e01aa-shared--pool11069-t114734] WARN org.apache.hadoop.hbase.ip ...
- 关于证书如何完成身份验证(SSL证书)
一.写在前面 SSL和IPsec是现在VPN技术中最为常见的,在云计算的应用环境中,SSL更受企业青睐,至于原因的话简单的说就是SSL更为简洁,不需要像IPsec那样需要额外安装客户端,这会带来软件维 ...
- Dolly
dolly - 必应词典 美['dɑli]英['dɒli] n.洋娃娃:(搬运重物的)台车 v.用独轮车运(物):用搅拌棒洗(衣):用捣棒捣碎(矿石) 网络多莉:多利:移动式摄影小车 变形复数:dol ...
- MySQL日常监控及sys库的使用【转】
一.统计信息(SQL维度) 关于SQL维度的统计信息主要集中在events_statements_summary_by_digest表中,通过将SQL语句抽象出digest,可以统计某类SQL语句在各 ...
- SQLServer 截取函数 substring函数
declare @name char(1000) --注意:char(10)为10位,要是位数小了会让数据出错 set @name='s{sss}fc{fggh}dghdf{cccs}x' selec ...