Self-Supervised Representation Learning
Self-Supervised Representation Learning
2019-11-11 21:12:14
This blog is copied from: https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
Self-Supervised Representation Learning
Nov 10, 2019 by Lilian Weng representation-learning long-read generative-model object-recognition
Self-supervised learning opens up a huge opportunity for better utilizing unlabelled data, while learning in a supervised learning manner. This post covers many interesting ideas of self-supervised learning tasks on images, videos, and control problems.
Given a task and enough labels, supervised learning can solve it really well. Good performance usually requires a decent amount of labels, but collecting manual labels is expensive (i.e. ImageNet) and hard to be scaled up. Considering the amount of unlabelled data (e.g. free text, all the images on the Internet) is substantially more than a limited number of human curated labelled datasets, it is kinda wasteful not to use them. However, unsupervised learning is not easy and usually works much less efficiently than supervised learning.
What if we can get labels for free for unlabelled data and train unsupervised dataset in a supervised manner? We can achieve this by framing a supervised learning task in a special form to predict only a subset of information using the rest. In this way, all the information needed, both inputs and labels, has been provided. This is known as self-supervised learning.
This idea has been widely used in language modeling. The default task for a language model is to predict the next word given the past sequence. BERT adds two other auxiliary tasks and both rely on self-generated labels.
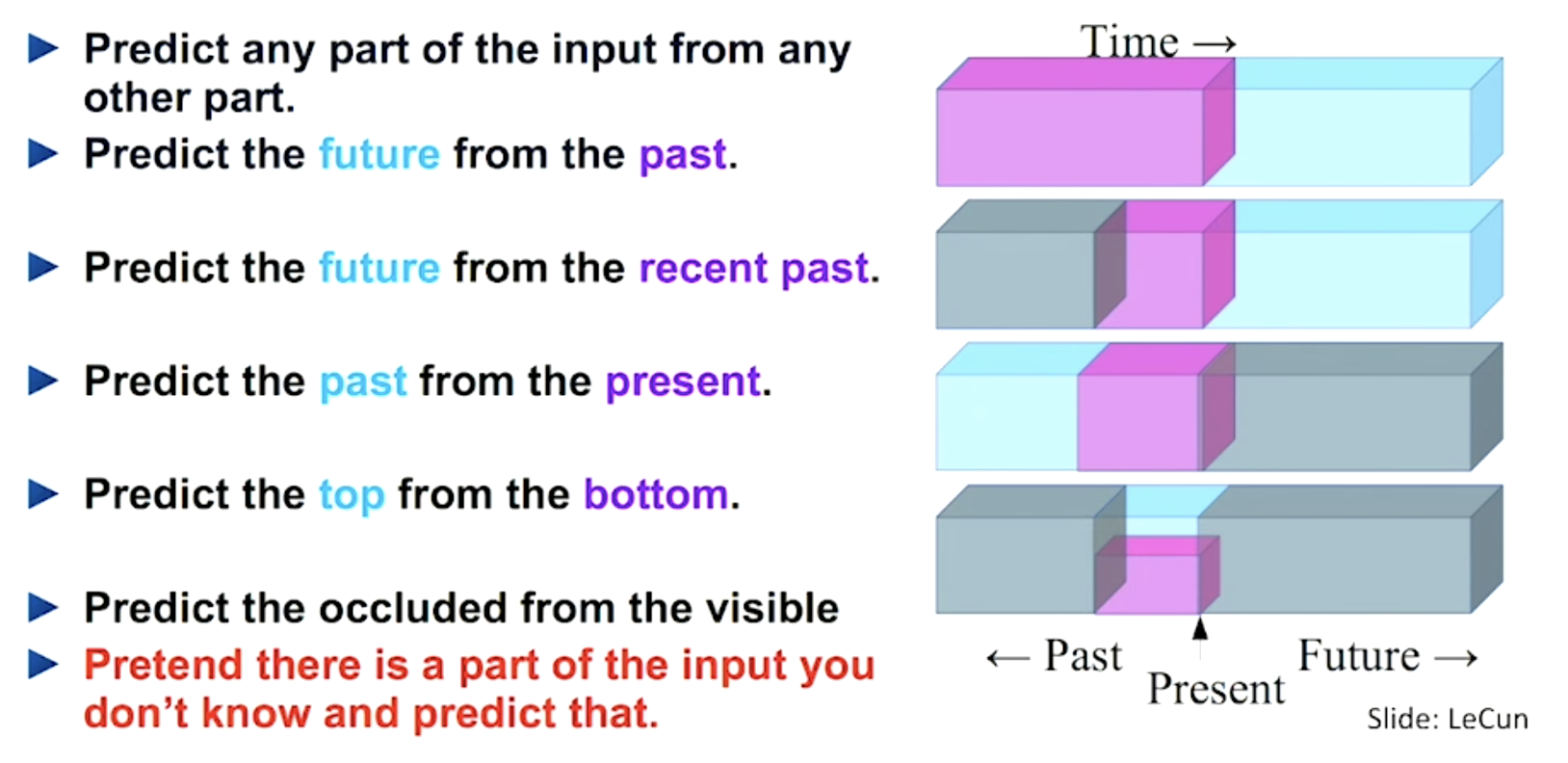
Fig. 1. A great summary of how self-supervised learning tasks can be constructed (Image source: LeCun’s talk)
Here is a nicely curated list of papers in self-supervised learning. Please check it out if you are interested in reading more in depth.
Why Self-Supervised Learning?
Self-supervised learning empowers us to exploit a variety of labels that come with the data for free. The motivation is quite straightforward. Producing a dataset with clean labels is expensive but unlabeled data is being generated all the time. To make use of this much larger amount of unlabeled data, one way is to set the learning objectives properly so as to get supervision from the data itself.
The self-supervised task, also known as pretext task, guides us to a supervised loss function. However, we usually don’t care about the final performance of this invented task. Rather we are interested in the learned intermediate representation with the expectation that this representation can carry good semantic or structural meanings and can be beneficial to a variety of practical downstream tasks.
For example, we might rotate images at random and train a model to predict how each input image is rotated. The rotation prediction task is made-up, so the actual accuracy is unimportant, like how we treat auxiliary tasks. But we expect the model to learn high-quality latent variables for real-world tasks, such as constructing an object recognition classifier with very few labeled samples.
Broadly speaking, all the generative models can be considered as self-supervised, but with different goals: Generative models focus on creating diverse and realistic images, while self-supervised representation learning care about producing good features generally helpful for many tasks. Generative modeling is not the focus of this post, but feel free to check my previous posts.
Images-Based
Many ideas have been proposed for self-supervised representation learning on images. A common workflow is to train a model on one or multiple pretext tasks with unlabelled images and then use one intermediate feature layer of this model to feed a multinomial logistic regression classifier on ImageNet classification. The final classification accuracy quantifies how good the learned representation is.
Recently, some researchers proposed to train supervised learning on labelled data and self-supervised pretext tasks on unlabelled data simultaneously with shared weights, like in Zhai et al, 2019 and Sun et al, 2019.
Distortion
We expect small distortion on an image does not modify its original semantic meaning or geometric forms. Slightly distorted images are considered the same as original and thus the learned features are expected to be invariant to distortion.
Exemplar-CNN (Dosovitskiy et al., 2015) create surrogate training datasets with unlabeled image patches:
- Sample patches of size 32 × 32 pixels from different images at varying positions and scales, only from regions containing considerable gradients as those areas cover edges and tend to contain objects or parts of objects. They are “exemplary” patches.
- Each patch is distorted by applying a variety of random transformations (i.e., translation, rotation, scaling, etc.). All the resulting distorted patches are considered to belong to the same surrogate class.
- The pretext task is to discriminate between a set of surrogate classes. We can arbitrarily create as many surrogate classes as we want.

Fig. 2. The original patch of a cute deer is in the top left corner. Random transformations are applied, resulting in a variety of distorted patches. All of them should be classified into the same class in the pretext task. (Image source: Dosovitskiy et al., 2015)
Rotation of an entire image (Gidaris et al. 2018 is another interesting and cheap way to modify an input image while the semantic content stays unchanged. Each input image is first rotated by a multiple of at random, corresponding to . The model is trained to predict which rotation has been applied, thus a 4-class classification problem.
In order to identify the same image with different rotations, the model has to learn to recognize high level object parts, such as heads, noses, and eyes, and the relative positions of these parts, rather than local patterns. This pretext task drives the model to learn semantic concepts of objects in this way.
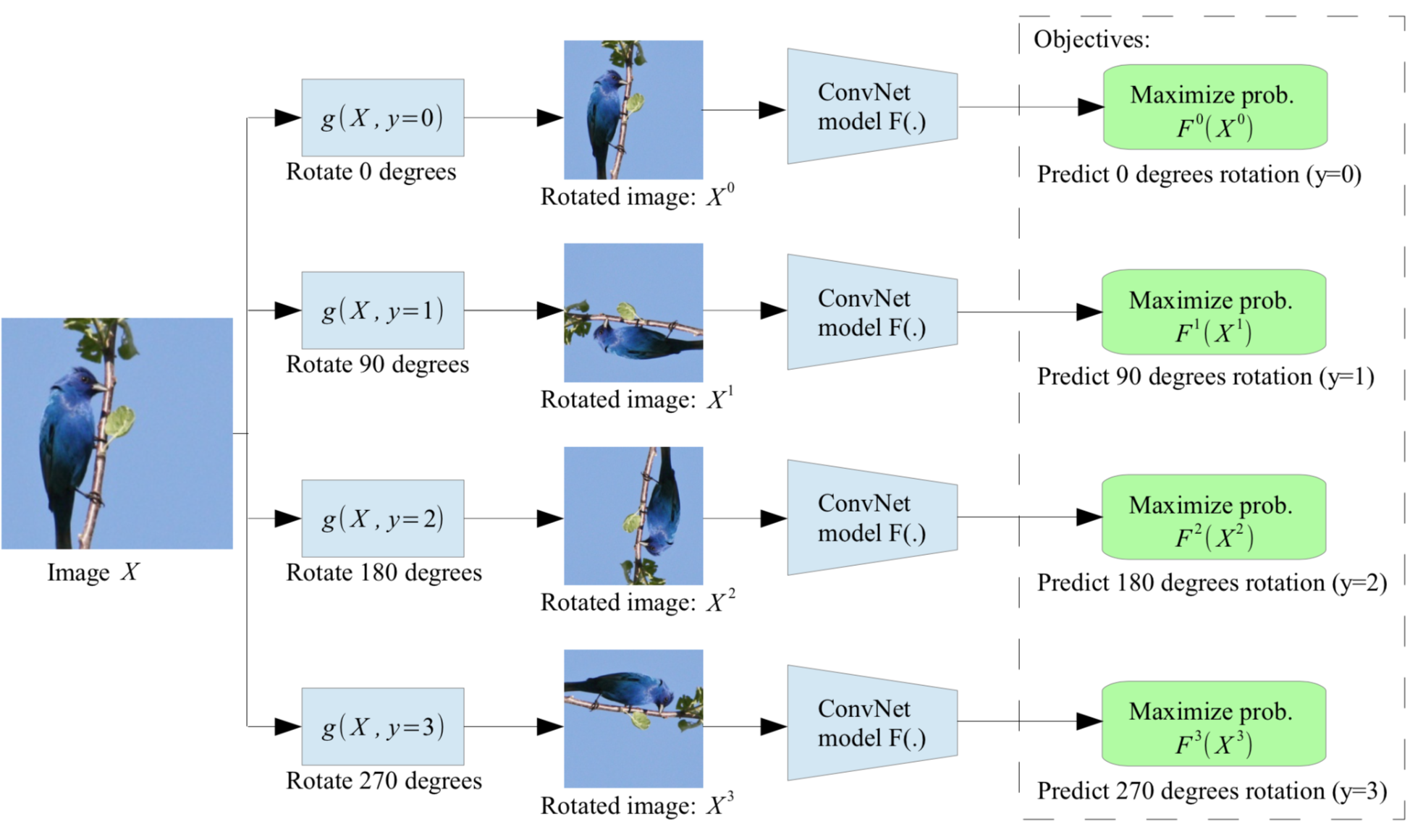
Fig. 3. Illustration of self-supervised learning by rotating the entire input images. The model learns to predict which rotation is applied. (Image source: Gidaris et al. 2018)
Patches
The second category of self-supervised learning tasks extract multiple patches from one image and ask the model to predict the relationship between these patches.
Doersch et al. (2015) formulates the pretext task as predicting the relative position between two random patches from one image. A model needs to understand the spatial context of objects in order to tell the relative position between parts.
The training patches are sampled in the following way:
- Randomly sample the first patch without any reference to image content.
- Considering that the first patch is placed in the middle of a 3x3 grid, and the second patch is sampled from its 8 neighboring locations around it.
- To avoid the model only catching low-level trivial signals, such as connecting a straight line across boundary or matching local patterns, additional noise is introduced by:The model is trained to predict which one of 8 neighboring locations the second patch is selected from, a classification problem over 8 classes.
- Add gaps between patches
- Small jitters
- Randomly downsample some patches to as little as 100 total pixels, and then upsampling it, to build robustness to pixelation.
- Shift green and magenta toward gray or randomly drop 2 of 3 color channels (See “chromatic aberration” below)
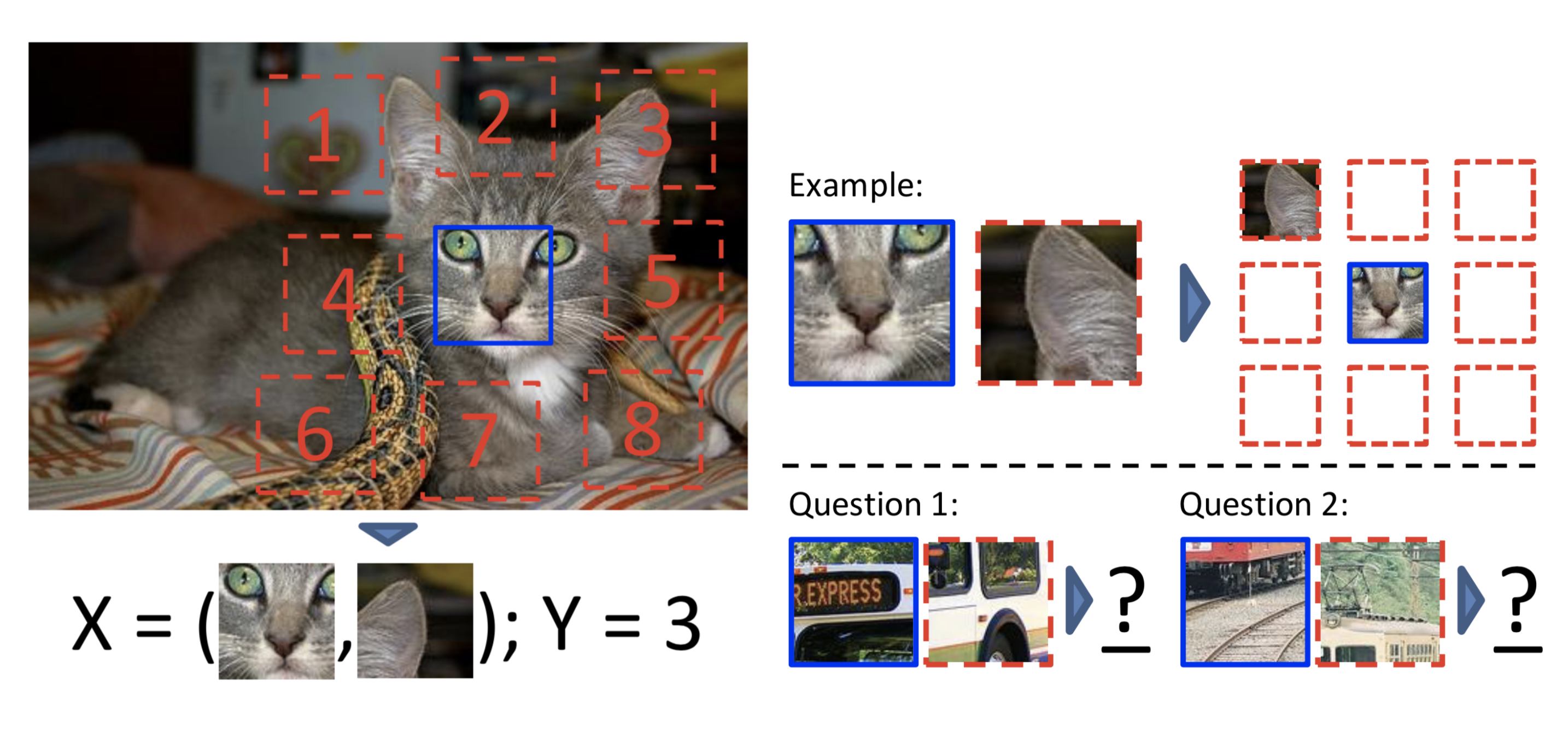
Fig. 4. Illustration of self-supervised learning by predicting the relative position of two random patches. (Image source: Doersch et al., 2015)
Other than trivial signals like boundary patterns or textures continuing, another interesting and a bit surprising trivial solution was found, called “chromatic aberration”. It is triggered by different focal lengths of lights at different wavelengths passing through the lens. In the process, there might exist small offsets between color channels. Hence, the model can learn to tell the relative position by simply comparing how green and magenta are separated differently in two patches. This is a trivial solution and has nothing to do with the image content. Pre-processing images by shifting green and magenta toward gray or randomly dropping 2 of 3 color channels can avoid this trivial solution.
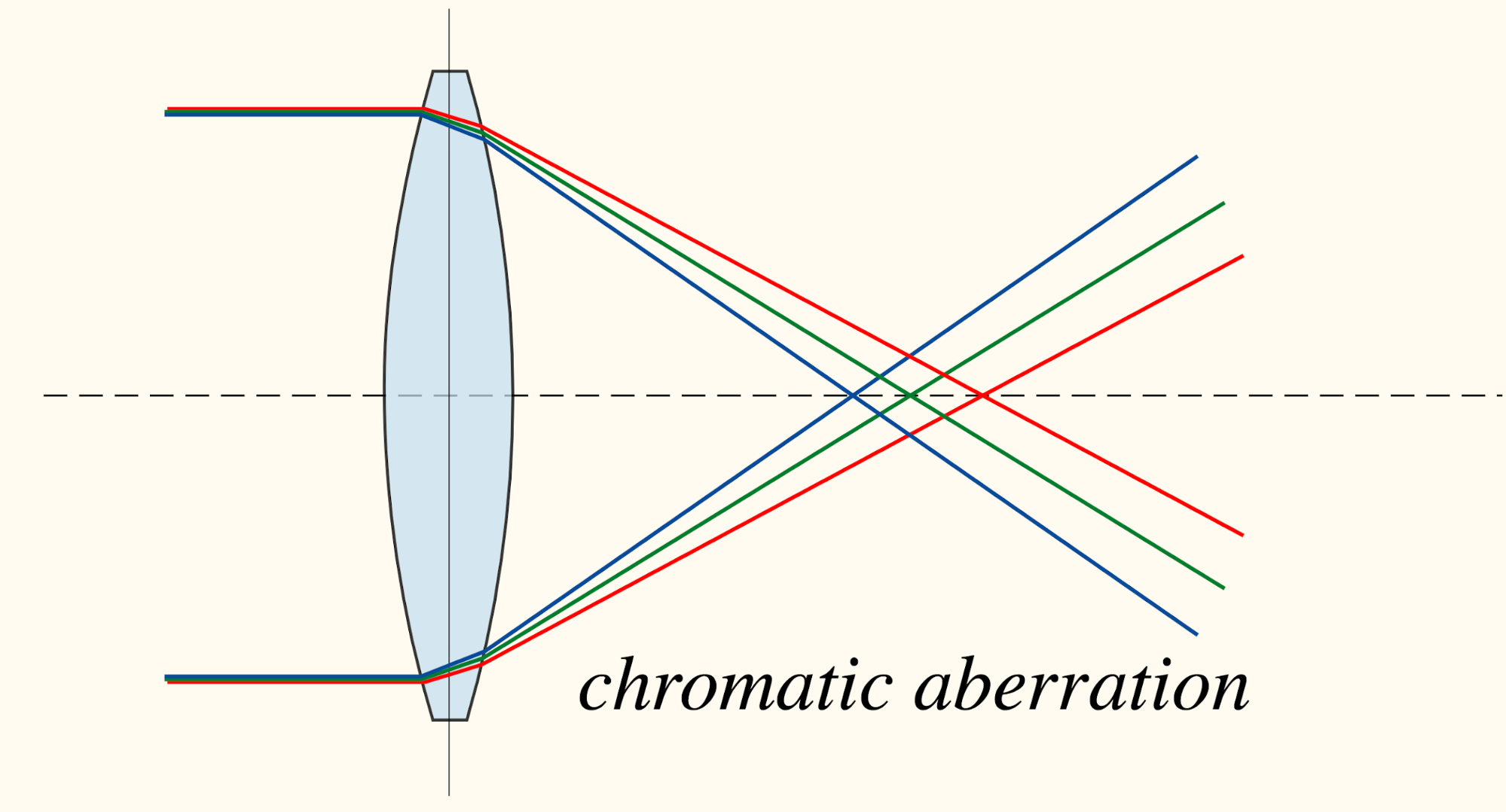
Fig. 5. Illustration of how chromatic aberration happens. (Image source: wikipedia)
{kind=link}
Since we have already set up a 3x3 grid in each image in the above task, why not use all of 9 patches rather than only 2 to make the task more difficult? Following this idea, Noroozi & Favaro (2016) designed a jigsaw puzzle game as pretext task: The model is trained to place 9 shuffled patches back to the original locations.
A convolutional network processes each patch independently with shared weights and outputs a probability vector per patch index out of a predefined set of permutations. To control the difficulty of jigsaw puzzles, the paper proposed to shuffle patches according to a predefined permutation set and configured the model to predict a probability vector over all the indices in the set.
Because how the input patches are shuffled does not alter the correct order to predict. A potential improvement to speed up training is to use permutation-invariant graph convolutional network (GCN) so that we don’t have to shuffle the same set of patches multiple times, same idea as in this paper.
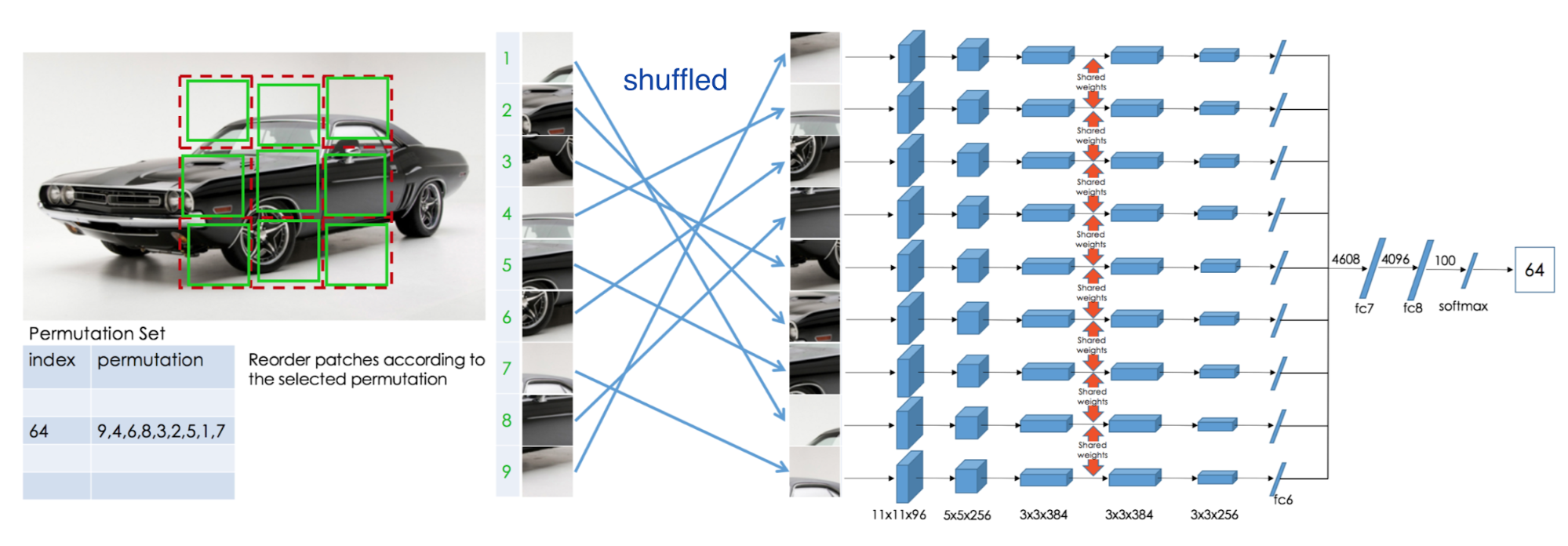
Fig. 6. Illustration of self-supervised learning by solving jigsaw puzzle. (Image source: Noroozi & Favaro, 2016)
Another idea is to consider “feature” or “visual primitives” as a scalar-value attribute that can be summed up over multiple patches and compared across different patches. Then the relationship between patches can be defined by counting features and simple arithmetic (Noroozi, et al, 2017).
The paper considers two transformations:
- Scaling: If an image is scaled up by 2x, the number of visual primitives should stay the same.
- Tiling: If an image is tiled into a 2x2 grid, the number of visual primitives is expected to be the sum, 4 times the original feature counts.
The model learns a feature encoder using the above feature counting relationship. Given an input image , considering two types of transformation operators:
- Downsampling operator, : downsample by a factor of 2
- Tiling operator : extract the -th tile from a 2x2 grid of the image.
We expect to learn:
Thus the MSE loss is: . To avoid trivial solution , another loss term is added to encourage the difference between features of two different images: , where is another input image different from and is a scalar constant. The final loss is:
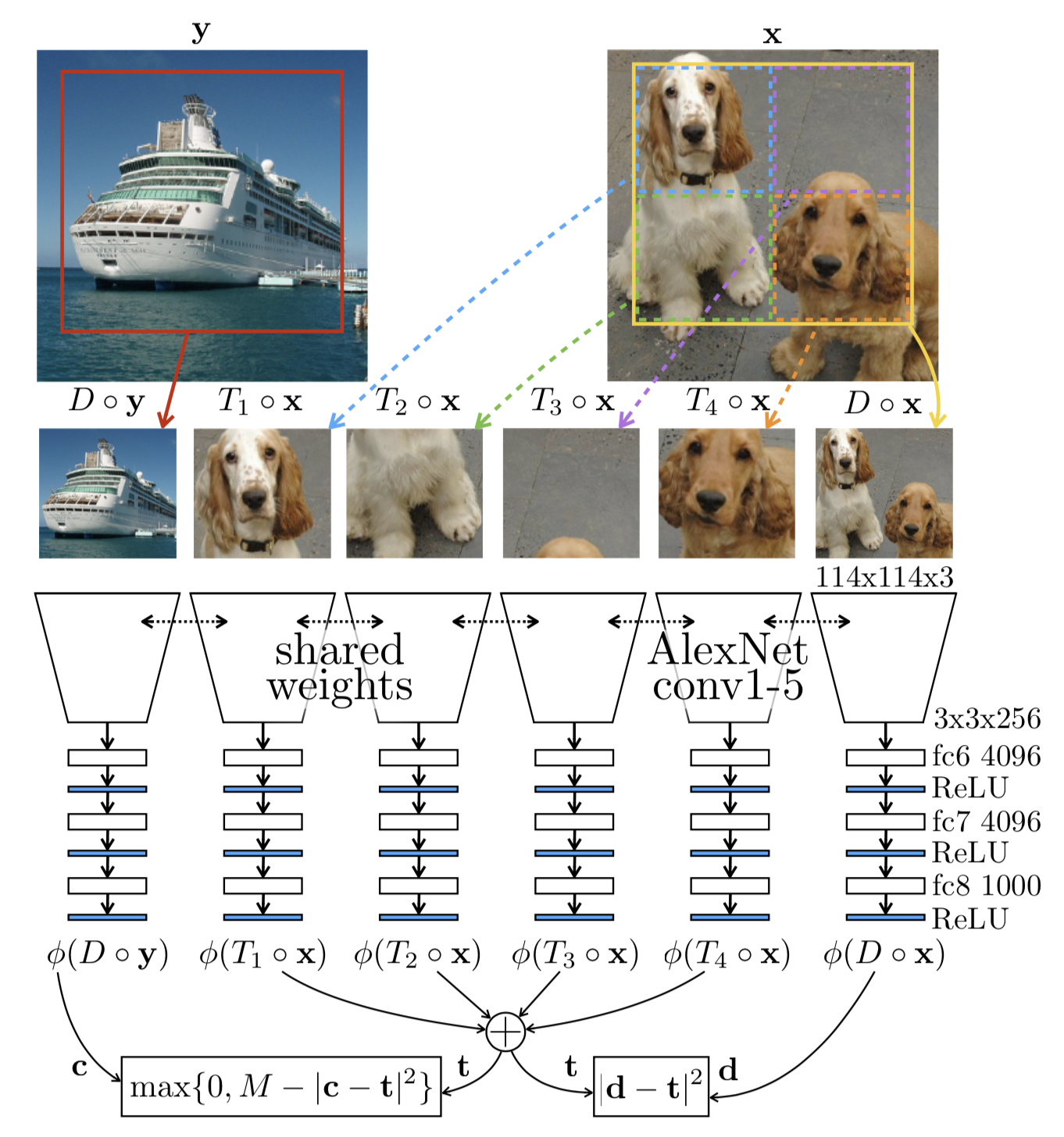
Fig. 7. Self-supervised representation learning by counting features. (Image source: Noroozi, et al, 2017)
Colorization
Colorization can be used as a powerful self-supervised task: a model is trained to color a grayscale input image; precisely the task is to map this image to a distribution over quantized color value outputs (Zhang et al. 2016).
The model outputs colors in the the CIE Lab* color space. The Lab* color is designed to approximate human vision, while, in contrast, RGB or CMYK models the color output of physical devices.
- L* component matches human perception of lightness; L* = 0 is black and L* = 100 indicates white.
- a* component represents green (negative) / magenta (positive) value.
- b* component models blue (negative) /yellow (positive) value.
Due to the multimodal nature of the colorization problem, cross-entropy loss of predicted probability distribution over binned color values works better than L2 loss of the raw color values. The ab color space is quantized with bucket size 10.
To balance between common colors (usually low ab values, of common backgrounds like clouds, walls, and dirt) and rare colors (which are likely associated with key objects in the image), the loss function is rebalanced with a weighting term that boosts the loss of infrequent color buckets. This is just like why we need both tf and idf for scoring words in information retrieval model. The weighting term is constructed as: (1-λ) * Gaussian-kernel-smoothed empirical probability distribution + λ * a uniform distribution, where both distributions are over the quantized ab color space.
Generative Modeling
The pretext task in generative modeling is to reconstruct the original input while learning meaningful latent representation.
The denoising autoencoder (Vincent, et al, 2008) learns to recover an image from a version that is partially corrupted or has random noise. The design is inspired by the fact that humans can easily recognize objects in pictures even with noise, indicating that key visual features can be extracted and separated from noise. See my old post.
The context encoder (Pathak, et al., 2016) is trained to fill in a missing piece in the image. Let be a binary mask, 0 for dropped pixels and 1 for remaining input pixels. The model is trained with a combination of the reconstruction (L2) loss and the adversarial loss. The removed regions defined by the mask could be of any shape.
where is the encoder and is the decoder.
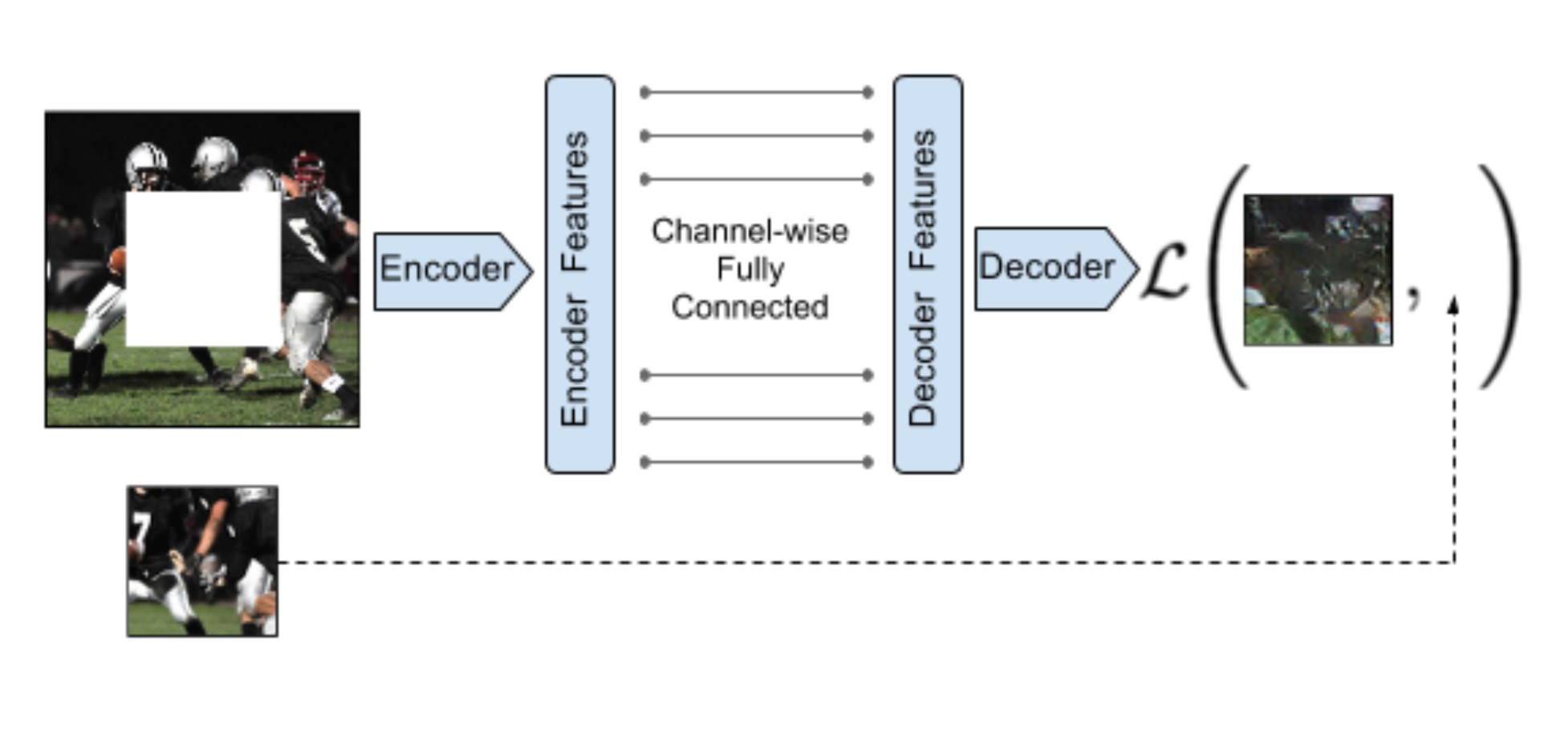
Fig. 8. Illustration of context encoder. (Image source: Pathak, et al., 2016)
When applying a mask on an image, the context encoder removes information of all the color channels in partial regions. How about only hiding a subset of channels? The split-brain autoencoder (Zhang et al., 2017) does this by predicting a subset of color channels from the rest of channels. Let the data tensor with color channels be the input for the -th layer of the network. It is split into two disjoint parts, and , where . Then two sub-networks are trained to do two complementary predictions: one network predicts from and the other network predicts from . The loss is either L1 loss or cross entropy if color values are quantized.
The split can happen once on the RGB-D or Lab* colorspace, or happen even in every layer of a CNN network in which the number of channels can be arbitrary.
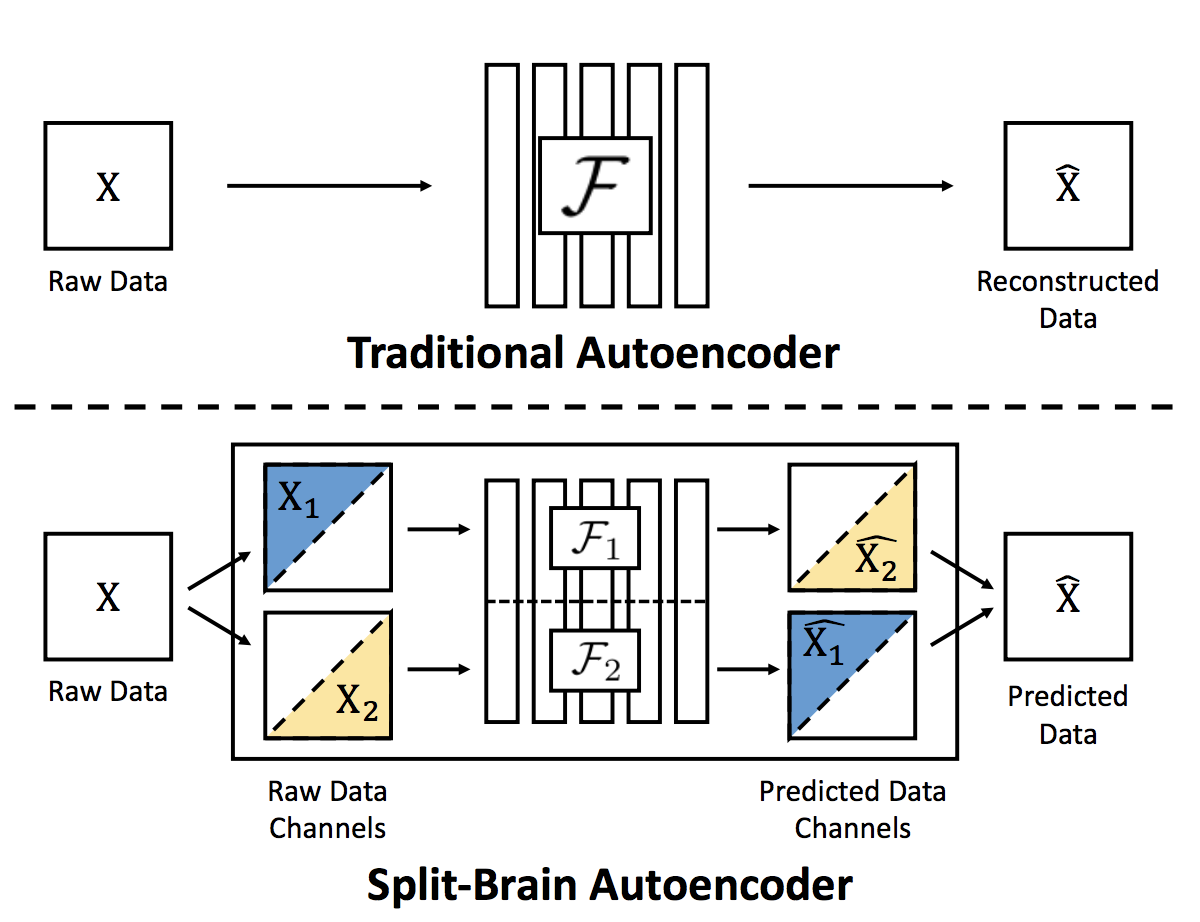
Fig. 9. Illustration of split-brain autoencoder. (Image source: Zhang et al., 2017)
The generative adversarial networks (GANs) are able to learn to map from simple latent variables to arbitrarily complex data distributions. Studies have shown that the latent space of such generative models captures semantic variation in the data; e.g. when training GAN models on human faces, some latent variables are associated with facial expression, glasses, gender, etc (Radford et al., 2016).
Bidirectional GANs (Donahue, et al, 2017) introduces an additional encoder to learn the mappings from the input to the latent variable . The discriminator predicts in the joint space of the input data and latent representation, , to tell apart the generated pair from the real one . The model is trained to optimize the objective: , where the generator and the encoder learn to generate data and latent variables that are realistic enough to confuse the discriminator and at the same time the discriminator tries to differentiate real and generated data.
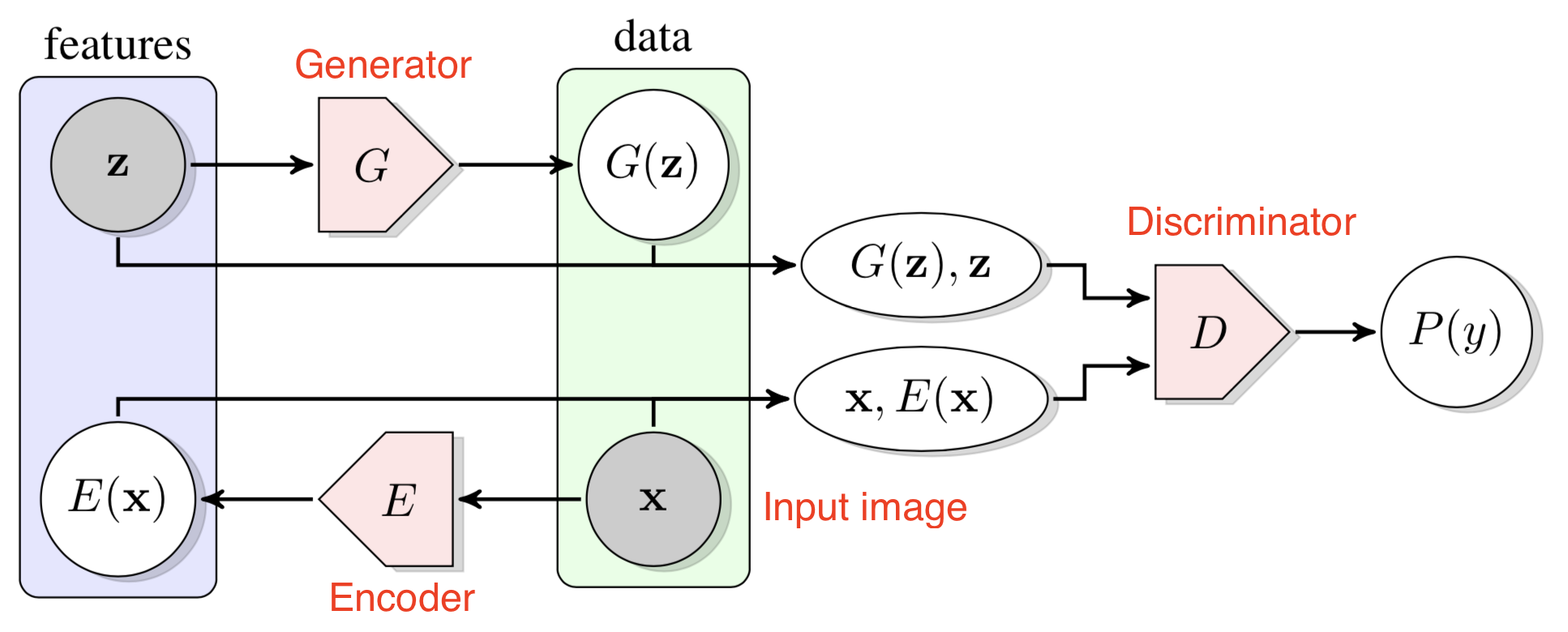
Fig. 10. Illustration of how Bidirectional GAN works. (Image source: Donahue, et al, 2017)
Video-Based
A video contains a sequence of semantically related frames. Nearby frames are close in time and more correlated than frames further away. The order of frames describes certain rules of reasonings and physical logics; such as that object motion should be smooth and gravity is pointing down.
A common workflow is to train a model on one or multiple pretext tasks with unlabelled videos and then feed one intermediate feature layer of this model to fine-tune a simple model on downstream tasks of action classification, segmentation or object tracking.
Tracking
The movement of an object is traced by a sequence of video frames. The difference between how the same object is captured on the screen in close frames is usually not big, commonly triggered by small motion of the object or the camera. Therefore any visual representation learned for the same object across close frames should be close in the latent feature space. Motivated by this idea, Wang & Gupta, 2015 proposed a way of unsupervised learning of visual representation by tracking moving objects in videos.
Precisely patches with motion are tracked over a small time window (e.g. 30 frames). The first patch and the last patch are selected and used as training data points. If we train the model directly to minimize the difference between feature vectors of two patches, the model may only learn to map everything to the same value. To avoid such a trivial solution, same as above, a random third patch is added. The model learns the representation by enforcing the distance between two tracked patches to be closer than the distance between the first patch and a random one in the feature space, , where is the cosine distance,
The loss function is:
where is a scalar constant controlling for the minimum gap between two distances; in the paper. The loss enforces at the optimal case.
This form of loss function is also known as triplet loss in the face recognition task, in which the dataset contains images of multiple people from multiple camera angles. Let be an anchor image of a specific person, be a positive image of this same person from a different angle and be a negative image of a different person. In the embedding space, should be closer to than :
A slightly different form of the triplet loss, named n-pair loss is also commonly used for learning observation embedding in robotics tasks. See a later section for more related content.
![]()
Fig. 11. Overview of learning representation by tracking objects in videos. (a) Identify moving patches in short traces; (b) Feed two related patched and one random patch into a conv network with shared weights. (c) The loss function enforces the distance between related patches to be closer than the distance between random patches. (Image source: Wang & Gupta, 2015)
Relevant patches are tracked and extracted through a two-step unsupervised optical flow approach:
- Obtain SURF interest points and use IDT to obtain motion of each SURF point.
- Given the trajectories of SURF interest points, classify these points as moving if the flow magnitude is more than 0.5 pixels.
During training, given a pair of correlated patches and , random patches are sampled in this same batch to form training triplets. After a couple of epochs, hard negative mining is applied to make the training harder and more efficient, that is, to search for random patches that maximize the loss and use them to do gradient updates.
Frame Sequence
Video frames are naturally positioned in chronological order. Researchers have proposed several self-supervised tasks, motivated by the expectation that good representation should learn the correct sequence of frames.
One idea is to validate frame order (Misra, et al 2016). The pretext task is to determine whether a sequence of frames from a video is placed in the correct temporal order (“temporal valid”). The model needs to track and reason about small motion of an object across frames to complete such a task.
The training frames are sampled from high-motion windows. Every time 5 frames are sampled and the timestamps are in order . Out of 5 frames, one positive tuple and two negative tuples, and are created. The parameter controls the difficulty of positive training instances (i.e. higher → harder) and the parameter controls the difficulty of negatives (i.e. lower → harder).
The pretext task of video frame order validation is shown to improve the performance on the downstream task of action recognition when used as a pretraining step.
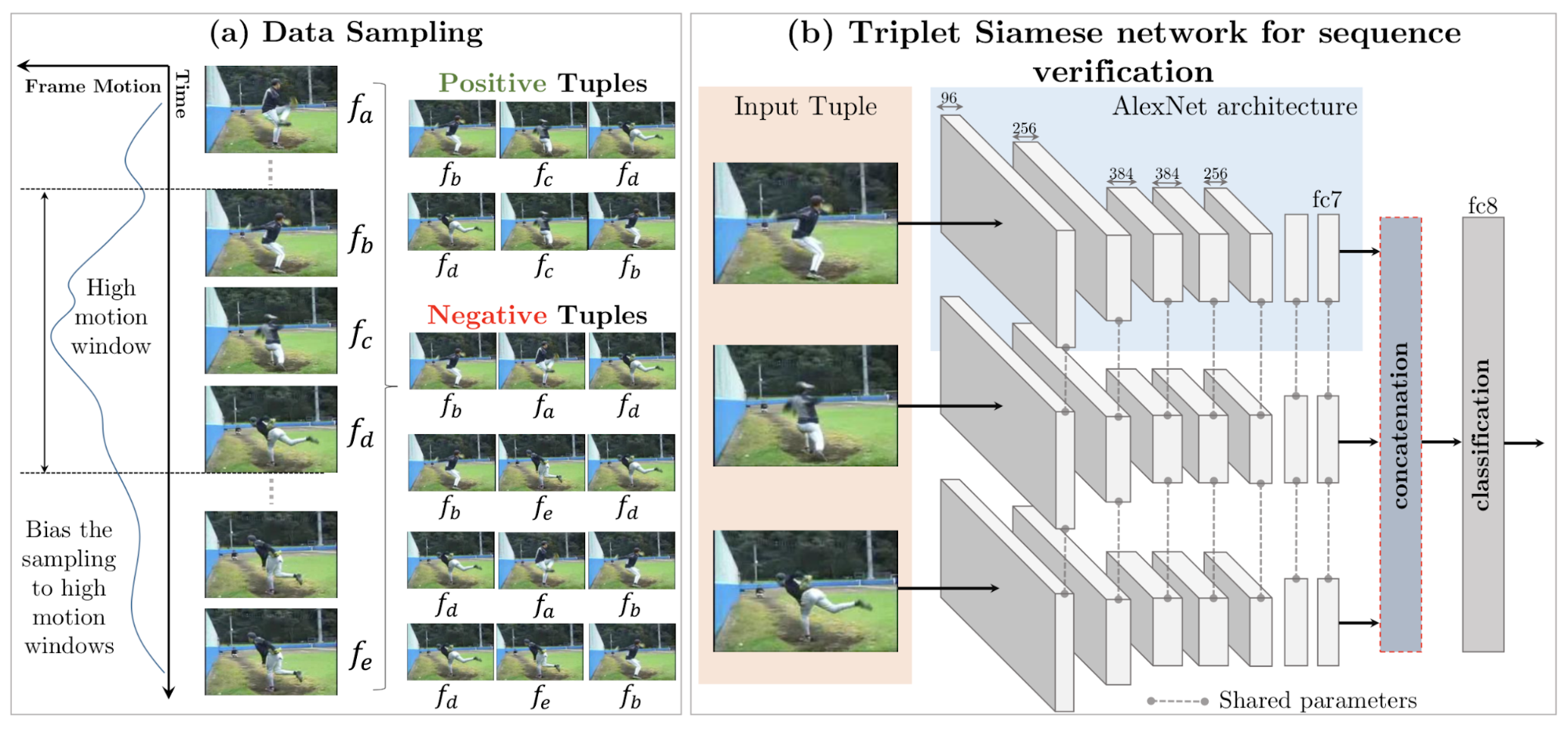
Fig. 12. Overview of learning representation by validating the order of video frames. (a) the data sample process; (b) the model is a triplet siamese network, where all input frames have shared weights. (Image source: Misra, et al 2016)
The task in O3N (Odd-One-Out Network; Fernando et al. 2017) is based on video frame sequence validation too. One step further from above, the task is to pick the incorrect sequence from multiple video clips.
Given input video clips, one of them has frames shuffled, thus in the wrong order, and the rest of them remain in the correct temporal order. O3N learns to predict the location of the odd video clip. In their experiments, there are 6 input clips and each contain 6 frames.
The arrow of time in a video contains very informative messages, on both low-level physics (e.g. gravity pulls objects down to the ground; smoke rises up; water flows downward.) and high-level event reasoning (e.g. fish swim forward; you can break an egg but cannot revert it.). Thus another idea is inspired by this to learn latent representation by predicting the arrow of time (AoT) — whether video playing forwards or backwards (Wei et al., 2018).
A classifier should capture both low-level physics and high-level semantics in order to predict the arrow of time. The proposed T-CAM (Temporal Class-Activation-Map) network accepts groups, each containing a number of frames of optical flow. The conv layer outputs from each group are concatenated and fed into binary logistic regression for predicting the arrow of time.
![]()
Fig. 13. Overview of learning representation by predicting the arrow of time. (a) Conv features of multiple groups of frame sequences are concatenated. (b) The top level contains 3 conv layers and average pooling. (Image source: Wei et al, 2018)
Interestingly, there exist a couple of artificial cues in the dataset. If not handled properly, they could lead to a trivial classifier without relying on the actual video content:
- Due to the video compression, the black framing might not be completely black but instead may contain certain information on the chronological order. Hence black framing should be removed in the experiments.
- Large camera motion, like vertical translation or zoom-in/out, also provides strong signals for the arrow of time but independent of content. The processing stage should stabilize the camera motion.
The AoT pretext task is shown to improve the performance on action classification downstream task when used as a pretraining step. Note that fine-tuning is still needed.
Video Colorization
Vondrick et al. (2018) proposed video colorization as a self-supervised learning problem, resulting in a rich representation that can be used for video segmentation and unlabelled visual region tracking, without extra fine-tuning.
Unlike the image-based colorization, here the task is to copy colors from a normal reference frame in color to another target frame in grayscale by leveraging the natural temporal coherency of colors across video frames (thus these two frames shouldn’t be too far apart in time). In order to copy colors consistently, the model is designed to learn to keep track of correlated pixels in different frames.
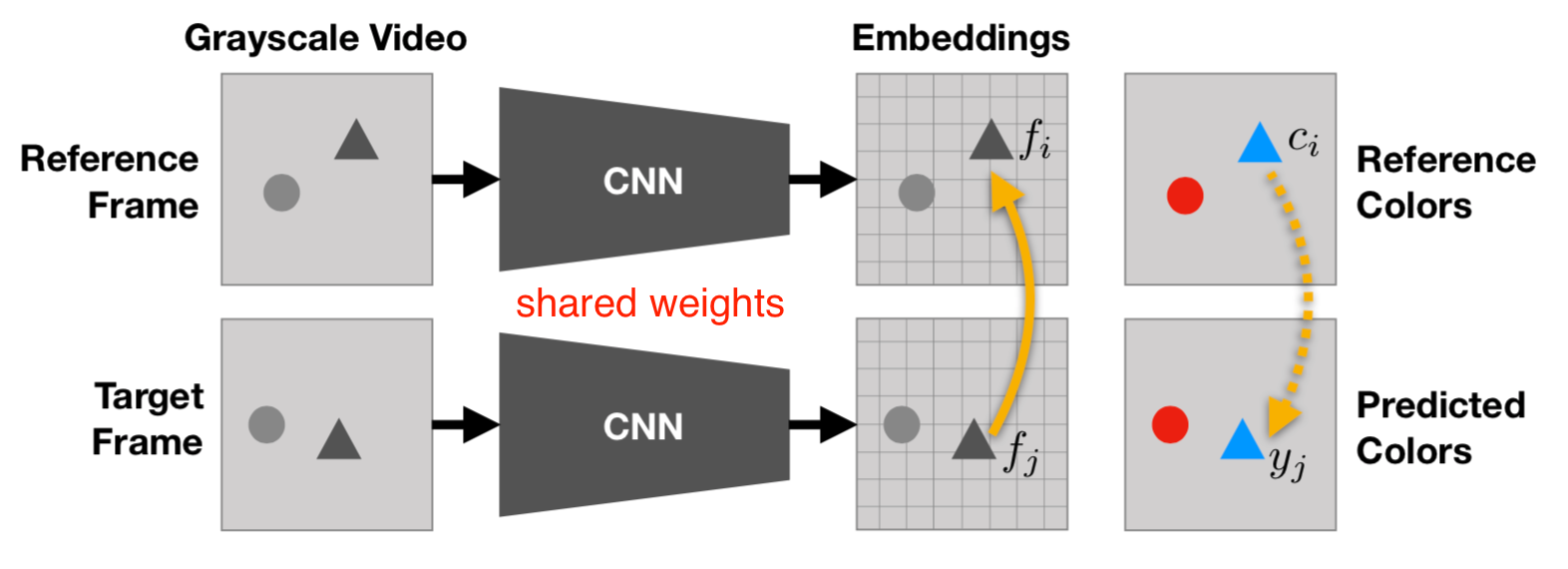
Fig. 14. Video colorization by copying colors from a reference frame to target frames in grayscale. (Image source: Vondrick et al. 2018)
The idea is quite simple and smart. Let be the true color of the pixel in the reference frame and be the color of -th pixel in the target frame. The predicted color of -th color in the target is a weighted sum of colors of all the pixels in reference, where the weighting term measures the similarity:
where are learned embeddings for corresponding pixels; indexes all the pixels in the reference frame. The weighting term implements an attention-based pointing mechanism, similar to matching network and pointer network. As the full similarity matrix could be really large, both frames are downsampled. The categorical cross-entropy loss between and is used with quantized colors, just like in Zhang et al. 2016.
Based on how the reference frame are marked, the model can be used to complete several color-based downstream tasks such as tracking segmentation or human pose in time. No fine-tuning is needed. See Fig. 15.

Fig. 15. Use video colorization to track object segmentation and human pose in time. (Image source: Vondrick et al. (2018))
Control-Based
When running a RL policy in the real world, such as controlling a physical robot on visual inputs, it is non-trivial to properly track states, obtain reward signals or determine whether a goal is achieved for real. The visual data has a lot of noise that is irrelevant to the true state and thus the equivalence of states cannot be inferred from pixel-level comparison. Self-supervised representation learning has shown great potential in learning useful state embedding that can be used directly as input to a control policy.
All the cases discussed in this section are in robotic learning, mainly for state representation from multiple camera views and goal representation.
Multi-View Metric Learning
The concept of metric learning has been mentioned multiple times in the previous sections. A common setting is: Given a triple of samples, (anchor , positive sample , negative sample ), the learned representation embedding fulfills that stays close to but far away from in the latent space.
Grasp2Vec (Jang et al., 2018) aims to learn an object-centric vision representation in the robot grasping task from free, unlabelled grasping activities. By object-centric, it means that, irrespective of how the environment or the robot looks like, if two images contain similar items, they should be mapped to similar representation; otherwise the embeddings should be far apart.
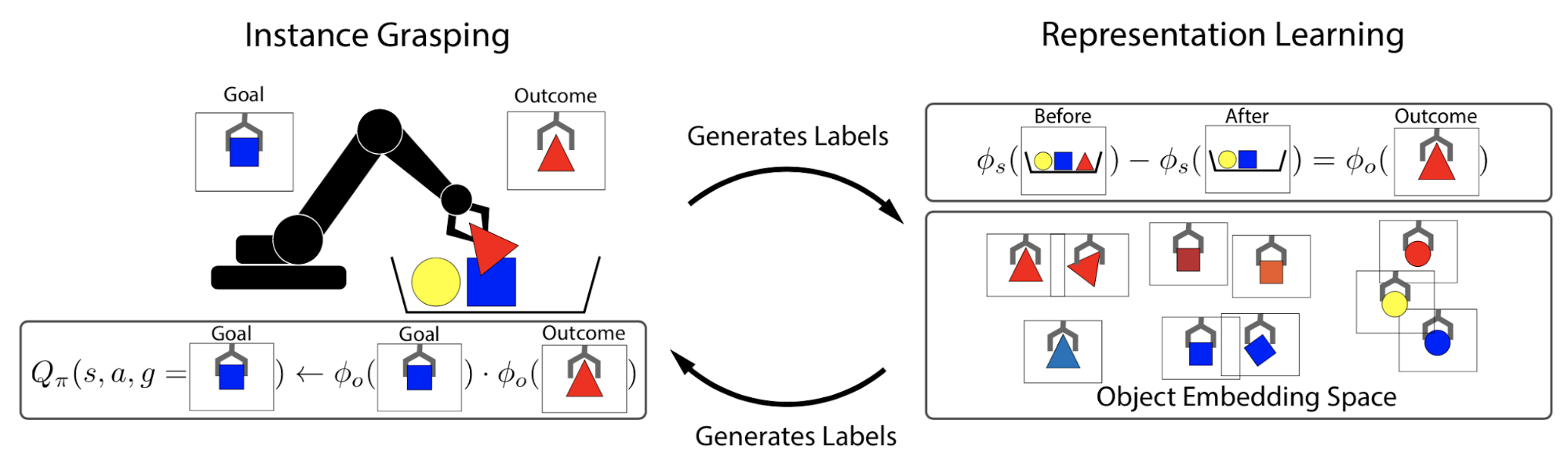
Fig. 16. A conceptual illustration of how grasp2vec learns an object-centric state embedding. (Image source: Jang et al., 2018)
The grasping system can tell whether it moves an object but cannot tell which object it is. Cameras are set up to take images of the entire scene and the grasped object. During early training, the grasp robot is executed to grasp any object at random, producing a triple of images, :
- is an image of the grasped object held up to the camera;
- is an image of the scene before grasping, with the object in the tray;
- is an image of the same scene after grasping, without the object in the tray.
To learn object-centric representation, we expect the difference between embeddings of and to capture the removed object . The idea is quite interesting and similar to relationships that have been observed in word embedding, e.g. distance(“king”, “queen”) ≈ distance(“man”, “woman”).
Let and be the embedding functions for the scene and the object respectively. The model learns the representation by minimizing the distance between and using n-pair loss:
where refers to a batch of (anchor, positive) sample pairs.
When framing representation learning as metric learning, n-pair loss is a common choice. Rather than processing explicit a triple of (anchor, positive, negative) samples, the n-pairs loss treats all other positive instances in one mini-batch across pairs as negatives.
The embedding function works great for presenting a goal with an image. The reward function that quantifies how close the actually grasped object is close to the goal is defined as . Note that computing rewards only relies on the learned latent space and doesn’t involve ground truth positions, so it can be used for training on real robots.

Fig. 17. Localization results of grasp2vec embedding. The heatmap of localizing a goal object in a pre-grasping scene is defined as , where is the output of the last resnet block after ReLU. The fourth column is a failure case and the last three columns take real images as goals. (Image source: Jang et al., 2018)
Other than the embedding-similarity-based reward function, there are a few other tricks for training the RL policy in the grasp2vec framework:
- posthoc labelingP: Augment the dataset by labeling a randomly grasped object as a correct goal, like HER (Hindsight Experience Replay; Andrychowicz, et al., 2017).
- Auxiliary goal augmentation: Augment the replay buffer even further by relabeling transitions with unachieved goals; precisely, in each iteration, two goals are sampled and both are used to add new transitions into replay buffer.
TCN (Time-Contrastive Networks; Sermanet, et al. 2018) learn from multi-camera view videos with the intuition that different viewpoints at the same timestep of the same scene should share the same embedding (like in FaceNet) while embedding should vary in time, even of the same camera viewpoint. Therefore embedding captures the semantic meaning of the underlying state rather than visual similarity. The TCN embedding is trained with triplet loss.
The training data is collected by taking videos of the same scene simultaneously but from different angles. All the videos are unlabelled.
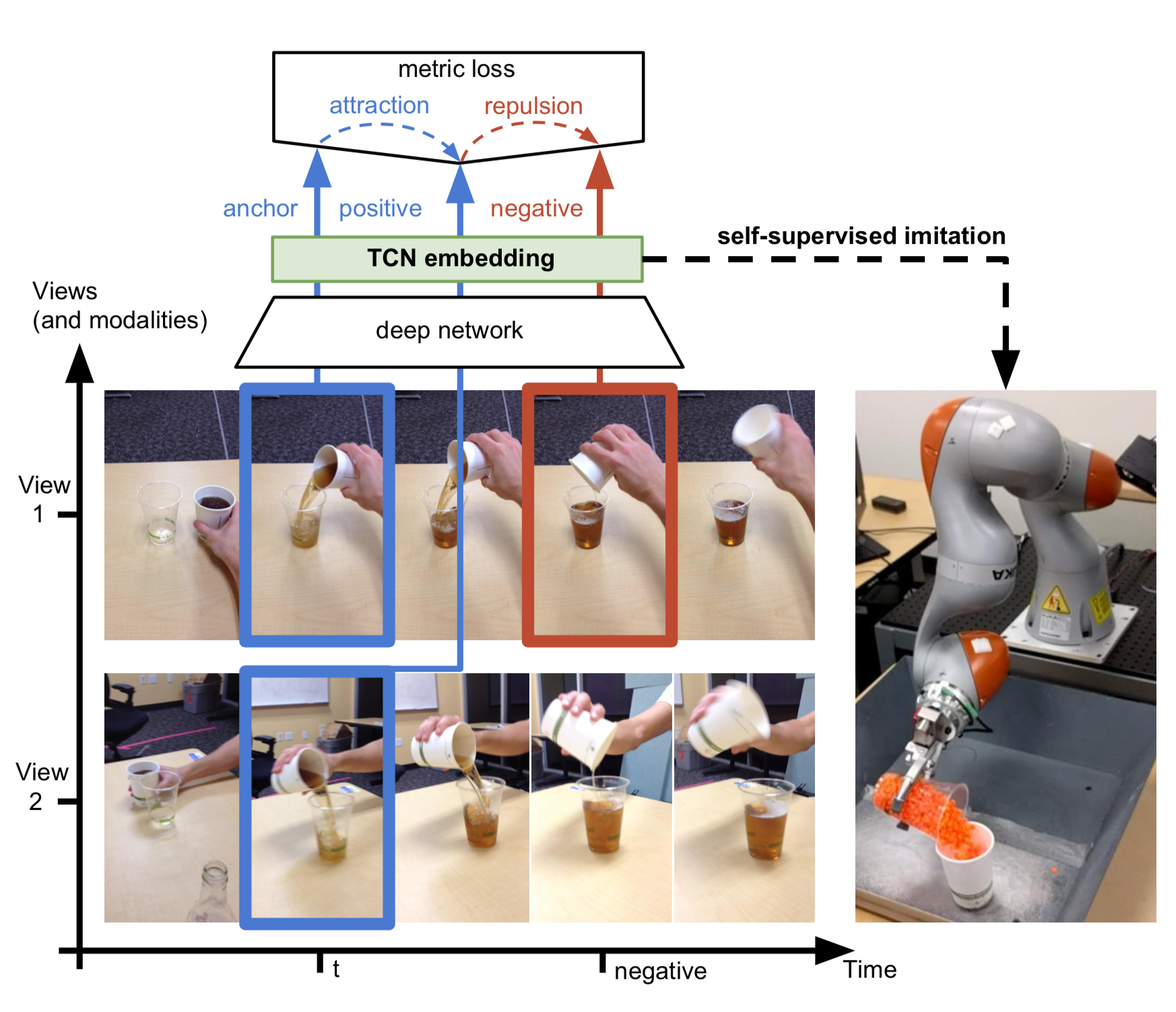
Fig. 18. An illustration of time-contrastive approach for learning state embedding. The blue frames selected from two camera views at the same timestep are anchor and positive samples, while the red frame at a different timestep is the negative sample.
TCN embedding extracts visual features that are invariant to camera configurations. It can be used to construct a reward function for imitation learning based on the euclidean distance between the demo video and the observations in the latent space.
A further improvement over TCN is to learn embedding over multiple frames jointly rather than a single frame, resulting in mfTCN (Multi-frame Time-Contrastive Networks; Dwibedi et al., 2019). Given a set of videos from several synchronized camera viewpoints, , the frame at time and the previous frames selected with stride in each video are aggregated and mapped into one embedding vector, resulting in a lookback window of size $(n−1) \times s + 1$. Each frame first goes through a CNN to extract low-level features and then we use 3D temporal convolutions to aggregate frames in time. The model is trained with n-pairs loss.
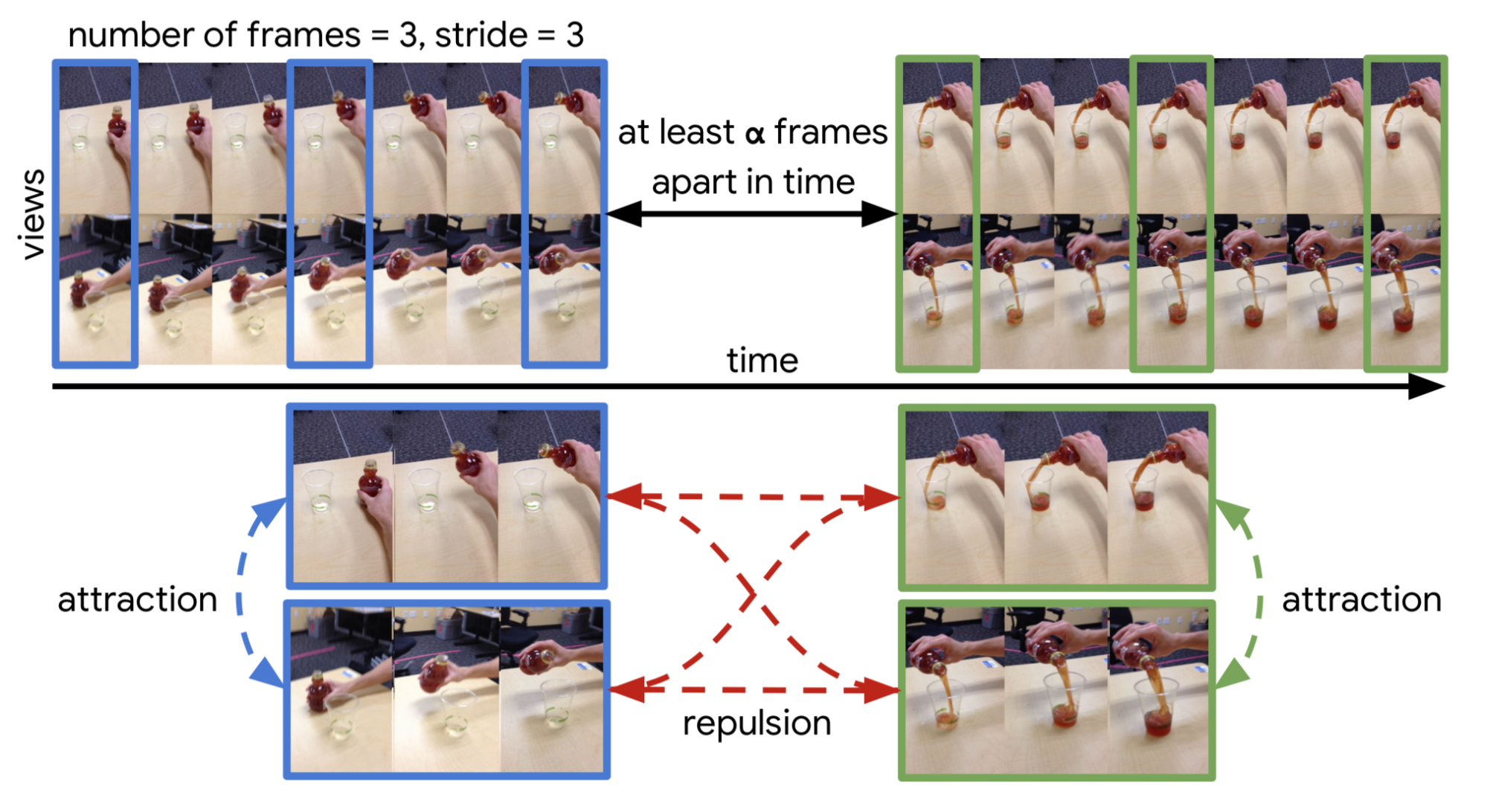
Fig. 19. The sampling process for training mfTCN. (Image source: Dwibedi et al., 2019)
The training data is sampled as follows:
- First we construct two pairs of video clips. Each pair contains two clips from different camera views but with synchronized timesteps. These two sets of videos should be far apart in time.
- Sample a fixed number of frames from each video clip in the same pair simultaneously with the same stride.
- Frames with the same timesteps are trained as positive samples in the n-pair loss, while frames across pairs are negative samples.
mfTCN embedding can capture the position and velocity of objects in the scene (e.g. in cartpole) and can also be used as inputs for policy.
Autonomous Goal Generation
RIG (Reinforcement learning with Imagined Goals; Nair et al., 2018) described a way to train a goal-conditioned policy with unsupervised representation learning. A policy learns from self-supervised practice by first imagining “fake” goals and then trying to achieve them.
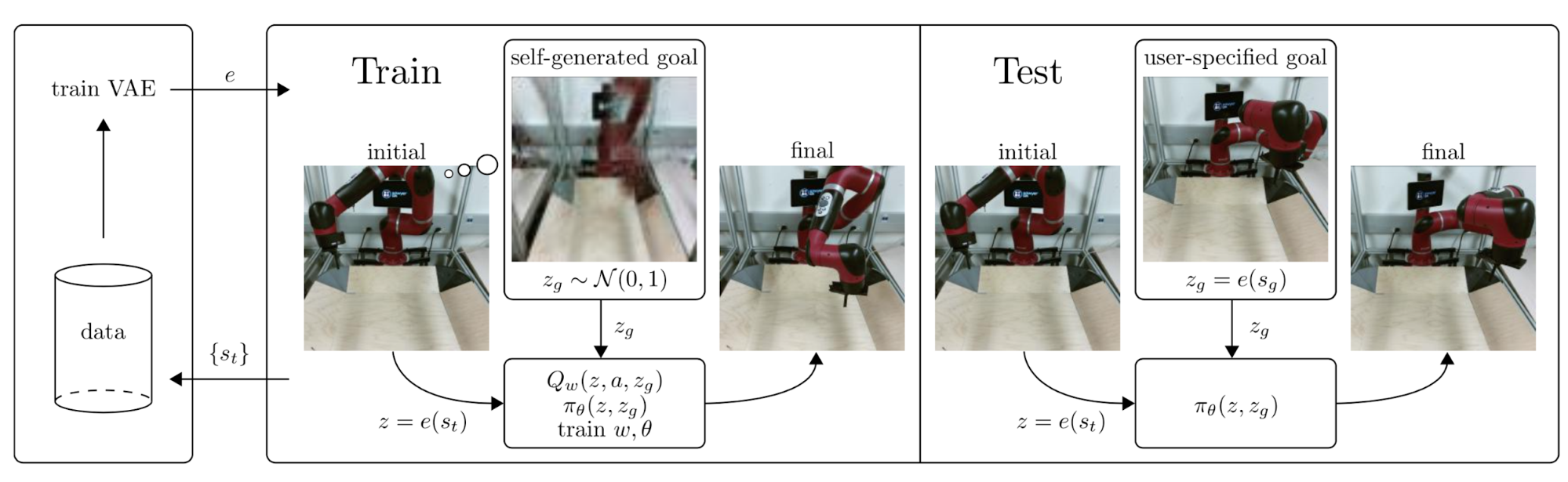
Fig. 20. The workflow of RIG. (Image source: Nair et al., 2018)
The task is to control a robot arm to push a small puck on a table to a desired position. The desired position, or the goal, is present in an image. During training, it learns latent embedding of both state and goal through $\beta$-VAE encoder and the control policy operates entirely in the latent space.
Let’s say a -VAE has an encoder mapping input states to latent variable which is modeled by a Gaussian distribution and a decoder mapping back to the states. The state encoder in RIG is set to be the mean of -VAE encoder.
The reward is the Euclidean distance between state and goal embedding vectors: . Similar to grasp2vec, RIG applies data augmentation as well by latent goal relabeling: precisely half of the goals are generated from the prior at random and the other half are selected using HER. Also same as grasp2vec, rewards do not depend on any ground truth states but only the learned state encoding, so it can be used for training on real robots.

Fig. 21. The algorithm of RIG. (Image source: Nair et al., 2018)
The problem with RIG is a lack of object variations in the imagined goal pictures. If -VAE is only trained with a black puck, it would not be able to create a goal with other objects like blocks of different shapes and colors. A follow-up improvement replaces -VAE with a CC-VAE (Context-Conditioned VAE; Nair, et al., 2019), inspired by CVAE (Conditional VAE; Sohn, Lee & Yan, 2015), for goal generation.
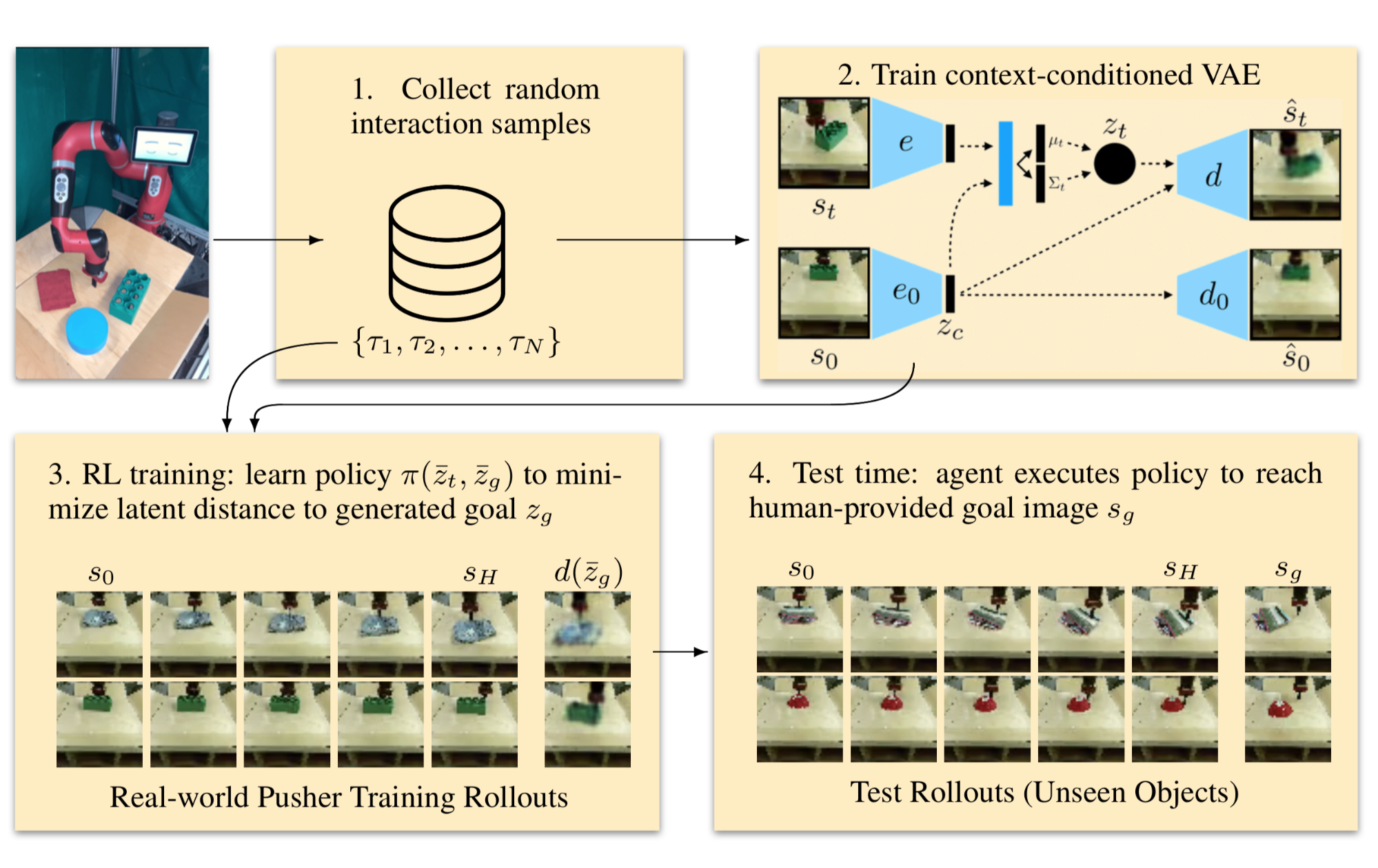
Fig. 22. The workflow of context-conditioned RIG. (Image source: Nair, et al., 2019).
A CVAE conditions on a context variable . It trains an encoder and a decoder and note that both have access to . The CVAE loss penalizes information passing from the input state through an information bottleneck but allows for unrestricted information flow from to both encoder and decoder.
To create plausible goals, CC-VAE conditions on a starting state so that the generated goal presents a consistent type of object as in . This goal consistency is necessary; e.g. if the current scene contains a red puck but the goal has a blue block, it would confuse the policy.
Other than the state encoder , CC-VAE trains a second convolutional encoder to translate the starting state into a compact context representation . Two encoders, and , are intentionally different without shared weights, as they are expected to encode different factors of image variation. In addition to the loss function of CVAE, CC-VAE adds an extra term to learn to reconstruct back to , .

Fig. 23. Examples of imagined goals generated by CVAE that conditions on the context image (the first row), while VAE fails to capture the object consistency. (Image source: Nair, et al., 2019).
A couple common observations:
- Combining multiple pretext tasks improves performance;
- Deeper networks improve the quality of representation;
- Supervised learning baselines still beat all of them by far.
References
[1] Alexey Dosovitskiy, et al. “Discriminative unsupervised feature learning with exemplar convolutional neural networks.” IEEE transactions on pattern analysis and machine intelligence 38.9 (2015): 1734-1747.
[2] Spyros Gidaris, Praveer Singh & Nikos Komodakis. “Unsupervised Representation Learning by Predicting Image Rotations” ICLR 2018.
[3] Carl Doersch, Abhinav Gupta, and Alexei A. Efros. “Unsupervised visual representation learning by context prediction.” ICCV. 2015.
[4] Mehdi Noroozi & Paolo Favaro. “Unsupervised learning of visual representations by solving jigsaw puzzles.” ECCV, 2016.
[5] Mehdi Noroozi, Hamed Pirsiavash, and Paolo Favaro. “Representation learning by learning to count.” ICCV. 2017.
[6] Richard Zhang, Phillip Isola & Alexei A. Efros. “Colorful image colorization.” ECCV, 2016.
[7] Pascal Vincent, et al. “Extracting and composing robust features with denoising autoencoders.” ICML, 2008.
[8] Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. “Adversarial feature learning.” ICLR 2017.
[9] Deepak Pathak, et al. “Context encoders: Feature learning by inpainting.” CVPR. 2016.
[10] Richard Zhang, Phillip Isola, and Alexei A. Efros. “Split-brain autoencoders: Unsupervised learning by cross-channel prediction.” CVPR. 2017.
[11] Xiaolong Wang & Abhinav Gupta. “Unsupervised Learning of Visual Representations using Videos.” ICCV. 2015.
[12] Carl Vondrick, et al. “Tracking Emerges by Colorizing Videos” ECCV. 2018.
[13] Ishan Misra, C. Lawrence Zitnick, and Martial Hebert. “Shuffle and learn: unsupervised learning using temporal order verification.” ECCV. 2016.
[14] Basura Fernando, et al. “Self-Supervised Video Representation Learning With Odd-One-Out Networks” CVPR. 2017.
[15] Donglai Wei, et al. “Learning and Using the Arrow of Time” CVPR. 2018.
[16] Florian Schroff, Dmitry Kalenichenko and James Philbin. “FaceNet: A Unified Embedding for Face Recognition and Clustering” CVPR. 2015.
[17] Pierre Sermanet, et al. “Time-Contrastive Networks: Self-Supervised Learning from Video” CVPR. 2018.
[18] Debidatta Dwibedi, et al. “Learning actionable representations from visual observations.” IROS. 2018.
[19] Eric Jang, et al. “Grasp2Vec: Learning Object Representations from Self-Supervised Grasping” CoRL. 2018.
[20] Ashvin Nair, et al. “Visual reinforcement learning with imagined goals” NeuriPS. 2018.
[21] Ashvin Nair, et al. “Contextual imagined goals for self-supervised robotic learning” CoRL. 2019.
Self-Supervised Representation Learning的更多相关文章
- (转)Predictive learning vs. representation learning 预测学习 与 表示学习
Predictive learning vs. representation learning 预测学习 与 表示学习 When you take a machine learning class, ...
- 翻译 Improved Word Representation Learning with Sememes
翻译 Improved Word Representation Learning with Sememes 题目 Improved Word Representation Learning with ...
- (zhuan) Notes on Representation Learning
this blog from: https://opendatascience.com/blog/notes-on-representation-learning-1/ Notes on Repr ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- 论文笔记系列-iCaRL: Incremental Classifier and Representation Learning
导言 传统的神经网络都是基于固定的数据集进行训练学习的,一旦有新的,不同分布的数据进来,一般而言需要重新训练整个网络,这样费时费力,而且在实际应用场景中也不适用,所以增量学习应运而生. 增量学习主要旨 ...
- 【CV】ICCV2015_Unsupervised Visual Representation Learning by Context Prediction
Unsupervised Visual Representation Learning by Context Prediction Note here: it's a learning note on ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 网络表示学习Network Representation Learning/Embedding
网络表示学习相关资料 网络表示学习(network representation learning,NRL),也被称为图嵌入方法(graph embedding method,GEM)是这两年兴起的工 ...
- Hierarchical Attention Based Semi-supervised Network Representation Learning
Hierarchical Attention Based Semi-supervised Network Representation Learning 1. 任务 给定:节点信息网络 目标:为每个节 ...
随机推荐
- CDA数据分析实务【第一章:营销决策分析概述】
一.营销概述 营销是关于企业如何发现.创造和交付价值以满足一定目标市场的需求,同时获取利润的学科.营销学用来辨识未被满足的需求,定义,度量目标市场的规模和利润潜力,找到最合适企业进入的细分市场和适合该 ...
- 排序算法的c++实现——快速排序
快速排序是分治思想的又一典型代表,是应用最广的排序算法.分治思想就是把原问题的解分解为两个或多个子问题解,求解出子问题的解之后再构造出原问题的解. 在快速排序算法中,它的思想是把一个待排序的数组分成前 ...
- 关于SQL优化
建立索引常用的规则 表的主键.外键必须有索引: 数据量超过300的表应该有索引: 经常与其他表进行连接的表,在连接字段上应该建立索引: 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引 ...
- 微信小程序 - scroll-view的scroll-into-view属性 - 在页面打开后滚动到指定的项
需求: 这是一个可横向滚动的导航条,现在要求我,从别的页面reLaunch回到首页这里,刷新页面内容的同时,菜单项要滚动出来 (如果该菜单项不在可视区域),而不是让他被挡住. 代码:<scrol ...
- 【功能点】php导出excel
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_33862644/article/d ...
- FFMPEG 命令行工具- ffmpeg
ffmpeg 简介 ffmpeg 用于转码的应用程序,命令格式: ffmpeg [options] [[infile options] -i infile]... {[outfile options] ...
- django项目后台权限管理功能。
对后台管理员进行分角色,分类别管理,每个管理员登录账号后只显示自己负责的权限范围. 创建后台管理数据库 models.py文件内 # 管理员表 class Superuser(models.Model ...
- C++类库开发详解(转)
前言:这是一篇总结性的文章,需要有一点C++和dll基本知识的基础,在网上查阅了很多资料感觉没有一篇详细.具体.全面的dll开发介绍,我这是根据最近项目和网上资料整理出来的,并附带实例的一个总结性的文 ...
- utf8mb4版本设置django
'OPTIONS':{ 'init_command':"SET sql_mode='STRICT_TRANS_TABLES'", 'charset':'utf8mb4',
- jsbridge与通信模型
三层通信模型: 应用层.解释层.会话层: 通信协议: 通信原语: 报文格式: 网络层: _evaluateJavascript 会话层: #define kQueueHasMessage @&qu ...