Flink原理(七)——动态表(Dynamic tables)
前言
本文是结合Flink官网,个人理解所得,若是有误欢迎留言指出,谢谢!文中图皆来自官网(链接[1])。
本文将随着下面这个问题展开,针对该问题更为生动的解释可以参见金竹老师的分享(链接[2])。
SQL适合流计算场景吗?
对于流计算,每一条数据的到来都会触发一次查询产生一个结果,并发射出去。我们发现对于相同的数据源,使用相同的SQL查询时,批、流的结果是相同的,即在不同模式下,SQL的语意是一致的(One Query One Result),最终的结果是一致。
1、动态表与连续查询(Dynamic Table&Continuous Query)
和动态表对应的是静态表——常规的数据库中的表或批处理中的表等,其在查询时数据不再变化。动态表是随时间变化的,即使是在查询的时候。怎么理解了?流上的数据是源源不断的,一条数据的到来会触发一次查询,这次查询在执行时还有下一条数据到来,对表本身数据是在变化的。
对动态表的查询是连续的,即连续查询(Continuous Query)。实质上, 动态表上的连续查询与定义物理视图(Materialized View)的查询很相似。物理视图定义为SQL查询,就像常规的虚拟视图一样,不同的是物理视图会缓存查询结果,这样在访问时不需要重新计算,而缓存带来的挑战是有可能提供过时的结果,Eager View Maintenance则是用于及时跟新物理视图的技术,这里就不展开了。
流、动态表、连续查询三者的关系如下图所示:

用一句话概括是:流被转换为动态表,对动态表的连续查询生成新的动态表(结果表),然后结果表被转换为流。
2、流上定义表
2.1 定义表
为了在流上使用关系型查询,需要将流转换成表。下面的分析过程均采用官网(Ref[2])中的例子进行说明。
1)点击事件流的schema如下:
[
user: VARCHAR, // the name of the user
cTime: TIMESTAMP, // the time when the URL was accessed
url: VARCHAR // the URL that was accessed by the user
]
2)从概念上来说,流上的每天记录都是动态表进行INSERT修改。从本质上讲,是从一个INSERT-Only(仅插入)的ChangeLog流上构建一个表。点击事件流上构建表如下图所示,且随着更多点击流记录的插入,生成的表不断增长:
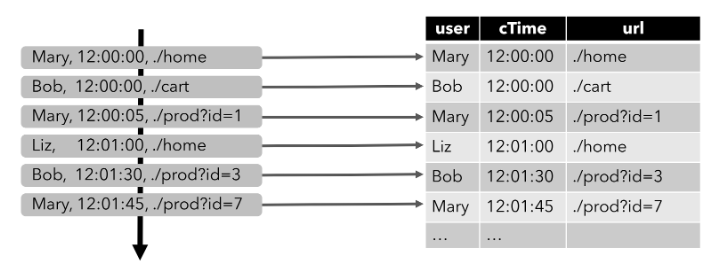
Note:定义在流上的表在内部是没有实现的。
2.2 连续查询
连续查询不会中止,会根据输入表来更新结果表,下面介绍两种查询的例子。
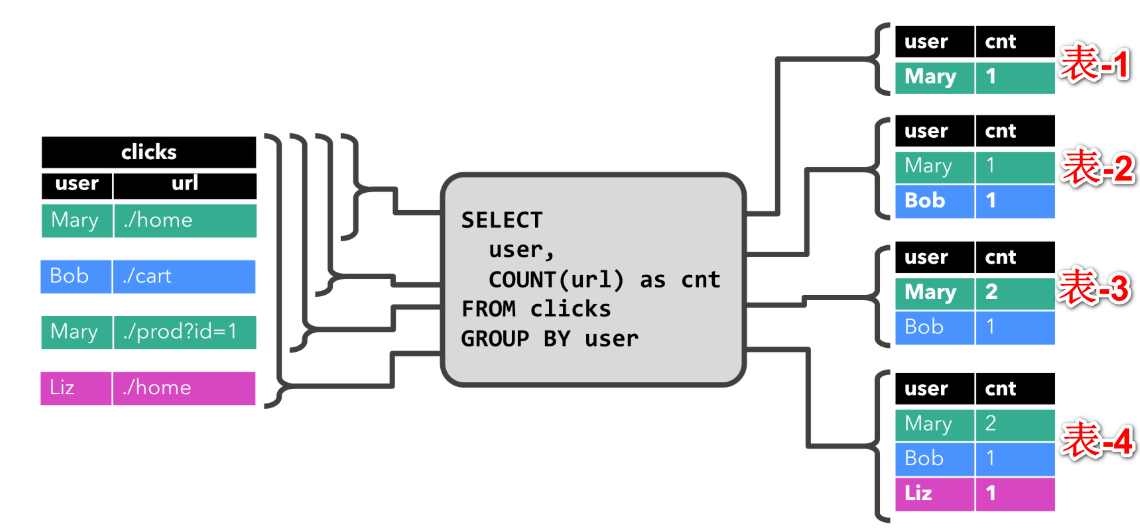
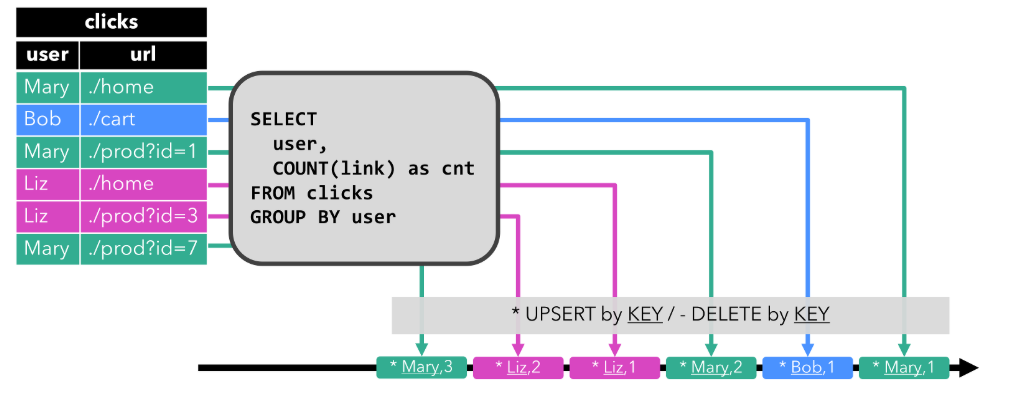
1)简单的GROUP-BY Count聚合查询
下图中,左边是输入表click,是随着时间updata增加的,右边是查询的结果表。开始clicks表中只有一条数据[Mary, ./home]时其结果表是表-1,当clicks表中新增一条数据[Bob, ./cart]时,其结果表是表-2,依次下推。每一条新数据的到来会对之前表行进update或INSERT操作,SQL语句就会根据现有数据更新的结果表。
2)带有窗口(window)的聚合查询
窗口的时间间隔是1个小时,窗口-1对应的时表-1,窗口-2对应的时表-2,依次类推。和第一种查询不一样的是,每一张时表只是统计对应窗口的数据,之前窗口的数据对其没有影响,对不同窗口的查询结果是以追加的形式写入result表中的。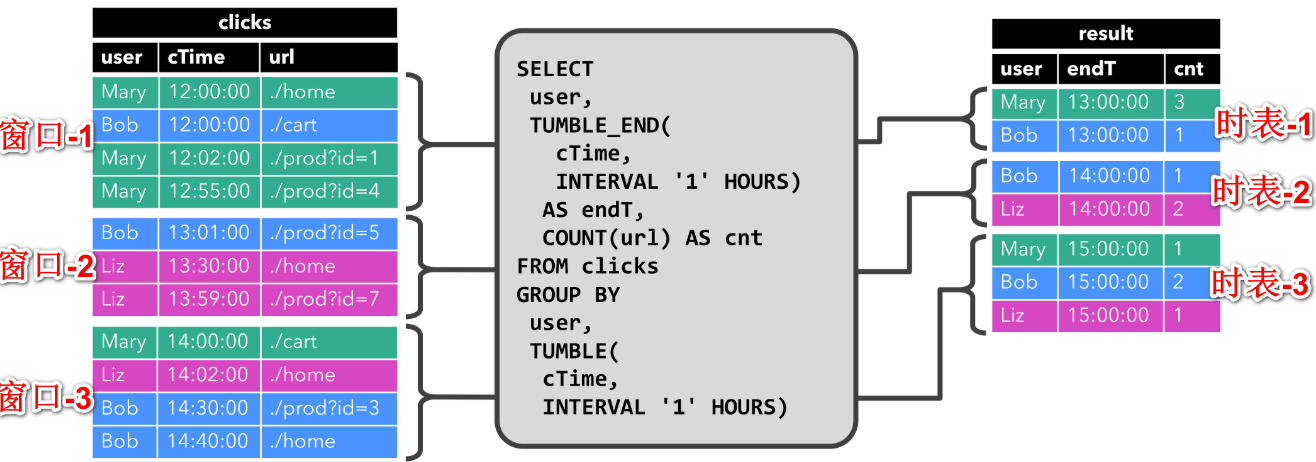
2.3 Update和Append查询
2.2中的两种例子分别对应的两种查询方式,
1)例子1对应着Update查询,这种方式需要更新之前已经发出的结果,包括INSERT和UPDATE两种改变。改变之前已经发出的结果意味着,这种查询需要维护更多的状态(state)数据;
2)例子2对应着Append查询,这种方式查询的结果都是以追加的形式加入到result表中,仅包含INSERT操作。这种方式生成的表和update生成的表转换成流的方式不一样(见下文)。
2.4 Restrictions查询
对于有些SQL查询会因需要保留的state多大或重新计算已发出的记录用来更新的代价太大而得不偿失。
1)state size:例如下面的SQL,在连续查询中,当一条新的消息到来时,为了更新之前已发出的结果(联想2.2中例1),需要保存之前的计算结果即state。当时当连续查询持续很长时间时,需要保存的state的容量会很大,且随着时间的递增会越来越大,更糟糕的是若不断有新用户(分配不同的username)加入,其要保存的count会随着时间更加恐怖,最后有可能导致任务失败。
SELECT user, COUNT(url) FROM clicks GROUP BY user;
2)computing updates:例如下面的SQL,当clicks表新增一条记录,为计算rank,需要对之前所有的重新计算和更新已发出结果的中很大一部分,一条记录的的增加,有可能导致很多user的rank变化。
SELECT user, RANK() OVER (ORDER BY lastLogin)
FROM (
SELECT user, MAX(cTime) AS lastAction FROM clicks GROUP BY user
);
3)查询配置(链接[3])
在常见的场景中,对长期的运行的job做连续查询,为了防止保存的state过大超出存储而任务失败,可能会对state的大小做一定限制即删除state。但这种方式可能引发另一个问题——查询出来的结果可能不准确。Flink Table API和SQL中提供查询参数试图在准确性和资源消耗中找到一个平衡点。
Idle State Retention Time含义是state的key在被删除之前多长时间没有被更新,即没有被更新state的保存时间。使用方式如下:
StreamQueryConfig qConfig = ... // set idle state retention time: min = 12 hours, max = 24 hours
qConfig.withIdleStateRetentionTime(Time.hours(12), Time.hours(24));
3、Table到流的转换
可以通过INSERT、UPDATE、DELETE像修改常规表一样去改变动态表。将动态表转换为流或将其写入外部系统时,需要对这些更改进行encode。 Flink的Table API和SQL支持三种encode改变动态表的方法:
1)Append-only Stream(仅追加流):仅通过INSERT操作得到的动态表可以发射插入行来转换为流(联想2.2中例2),这种方式转换的流中数据都是片段性的,一个片段代表一个窗口;
2)Retract Stream(回溯流):restract stream有两种消息:添加(add)消息和回溯(retract)消息。将动态表转换为回溯(retract)流,通过将INSERT更改encode为添加消息,将DELETE更改encode为回溯消息,将UPDATE更改endcode为更新(上一个)行的回溯消息以及添加消息更新新的行 。 下图显示了动态表到回溯流的转换。
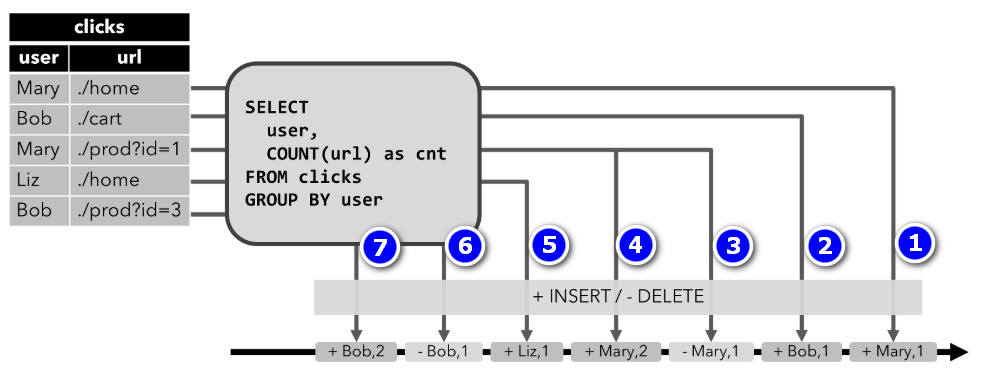
流上每条消息都有一个标识位,其中+标识INSERT操作,-标识DELETE操作。在clicks表中第一、二行消息[Mary, ./home]和[Bob, ./cat]被转换为流中1第、2条消息,当clicks表中第三行[Mary, ./prod?id=1]转换时,会先将已发出的第1条信息标记为DELETE告诉下游,然后第4条消息重新插入user为Mary的消息,依次类推,这样可以保证输出结果的正确性。
3)Upsert Stream(上插流):Upsert流包括upsert消息和删除消息。 动态表要转换为upsert流需要(可能是复合的)唯一键。 通过将INSERT和UPDATE 操作encode为upsert消息,并将DELETE更改encode为删除消息,可以是具有唯一键的动态表转换为流。 流运算需要知道唯一键属性才能正确应用消息。 与回溯流的主要区别在于UPDATE使用单个消息((主键))进行编码,因此更有效。
(个人理解待验证)Upsert流和Retract流的区别在于数据存在第三方系统中时,前者可能存在重复数据,后者没有。
NOTE:在将动态表(dynamic table)转换为数据流(Data Stream)时,仅支持append和retract两种方式。
Ref:
[2]http://www.itdks.com/Course/detail?id=13213&from=search
Flink原理(七)——动态表(Dynamic tables)的更多相关文章
- Flink:动态表上的连续查询
用SQL分析数据流 越来越多的公司在采用流处理技术,并将现有的批处理应用程序迁移到流处理或者为新的应用设计流处理方案.其中许多应用程序专注于分析流数据.分析的数据流来源广泛,如数据库交易,点击,传感器 ...
- 【翻译】Flink Table Api & SQL —Streaming 概念 ——动态表
本文翻译自官网:Flink Table Api & SQL 动态表 https://ci.apache.org/projects/flink/flink-docs-release-1.9/de ...
- Tableview中Dynamic Prototypes动态表的使用
Tableview时IOS中应用非常广泛的控件,当需要动态的添加多条不同的数据时,需要用动态表来实现,下面给出一个小例子,适用于不确定Section的数目,并且每个Section中的行数也不同的情况, ...
- Angular动态表单生成(七)
动态表单生成之拖拽生成表单(上) 这个功能就比较吊炸天了,之前的六篇,都是ng-dynamic-forms自带的功能,可能很多的说明官方的文档都已经写了,我只是个搬运工,而在这篇文章中,我将化身一个工 ...
- SpringBoot与MybatisPlus3.X整合之动态表名 SQL 解析器(七)
pom.xml <dependencies> <dependency> <groupId>org.springframework.boot</groupId& ...
- MySQL常用的七种表类型(转)
MySQL常用的七种表类型(转) 其实MySQL提供的表类型截至到今天已经有13种,各有各的好处,但是民间流传的常用的应该是7种,如果再细化出来,基本上就只有两种:InnoDB.MyIASM两种. ...
- C#编程(七十)----------dynamic类型
原文链接 : http://blog.csdn.net/shanyongxu/article/details/47296033 dynamic类型 C#新增了dynamic关键字,正是因为这一个小小的 ...
- Angular动态表单生成(八)
动态表单生成之拖拽生成表单(下) 我们的动态表单,最终要实现的效果与Form.io的在线生成表单的效果类似,可以参考它的demo地址:https://codepen.io/travist/full/x ...
- Asp.Net SignalR 使用记录 技术回炉重造-总纲 动态类型dynamic转换为特定类型T的方案 通过对象方法获取委托_C#反射获取委托_ .net core入门-跨域访问配置
Asp.Net SignalR 使用记录 工作上遇到一个推送消息的功能的实现.本着面向百度编程的思想.网上百度了一大堆.主要的实现方式是原生的WebSocket,和SignalR,再次写一个关于A ...
随机推荐
- Ubuntu安装FreeSWITCH亲测
本人在安装FreeSWITCH的时候遇到了相当多的坑,网上很多方法都模棱两可,经常装失败,最后终于装成功后做一下总结 最顺利的安装方式 1. 下载压缩文件 下载地址:http://files.free ...
- 使用协方差矩阵的特征向量PCA来处理数据降维
取2维特征,方便图形展示 import matplotlib.pyplot as plt from sklearn.decomposition import PCA from sklearn.data ...
- Java通过行为参数化传递代码
在软件工程中,一个众所周知的问题就是,不管做什么,用户的需求肯定会变.如何应对这样不断变化的需求?理想的状态下,应该把的工作量降到最少.此外,类似的新功能实现起来还应该很简单,而且易于长期维护.行为参 ...
- Ubuntu安装sysv-rc-conf配置开机启动服务
ubuntu下chkconfig的替代方案: 第一步:在终端键入sudo apt-get install sysv-rc-conf安装sysv-rc-conf服务. 第二步:检查设置系统开机自启动服务 ...
- elasticsearch 管理常用命令集合
elasticsearch rest api遵循的格式为: curl -X<REST Verb> <Node>:<Port>/<Index>/<T ...
- 从一个案例窥探ORACLE的PASSWORD_VERSIONS
1.环境说明 ORACLE 客户端版本 11.2.0.1 ORACLE 服务端版本 12.2.0.1 2.异常现象 客户端(下文也称为Cp)访问服务端(Sp),报了一个错误: Figure 1 以错误 ...
- 第07组 Beta冲刺(2/4)
队名:秃头小队 组长博客 作业博客 组长徐俊杰 过去两天完成的任务:学习了很多东西 Github签入记录 接下来的计划:继续学习 还剩下哪些任务:后端部分 燃尽图 遇到的困难:自己太菜了 收获和疑问: ...
- 【LeetCode】整数反转【不能借助辅助空间,需要处理溢出】
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转. 示例 1: 输入: 123 输出: 321 示例 2: 输入: -123 输出: -321 示例 3: 输入: 120 输出: ...
- Python-13-模块和包
一.模块的概念 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代 ...
- SVN:修改文件后提示感叹号消失了处理办法
使用SVN发现文件修改后,默认的修改标记红色感叹号不见了 重新显示设置方法: [右键]——[TortoiseSVN]——[Setting] 在[Icon Overlays]中选择[Default]即可 ...