使用XDocReport将HTML格式数据转换为Word
文档地址:https://github.com/opensagres/xdocreport/wiki/DocxReportingQuickStart
本文采用XDocReport集合Freemaiker进行处理
1. 引入Maven依赖:
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>xdocreport</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.0</version>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.23</version>
</dependency>
2. 创建Word模版
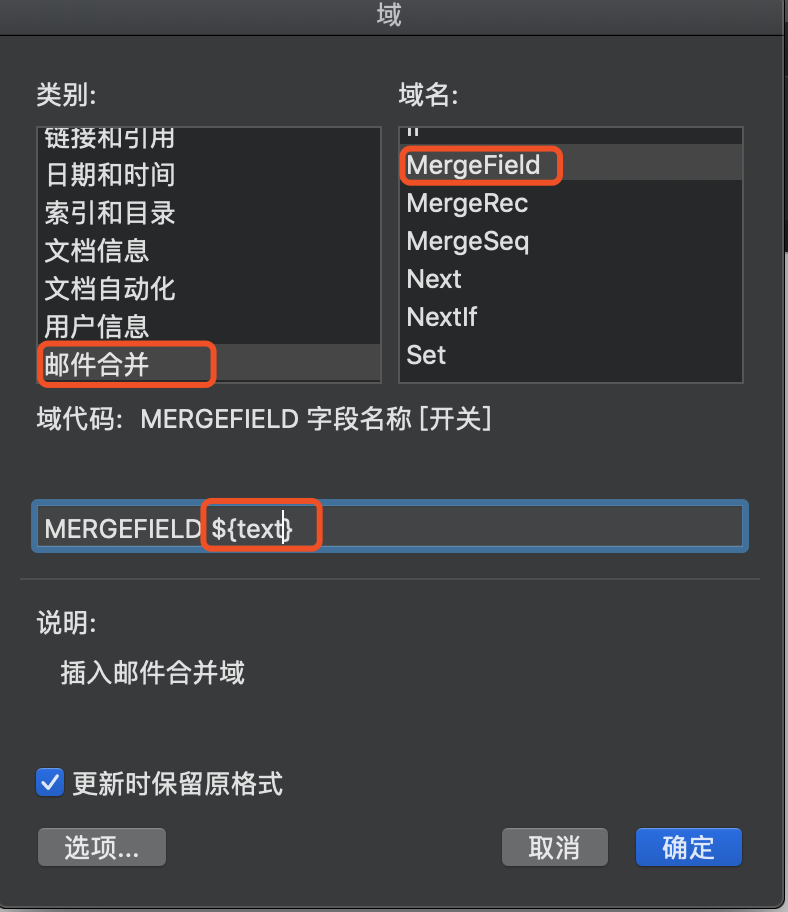
新建Word,在光标处通过快捷键Ctrl+F9 或 工具栏“插入”->“文档部件或文本”->“域”
根据电脑系统不同出现的界面不同,但内容都差不多,${text} 这个text就是后期要替换的变量了。
3. Java代码处理逻辑
String templateFilePath = request.getSession().getServletContext().getRealPath("/WEB-INF/templates/freemarkerTest.docx");
File file = new File(templateFilePath);
InputStream in = new FileInputStream(file);
IXDocReport report;
String targetPath = basePath + lawDownDto.getLawsName() + ".docx";
try {
report = XDocReportRegistry.getRegistry().loadReport(in, TemplateEngineKind.Freemarker);
// 设置内容为HTML格式
FieldsMetadata metadata = report.createFieldsMetadata();
metadata.addFieldAsTextStyling("text", SyntaxKind.Html);
// 创建内容-text为模版中对应都变量名称
IContext context = report.createContext();
context.put("text", content);
// 生成文件
OutputStream out = new FileOutputStream(targetPath);
report.process(context, out);
} catch (XDocReportException e) {
e.printStackTrace();
}
文件下载:在生成文件逻辑后创建读取流返回即可。
=============================================================
如果文件中有图片需要处理:
图片方案一:单个图片且位置固定,可通过XDocReport配置模版处理
图片方案二:多个图片且位置不固定,可通过POI结合Freemarker进行处理
图片方案一:
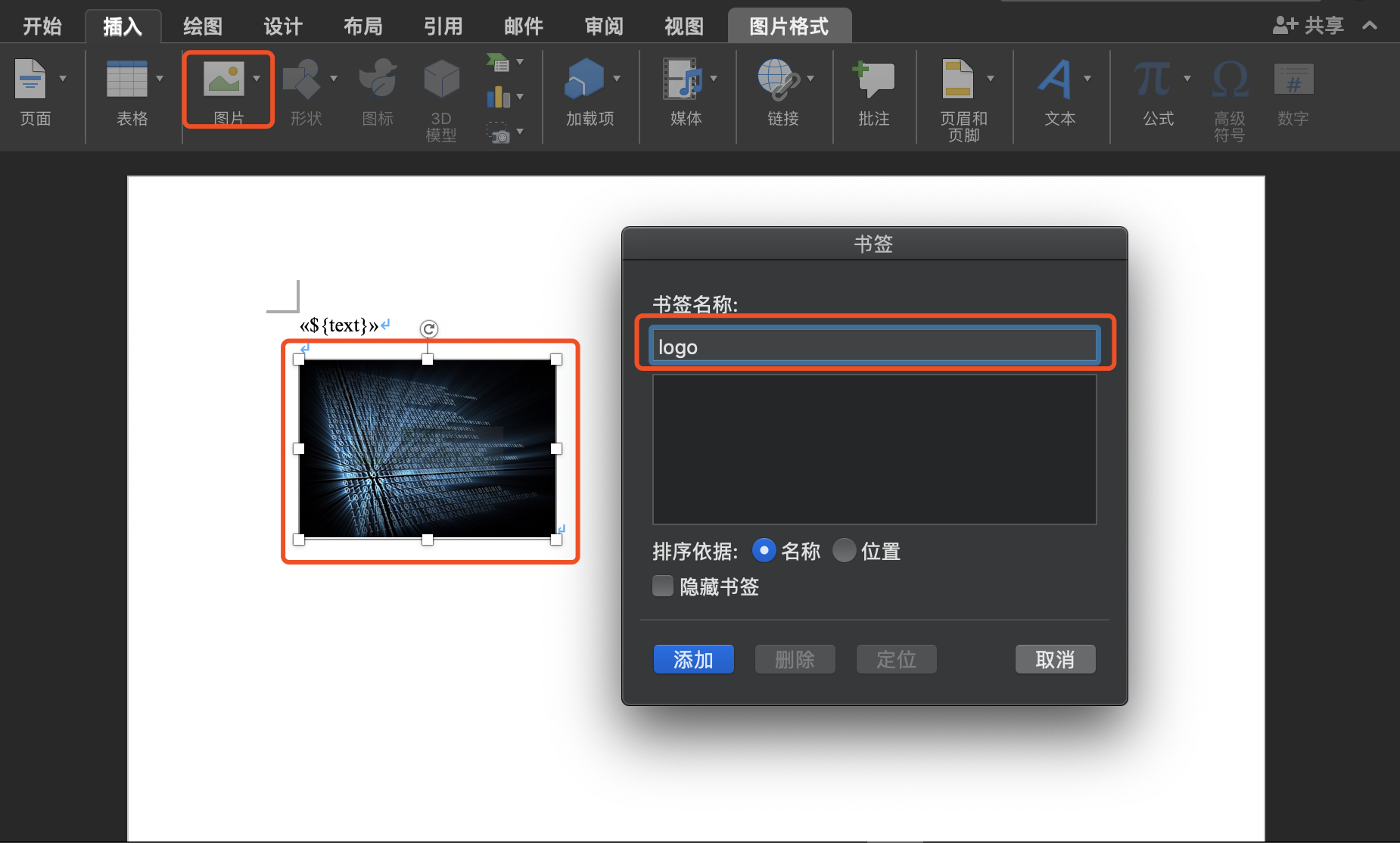
1. 在模版中插入临时图片,选中图片并添加“书签”,书签名称是后续作为替换的变量
2. 代码中追加逻辑
在上面代码10后追加
// logo为模版中标签名称
metadata.addFieldAsImage("logo");
report.setFieldsMetadata(metadata);
在上面代码14行后追加
// IImageProvider可通过3种方式创建(File/IO流/ClassPath下文件)具体可参考顶部文档-Dynamic Image
IImageProvider logo = new FileImageProvider(new File("1950737_195902644.png"));
context.put("logo", logo);
图片方案二:
1. 在上面读取模版之前进行数据替换
// 处理文本中的图片,使用imgReplace变量替换
Map<String, Object> param = new HashMap<String, Object>();
if (StringUtils.isNotBlank(content)) {
content = HtmlUtils.htmlUnescape(content);
List<HashMap<String, String>> imgs = getImgStrContent(content);
int count = 0;
for (HashMap<String, String> img : imgs) {
count++;
//处理替换以“/>”结尾的img标签
content = content.replace(img.get("img"), "${imgReplace" + count + "}");
//处理替换以“>”结尾的img标签
content = content.replace(img.get("img1"), "${imgReplace" + count + "}");
Map<String, Object> header = new HashMap<String, Object>();
String result = "";
result = img.get("src");
//如果没有宽高属性,默认设置为
if(img.get("width") == null || img.get("height") == null) {
header.put("width", 150);
header.put("height", 150);
}else {
header.put("width", (int)(Double.parseDouble(img.get("width"))));
header.put("height", (int) (Double.parseDouble(img.get("height"))));
}
if( StringUtils.isNotBlank(result) ){
String type1 = result.substring(result.lastIndexOf(".") , result.length());
header.put("type", type1);
header.put("content",this.imageToInputStream(result));
}
param.put("${imgReplace" + count + "}", header);
}
}
//获取html中的图片元素信息
private List<HashMap<String, String>> getImgStrContent(String htmlStr) {
List<HashMap<String, String>> pics = new ArrayList<HashMap<String, String>>();
Document doc = Jsoup.parse(htmlStr);
if( doc != null ){
Elements imgs = doc.select("img");
if( imgs != null && imgs.size() > 0 ){
for (Element img : imgs) {
HashMap<String, String> map = new HashMap<String, String>();
if(!"".equals(img.attr("width"))) {
map.put("width", img.attr("width"));
}
if(!"".equals(img.attr("height"))) {
map.put("height", img.attr("height"));
}
map.put("img", img.toString().substring(0, img.toString().length() - 1) + "/>");
map.put("img1", img.toString());
map.put("src", img.attr("src"));
pics.add(map);
}
}
}
return pics;
}
// 读取生成的文件
readStream = new FileInputStream(targetPath);
ByteArrayOutputStream docxOs = new ByteArrayOutputStream();
int b = 0;
byte[] buf = new byte[1024];
while ((b = readStream.read(buf)) != -1) {
docxOs.write(buf, 0, b);
}
docxResponseStream = new ByteArrayInputStream(docxOs.toByteArray());
// 创建word 对象
XWPFDocument document = new XWPFDocument(docxResponseStream);
newOS = new ByteArrayOutputStream();
if (document != null && param != null) {
// 生成带图片的word(如需工具类请给我发邮件)
XWPFDocument customXWPFDocument = WordUtil.getWord(param, document);
// 设置表格边框样式(另外一片文章会介绍)
// List<XWPFTable> list = formatTableBorder(customXWPFDocument);
// 处理合并单元格(另外一片文章会介绍)
// mergeCell(content, list);
// 写入输出流返回
customXWPFDocument.write(newOS);
document.close();
customXWPFDocument.close();
resultInpu = new ByteArrayInputStream(newOS.toByteArray());
}else{
resultInpu = docxResponseStream;
}
以上内容即可完成Word中多图片的动态展示。
后续会写处理表格边框、单元格合并及段落都相关内容。
使用XDocReport将HTML格式数据转换为Word的更多相关文章
- Python将JSON格式数据转换为SQL语句以便导入MySQL数据库
前文中我们把网络爬虫爬取的数据保存为JSON格式,但为了能够更方便地处理数据.我们希望把这些数据导入到MySQL数据库中.phpMyadmin能够把MySQL数据库中的数据导出为JSON格式文件,但却 ...
- tensorflow学习笔记(10) mnist格式数据转换为TFrecords
本程序 (1)mnist的图片转换成TFrecords格式 (2) 读取TFrecords格式 # coding:utf-8 # 将MNIST输入数据转化为TFRecord的格式 # http://b ...
- 将JSON格式数据转换为javascript对象 JSON.parse()
<html><body><h2>通过 JSON 字符串来创建对象</h3><p>First Name: <span id=" ...
- Java导出带格式的Excel数据到Word表格
前言 在Word中创建报告时,我们经常会遇到这样的情况:我们需要将数据从Excel中复制和粘贴到Word中,这样读者就可以直接在Word中浏览数据,而不用打开Excel文档.在本文中,您将学习如何使用 ...
- 记录几种有关libsvm格式数据的list和dict用法
# list元素求和 sum = reduce(lambda x,y: x+y, mylist) # 比较两个 lists 的元素是否完全一致 if all(x==y for x, y in zip( ...
- CAJ Viewer安装流程以及CAJ或Pdf转换为Word格式
不多说,直接上干货! pdf转word格式,最简单的就是,实用工具 Adobe Acrobat DC 首先声明的是,将CAJ或者Pdf转换成Word文档,包括里面的文字.图片以及格式,根本不需 ...
- java 导出数据为word文档(保持模板格式)
导出数据到具体的word文档里面,word有一定的格式,需要保持不变 这里使用freemarker来实现: ①:设计好word文档格式,需要用数据填充的地方用便于识别的长字符串替换 如 aaaaa ...
- C# 将PDF文件转换为word格式
Pdf(Portable Document Format)意为“便携式文档格式”,是现在最流行的文件格式之一,它有很多优点如:尺寸较小.阅读方便.操作系统平台通用等,非常适合在网络上传播和使用.如今在 ...
- 数据转换为json格式的方法
数据转换为json格式: 如果一张表中存在主外键关系,模板自动生成的类是不可以转换成JSON格式的,此时需要重新写一个类,类前面需加[DataContract],字段前需加[DataMember],实 ...
随机推荐
- day5_configparser模块
第一种情况:# 配置文件baidu.ini和当前文件在同一级目录: import configparser conf_read = configparser.ConfigParser() conf_r ...
- python27期day10:函数的动态参数、函数的注释、函数的名称空间、函数的嵌套、global(修改全局的)、nonlocal(修改局部的)、函数名的第一类对象及使用、作业题。
1.动态参数的作用: 能够接收不固定长度参数 位置参数过多时可以使用动态参数 * args是程序员之间约定俗称(可以更换但是不建议更换) * args获取的是一个元组 ** kwargs获取的是一个字 ...
- 如何使用 aph-cli 搭建本地静态开发环境(server + proxy + mock)
前提资源 1.aph系统使用说明 2.aph-cli 使用说明 ================================== 一.如何使用aph-cli简单起一个服务 1.在APH管理系统注册 ...
- Vue (表单、斗篷、条件、循环指令,分隔符成员、计算属性成员、属性的监听、vue组件、子组件、各个常见的钩子函数)
表单指令 <!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF- ...
- BERT
推出一个半月,斯坦福SQuAD问答榜单前六名都在使用BERT BERT 成为了你做 NLP 时不得不用的模型了……吗? 今日,机器之心小编在刷 Twitter 时,发现斯坦福自然语言处理组的官方账 ...
- 论文阅读笔记五十七:FCOS: Fully Convolutional One-Stage Object Detection(CVPR2019)
论文原址:https://arxiv.org/abs/1904.01355 github: tinyurl.com/FCOSv1 摘要 本文提出了一个基于全卷积的单阶段检测网络,类似于语义分割,针对每 ...
- 了解html
什么是html? html:Hyper Text Markup Language(超文本标记语言) 纯文本:只能存储一些简单的字符(不能插入图片.视频...) 注意:html不是一种编程语言(它没有任 ...
- node fs相对路径
如果在js里面使用了node.js的fs,在传入path参数时,如果使用相对路径,按照根目录的层级就是用就好. 比如:目录结构为: a -b -c -c1.js d 在c1.js中调用时,如果需要使用 ...
- python之路—从入门到放弃
python基础部分 函数 初识函数 函数进阶 装饰器函数 迭代器和生成器 内置函数和匿名函数 递归函数 常用模块 常用模块 模块和包 面向对象 初识面向对象 面向对象进阶 网络编程 网络编程 并发编 ...
- treegrid 表格树
treegrid 实现表格树的结构 效果图: 第一步:页面布局 <div class="col-sm-12 select-table table-striped" styl ...