python27期day16:序列化、json、pickle、hashlib、collections、软件开发规范、作业。
序列化模块:
什么是序列化呢? 序列化的本质就是将一种数据结构(如字典、列表)等转换成一个特殊的序列(字符串或者bytes)的过程就叫做序列化。
将这个字典直接写入文件是不可以的,必须转化成字符串的形式,而且你读取出来也是字符串形式的字典(可以用代码展示)。
json序列化除了可以解决写入文件的问题,还可以解决网络传输的问题,比如你将一个list数据结构通过网络传给另个开发者,那么你不可以直接传输,之前我们说过,你要想传输出去必须用bytes类型。但是bytes类型只能与字符串类型互相转化,它不能与其他数据结构直接转化,所以,你只能将list ---> 字符串 ---> bytes 然后发送,对方收到之后,在decode() 解码成原字符串。此时这个字符串不能是我们之前学过的str那种字符串,因为它不能反解,必须要是这个特殊的字符串,他可以反解成list 这样开发者之间就可以借助网络互传数据了,不仅仅是开发者之间,你要借助网络爬取数据这些数据多半是这种特殊的字符串,你接受到之后,在反解成你需要的数据类型。
序列化模块就是将一个常见的数据结构转化成一个特殊的序列,并且这个特殊的序列还可以反解回去。它的主要用途:文件读写数据,网络传输数据。
不同语言都遵循的一种数据转化格式,即不同语言都使用的特殊字符串。(比如Python的一个列表[1, 2, 3]利用json转化成特殊的字符串,然后在编码成bytes发送给php的开发者,php的开发者就可以解码成特殊的字符串,然后在反解成原数组(列表): [1, 2, 3])
json序列化只支持部分Python数据结构:dict,list, tuple,str,int, float,True,False,None
支持Python所有的数据类型包括实例化对象。
json模块是将满足条件的数据结构转化成特殊的字符串,并且也可以反序列化还原回去。
序列化模块总共只有两种用法,要不就是用于网络传输的中间环节,要不就是文件存储的中间环节,所以json模块总共就有两对四个方法:
json模块:
用于网络传输:dumps、loads
用于文件写读:dump、load
dumps、loads:
1、将字典类型转换成字符串类型:
import json
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic)
结果:<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"} #注意,json转换完的字符串类型的字典中的字符串是由""表示的2、将字符串类型的字典转换成字典类型用loads:
import json
dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2)
结果:<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
3、还支持列表类型:
list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic)
结果:<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2)
结果:<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
dump、load:
1、将对象转换成字符串写入到文件当中:
import json
f = open('json_file.json','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
# json文件也是文件,就是专门存储json字符串的文件。
2、将文件中的字符串类型的字典转换成字典:
import json
f = open('json_file.json')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
3、其他参数说明:
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(,,:);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
sort_keys:将数据根据keys的值进行排序。 剩下的自己看源码研究
4、json序列化存储多个数据到同一个文件中:
对于json序列化,存储多个数据到一个文件中是有问题的,默认一个json文件只能存储一个json数据,但是也可以解决,举例说明:
对于json 存储多个数据到文件中:
dic1 = {'name':'oldboy1'}
dic2 = {'name':'oldboy2'}
dic3 = {'name':'oldboy3'}
f = open('序列化',encoding='utf-8',mode='a')
json.dump(dic1,f)
json.dump(dic2,f)
json.dump(dic3,f)
f.close()
f = open('序列化',encoding='utf-8')
ret = json.load(f)
ret1 = json.load(f)
ret2 = json.load(f)
print(ret)
上边的代码会报错,解决方法:
dic1 = {'name':'oldboy1'}
dic2 = {'name':'oldboy2'}
dic3 = {'name':'oldboy3'}
f = open('序列化',encoding='utf-8',mode='a')
str1 = json.dumps(dic1)
f.write(str1+'\n')
str2 = json.dumps(dic2)
f.write(str2+'\n')
str3 = json.dumps(dic3)
f.write(str3+'\n')
f.close()f = open('序列化',encoding='utf-8')
for line in f:
print(json.loads(line))pickle模块:
只能是Python语言遵循的一种数据转化格式,只能在python语言中使用。
pickle模块是将Python所有的数据结构以及对象等转化成bytes类型,然后还可以反序列化还原回去。
刚才也跟大家提到了pickle模块,pickle模块是只能Python语言识别的序列化模块。如果把序列化模块比喻成全世界公认的一种交流语言,也就是标准的话,json就是像是英语,全世界(python,java,php,C,等等)都遵循这个标准。而pickle就是中文,只有中国人(python)作为第一交流语言。
既然只是Python语言使用,那么它支持Python所有的数据类型包括后面我们要讲的实例化对象等,它能将这些所有的数据结构序列化成特殊的bytes,然后还可以反序列化还原。使用上与json几乎差不多,也是两对四个方法。
用于网络传输:dumps、loads
用于文件写读:dump、load
dumps、loads:
import pickle
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) # bytes类型
dic2 = pickle.loads(str_dic)
print(dic2) #字典
# 还可以序列化对象
import pickle
def func():
print(666)
ret = pickle.dumps(func)
print(ret,type(ret)) # b'\x80\x03c__main__\nfunc\nq\x00.' <class 'bytes'>
f1 = pickle.loads(ret) # f1得到 func函数的内存地址
f1() # 执行func函数
dump、load:
dic = {(1,2):'oldboy',1:True,'set':{1,2,3}}
f = open('pick序列化',mode='wb')
pickle.dump(dic,f)
f.close()
with open('pick序列化',mode='wb') as f1:
pickle.dump(dic,f1)
pickle序列化存储多个数据到一个文件中:
dic1 = {'name':'oldboy1'}
dic2 = {'name':'oldboy2'}
dic3 = {'name':'oldboy3'}
f = open('pick多数据',mode='wb')
pickle.dump(dic1,f)
pickle.dump(dic2,f)
pickle.dump(dic3,f)
f.close()
f = open('pick多数据',mode='rb')
while True:
try:
print(pickle.load(f))
except EOFError:
break
f.close()
这时候机智的你又要说了,既然pickle如此强大,为什么还要学json呢?这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块,但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle。
shelve模块
shelve模块:类似于字典的操作方式去操作特殊的字符串(不讲,可以课下了解)。
#1、将字典放入文本
import shelve
f = shelve.open(r"shelve")
f["stul_info"] = {"name":"alex","age":"18"}
f.close()
# dic = {}
# dic["name"] = "alvin"
# dic["info"] = {"name":"alex"}
XML模块
#1、用getroot打印根节点
import xml.etree.ElementTree as ET #as后面的ET代指前面模块的名字
tree = ET.parse("xml_lesson.xml") #用ET里面的parse方法并赋予对象tree、
root = tree.getroot()
print(root.tag)
#2、遍历xml文档
for i in root:
print(i)
#3、遍历属性tag
for i in root:
print(i.tag)
#4、双层循环遍历
for i in root:
for j in i:
print(j.tag)
#5、看值attrib属性组成键值对
for i in root :
print(i.attrib)
#6、遍历打印子元素
for i in root:
for j in i:
print(j.attrib)
#7、text
for i in root:
for j in i:
print(j.text)
re正则模块
import re
#1、找到以a开头和l结尾的
s = "hellocdalexfdsfdsfdsf"
print(s.find("alex"))
#2、371481198506143635(alex身份证号)
print(re.findall("\d+","alex22ccsd45vcxvcx767bvcbcv876"))
#3、findall(匹配规则+内容)
print(re.findall("alex","afdsvcxvfsg"))
#4、a..x(代表以a开头中间任意两个字符以x结尾的
print(re.findall("a..x","affxcvcvsdf"))
#5、^尖角号代表以什么开头
print(re.findall("^a..c","acxcxacxcx"))
#6、$代表以什么结尾
print(re.findall("a..x$","acxvfsdfsdarrx"))
#7、*代表0到无穷次
print(re.findall("d*","dfdsfdsfdsadsadddddddddvcxvxc"))
#8、?
#9、{}为范围取
#10、[]中括号字符集
#11、(小括号
print(re.findall("\([^()]*\)","12 + (34 * 6 + 2 - 5*(2-1)"))
#12\d
#13\D
#14、|管道符代表或的意思
print(re.findall(r"ka|b","sdjkbsf"))
print(re.findall(r"ka|b","sdjkabsf"))
print(re.findall(r"ka|bc","sdjkabcsf"))
#15、d+
print(re.sub("\d+","A","fdsfdsfjaskd4324vcxvxc"))
#16、加参数
print(re.subn("\d","A","jackcxcvsdfd4343543543vcxvxcavcxvxd543534fdfds",8))
#17、
loging日志模块
#1、日志级别
import logging
#2、增加参数
# logging.basicConfig(
# level=logging.DEBUG,
# filename="logger.log",
# filename="w" #模式是追加
# )
# logging.debug("debug message")
# logging.info("info message")
# logging.warning("warning message")
# logging.error("error message")
# logging.critical("critical message")
#3、
import configparser
config = configparser.ConfigParser() #用configparser模块里面的ConfigParser类生成config对象
config["DEFAULT"] = {"ServerAliveInterval" : "45", #键值对
"Compression": "yes",
"CompressionLevel" : "9"} config["bitbucket.org"] = {}
config["bitbucket.org"]["User"] = "hg"
config["topsecret.server.com"] = {}
topsecret = config["topsecret.server.com"]
topsecret["Host Port"] = "50022"
topsecret["ForwardXll"] = "no"
config["DEFAULT"]["ForwardXll"] = "yes"
with open("example.ini","w") as configfile:
config.write(configfile)
hashlib哈希模块:
hashlib的特征以及使用要点:
1、bytes类型数据 ---> 通过hashlib算法 ---> 固定长度的字符串
2、不同的bytes类型数据转化成的结果一定不同。
3、相同的bytes类型数据转化成的结果一定相同。
4、此转化过程不可逆。
hashlib模块就相当于一个算法的集合,这里面包含着很多的算法,算法越高,转化成的结果越复杂,安全程度越高,相应的效率就会越低。
普通加密:
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update('123456'.encode('utf-8')) # 必须是bytes类型才能够进行加密
print(md5.hexdigest())
# 计算结果如下:
'e10adc3949ba59abbe56e057f20f883e'
# 验证:相同的bytes数据转化的结果一定相同
import hashlib
md5 = hashlib.md5()
md5.update('123456'.encode('utf-8'))
print(md5.hexdigest())
# 计算结果如下:
'e10adc3949ba59abbe56e057f20f883e'
# 验证:不相同的bytes数据转化的结果一定不相同
import hashlib
md5 = hashlib.md5()
md5.update('12345'.encode('utf-8'))
print(md5.hexdigest())
# 计算结果如下:
'827ccb0eea8a706c4c34a16891f84e7b'
固定加盐:
ret = hashlib.md5('xx教育'.encode('utf-8')) # xx教育就是固定的盐
ret.update('a'.encode('utf-8'))
print(ret.hexdigest())
结果:d9e8fff14a026ecefa7d700334279762
动态加盐:
username = '宝元666'
ret = hashlib.md5(username[::2].encode('utf-8')) # 针对于每个账户,每个账户的盐都不一样
ret.update('a'.encode('utf-8'))
print(ret.hexdigest())
sha系列:sha1,sha224,sha512等等,数字越大,加密的方法越复杂,安全性越高,但是效率就会越慢。
ret = hashlib.sha1()
ret.update('guobaoyuan'.encode('utf-8'))
print(ret.hexdigest())
#也可加盐
ret = hashlib.sha384(b'asfdsa')
ret.update('guobaoyuan'.encode('utf-8'))
print(ret.hexdigest())
# 也可以加动态的盐
ret = hashlib.sha384(b'asfdsa'[::2])
ret.update('guobaoyuan'.encode('utf-8'))
print(ret.hexdigest())
文件的一致性校验:
hashlib模块除了可以用于密码加密之外,还有一个常用的功能,那就是文件的一致性校验。linux讲究:一切皆文件,我们普通的文件,是文件,视频,音频,图片,以及应用程序等都是文件。我们都从网上下载过资源,比如我们刚开学时让大家从网上下载Python解释器,当时你可能没有注意过,其实你下载的时候都是带一个MD5或者shax值的,为什么? 我们的网络世界是很不安全的,经常会遇到病毒,木马等,有些你是看不到的可能就植入了你的电脑中,那么他们是怎么来的? 都是通过网络传入来的,就是你在网上下载一些资源的时候,趁虚而入,当然大部分被我们的浏览器或者杀毒软件拦截了,但是还有一部分偷偷的进入你的磁盘中了。那么我们自己如何验证我们下载的资源是否有病毒呢?这就需要文件的一致性校验了。在我们下载一个软件时,往往都带有一个MD5或者shax值,当我们下载完成这个应用程序时你要是对比大小根本看不出什么问题,你应该对比他们的md5值,如果两个md5值相同,就证明这个应用程序是安全的,如果你下载的这个文件的MD5值与服务端给你提供的不同,那么就证明你这个应用程序肯定是植入病毒了(文件损坏的几率很低),那么你就应该赶紧删除,不应该安装此应用程序。
我们之前说过,md5计算的就是bytes类型的数据的转换值,同一个bytes数据用同样的加密方式转化成的结果一定相同,如果不同的bytes数据(即使一个数据只是删除了一个空格)那么用同样的加密方式转化成的结果一定是不同的。所以,hashlib也是验证文件一致性的重要工具。
校验Pyhton解释器的Md5值是否相同:
import hashlib
def file_check(file_path):
with open(file_path,mode='rb') as f1:
sha256 = hashlib.md5()
while 1:
content = f1.read(1024)
if content:
sha256.update(content)
else:
return sha256.hexdigest()
print(file_check('python-3.6.6-amd64.exe'))
socketserver模块:


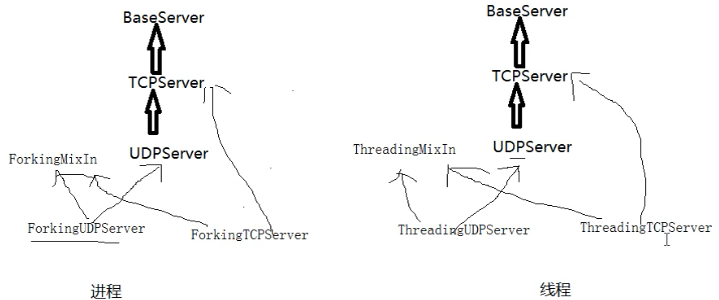
server类:处理链接包含:BaseServer、TcpServer、UdpServer、UnixStreamServer、UnixDatagramServer。
request类:处理通信包含BaseRequestHandler、StreamRequestHandler、DatagramRequestHandler。
对于tcp来说
self.request=conn
对于udp来说
self.request=(client_data_bytes,udp的套接字对象)
collections(收藏)模块:
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict以及判断什么是可迭代对象什么是迭代器
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
namedtuple:
我们知道tuple可以表示不变数据,例如,一个点的二维坐标就可以表示成:
p = (1, 2)但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
这时,namedtuple就派上了用场:
from collections import namedtuple
point = namedtuple("point",["x","y"])
p = point(1,2)
print(p)
结果:point(x=1, y=2)
deque:
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
q.appendleft('y')
print(q)
结果:q deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
OrderedDict:
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict
od = OrderedDict([("a",1),("b",2),("c",3)])
print(od)
结果:OrderedDict([('a', 1), ('b', 2), ('c', 3)])
OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
from collections import OrderedDict
od = OrderedDict([("a",1),("b",2),("c",3)])
od["z"] = 1
od["y"] = 2
od["x"] = 3
print(od.keys())
结果:odict_keys(['a', 'b', 'c', 'z', 'y', 'x'])
defaultdict:
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
from collections import defaultdict
values = [11,22,33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value > 66:
my_dict["k1"].append(value)
else:
my_dict["k2"].append(value)
print(my_dict)
结果:defaultdict(<class 'list'>, {'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]})
Counter:
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
from collections import Counter
c = Counter("dsadasdsfdafsdsfds")
print(c)
结果:Counter({'d': 6, 's': 6, 'a': 3, 'f': 3})
isinstance:
判断当前数据类型,返回的是一个布尔值
from collections import Iterable,Iterator
lst = [1,2,3,4]
print(isinstance(lst,list)) # 判断lst是不是列表类型 返回的是True
print(isinstance(lst,Iterator)) # 判断lst是不是迭代器 返回的是False
print(isinstance(lst,Iterable)) # 判断lst是不是可迭代对象 返回的是True
软件开发规范:
你现在包括之前写的一些程序,所谓的'项目',都是在一个py文件下完成的,代码量撑死也就几百行,你认为没问题,挺好。但是真正的后端开发的项目,系统等,少则几万行代码,多则十几万,几十万行代码,你全都放在一个py文件中行么?当然你可以说,只要能实现功能即可。咱们举个例子,如果你的衣物只有三四件,那么你随便堆在橱柜里,没问题,咋都能找到,也不显得特别乱,但是如果你的衣物,有三四十件的时候,你在都堆在橱柜里,可想而知,你找你穿过三天的袜子,最终从你的大衣口袋里翻出来了,这是什么感觉和心情......
软件开发,规范你的项目目录结构,代码规范,遵循PEP8规范等等,让你更加清晰滴,合理滴开发。
那么接下来我们以博客园系统的作业举例,将我们之前在一个py文件中的所有代码,整合成规范的开发。
首先我们看一下,这个是我们之前的目录结构(简化版):

py文件的具体代码如下:
status_dic = {
'username': None,
'status': False,
}
flag = True
def login():
i = 0
with open('register', encoding='utf-8') as f1:
dic = {i.strip().split('|')[0]: i.strip().split('|')[1] for i in f1}
while i < 3:
username = input('请输入用户名:').strip()
password = input('请输入密码:').strip()
if username in dic and dic[username] == password:
print('登录成功')
return True
else:
print('用户名密码错误,请重新登录')
i += 1
def register():
with open('register', encoding='utf-8') as f1:
dic = {i.strip().split('|')[0]: i.strip().split('|')[1] for i in f1}
while 1:
print('\033[1;45m 欢迎来到注册页面 \033[0m')
username = input('请输入用户名:').strip()
if not username.isalnum():
print('\033[1;31;0m 用户名有非法字符,请重新输入 \033[0m')
continue
if username in dic:
print('\033[1;31;0m 用户名已经存在,请重新输入 \033[0m')
continue
password = input('请输入密码:').strip()
if 6 <= len(password) <= 14:
with open('register', encoding='utf-8', mode='a') as f1:
f1.write(f'\n{username}|{password}')
status_dic['username'] = str(username)
status_dic['status'] = True
print('\033[1;32;0m 恭喜您,注册成功!已帮您成功登录~ \033[0m')
return True
else:
print('\033[1;31;0m 密码长度超出范围,请重新输入 \033[0m')
def auth(func):
def inner(*args, **kwargs):
if status_dic['status']:
ret = func(*args, **kwargs)
return ret
else:
print('\033[1;31;0m 请先进行登录 \033[0m')
if login():
ret = func(*args, **kwargs)
return ret
return inner
@auth
def article():
print(f'\033[1;32;0m 欢迎{status_dic["username"]}访问文章页面\033[0m')
@auth
def diary():
print(f'\033[1;32;0m 欢迎{status_dic["username"]}访问日记页面\033[0m')
@auth
def comment():
print(f'\033[1;32;0m 欢迎{status_dic["username"]}访问评论页面\033[0m')
@auth
def enshrine():
print(f'\033[1;32;0m 欢迎{status_dic["username"]}访问收藏页面\033[0m')
def login_out():
status_dic['username'] = None
status_dic['status'] = False
print('\033[1;32;0m 注销成功 \033[0m')
def exit_program():
global flag
flag = False
return flag
choice_dict = {
1: login,
2: register,
3: article,
4: diary,
5: comment,
6: enshrine,
7: login_out,
8: exit_program,
}
while flag:
print('''
欢迎来到博客园首页
1:请登录
2:请注册
3:文章页面
4:日记页面
5:评论页面
6:收藏页面
7:注销
8:退出程序''')
choice = input('请输入您选择的序号:').strip()
if choice.isdigit():
choice = int(choice)
if 0 < choice <= len(choice_dict):
choice_dict[choice]()
else:
print('\033[1;31;0m 您输入的超出范围,请重新输入 \033[0m')
else:
print('\033[1;31;0m 您您输入的选项有非法字符,请重新输入 \033[0m')
此时我们是将所有的代码都写到了一个py文件中,如果代码量多且都在一个py文件中,那么对于代码结构不清晰,不规范,运行起来效率也会非常低。所以我们接下来一步一步的修改:
- 程序配置.

你项目中所有的有关文件的操作出现几处,都是直接写的register相对路径,如果说这个register注册表路径改变了,或者你改变了register注册表的名称,那么相应的这几处都需要一一更改,这样其实你就是把代码写死了,那么怎么解决? 我要统一相同的路径,也就是统一相同的变量,在文件的最上面写一个变量指向register注册表的路径,代码中如果需要这个路径时,直接引用即可。

- 划分文件

一个项目的函数不能只是这些,我们只是举个例子,这个小作业函数都已经这么多了,那么要是一个具体的实际的项目,函数会非常多,所以我们应该将这些函数进行分类,然后分文件而治。在这里我划分了以下几个文件:
settings.py: 配置文件,就是放置一些项目中需要的静态参数,比如文件路径,数据库配置,软件的默认设置等等
类似于我们作业中的这个:

common.py:公共组件文件,这里面放置一些我们常用的公共组件函数,并不是我们核心逻辑的函数,而更像是服务于整个程序中的公用的插件,程序中需要即调用。比如我们程序中的装饰器auth,有些函数是需要这个装饰器认证的,但是有一些是不需要这个装饰器认证的,它既是何处需要何处调用即可。比如还有密码加密功能,序列化功能,日志功能等这些功能都可以放在这里。

src.py:这个文件主要存放的就是核心逻辑功能,你看你需要进行选择的这些核心功能函数,都应该放在这个文件中。

start.py:项目启动文件。你的项目需要有专门的文件启动,而不是在你的核心逻辑部分进行启动的,有人对这个可能不太理解,我为什么还要设置一个单独的启动文件呢?你看你生活中使用的所有电器基本都一个单独的启动按钮,汽车,热水器,电视,等等等等,那么为什么他们会单独设置一个启动按钮,而不是在一堆线路板或者内部随便找一个地方开启呢? 目的就是放在显眼的位置,方便开启。你想想你的项目这么多py文件,如果src文件也有很多,那么到底哪个文件启动整个项目,你还得一个一个去寻找,太麻烦了,这样我把它单独拿出来,就是方便开启整个项目。
那么我们写的项目开启整个项目的代码就是下面这段:

你把这些放置到一个文件中也可以,但是没有必要,我们只需要一个命令或者一个开启指令就行,就好比我们开启电视只需要让人很快的找到那个按钮即可,对于按钮后面的一些复杂的线路板,我们并不关心,所以我们要将上面这个段代码整合成一个函数,开启项目的''按钮''就是此函数的执行即可。

这个按钮要放到启动文件start.py里面。
除了以上这几个py文件之外还有几个文件,也是非常重要的:
类似于register文件:这个文件文件名不固定,register只是我们项目中用到的注册表,但是这种文件就是存储数据的文件,类似于文本数据库,那么我们一些项目中的数据有的是从数据库中获取的,有些数据就是这种文本数据库中获取的,总之,你的项目中有时会遇到将一些数据存储在文件中,与程序交互的情况,所以我们要单独设置这样的文件。
log文件:log文件顾名思义就是存储log日志的文件。日志我们一会就会讲到,日志主要是供开发人员使用。比如你项目中出现一些bug问题,比如开发人员对服务器做的一些操作都会记录到日志中,以便开发者浏览,查询。
至此,我们将这个作业原来的两个文件,合理的划分成了6个文件,但是还是有问题的,如果我们的项目很大,你的每一个部分相应的你一个文件存不下的,比如你的src主逻辑文件,函数很多,你是不是得分成:src1.py src2.py?
你的文本数据库register这个只是一个注册表,如果你还有个人信息表,记录表呢? 如果是这样,你的整个项目也是非常凌乱的:

3. 划分具体目录
上面看着就非常乱了,那么如何整改呢? 其实非常简单,原来你就是30件衣服放在一个衣柜里,那么你就得分类装,放外套的地方,放内衣的地方,放佩饰的地方等等,但是突然你的衣服编程300件了,那一个衣柜放不下,我就整多个柜子,分别放置不同的衣物。所以我们这可以整多个文件夹,分别管理不同的物品,那么标准版本的目录结构就来了:
为什么要设计项目目录结构?
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
- 一类同学认为,这种个人风格问题"无关紧要"。理由是能让程序work就好,风格问题根本不是问题。
- 另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
- 可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
- 可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。

上面那个图片就是较好的目录结构。
二. 按照项目目录结构,规范博客园系统
接下来,我就带领大家把具体的代码写入对应的文件中,并且将此项目启动起来,一定要跟着我的步骤一步一步去执行:
- 配置start.py文件
我们首先要配置启动文件,启动文件很简答就是将项目的启动执行放置start.py文件中,运行start.py文件可以成功启动项目即可。 那么项目的启动就是这个指令run() 我们把这个run()放置此文件中不就行了?

这样你能执行这个项目么?肯定是不可以呀,你的starts.py根本就找不到run这个变量,肯定是会报错的。
NameError: name 'run' is not defined 本文件肯定是找不到run这个变量也就是函数名的,不过这个难不倒我们,我们刚学了模块, 另个一文件的内容我们可以引用过来。但是你发现import run 或者 from src import run 都是报错的。为什么呢? 骚年,遇到报错不要慌!我们说过你的模块之所以可以引用,那是因为你的模块肯定在这个三个地方:内存,内置,sys.path里面,那么core在内存中肯定是没有的,也不是内置,而且sys.path也不可能有,因为sys.path只会将你当前的目录(bin)加载到内存,所以你刚才那么引用肯定是有问题的,那么如何解决?内存,内置你是左右不了的,你只能将core的路径添加到sys.path中,这样就可以了。
import sys
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\core')
from src import run
run()
这样虽然解决了,但是你不觉得有问题么?你现在从这个start文件需要引用src文件,那么你需要手动的将src的工作目录添加到sys.path中,那么有没有可能你会引用到其他的文件?比如你的项目中可能需要引用conf,lib等其他py文件,那么在每次引用之前,或者是开启项目时,全部把他们添加到sys.path中么?
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\core')
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\conf')
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\db')
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\lib')
这样是不是太麻烦了? 我们应该怎么做?我们应该把项目的工作路径添加到sys.path中,用一个例子说明:你想找张三,李四,王五,赵六等人,这些人全部都在一栋楼比如在汇德商厦,那么我就告诉你汇德商厦的位置:北京昌平区沙河镇汇德商厦。 你到了汇德商厦你在找具体这些人就可以了。所以我们只要将这个blog项目的工作目录添加到sys.path中,这样无论这个项目中的任意一个文件引用项目中哪个文件,就都可以找到了。所以:
import sys
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog')
from core.src import run
run()
上面还是差一点点,你这样写你的blog的路径就写死了,你的项目不可能只在你的电脑上,项目是共同开发的,你的项目肯定会出现在别人电脑上,那么你的路径就是问题了,在你的电脑上你的blog项目的路径是上面所写的,如果移植到别人电脑上,他的路径不可能与你的路径相同, 这样就会报错了,所以我们这个路径要动态获取,不能写死,所以这样就解决了:
import sys
import os
# sys.path.append(r'D:\lnh.python\py project\teaching_show\blog')
print(os.path.dirname(__file__))
# 获取本文件的绝对路径 # D:/lnh.python/py project/teaching_show/blog/bin
print(os.path.dirname(os.path.dirname(__file__)))
# 获取父级目录也就是blog的绝对路径 # D:/lnh.python/py project/teaching_show/blog
BATH_DIR = os.path.dirname(os.path.dirname(__file__))
sys.path.append(BATH_DIR)
from core.src import run
run()
那么还差一个小问题,这个starts文件可以当做脚本文件进行直接启动,如果是作为模块,被别人引用的话,按照这么写,也是可以启动整个程序的,这样合理么?这样是不合理的,作为启动文件,是不可以被别人引用启动的,所以我们此时要想到 __name__了:
import sys
import os
# sys.path.append(r'D:\lnh.python\py project\teaching_show\blog')
# print(os.path.dirname(__file__))
# 获取本文件的绝对路径 # D:/lnh.python/py project/teaching_show/blog/bin
# print(os.path.dirname(os.path.dirname(__file__)))
# 获取父级目录也就是blog的绝对路径 # D:/lnh.python/py project/teaching_show/blog
BATH_DIR = os.path.dirname(os.path.dirname(__file__))
sys.path.append(BATH_DIR)
from core.src import run
if __name__ == '__main__':
run()
这样,我们的starts启动文件就已经配置成功了。以后只要我们通过starts文件启动整个程序,它会先将整个项目的工作目录添加到sys.path中,然后在启动程序,这样我整个项目里面的任何的py文件想引用项目中的其他py文件,都是你可以的了。
- 配置settings.py文件。
接下来,我们就会将我们项目中的静态路径,数据库的连接设置等等文件放置在settings文件中。
我们看一下,你的主逻辑src中有这样几个变量:
status_dic = {
'username': None,
'status': False,
}
flag = True
register_path = r'D:\lnh.python\py project\teaching_show\blog\register'
我们是不是应该把这几个变量都放置在settings文件中呢?不是!setttings文件叫做配置文件,其实也叫做配置静态文件,什么叫静态? 静态就是一般不会轻易改变的,但是对于上面的代码status_dic ,flag这两个变量,由于在使用这个系统时会时长变化,所以不建议将这个两个变量放置在settings配置文件中,只需要将register_path放置进去就可以。
register_path = r'D:\lnh.python\py project\teaching_show\blog\register'

但是你将这个变量放置在settings.py之后,你的程序启动起来是有问题,为什么?
with open(register_path, encoding='utf-8') as f1:
NameError: name 'register_path' is not defined
因为主逻辑src中找不到register_path这个路径了,所以会报错,那么我们解决方式就是在src主逻辑中引用settings.py文件中的register_path就可以了。

这里引发一个问题:为什么你这样写就可以直接引用settings文件呢?我们在starts文件中已经说了,刚已启动blog文件时,我们手动将blog的路径添加到sys.path中了,这就意味着,我在整个项目中的任何py文件,都可以引用到blog项目目录下面的任何目录:bin,conf,core,db,lib,log这几个,所以,刚才我们引用settings文件才是可以的。
- 配置common.py文件
接下来,我们要配置我们的公共组件文件,在我们这个项目中,装饰器就是公共组件的工具,我们要把装饰器这个工具配置到common.py文件中。先把装饰器代码剪切到common.py文件中。这样直接粘过来,是有各种问题的:

所以我们要在common.py文件中引入src文件的这两个变量。

可是你的src文件中使用了auth装饰器,此时你的auth装饰器已经移动位置了,所以你要在src文件中引用auth装饰器,这样才可以使用上


OK,这样你就算是将你之前写的模拟博客园登录的作业按照规范化目录结构合理的完善完成了,最后还有一个关于README文档的书写。
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
作业题:
# 1.使用软件开发规范的方式实现一下模拟博客园登录
# a.注册时需要对密码进行加密
# b.登录时需要加密然后校验
"""
2.使用hashlib和json重新实现三次登录锁定
a.注册时需要对密码进行加密
b.将错误用户账号和错误次数编写成如下结构,存储到错误文件中
{"alex":2}
{"meet":3}
"""
import hashlib
import json
login_dic = {
"count":3
}
file_path = "userinfo.txt"
error_path = "error_user.txt"
def my_md5(user,pwd):
md5 = hashlib.md5(user.encode("utf-8"))
md5.update(pwd.encode("utf-8"))
pwd = md5.hexdigest()
return pwd
def auth(user,pwd):
with open(file_path, "a+", encoding="utf-8")as ff:
ff.seek(0)
pwd = my_md5(user, pwd)
for em in ff:
file_user, file_pwd = em.strip().split(":")
# pwd = my_md5(user, pwd) # 错误问题:同名
# print(file_user,file_pwd,user,pwd)
if file_user == user and file_pwd == pwd:
print(f"欢迎{user}登录!")
login_dic['count'] = 0
return
else:
login_dic['count'] -= 1
if user in error_dic:
error_dic[user] += 1
else:
error_dic[user] = 1
f = open(error_path, 'w', encoding="utf-8")
f.write(json.dumps(error_dic))
print(f"用户密码错误,剩余次数:{login_dic['count']}")
def register(user,pwd):
"""
注册
:param user:
:param pwd:
:return:
"""
with open(file_path,"a+",encoding="utf-8")as f:
f.seek(0)
for i in f:
file_user,file_pwd = i.split(":") # ['alex',"alex1234"]
if user == file_user:
print("用户名已存在!")
return
else:
pwd = my_md5(user,pwd)
print(pwd)
f.write(f"{user}:{pwd}\n")
print("注册成功!")
error_dic = {} # {"alex":2,"meet":3}
def login(user,pwd):
with open(error_path,"a+",encoding="utf-8")as f1:
f1.seek(0)
for i in f1:
error_dic.update(json.loads(i))
print(error_dic)
if user in error_dic:
if error_dic[user] >= 3:
print(f"{user}用户锁定!")
login_dic['count'] = 0
else:
auth(user,pwd)
else:
auth(user,pwd)
msg = """
1.登录
2.注册
"""
func_dic = {
"2":register,
"1":login
}
while login_dic['count']:
choose = input(msg)
if choose in func_dic:
user = input("username:")
pwd = input("password:")
func_dic[choose](user, pwd)
else:
print("输入有误!")
# 22e02a465ca7e6f8e93db22ebb78f096
python27期day16:序列化、json、pickle、hashlib、collections、软件开发规范、作业。的更多相关文章
- 序列化,os,sys,hashlib,collections
序列化,os,sys,hashlib,collections 1.序列化 什么是序列化?序列化的本质就是将一种数据结构(如字典,列表)等转换成一个特殊的序列(字符串或者bytes)的过程就叫做序列化. ...
- Pythoy 数据类型序列化——json&pickle 模块
Pythoy 数据类型序列化--json&pickle 模块 TOC 什么是序列化/反序列化 pickle 模块 json 模块 对比json和pickle json.tool 命令行接口 什 ...
- python中软件开发规范,模块,序列化随笔
1.软件开发规范 首先: 当代码都存放在一个py文件中时会导致 1.不便于管理,修改,增加 2.可读性差 3.加载速度慢 划分文件1.启动文件(启动接口)--starts文件放bin文件里2.公共文件 ...
- 面向对象进阶------>模块 json pickle hashlib
何为模块呢? 其实模块就是.py文件 python之所以好用就是模块多 模块分三种 : 内置模块 . 拓展模块.自定义模块. 现在我们来认识:内置模块中的 序列化模块和 hashlib 模块 1 ...
- Day 4-5 序列化 json & pickle &shelve
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 反序列化: 把字符转成内存里的数据类型. 用于序列化的两个模块.他 ...
- json&pickle序列化和软件开发规范
json和pickle 用于序列化的两个模块 json 用于字符串和python数据类型间进行转换,json只支持列表,字典这样简单的数据类型 但是它不支持类,函数这样的数据类型转换 pickle ...
- Python基础-序列化(json/pickle)
我们把对象(变量)从内存中变成可存储的过程称之为序列化,比如XML,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等 ...
- day 19 os模块的补充 序列化 json pickle
os 模块 os.path.abspath 规范绝对路径 os.path.split() 把路径分成两段,第二段是一个文件或者是文件夹 os.path.dirname 取第一部分 os.p ...
- python学习之文件读写,序列化(json,pickle,shelve)
python基础 文件读写 凡是读写文件,所有格式类型都是字符串形式传输 只读模式(默认) r f=open('a.txt','r')#文件不存在会报错 print(f.read())#获取到文件所 ...
随机推荐
- 剑指Offer-3.从尾到头打印链表(C++/Java)
题目: 输入一个链表,按链表从尾到头的顺序返回一个ArrayList. 分析: 很简单的一道题,其实也就是从尾到头打印链表,题目要求返回ArrayList,其实也就是一个数组. 可以将链表中的元素全部 ...
- Ubuntu下的录GIF神器——Peek
最近一直在找Ubuntu下面录GIF好用方便的软件一直没找到,很多都是要获取录屏四角的坐标,现在终于找到了,就是我们的录GIF神器——Peek. 1 获取Peek的ppa源 sudo add-apt- ...
- Django 模版语言
传入变量 {{ 变量名 }} 在 view.py 的函数返回 render 时在html文件名后传入一个字典,字典的 key 对应html文件中的变量名,value 为传入的值 views.py: d ...
- Ultimate Chicken Horse GameProject第三次迭代成果文档
经过三次迭代我们实现了游戏的基本功能 项目文档的github链接:https://github.com/k6tok12355/Ultimate-Chicken-Horse 下面是我们在第一次迭代中设定 ...
- [Taro] taro中定义以及使用全局变量
taro中定义以及使用全局变量 错误的姿势 // app.tsx文件中 class App extends Component { componentDidMount() { this.user = ...
- nowcoder941B 弹钢琴
题目链接 思路 首先按照音色排个序,顺便离散化一下音高. 用\(h[i]\)表示第\(i\)个键的音高,用\(w[i]\)表示第\(i\)个键的春希度. 朴素\(dp\) \(f[i][j]\)表示前 ...
- c语言新知
C语言学得有点懈怠,昨个遇一个高手. 教了我两天,真细腻. 第一天,让我写一个程序删除字符串多余空格. 我俩代码对比 结果很显然了.
- 性能对比:aelf智能合约运行环境性能是evm的1000倍
测试用例及代码库 机器配置 测试结果 3.1 EVM 3.2 AElf 3.2.1 LoopDivAdd10M 3.2.2 LoopExpNop1M 测试结论 近期对标以太坊做了一系列针对测试,在此次 ...
- 在 React 组件中监听 android 手机物理返回/回退/back键事件
当前端页面嵌入到 webview 中运行时,有时会需要监听手机的物理返回按键事件来做一些自定义的操作. 比如我最近遇到的,在一个页面里面有批量选择的功能,当点击手机的返回键时,清除页面上的选中状态.我 ...
- not in和not exists区别
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引: 而not extsts 的子查询依然能用到表上的索引. 所以无论那个表大,用not exists都比not in要快. 也就是 ...