BERT、ERNIE以及XLNet学习记录
主要是对
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding提出的BERT
清华和华为提出的ERNIE: Enhanced Language Representation with Informative Entities
百度提出的ERNIE: Enhanced Representation through Knowledge Integration
这三个模型的学习记录
BERT
看BERT之前先看https://www.cnblogs.com/dyl222/p/10888917.html 因为它所使用的特征抽取器是《Attention is all you need》中提出的Transformer
论文翻译看:
https://zhuanlan.zhihu.com/p/52248160
BERT的具体解读看:https://blog.csdn.net/yangfengling1023/article/details/84025313
BERT属于一种两阶段的模型,第一阶段是基于大规模无监督语料进行预训练(pre-train)第二阶段是结合具体的任务进行微调(fine-tuning),它最大的优势是效果好,通过多层的Transformer从海量的无监督语料中所抽取出的语言学特征有很强的泛化性,对下游任务能够起到很好的特征补充作用。
它最大的创新点在于它所提出的两个新的预训练任务:
1、Masked LM
Masked LM随机的从输入中遮罩一些Token,目标是只通过它的上下文去预测这些被遮罩Token,它能够充分的利用上下文,和Bi-LSTM这种通过拼接来实现的弱双向相比,它所实现的是真正的双向。
在所有的实验中,我们在每一个序列中随机的遮盖了15%的Token。
虽然这允许我们做双向的预训练模型,但是这种方法仍然有两个弊端。第一个是这种方法会让预训练模型和微调阶段不能相互匹配,因为[MASK]标记在微调阶段中是不存在的。为了消除这个弊端,我们并不总是把遮盖的Token用[MASK]表示,而是在训练数据中对随机产生的15%的Token用[MASK]表示,比如,在句子"my dog is hairy"中选择"hairy",然后通过以下的方式产生标记:
* 并不总是用[MASK]替换选择的Token,数据通过如下方式产生:
* 80%的情况下:把选择的词替换成[MASK],比如:"my dog is hairy" → "my dog is [MASK]"
* 10%的情况下替换选中的Token为随机Token,比如:"my dog is hairy" → "my dog is apple"
* 10% 的情况下保持原Token不变,比如:"my dog is hairy" → "my dog is hairy"。
第二个弊端是使用一个MLM意味着每个batch中只有15%的标记会被预测,所以在预训练的时候收敛需要更多步。但是和MLM带来的巨大提升相比,这么做是值得的。
2.Next Sentence Prediction
训练数据的正样本是通过采样同一个文档中的两个连续的句子,而负样本是通过采用两个不同的文档的句子。该任务主要是希望能提高下游任务的效果。很多重要的下游任务如问答和自然语言推断(NLI)是基于两个句子之间的理解的,语言模型并不能直接捕获到这种关系。为了训练可以理解句子关系的模型,我们预训练了一个可以从任何单语语料库中轻松产生的二值化的下句预测任务,NSP其实包含了两个子任务,主题预测与关系一致性预测,但是主题预测相比于关系一致性预测简单太多了,并且在MLM任务中其实也有类型的效果。特别的,当为每个预训练模型选择句子A和句子B时,50%的情况B就是A的下一句,50%的情况下是从语料中随机选择的句子。比如:

输入部分:

输入由三部分组成分别为word embedding、位置向量、以及段向量
我们在30000个词上使用了WordPiece嵌入,把拆分的词片段(word pieces)用"##"标注(译者注:见图中"playing"-"play ##ing")
每一句的句首使用了特殊的分类嵌入([CLS])。这个标记。在最终的隐藏层中(也就是转换器的输出)对应的是分类任务中序列标识的聚合表示。非分类任务中这一标记将被忽略。也就是在处理分类下游任务时选用[CLS]向量作为输入,因为它所代表的是句向量
句子对被打包在一起作为一个句子。我们用两种方法区别他们,首先,我们把他们用特殊的标记([SEP])区分开,然后我们会给第一句的每一个标记添加一个学习到的句子 A 的嵌入,给第二句的每个标记添加一个学习到的句子 B 的嵌入
* 对于单个句子输入我们只使用句子 A 的嵌入。
句子A的段向量输入全为0,句子B的段向量输入全为1
BERT的优势:
1)通过MLM实现的是真正的双向,ELMO中使用的Bi-LSTM对正向和反向的表征进行拼接实现的只是一种弱双向。
2)选用Transformer作为特征抽取器,相比于CNN能够获得更多的全局信息,相比于LSTM等RNN系列的特征抽取器,它能够实现并行,同时还引入了多层,尽管NLP方面的多层不能简单的和图像方面的多层进行比较,但是这也是一大进步,在NLP方面引入了多层能够抽取到更丰富的信息。
3)最大的优势是它明确了如何对海量的无监督的语料进行利用的一个方向,通过pre-train所抽取出的语言学特征具有很强的泛化性,好比于图像领域的image-net,只需在下游具体任务少量语料的基础上进行fine-tuning就能够取得很好的效果。
BERT的缺点:
它的Positional Embedding是绝对位置信息,想要通过Transformer通过绝对位置编码得到相对位置信息,但是为了进行多头的划分,Q,K,V都需要先进行一次线性变换,使得其无法得到相对位置信息,但是在有些任务中相对位置信息非常重要。
为了实现真正的双向而创建的MLM,那些在pre-train阶段的[MASK]标签在fine-tune阶段是不存在的,这会导致预训练和微调之间的差异(这个问题在XLNet中得到了解决)。同时通过[MASK]进行掩盖,它假设被掩盖的token和未被掩盖的token之间是相互独立的,由于高阶,远程依赖在自然语言中的普遍存在,这样做过度简化了。
在训练语言模型时过长的语料会被截断,尽管BERT所使用的特征提取器Transformer通过self-attention能够一步到位获得远程的依赖,但是由于训练语言模型时选取的长度是固定,所以无法突破上下文的限制,获得更长的依赖。(这个问题在《TRANSFORMER-XL: ATTENTIVE LANGUAGE MODELS BEYOND A FIXED-LENGTH CONTEXT》中得到了解决,同时XLnet预训练语言模型也是使用的transformer-XL作为特征抽取器)
Bert中的一些细节记录(编码在tokenization中使用'utf-8',model中的一些参数初始化选用的为截断式的正太分布(正太分布的随机初始化以及He初始化适用于relu以及gelu类的激活函数),编码器中的激活函数选用的为gelu(有关具体解析参照:https://blog.csdn.net/liruihongbob/article/details/86510622))
清华和华为的ERNIE
利用信息实体增强语言表达
论文具体解析见:https://cloud.tencent.com/developer/article/1438052
在大规模语料库上预训练的 BERT,它可以从纯文本中很好地捕捉丰富的语义模式,经过微调后可以持续改善不同 NLP 任务的性能。因此,我们获取 BERT 隐藏层表征后,可用于提升自己任务的性能。
但是,已有的预训练语言模型很少考虑知识信息,具体而言即知识图谱(knowledge graphs,KG),知识图谱能够提供丰富的结构化知识事实,以便进行更好的知识理解。简而言之,预训练语言模型只知道语言相关的「合理性」,它并不知道语言到底描述了什么,里面是不是有什么特殊的东西。
ERNIE的目标是:以知识图谱中的多信息实体(informative entity)作为外部知识改善语言表征。
论文中的研究结合大规模语料库和知识图谱训练出增强版的语言表征模型 (ERNIE),该模型可以同时充分利用词汇、句法和知识信息。实验结果表明 ERNIE 在多个知识驱动型任务上取得了极大改进,在其他 NLP 任务上的性能可以媲美当前最优的 BERT 模型。
但是如何把知识图谱中的外部知识组合到语言表征模型中?
原文中所提到的两个挑战:
1)结构化的知识编码:对于给定的文本,如何高效地抽取并编码对应的知识图谱事实是非常重要的,这些 KG 事实需要能用于语言表征模型。(即为如何从文本中高效的抽取并编码能够用于语言表征模型的知识图谱事实)
2)异质信息融合:语言表征的预训练过程和知识表征过程有很大的不同,它们会产生两个独立的向量空间。因此,如何设计一个特殊的预训练目标,以融合词汇、句法和知识信息就显得非常重要了。(如何设计预训练目标对知识表征和语言表征这两个独立的向量空间进行融合)
对于挑战一,作者的解决方法是:
首先识别文本中的命名实体,然后将这些提到的实体与知识图谱中的实体进行匹配。
研究者并不直接使用 KG 中基于图的事实,相反他们通过《Translating Embeddings for Modeling Multi-relational Data》论文中提出的知识嵌入算法编码 KG 的图结构,并将多信息实体嵌入作为 ERNIE 的输入。基于文本和知识图谱的对齐,ERNIE 将知识模块的实体表征整合到语义模块的隐藏层中。
对于挑战二,作者的解决方案是:
提出了一种知识型编码器(K-Encoder)用于对知识表征和语言表征这两个独立的向量空间进行融合。
模型的整体结构如下:(下面的细节是自己结合论文的理解,能力有限,若理解不对希望各位大神能够批评指正)
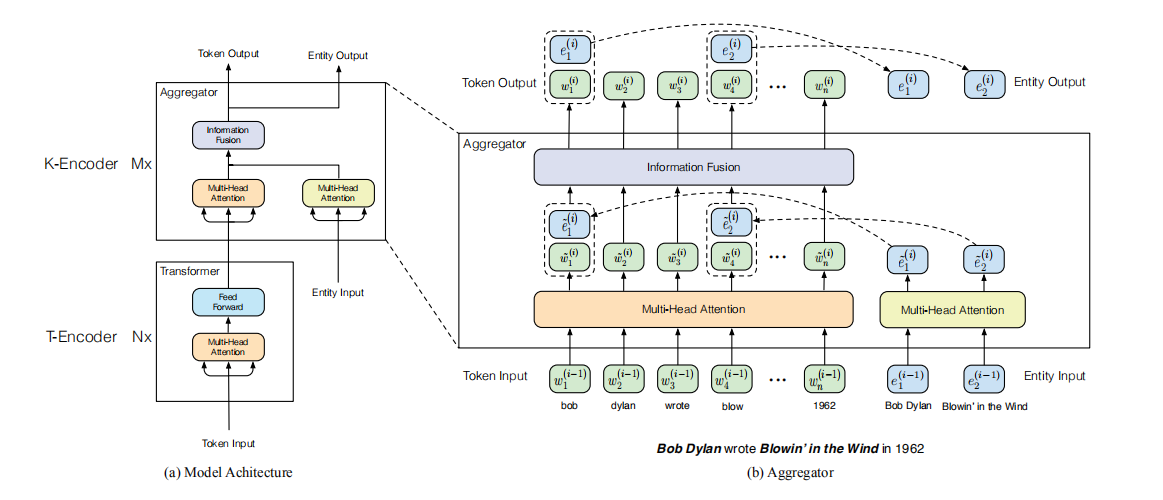
上图中左半部分是ERNIE的架构,右半部分是对K-Encoder的具体解析
由上图可知ERNIE 的整个模型架构由两个堆叠的模块构成,下面的部分T-Encoder和BERT中的Encoder结构相同,这里的Transformer使用了6层(N=6)。这一部分用于提取语言表征。
上面的部分K-Encoder用于对知识表征和语言表征这两个独立的向量空间进行融合。它由M层(论文中M=6)Aggregator堆叠而成。先看输入部分

对于第一层左边的Token Input是T-Encoder的输出,右边的Entity Input是通过《Translating Embeddings for Modeling Multi-relational Data》论文中方法抽取的知识表征,对于第二层到第M层则是上层的输出。
然后经过:
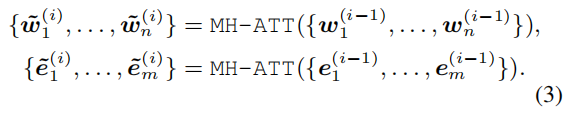
其中MH-ATT为多头自注意力机制
随后看下面这一部分:

每个聚合器的这一部分都用于对语言表征和知识表征进行信息融合,具体的融合方法为:

其中使用的激活函数为GELU
对于没有对应实体的部分采用:
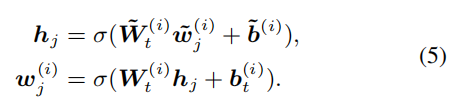
ERNIE属于一种三阶段的模型,第一阶段是通过TransE抽取知识信息(KG中记录了很多三元组关系,(主体,关系,客体),开始对这三类的向量表示是随机生成的,通过训练使得主体向量+客体向量近似于关系向量),第二阶段是pre-train融入知识信息的语言模型,第三阶段是结合具体任务进行fine-tuning。
相比于BERT在pre-train阶段ERNIE新增了一个任务denoising entity auto-encoder (dEA)(这个任务是自然而然应该想到的,Bert的MASK预测词采用的就是降噪自编码思想,对于多出的实体任务也应该降噪)
它随机屏蔽了一些对齐的token-entity,然后要求系统根据对齐的令牌预测所有相应的实体。
考虑到softmax层的E的大小非常大,因此我们仅要求系统基于给定的实体序列(也就是每句中实体矩阵E仅有该句中所含的实体向量组成,而不是所有实体向量)而不是KG中的所有实体来预测实体。通过如下公式进行计算交叉熵损失函数:

注意这里e和经过线性变换后的w运行的点乘,每个token都和该句中的所有实体向量进行相似度运算,从而进行对齐。需要注意的点是,实体是和句中的实体头进行对齐。
ERNIE最大的贡献是在pre-train阶段在语言表征中融入了知识表征,对于那些知识驱动型的任务效果有所提高,对于那些常用的NLP任务效果和BERT相当。
百度的ERNIE
相比于清华和华为提出的ERNIE,百度的ERNIE相比于BERT的改进非常小,是在BERT模型的基础上进行改进的。
百度的ERNIE相比于BERT也是为了融入知识图谱从而能够让模型学习到海量文本中蕴含的潜在知识。相比于BERT其改进的地方在于对Masked的改进,百度的ERNIE通过MLM掩盖的不只是字,还有词以及实体。例如:

- Learned by BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。
- Learned by ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
在 BERT 模型中,通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的知识。而 ERNIE 通过学习词与实体的表达,使模型能够建模出『哈尔滨』与『黑龙江』的关系,学到『哈尔滨』是『黑龙江』的省会以及『哈尔滨』是个冰雪城市。
ERNIE 模型本身保持基于字特征输入建模,使得模型在应用时不需要依赖其他信息,具备更强的通用性和可扩展性。相对词特征输入模型,字特征可建模字的组合语义,例如建模红色,绿色,蓝色等表示颜色的词语时,通过相同字的语义组合学到词之间的语义关系。
具体可参考:https://zhuanlan.zhihu.com/p/59436589
对于XLNet具体可以参考:https://zhuanlan.zhihu.com/p/70257427
先说下XLNet中提到的自回归语言模型(Autoregressive LM)以及自编码语言模型(Autoencoder LM)
根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的LM被称为自回归语言模型。例如RNNLM、GPT是根据上文预测下一个单词,ELMO是即根据上文预测下一个词也根据下文预测前面的词,这些都是典型的自回归语言模型。
缺点:无法同时应用上下文的信息。优点:相比于BERT使用的降噪自编码语言模型不会出现预训练和微调不相统一的问题。
自编码语言模型的典型代表是BERT使用的MLM,Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
它的优缺点正好和自回归语言模型相反。缺点是:会出现预训练和微调不相统一的问题。优点是:能够同时应用上下文的信息。
XLNet它的思想是如何成功的融合上两种语言模型的优点,即为如何不用Mask,通过自回归语言模型的思想,而又能应用到上下文的信息,作者提出了一种Permutation LM
也就是XLNet主要是对预训练阶段的改进。看一下下图:

结合上图,例如[x1,x2,x3,x4]一条文本有这四个token组成,index从1开始,则对index的全排列中有[3,2,4,1]图左上,[2,4,3,1]以及[1,4,2,3]和[4,3,1,2]
先明确当前任务是预测index为3也就是x3这个词,使用的是自回归语言模型的思想,也就是从左到右结合上文预测下一个词,图左上代表当前输入为[x3,x2,x4,x1]从左到右x3在最左所以此次全排列的输入无法获得上下文信息,图右上代表当前输入为[x2,x4,x3,x1]从左到右x2以及x4都在x3的前面,这样就能够同时应用到上下文信息了。
上面讲的是Permutation LM的基本思想,难点在于具体怎么做才能实现上述思想。首先,需要强调一点,尽管上面讲的是把句子X的单词排列组合后,再随机抽取例子作为输入,但是,实际上你是不能这么做的,因为Fine-tuning阶段你不可能也去排列组合原始输入。所以,就必须让预训练阶段的输入部分,看上去仍然是x1,x2,x3,x4这个输入顺序,但是可以在Transformer部分做些工作,来达成我们希望的目标。具体而言,XLNet采取了Attention掩码的机制,你可以理解为,当前的输入句子是X,要预测的单词Ti是第i个单词,前面1到i-1个单词,在输入部分观察,并没发生变化,该是谁还是谁。但是在Transformer内部,通过Attention掩码,从X的输入单词里面,也就是Ti的上文和下文单词中,随机选择i-1个,放到Ti的上文位置中,把其它单词的输入通过Attention掩码隐藏掉,于是就能够达成我们期望的目标(当然这个所谓放到Ti的上文位置,只是一种形象的说法,其实在内部,就是通过Attention Mask,把其它没有被选到的单词Mask掉,不让它们在预测单词Ti的时候发生作用,如此而已。看着就类似于把这些被选中的单词放到了上文Context_before的位置了)。具体实现的时候,XLNet是用“双流自注意力模型”实现的
双流自注意力机制:一个是内容流自注意力,其实就是标准的Transformer的计算过程;主要是引入了Query流自注意力,这个是干嘛的呢?其实就是用来代替Bert的那个[Mask]标记的,因为XLNet希望抛掉[Mask]标记符号,但是比如知道上文单词x1,x2,要预测单词x3,此时在x3对应位置的Transformer最高层去预测这个单词,但是输入侧不能看到要预测的单词x3,Bert其实是直接引入[Mask]标记来覆盖掉单词x3的内容的,等于说[Mask]是个通用的占位符号。而XLNet因为要抛掉[Mask]标记,但是又不能看到x3的输入,于是Query流,就直接忽略掉x3输入了,只保留这个位置信息,用参数w来代表位置的embedding编码。其实XLNet只是扔了表面的[Mask]占位符号,内部还是引入Query流来忽略掉被Mask的这个单词。和Bert比,只是实现方式不同而已。(也就是XLNet只是和Bert实现Mask的方式不同,为了结合[MASK]这个标签在fine-tuning阶段不存在从而会导致训练和预测不统一的问题,XLNet是通过Query流自注意力来实现遮罩的,因此它也无法解决因为遮罩而产生的遮罩部分与非遮罩部分完全独立的这个假设问题)。
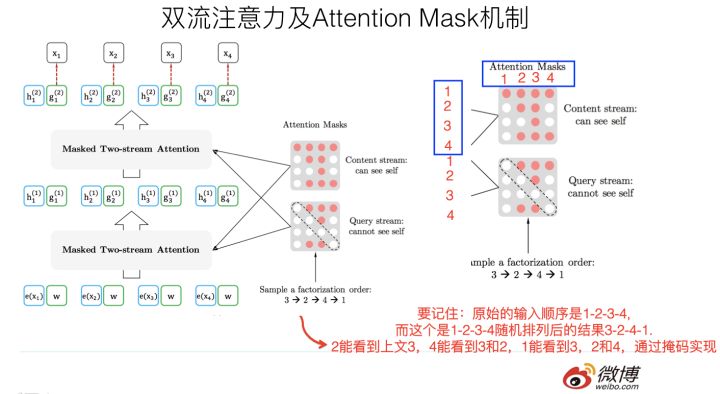
除了图片上的内容,这里做进一步补充,白点是看不到的,从横行看竖行,此时输入的是[x3,x2,x4,x1]这个组合序列,x1在最右边,x2,x3,x4都能被利用,所以上图右部分的上边那个矩阵,横行的1对于竖行的1,2,3,4都能看到
把一个长序列进行全排列可想而知语料被扩充到了多大,因此并不是所有的全排列都会被应用,只是采样一部分。
对Transformer-XL介绍
可以结合:https://wenku.baidu.com/view/97d228975ff7ba0d4a7302768e9951e79b8969eb.html
主要是为了解决在使用Transformer作为特征抽取器训练语言模型时,由于固定了句子的最大长度,使得它无法获得超出设定的句子最大长度的长期依赖问题。同时针对Transformer所使用的绝对位置编码,它改为了相对位置编码,具体原因和好处见下文。
模型的创新:



为什么要引用相对位置编码,以及用相对位置编码的好处

相对位置编码的具体介绍:




BERT、ERNIE以及XLNet学习记录的更多相关文章
- Quartz 学习记录1
原因 公司有一些批量定时任务可能需要在夜间执行,用的是quartz和spring batch两个框架.quartz是个定时任务框架,spring batch是个批处理框架. 虽然我自己的小玩意儿平时不 ...
- Java 静态内部类与非静态内部类 学习记录.
目的 为什么会有这篇文章呢,是因为我在学习各种框架的时候发现很多框架都用到了这些内部类的小技巧,虽然我平时写代码的时候基本不用,但是看别人代码的话至少要了解基本知识吧,另外到底内部类应该应用在哪些场合 ...
- Apache Shiro 学习记录4
今天看了教程的第三章...是关于授权的......和以前一样.....自己也研究了下....我觉得看那篇教程怎么说呢.....总体上是为数不多的精品教程了吧....但是有些地方确实是讲的太少了.... ...
- UWP学习记录12-应用到应用的通信
UWP学习记录12-应用到应用的通信 1.应用间通信 “共享”合约是用户可以在应用之间快速交换数据的一种方式. 例如,用户可能希望使用社交网络应用与其好友共享网页,或者将链接保存在笔记应用中以供日后参 ...
- UWP学习记录11-设计和UI
UWP学习记录11-设计和UI 1.输入和设备 通用 Windows 平台 (UWP) 中的用户交互组合了输入和输出源(例如鼠标.键盘.笔.触摸.触摸板.语音.Cortana.控制器.手势.注视等)以 ...
- UWP学习记录10-设计和UI之控件和模式7
UWP学习记录10-设计和UI之控件和模式7 1.导航控件 Hub,中心控件,利用它你可以将应用内容整理到不同但又相关的区域或类别中. 中心的各个区域可按首选顺序遍历,并且可用作更具体体验的起始点. ...
- UWP学习记录9-设计和UI之控件和模式6
UWP学习记录9-设计和UI之控件和模式6 1.图形和墨迹 InkCanvas是接收和显示墨迹笔划的控件,是新增的比较复杂的控件,这里先不深入. 而形状(Shape)则是可以显示的各种保留模式图形对象 ...
- UWP学习记录8-设计和UI之控件和模式5
UWP学习记录8-设计和UI之控件和模式5 1.日历.日期和时间控件 日期和时间控件提供了标准的本地化方法,可供用户在应用中查看并设置日期和时间值. 有四个日期和时间控件可供选择,选择的依据如下: 日 ...
- UWP学习记录7-设计和UI之控件和模式4
UWP学习记录7-设计和UI之控件和模式4 1.翻转视图 使用翻转视图浏览集合中的图像或其他项目(例如相册中的照片或产品详细信息页中的项目),一次显示一个项目. 对于触摸设备,轻扫某个项将在整个集合中 ...
随机推荐
- 解决python 缺少os.fspath
在python3.6下运行pandas会报错缺少os.fspath 升级到python3.7 3.7 安装参考:https://www.cnblogs.com/jifeng/p/11221469.ht ...
- Vue使用小结
公司新项目使用Asp.Net Core+Vue组合来做,这里总结下对于Vue的认识 为什么选择Vue 主要基于以下几点选择Vue而不是jQuery.React等框架 双向绑定相比于jQuery减少了许 ...
- .NET Core 多框架支持(net45+netstandard20)实践中遇到的一些问题总结
.NET Core 多框架支持(net45+netstandard20)实践中遇到的一些问题总结 前言 本文主要是关于.NET Standard 代码 在多框架 和 多平台 支持自己实践过程中遇到的一 ...
- 阿里云容器服务中国最佳,进入 Forrester 报告强劲表现者象限
近日,全球知名市场调研机构 Forrester 发布首个企业级公共云容器平台报告. 报告显示:阿里云容器服务创造了中国企业最好成绩,与谷歌云位于同一水平线,进入强劲表现者象限. 究其原因,分析师认为: ...
- 超详细Pycharm部署项目视频教程
在实际的工作中,不管你是开发.测试还是运维人员,都应该掌握的一项技能就是部署项目,简单说就是把项目放到服务器中,使其正常运行.今天猪哥就以咱们的微信机器人项目为例子,带大家来部署一下项目.本文将会详细 ...
- Java匹马行天下之学编程的起点——走进编程的殿堂
学编程的起点——走进编程的殿堂 前言: 知其然,知其所以然,努力固然重要,但是思维的提升会让你事半功倍,我会用我花费时间换来的“思维”带更多的朋友入门,让你们明明白白学编程,学编程,不迷茫. 转变思维 ...
- webapi 导入excel处理数据
参考资料 https://blog.csdn.net/pan_junbiao/article/details/82935992 https://www.cnblogs.com/dansedia ...
- Codeforces 939A题,B题(水题)
题目链接:http://codeforces.com/problemset/problem/939/A A题 A. Love Triangle time limit per test 1 second ...
- mask-rcnn代码解读(七):display(self)函数的解析
如和将class中定义的变量打印或读取出来,受maskrcnn的config.py的启示,我将对该函数进行解释. 我将介绍该函数前,需要对一些名词进行解释,如下: ①Ipython:ipython是一 ...
- 怎么进入bios设置界面,电脑如何进入BIOS进行设置,怎么进入BIOS的方法集合
怎么进入bios设置界面,电脑如何进入BIOS进行设置,怎么进入BIOS的方法集合 开机出现电脑商家图标时,按住F10键进入BIOS界面.进入BIOS界面一般都是开机后按<del,Esc,F1, ...