SPFA + 链式前向星(详解)
求最短路是图论中最基础的算法,最短路算法挺多,本文介绍SPFA算法。 关于其他最短路算法,请看我另一篇博客最短路算法详解
链式前向星概念
简单的说,就是存储图的一个数据结构。它是按照边来存图,而邻接矩阵是按点来存图,故链式前向星又叫边集数组
为何用链式前向星
当图的边数不多,而节点数很多(稠密图)的时候,如果我们仍然用邻接矩阵来存的话,内存占用可能会很大,而这种情况在ACM竞赛中又是很常见的,此时链式前向星就显得尤为重要。
链式前向星详解
主要涉及到两个数组,一个是head[MAXE]数组,另一个是edge[MAXE]数组:
// edge数组是一个边集数组,存放一条边的信息
// to --- 该条边的终点
// next --- 下一条要访问的边(存的是edge数组的下标).
// 即:访问完了edge[i],下一条要访问的就是edge[edge[i].next],
// 如果next为0,表示now这个节点作为起点的边已经全部访问完.(下一步:Q.front())
// w --- 该条边的权值
struct Node {
int to,next,w;
};
Node edge[MAXE]; // idx --- edge数组的下标
// head[i] --- 表示以i节点为起点的所有出边在edge数组中的起始存储位置为head[i].
// (如果head[i]为0,表示结点i没有出边)
int idx,head[MAXV];
理解了这两个数组,那么链式前向星也就理解了。其实链式前向星主要还是理解head数组和edge数组中的next这两个东西是怎么相互作用的,简单的说,就是head数组指导next,next指导edge的下一个下标。即:head[i]存储的是节点i作为起始节点的出边在edge数组中的起始存储位置,next引导节点i的下一条出边在edge数组中的存储位置。
怎么实现图的存储的呢?
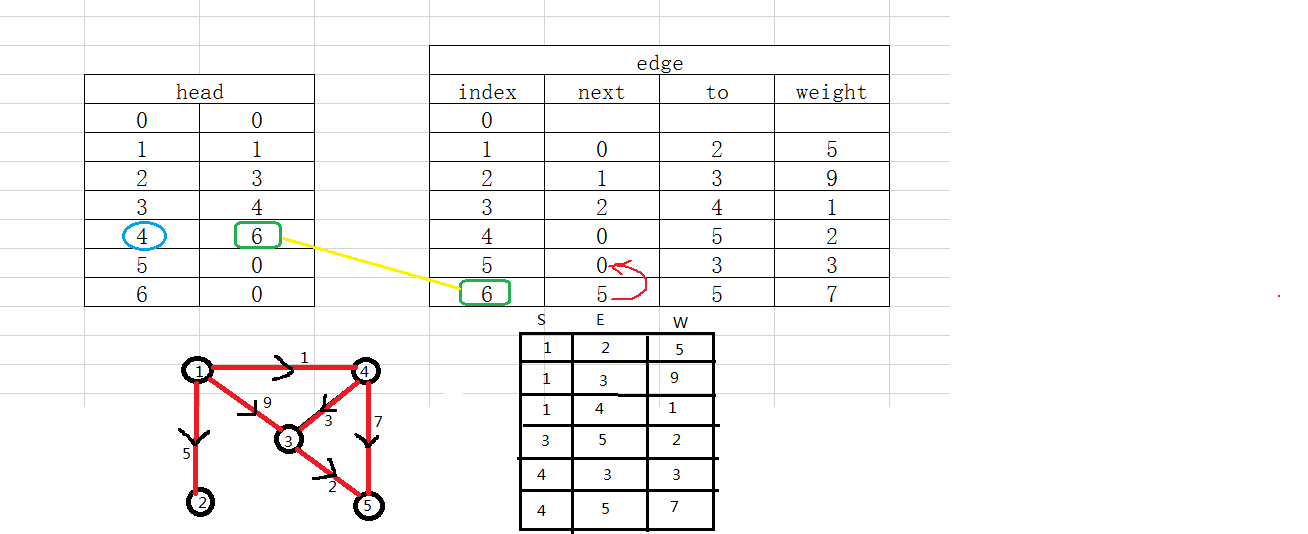
这张图看懂了,链式前向星也就搞懂了。
链式前向星代码实现
//Memory Time
// 2556K 362MS
// by : Snarl_jsb
#include<algorithm>
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<iostream>
#include<vector>
#include<queue>
#include<stack>
#include<iomanip>
#include<string>
#include<climits>
#include<cmath>
#define MAXV 10010
#define MAXE 50010
#define LL long long
using namespace std;
int T,n,m,u,v,w;
int now,home,goal;
bool vis[MAXV];
LL dis[MAXV];
namespace Adj
{
// edge数组是一个边集数组,存放一条边的信息
// to --- 该条边的终点
// next --- 下一条要访问的边(存的是edge数组的下标).
// 即:访问完了edge[i],下一条要访问的就是edge[edge[i].next],
// 如果next为0,表示now这个节点作为起点的边已经全部访问完.(下一步:Q.front())
// w --- 该条边的权值
struct Node
{
int to,next,w;
};
Node edge[MAXE]; // idx --- edge数组的下标
// head[i] --- 表示以i节点为起点的所有出边在edge数组中的起始存储位置为head[i].(如果head[i]为0,表示结点i没有出边)
int idx,head[MAXV];
// 初始化
void init()
{
idx=;
memset(head,,sizeof(head));
} // 加边函数
void addEdge(int u,int v,int w) // 起点,终点,权值
{
edge[idx].to=v; // 该边的终点
edge[idx].w=w; // 权值
edge[idx].next=head[u]; // (指向head[u]后,head[u]又指向了自己)
head[u]=idx; // 以u结点为起点的边在edge数组中存储的下标
idx++;
}
}
using namespace Adj;
void visit(int sta)
{
for(int i=;i<=n;i++)
{
vis[i]=;
dis[i]=LLONG_MAX;
}
// 起点进队
queue<int>Q;
Q.push(sta);
vis[sta]=;
dis[sta]=;
while(!Q.empty())
{
int now=Q.front();
Q.pop();
// 在spfa中这儿需要改为0,因为每个节点需要重复进队
vis[now]=;
//取出now结点在edge中的起始存储下标(当i=0,即edge[i].next为0,说明以now节点为起始点的边全部访问完)
for(int i=head[now];i;i=edge[i].next)
{
int son=edge[i].to;
printf("%d --> %d , weight = %d\n",now,edge[i].to,edge[i].w);
if(!vis[son])
{
Q.push(son); // 子节点未访问过
vis[son]=; // 标记已访问
}
}
}
} int main()
{
while()
{
Adj::init();
scanf("%d",&n);
scanf("%d",&m);
while(m--) // 输入m条边
{
int s,e,w; // 起点 终点 权值
scanf("%d %d %d",&s,&e,&w);
addEdge(s,e,w); //若是无向图,反过来再加一次
}
int start_point; //访问的起点
scanf("%d",&start_point);
visit(start_point);
}
return ;
}
spfa概念
SPFA算法是求单源最短路径的一种算法,在Bellman-ford算法的基础上加上一个队列优化,减少了冗余的松弛操作,是一种高效的最短路算法。
SPFA的运用和分析
运用:
- 求单源最短路;
- 判断负环(某个点进队的次数超过了v次,则存在负环)
分析:
- 平均时间复杂度:O(kE),k<=2
- 最差时间复杂度:O(VE) (出题人可能设计卡spfa时间复杂度的数据)
SPFA代码实现
//Memory Time
// 2556K 362MS
// by : Snarl_jsb
#include<algorithm>
#include<cstdio>
#inlude<cstring>
#include<cstdlib>
#include<iostream>
#include<vector>
#include<queue>
#include<stack>
#include<iomanip>
#include<string>
#include<climits>
#include<cmath>
#define MAXV 10010
#define MAXE 50010
#define LL long long
using namespace std;
int T,n,m,u,v,w;
int now,home,goal;
bool vis[MAXV];
LL dis[MAXV];
namespace Adj
{
// edge数组是一个边集数组,存放一条边的信息
// to --- 该条边的终点
// next --- 下一条要访问的边(存的是edge数组的下标).即:访问完了edge[i],下一条要访问的就是edge[edge[i].next],如果next为0,表示now这个节点作为起点的边已经全部访问完.(下一步:Q.front())
// w --- 该条边的权值
struct Node
{
int to,next,w;
};
Node edge[MAXE]; // idx --- edge数组的下标
// head[i] --- 表示以i节点为起点的所有出边在edge数组中的起始存储位置为head[i].(如果head[i]为0,表示结点i没有出边)
int idx,head[MAXV];
// 初始化
void init()
{
idx=;
memset(head,,sizeof(head));
} // 加边函数
void addEdge(int u,int v,int w) // 起点,终点,权值
{
edge[idx].to=v; // 该边的终点
edge[idx].w=w; // 权值
edge[idx].next=head[u]; // (指向head[u]后,head[u]又指向了自己)
head[u]=idx; // 以u结点为起点的边在edge数组中存储的下标
idx++;
}
}
using namespace Adj;
void visit(int sta)
{
for(int i=;i<=n;i++)
{
vis[i]=;
dis[i]=LLONG_MAX;
}
// 起点进队
queue<int>Q;
Q.push(sta);
vis[sta]=;
dis[sta]=;
while(!Q.empty())
{
int now=Q.front();
Q.pop();
vis[now]=; // 在spfa中这儿需要改为0,因为每个节点需要重复进队
for(int i=head[now];i;i=edge[i].next) //取出now结点在edge中的起始存储下标(当i=0,即edge[i].next为0,说明以now节点为起始点的边全部访问完)
{
int w=edge[i].w;
int son=edge[i].to;
printf("%d --> %d , weight = %d\n",now,edge[i].to,edge[i].w);
if(dis[now]+w<dis[son]) // 松弛操作
{
dis[son]=dis[now]+w;
if(!vis[son])
{
Q.push(son); // 子节点未访问过
vis[son]=; // 标记已访问
}
} }
}
puts("/*************************************** END ******************************************/");
for(int i=;i<=n;++i)
{
printf("%d --> %d shortest distance is %d\n",sta,i,dis[i]);
} } int main()
{
while()
{
Adj::init();
scanf("%d",&n);
scanf("%d",&m);
for(int i=;i<=m;++i) // 输入m条边
{
int s,e,w; // 起点 终点 权值
scanf("%d %d %d",&s,&e,&w);
addEdge(s,e,w); //若是无向图,反过来再加一次
}
int start_point; //访问的起点
scanf("%d",&start_point);
visit(start_point);
}
return ;
} /*
5 6
1 2 5
1 3 9
1 4 1
3 5 2
4 3 3
4 5 7
1
*/
SPFA + 链式前向星(详解)的更多相关文章
- UESTC30-最短路-Floyd最短路、spfa+链式前向星建图
最短路 Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) 在每年的校赛里,所有进入决赛的同 ...
- UESTC 30.最短路-最短路(Floyd or Spfa(链式前向星存图))
最短路 Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Others) 在每年的校赛里,所有进入决赛的同 ...
- POJ 3159 Candies(差分约束+spfa+链式前向星)
题目链接:http://poj.org/problem?id=3159 题目大意:给n个人派糖果,给出m组数据,每组数据包含A,B,C三个数,意思是A的糖果数比B少的个数不多于C,即B的糖果数 - A ...
- SPFA+链式前向星
板子 #include <bits/stdc++.h> using namespace std; typedef long long ll; const ll inf=2<<3 ...
- spfa+链式前向星模板
#include<bits/stdc++.h> #define inf 1<<30 using namespace std; struct Edge{ int nex,to,w ...
- POJ 3169 Layout(差分约束+链式前向星+SPFA)
描述 Like everyone else, cows like to stand close to their friends when queuing for feed. FJ has N (2 ...
- 链式前向星+SPFA
今天听说vector不开o2是数组时间复杂度常数的1.5倍,瞬间吓傻.然后就问好的图表达方式,然后看到了链式前向星.于是就写了一段链式前向星+SPFA的,和普通的vector+SPFA的对拍了下,速度 ...
- 单元最短路径算法模板汇总(Dijkstra, BF,SPFA),附链式前向星模板
一:dijkstra算法时间复杂度,用优先级队列优化的话,O((M+N)logN)求单源最短路径,要求所有边的权值非负.若图中出现权值为负的边,Dijkstra算法就会失效,求出的最短路径就可能是错的 ...
- 【模板】链式前向星+spfa
洛谷传送门--分糖果 博客--链式前向星 团队中一道题,数据很大,只能用链式前向星存储,spfa求单源最短路. 可做模板. #include <cstdio> #include <q ...
随机推荐
- (7)树莓派读物USB摄像头
https://blog.csdn.net/qq_42403190/article/details/90453305 创建文件 camera.py 简单读取 #!/usr/bin/env python ...
- git 提交代码报错failed to push some refs to 解决笔记
Administrator@SC- MINGW64 /e/gitrepository (master) $ git push django master To github.com:zgc137/dj ...
- javascript使用H5新版媒体接口navigator.mediaDevices.getUserMedia,做扫描二维码,并识别内容
本文代码测试要求,最新的chrome浏览器(手机APP),并且要允许chrome拍照录像权限,必须要HTTPS协议,http不支持. 原理:调用摄像头,将摄像头返回的媒体流渲染到视频标签中,再通过ca ...
- 论文阅读:Single Image Dehazing via Conditional Generative Adversarial Network
Single Image Dehazing via Conditional Generative Adversarial Network Runde Li∗ Jinshan Pan∗ Zechao L ...
- mysql 层级结构查询
描述:最近遇到了一个问题,在mysql中如何完成节点下的所有节点或节点上的所有父节点的查询? 在Oracle中我们知道有一个Hierarchical Queries可以通过CONNECT BY来查询, ...
- ubuntu之路——day20 昨天和今天搞定Res18并在GPU上运行 明天YOLO在车辆识别上试一下
- sql查询条件参数为空
查询某些值为空的数据 select * from usertable where name is null or page is null
- javascript的Map使用
setExpenseAndAmountSum: function() { var detailList = vehicleVueObj.vehicleData; var expenseAmountSu ...
- JPA的懒加载
JPA数据懒加载LAZY和实时加载EAGER(二) 懒加载LAZY和实时加载EAGER的概念,在各种开发语言中都有广泛应用.其目的是实现关联数据的选择性加载,懒加载是在属性被引用时,才生成查询语句 ...
- [oracle/java/sql]用于上十万批量数据插入Oracle表的Java程序
程序下载:https://files.cnblogs.com/files/xiandedanteng/LeftInnerNotExist20191222.rar 原理:Oracle的Insert al ...