SparkStreaming+kafka Receiver模式
1.图解
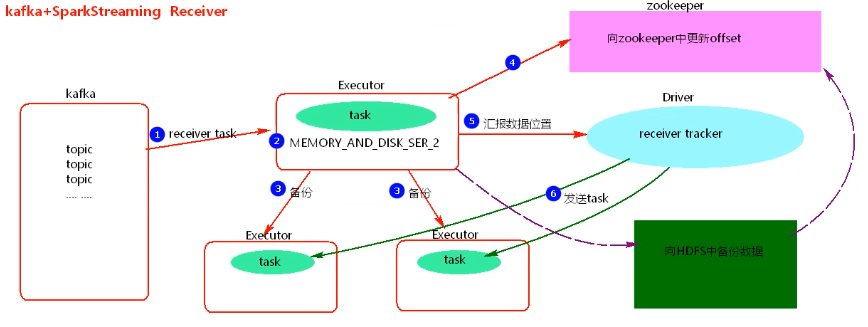
2.过程
1.使用Kafka的High Level Consumer API 实现,消费者不能自己去维护消费者offset,而且kafka也不关心数据是否丢失。
2.当向zookeeper中更新完offset后,Driver如果挂到,Driver下的Executors会被kill掉,会造成数据丢失。
3.开启WAL【Write Ahead Log】预写日志机制,将数据备份到HDFS中一份,再去更新zookeeper中的offset,此时需调整spark存储基本,去掉备份两次【MEMORY_AND_DISK_SER_2中的_2】。开启WAL机制会加大application处理的时间。
3.特点
1.receiver模式依赖zookeeper管理offset。
2.receiver模式的并行度由spark.streaming.blockInterval决定,默认是200ms。
3.receiver模式接收block.batch数据后会封装到RDD中,这里的block对应RDD中的partition。
4.在batchInterval一定的情况下,减少spark.streaming.Interval参数值,会增大DStream中的partition个数,建议spark.streaming.Interval最低不能低于50ms。
4.代码实现
package big.data.analyse.streaming import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkContext, SparkConf} /**
* Created by zhen on 2019/5/11.
*/
object SparkStreamingReceiverKafka {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("SparkStreamingReceiverKafka")
conf.set("spark.streaming.kafka.maxRatePerPartition", "")
conf.setMaster("local[2]") val sc = new SparkContext(conf)
sc.setLogLevel("WARN") val ssc = new StreamingContext(sc, Seconds()) // 创建streamingcontext入口 val quorum = "master,worker1,worker2"
val groupId = "zhenGroup"
val map : Map[String, Int] = Map("zhenTopic" -> ) // topic名称为zhenTopic,每次使用1个线程读取数据 val dframe = KafkaUtils.createStream(ssc, quorum, groupId, map, StorageLevel.MEMORY_AND_DISK_SER_2) dframe.foreachRDD(rdd => { // 操作方式和rdd类似,必须使用action算子才会触发程序执行!
rdd.foreachPartition(partition =>{
partition.foreach(println)
})
})
}
}
SparkStreaming+kafka Receiver模式的更多相关文章
- 【Spark篇】---SparkStreaming+Kafka的两种模式receiver模式和Direct模式
一.前述 SparkStreamin是流式问题的解决的代表,一般结合kafka使用,所以本文着重讲解sparkStreaming+kafka两种模式. 二.具体 1.Receiver模式 原理图 ...
- SparkStreaming+Kafka 处理实时WIFI数据
业务背景 技术选型 Kafka Producer SparkStreaming 接收Kafka数据流 基于Receiver接收数据 直连方式读取kafka数据 Direct连接示例 使用Zookeep ...
- SparkStreaming+Kafka整合
SparkStreaming+Kafka整合 1.需求 使用SparkStreaming,并且结合Kafka,获取实时道路交通拥堵情况信息. 2.目的 对监控点平均车速进行监控,可以实时获取交通拥堵情 ...
- [Spark]Spark-streaming通过Receiver方式实时消费Kafka流程(Yarn-cluster)
1.启动zookeeper 2.启动kafka服务(broker) [root@master kafka_2.11-0.10.2.1]# ./bin/kafka-server-start.sh con ...
- 【SparkStreaming学习之四】 SparkStreaming+kafka管理消费offset
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Spark-Streaming kafka count 案例
Streaming 统计来自 kafka 的数据,这里涉及到的比较,kafka 的数据是使用从 flume 获取到的,这里相当于一个小的案例. 1. 启动 kafka Spark-Streaming ...
- Kafka KRaft模式探索
1.概述 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据.其核心组件包含Producer.Broker.Consumer,以及依赖的Zookeeper集群. ...
- kafka单机模式部署安装,zookeeper启动
在root的用户下 1):前提 安装JDK环境,设置JAVA环境变量 2):下载kafka,命令:wget http://mirrors.shuosc.org/apache/kafka/0.10.2 ...
- java kafka单列模式生产者客户端
1.所需要的依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="ht ...
随机推荐
- java 日志框架 pom配置
使用log4j https://blog.csdn.net/qq_37936542/article/details/80839389[slf4j+logback实现web项目日志输出] 只需引入一个包 ...
- Html表格和表头文字不换行
[本文出自天外归云的博客园] 希望表头中的文字和表格中的文字不换行,只需要在th和td标签加上: nowrap="nowrap"
- c# 通过win32 api 得到指定Console application Content
已知的问题: 1. 调试的时候会报IO 异常,非调试环境是正常的 2. Windows 应用程序才可以使用,可以用非windows应用程序包一层 using System; using System. ...
- 工控随笔_24_西门子TIA 博图硬件目录的更新
西门子博图软件,不但体积庞大,功能也很复杂,与经典的Step7相比,如果不是经常使用,一般都会有一种很难使用的感觉. 而且相比原来的Step7操作有点不太一样.这里简单的说一下硬件目录的更新. 有两种 ...
- [LeetCode] 901. Online Stock Span 线上股票跨度
Write a class StockSpanner which collects daily price quotes for some stock, and returns the span of ...
- 最常见的Java面试题及答案汇总(三)
上一篇:最常见的Java面试题及答案汇总(二) 多线程 35. 并行和并发有什么区别? 并行是指两个或者多个事件在同一时刻发生:而并发是指两个或多个事件在同一时间间隔发生. 并行是在不同实体上的多个事 ...
- Node.js实现PC端类微信聊天软件(四)
Github StackChat 学习回顾 React和Electron结合 TypeError: fs.existsSync is not a function 在React组件里引入electro ...
- 修复Nginx报错:upstream sent too big header while reading response header from upstream
在 nginx.conf 的http段,加入下面的配置: proxy_buffer_size 128k; proxy_buffers 32k; proxy_busy_buffers_size 128k ...
- Ubuntu下载源码并编译
本文章将介绍如何在Ubunt下进行Linux源码下载,并进行简单的编译步骤. 1.下载linux源码 先查看对应的Ubuntu对应版本源码 $ sudo apt-cache search linux- ...
- [转帖]8个最佳Docker容器监控工具,收藏了
8个最佳Docker容器监控工具,收藏了 https://www.sohu.com/a/341156793_100159565?spm=smpc.author.fd-d.9.1574127778732 ...