PostgreSQL 缓存
PostgreSQL physical storage和 inter db 值得阅读
数据在物理介质上存储是以page的形式,大小为8K,如下:
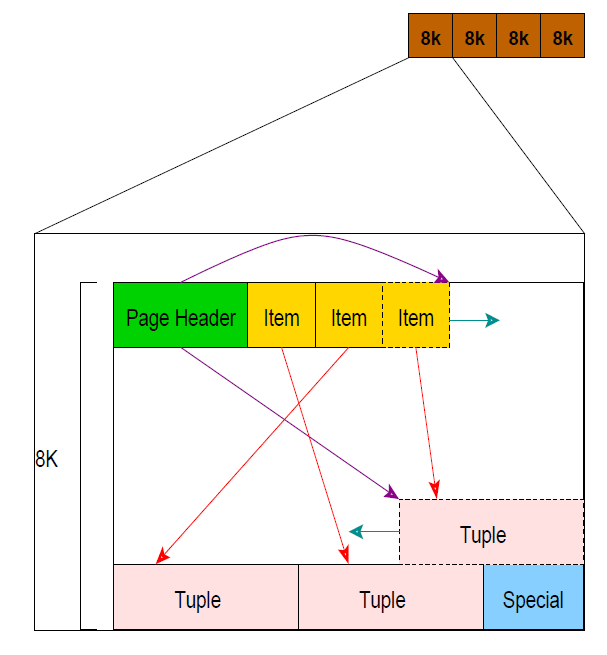
- a
tuple或anitem是行的同义词 - a
relation是表的同义词 - a
filenode是表示对表或索引的引用的id。 - a
block和page是等于它们代表存储表的文件的8kb段信息。
PostgreSQL会把table数据和index以page的形式存储在缓存中,同时在某些情况下(使用 prepared)也会把查询计划缓存下来,但是不会去缓存具体的查询结果。它是把查询到的数据页缓存起来,这个页会包含连续的数据,即不仅仅是你所要的查询的数据。
缓存指的是共享缓存,shared_buffers,所代表的内存区域可以看成是一个以8KB的block为单位的数组,即最小的分配单位是8KB。当Postgres想要从disk获取(主要是table和index)数据(page)时,他会(根据page的元数据)先搜索shared_buffers,确认该page是否在shared_buffers中,如果存在,则直接命中,返回缓存的数据以避免I/O。如果不存在,Postgres才会通过I/O访问disk获取数据。
缓冲区的分配
我们知道Postgres是基于进程工作的系统,即对于每一个服务器的connection,Postgres主进程都会向操作系统fork一个新的子进程(backend)去提供服务。同时,Postgres本身除了主进程之外也会起一些辅助的进程。
因此,对于每一个connection的数据请求,对应的后端进程(backend)都会首先向LRU cache中请求数据页page(这个数据请求不一定指的是SQL直接查询的表或者视图的page,比如index和系统表),这个时候就发起了一次缓冲区的分配请求。那么,这个时候我们就要抉择了。如果要请求的block就在cache中,那最好,我们"pinned"这个block,并且返回cache中的数据。所谓的"pinned"指的是增加这个block的"usage count"。
当"usage count"为0时,我们就认为这个block没用了,在后面cache满的时候,它就该挪挪窝了。
那也就是说,只有当buffers/slots已满的情况下,才会引发缓存区的换出操作。
缓存区的换出
决定哪个page该从内存中换出并写回到disk中,这是一个经典的计算机科学的问题。
一个最简单的LRU算法在实际情况下基本上很难work起来。因为LRU是要把最近最少使用的page换出去,但是我们没有记录上次运行时的状态。
因此,作为一个折中和替代,我们追踪并记录每个page的"usage count",在有需要时,将那些"usage count"为0的page换出并写回到disk中。后面也会提到,脏页面也会被写回disk。
PostgreSQL 缓存的更多相关文章
- PostgreSQL缓存
目录[-] pg_buffercache pgfincore pg_prewarm dstat Linux ftools 使用pg_prewarm预加载关系/索引: pgfincore 输出: 怎样刷 ...
- 【转】2016/2017 Web 开发者路线图
链接:知乎 [点击查看大图] 原图来自LearnCodeAcademy最火的视频,learncode是YouTube上最火的Web开发教学频道,介绍包括HTML/CSS/JavaScript/Subl ...
- 如何使用Docker部署PHP开发环境
本文主要介绍了如何使用Docker构建PHP的开发环境,文中作者也探讨了构建基于Docker的开发环境应该使用单容器还是多容器,各有什么利弊.推荐PHP开发者阅读.希望对大家有所帮助. 环境部署一直是 ...
- Django---进阶12
目录 Auth模块 方法总结 如何扩展auth_user表 项目开发流程 表设计 作业 Auth模块 """ 其实我们在创建好一个django项目之后直接执行数据库迁移命 ...
- day71 django收尾
目录 一.Auth模块 1 简介 2 方法总结 3 如何扩展auth_user表 二.bbs表介绍 1 项目开发流程 2 bbs七张表关系 一.Auth模块 1 简介 在我们创建好一个django项目 ...
- Django学习day13随堂笔记
每日测验 """ 今日考题 1.什么是django中间件,它的作用是什么,如何自定义中间件,里面有哪些用户可以自定义的方法,这些方法有何特点 2.基于django中间件的 ...
- Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性
摘要:对于 PostgreSQL 的实时数据采集, 业界经常遇到了包括:对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂等等问题.Tapdata 在解决 Pos ...
- CentOS7下安装并简单设置PostgreSQL笔记
为什么是PostgreSQL? 在.NET Core诞生之前,微软平台上最常见的开发组件便是.NET Framework + SQL Server了,但是现在.NET Core终于让跨平台部署成为了现 ...
- 影响postgresql性能的几个重要参数
转载 一篇蛮老的文章了,但是还是很有用,可参考修补. PG的配置文件是数据库目录下的postgresql.conf文件,8.0以后的版本可支持K,M,G这样的参数,只要修改相应参数后重新启动PG服务就 ...
随机推荐
- rabbitMQ基础应用
1.安装erlang [root@localhost ~]#yum -y install erlang 2.安装rabbitMQ [root@localhost ~]#yum -y install r ...
- 2019 大众书网Java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.大众书网等公司offer,岗位是Java后端开发,因为发展原因最终选择去了大众书网,入职一年时间了,也成为了面 ...
- 把JSON数据格式转换为Python的类对象
JOSN字符串转换为自定义类实例对象 有时候我们有这种需求就是把一个JSON字符串转换为一个具体的Python类的实例,比如你接收到这样一个JSON字符串如下: {"Name": ...
- JS面向对象设计-创建对象
Object构造函数和对象字面量都可以用来创建单个对象,但是在创建多个对象时,会产生大量重复代码. 1.工厂模式 工厂模式抽象了创建具体对象的过程.由于ECMAScript无法创建类,我们用函数来封装 ...
- 要什么 Photoshop,会这些 CSS 就够了
标题党一时爽,一直标题党一直爽 还在上大学那会儿,我就喜欢玩 Photoshop.后来写网页的时候,由于自己太菜,好多花里胡哨的效果都得借助 Photoshop 实现,当时就特别希望 CSS 能像 P ...
- Qt之Q_PROPERTY宏理解
在初学Qt的过程中,时不时地要通过F2快捷键来查看QT类的定义,发现类定义中有许多Q_PROPERTY的东西,比如最常用的QWidget的类定义: Qt中的Q_PROPERTY宏在Qt中是很常用的,那 ...
- springboot入门介绍
1. SpringBoot学习之@SpringBootApplication注解 下面是我们经常见到SpringBoot启动类代码: @SpringBootApplicationpublic clas ...
- 解决debugJDK源码看不到局部变量的值
背景:使用的jdk1.8.0_201 问题描述:在eclispe中调试代码进入到JDK源码中,想看到某个变量的值得变化,发现此变量的值没法看到 解决方案: 1.进入到你安装本机的jdk目录下,找到sr ...
- php获取ssl验证的https页面的源码
$response = "https://faculty.xidian.edu.cn/system/resource/tsites/tsitesencrypt.jsp?id=_tsites_ ...
- Linux操作系统安全-使用gpg实现对称加密
Linux操作系统安全-使用gpg实现对称加密 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.gpg工具包概述 1>.什么是gpg GnuPG是GNU负责安全通信和数据存 ...