LCA 学习算法 (最近的共同祖先)poj 1330
Nearest Common Ancestors
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 20983 | Accepted: 11017 |
Description
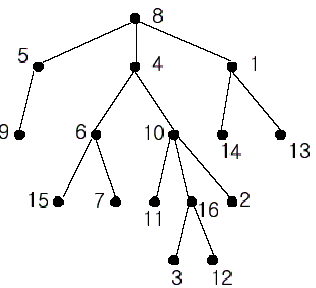
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor
of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node
x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common
ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest
common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
N. Each of the next N -1 lines contains a pair of integers that represent an edge --the first integer is the parent node of the second integer. Note that a tree with N nodes has exactly N - 1 edges. The last line of each test case contains two distinct integers
whose nearest common ancestor is to be computed.
Output
Sample Input
2
16
1 14
8 5
10 16
5 9
4 6
8 4
4 10
1 13
6 15
10 11
6 7
10 2
16 3
8 1
16 12
16 7
5
2 3
3 4
3 1
1 5
3 5
Sample Output
4
3
在求解近期公共祖先为问题上,用到的是Tarjan的思想,从根结点開始形成一棵深搜树。处理技巧就是在回溯到结点u的时候。u的子树已经遍历。这时候才把u结点放入合并集合中,这样u结点和全部u的子树中的结点的近期公共祖先就是u了,u和还未遍历的全部u的兄弟结点及子树中的近期公共祖先就是u的父亲结点。
这样我们在对树深度遍历的时候就非常自然的将树中的结点分成若干的集合,两个集合中的所属不同集合的随意一对顶点的公共祖先都是同样的,也就是说这两个集合的近期公共祖先仅仅有一个。时间复杂度为O(n+q),n为节点,q为询问节点对数。
#include"stdio.h"
#include"string.h"
#include"vector"
using namespace std;
#define N 11000
const int inf=1<<20;
vector<int>g[N];
int s,t,n;
int f[N],pre[N],ans[N];
bool vis[N];
int findset(int x)
{
if(x!=f[x])
f[x]=findset(f[x]);
return f[x];
}
int unionset(int a,int b)
{
int x=findset(a);
int y=findset(b);
if(x==y)
return x;
f[y]=x;
return x;
}
void lca(int u)
{
int i,v;
ans[u]=u;
for(i=0;i<g[u].size();i++)
{
v=g[u][i]; //訪问由父节点引出的各个子节点
lca(v);
int x=unionset(u,v); //把父子节点合并
ans[x]=u; //祖先节点记为U
}
vis[u]=1;
if(u==s&&vis[t]) //两个节点依次被訪问标记,第二次訪问时才满足条件
{
printf("%d\n",ans[findset(t)]);
return ;
}
else if(u==t&&vis[s])
{
printf("%d\n",ans[findset(s)]);
return ;
}
}
int main()
{
int i,u,v,T;
scanf("%d",&T);
while(T--)
{
scanf("%d",&n);
for(i=1;i<=n;i++)
{
pre[i]=-1; //记录节点I的父节点
f[i]=i; //并查集记录根节点
vis[i]=0;
g[i].clear();
}
for(i=1;i<n;i++)
{
scanf("%d%d",&u,&v);
g[u].push_back(v);
pre[v]=u;
}
scanf("%d%d",&s,&t);
for(i=1;i<=n;i++)
if(pre[i]==-1)
break;
lca(i);
}
return 0;
}
版权声明:本文博客原创文章,博客,未经同意,不得转载。
LCA 学习算法 (最近的共同祖先)poj 1330的更多相关文章
- [最近公共祖先] POJ 1330 Nearest Common Ancestors
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 27316 Accept ...
- POJ 1330 Nearest Common Ancestors (LCA,倍增算法,在线算法)
/* *********************************************** Author :kuangbin Created Time :2013-9-5 9:45:17 F ...
- POJ 1330 Nearest Common Ancestors 倍增算法的LCA
POJ 1330 Nearest Common Ancestors 题意:最近公共祖先的裸题 思路:LCA和ST我们已经很熟悉了,但是这里的f[i][j]却有相似却又不同的含义.f[i][j]表示i节 ...
- POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA)
POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA) Description A ...
- POJ 1330 Nearest Common Ancestors (LCA,dfs+ST在线算法)
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 14902 Accept ...
- POJ - 1330 Nearest Common Ancestors(dfs+ST在线算法|LCA倍增法)
1.输入树中的节点数N,输入树中的N-1条边.最后输入2个点,输出它们的最近公共祖先. 2.裸的最近公共祖先. 3. dfs+ST在线算法: /* LCA(POJ 1330) 在线算法 DFS+ST ...
- 最近公共祖先LCA(Tarjan算法)的思考和算法实现
LCA 最近公共祖先 Tarjan(离线)算法的基本思路及其算法实现 小广告:METO CODE 安溪一中信息学在线评测系统(OJ) //由于这是第一篇博客..有点瑕疵...比如我把false写成了f ...
- 最近公共祖先 LCA 倍增算法
树上倍增求LCA LCA指的是最近公共祖先(Least Common Ancestors),如下图所示: 4和5的LCA就是2 那怎么求呢?最粗暴的方法就是先dfs一次,处理出每个点的深度 ...
- POJ 1986 Distance Queries (Tarjan算法求最近公共祖先)
题目链接 Description Farmer John's cows refused to run in his marathon since he chose a path much too lo ...
随机推荐
- [C++]函数参数浅析
Date:2014-1-9 Summary: 函数参数相关记录 Contents:1.形参实参 形参:用于接收值的变量被称为形参 实参:传递给函数的值被称为实参 2.函数的参数传递之后2种 a).值传 ...
- 成都Java培训机构太多,该如何选择呢?
Java培训的势头愈发火热.越来越多的人看到了Java培训的前途所在,可是最好的Java培训机构是哪家呢?如何推断一家Java培训机构的专业性呢?140610lscs" target=&qu ...
- 解决AngularJS和Django模板标签冲突问题
原地址 Django和AngularJS在模板中使用同样的符号来引用变量,例如 {{variable_name}}. 有两种解决办法,各有利弊.一个修改AngularJS模板语法,另一个使用Djang ...
- random_shuffle (stl算法)打乱顺序 - 飞不会的日志 - 网易博客
random_shuffle (stl算法)打乱顺序 - 飞不会的日志 - 网易博客 random_shuffle (stl算法)打乱顺序 2012-03-31 10:39:11| 分类: 算法 | ...
- Android 调用谷歌语音识别
調用谷歌语音识别其实很简单,直接利用 intent 跳转到手机里面的谷歌搜索 代码也很简单,直接调用方法 startVoiceRecognitionActivity() 如果大家手机里面没有谷歌搜索, ...
- 关于identifier was truncated to '255' characters
学习c++过程中,遇到在VC中使用set时DEBUG模式出现的警告 identifier was truncated to '255' characters in the debug informat ...
- BZOJ 1109 POI2007 堆积木Klo LIS
题目大意:给定一个序列,能够多次将某个位置的数删掉并将后面全部数向左串一位,要求操作后a[i]=i的数最多 首先我们如果最后a[i]=i的数的序列为S 那么S满足随着i递增,a[i]递增(相对位置不变 ...
- SQL参数化查询的问题
最近碰到个问题, SQL语句中的 "... like '%@strKeyword%'"这样写查不出结果, 非的写成 "... like '%" + strKey ...
- css 背景色渐变
background:rgba(0, 0, 0, 0) linear-gradient(to bottom, #eff5ff 0px, #e0ecff 20%) repeat-x scroll 0 0 ...
- 神经网络BP算法C和python代码
上面只显示代码. 详BP原理和神经网络的相关知识,请参阅:神经网络和反向传播算法推导 首先是前向传播的计算: 输入: 首先为正整数 n.m.p.t,分别代表特征个数.训练样本个数.隐藏层神经元个数.输 ...