reshape2 数据操作 数据融合 (melt)
前面一篇讲了cast,想必已经见识到了reshape2的强大,当然在使用cast时配合上melt这种强大的揉数据能力才能表现的淋漓尽致。
下面我们来看下,melt这个函数以及它的特点。
melt(data, ..., na.rm = FALSE, value.name = "value")
从这里来看函数的参数也相对比较简单,data表示要处理的数据,na.rm表示缺失值处理办法,value.name用于重命名值所在列的名称
另外,melt函数的难点在于,不同数据结构,用到的参数可能是不一样的。
首先,要融合的数据为数组、表以及矩阵,那么melt的表达式为:
melt(data, varnames = names(dimnames(data)), ..., na.rm = FALSE, as.is = FALSE, value.name = "value")
varnames用户命名变量名称
其次,要融合的数据为数据框,那么melt的表达式为:
melt(data, id.vars, measure.vars, variable.name = "variable", ..., na.rm = FALSE, value.name = "value", factorsAsStrings = TRUE)
id.vars 设置融合后单独显示的变量,可以用变量位置及名称表示,没写表示使用所有非measure.vars值
measure.vars 通常根据id.vars 设置的变化而变化
最后,要融合的数据为列表,那么melt的表达式为:
melt(data, ..., level = 1)
下面来看些具体的例子
data<- array(c(1:22, NA,"wo"), c(2,3,4))
data

melt(data)
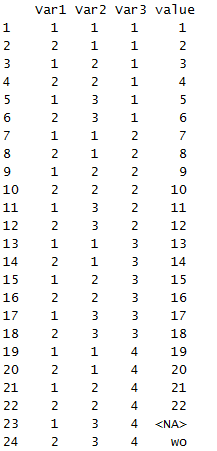
可以看出数据融合后,可读性比数组的情况下强了好多,var1表示数组的行,var2表示数组的列,var3表示数组序列。
比如,18位置就是第3数组,2行3列的位置,11则是第2数组,1行3列。
melt(a, na.rm = TRUE)

可以看到数组中的缺失值被移除了。
melt(data, varnames=c("hang","lie","Zu"))
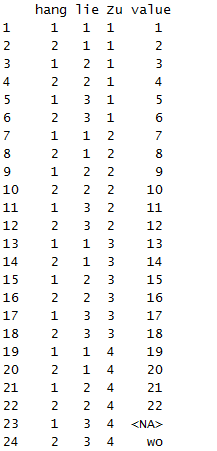
对融合后的每个变量进行重命名。
下面来看下数据为数据框的情况。
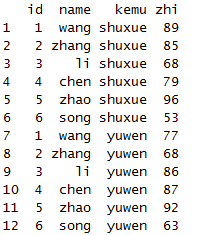
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63))
x
melt(x,id=c("id","name"))
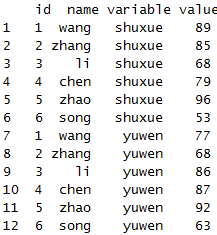
melt(x,id=1:2,variable.name="kemu",value.name="zhi")
melt(x,measure.vars=c("id","name"))
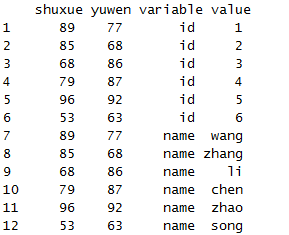
最后,来看下如果数据是列表的情况
shuju<- list(matrix(1:4, ncol=2), array(1:27, c(3,3,3)))
shuju

这个列表的机构比较复杂,读起来有点难度
下面melt融合后的结果
melt(shuju)
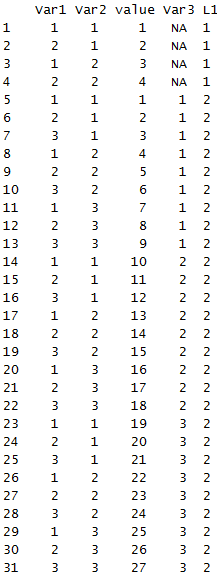
可以看出数据变得非常简洁。
reshape2 数据操作 数据融合 (melt)的更多相关文章
- reshape2 数据操作 数据融合( cast)
我们在做数据分析的时候,对数据进行操作也是一项极其重要的内容,这里我们同样介绍强大包reshape2,其中的几个函数,对数据进行操作cast和melt两个函数绝对少不了. 首先是cast,把长型数据转 ...
- dplyr 数据操作 数据排序 (arrange)
在R中,我们在整理数据时,经常需要对数据排序,以便数据增强数据的可读性. 下面我们来看下dplyr中的,arrange函数 arrange(.data, ...) 跟filter()类似,arrang ...
- dplyr 数据操作 数据过滤 (filter)
在R的使用过程中我们几乎都绕不开Hadley Wickham 开发的几个包,前面说过的ggplot2.reshape2以及即将要讲的dplyr 因为这几个包可以非常轻易的使我们从复杂的数据操作中逃离, ...
- HIVE之 DDL 数据定义 & DML数据操作
DDL数据库定义 创建数据库 1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db. hive (default)> create dat ...
- pandas模块的数据操作
数据操作 数据操作最重要的一步也是第一步就是收集数据,而收集数据的方式有很多种,第一种就是我们已经将数据下载到了本地,在本地通过文件进行访问,第二种就是需要到网站的API处获取数据或者网页上爬取数据, ...
- Appium+python自动化(三十)- 实现代码与数据分离 - 数据配置-yaml(超详解)
简介 本篇文章主要介绍了python中yaml配置文件模块的使用让其完成数据和代码的分离,宏哥觉得挺不错的,于是就义无反顾地分享给大家,也给大家做个参考.一起跟随宏哥过来看看吧. 思考问题 前面我们配 ...
- R︱高效数据操作——data.table包(实战心得、dplyr对比、key灵活用法、数据合并)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 由于业务中接触的数据量很大,于是不得不转战开始 ...
- Redis 安装,配置以及数据操作
Nosql介绍 Nosql:一类新出现的数据库(not only sql)的特点 不支持SQL语法 存储结构跟传统关系型数据库中那种关系表完全不同,nosql中存储的数据都是k-v形式 Nosql的世 ...
- MySQL 数据操作与查询笔记 • 【第1章 MySQL数据库基础】
全部章节 >>>> 本章目录 1.1 数据库简介 1.1.1 数据和数据库定义 1.1.2 数据库发展阶段 1.1.3 数据库系统组成 1.1.4 关系型数据库 1.2 M ...
随机推荐
- AR/VR行业是否会像智能手机一样的飞速崛起
从硬件和内容两方面来看,VR(虚拟现实)应该会比AR(增强现实)率先普及大众.当然,这是建立在解决无线化.眩晕.便携等问题之后的事儿,内容上不用担心,照现在这个发展速度-- 说到"风口&qu ...
- java 报表到excel
现加个jar包 http://pan.baidu.com/s/1boe5kXh vfp8 然后代码 package makeReportToExcel; import java.io.File; ...
- IOS网络请求中文转码
-(void)get { NSString *urlStr = @"http://120.25.226.186:32812/login2?username=小码哥&pwd=520it ...
- 各类数据库url
msql: jdbc:mysql://127.0.0.1:3306/databaseName ms-sql jdbc:microsoft:sqlserver://127.0.0.1:1433;Data ...
- C++内存池
内存池是一种内存分配方式.通常我们习惯直接使用new.malloc等API申请分配内存,这样做的缺点在于:由于所申请内存块的大小不定,当频繁使用时会造成大量的内存碎片.并由于频繁的分配和回收内存会降低 ...
- Java写入文件
import java.io.File;import java.io.FileNotFoundException;import java.io.PrintWriter; public class Fi ...
- CodeForces 671A Recycling Bottles
暴力. 每个人找到一个入口,也就是从回收站到这个入口走的路程由人的位置到入口的路程来替代. 因此,只要找两个人分别从哪里入口就可以了.注意:有可能只要一个人走,另一人不走. #pragma comme ...
- 爬虫代码实现五:解析所有分页url并优化解析实现类
如图,我们进入优酷首页,可以看到电视剧列表,我们称这个页面为电视剧列表页,而点击进入某个电视剧,则称为电视剧详情页.那么如何获取所有分页以及对应的详情页呢,通过下面的分页得到. 因此,首先,我们将St ...
- 【IIS】windows2008 ii7 设置访问网站提示帐号密码登录
3个步骤: 1.添加windows身份验证: windows2008默认是不启用的,需要我们自己去启动,在管理工具 - 服务器管理- 角色 ,拉下去,下面有个[添加角色服务],安全性- Windows ...
- layer ifram 弹出框
父层 <div class="col-xs-4 text-left" style="padding-left: 50px;"><button ...