Boosting算法简介
一、Boosting算法的发展历史
Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boostrapping方法和bagging方法。我们先简要介绍一下bootstrapping方法和bagging方法。
1)bootstrapping方法的主要过程
主要步骤:
i)重复地从一个样本集合D中采样n个样本
ii)针对每次采样的子样本集,进行统计学习,获得假设Hi
iii)将若干个假设进行组合,形成最终的假设Hfinal
iv)将最终的假设用于具体的分类任务
2)bagging方法的主要过程
主要思路:
i)训练分类器
从整体样本集合中,抽样n* < N个样本 针对抽样的集合训练分类器Ci
ii)分类器进行投票,最终的结果是分类器投票的优胜结果
但是,上述这两种方法,都只是将分类器进行简单的组合,实际上,并没有发挥出分类器组合的威力来。直到1989年,Yoav Freund与 Robert Schapire提出了一种可行的将弱分类器组合为强分类器的方法。并由此而获得了2003年的哥德尔奖(Godel price)。
Schapire还提出了一种早期的boosting算法,其主要过程如下:
i)从样本整体集合D中,不放回的随机抽样n1 < n 个样本,得到集合 D1
训练弱分类器C1
ii)从样本整体集合D中,抽取 n2 < n 个样本,其中合并进一半被 C1 分类错误的样本。得到样本集合 D2
训练弱分类器C2
iii)抽取D样本集合中,C1 和 C2 分类不一致样本,组成D3
训练弱分类器C3
iv)用三个分类器做投票,得到最后分类结果
到了1995年,Freund and schapire提出了现在的adaboost算法,其主要框架可以描述为:
i)循环迭代多次
更新样本分布
寻找当前分布下的最优弱分类器
计算弱分类器误差率
ii)聚合多次训练的弱分类器
在下图中可以看到完整的adaboost算法:

现在,boost算法有了很大的发展,出现了很多的其他boost算法,例如:logitboost算法,gentleboost算法等等。在这次报告中,我们将着重介绍adaboost算法的过程和特性。
二、Adaboost算法及分析
从图1.1中,我们可以看到adaboost的一个详细的算法过程。Adaboost是一种比较有特点的算法,可以总结如下:
1)每次迭代改变的是样本的分布,而不是重复采样(re weight)
2)样本分布的改变取决于样本是否被正确分类
总是分类正确的样本权值低
总是分类错误的样本权值高(通常是边界附近的样本)
3)最终的结果是弱分类器的加权组合
权值表示该弱分类器的性能
简单来说,Adaboost有很多优点:
1)adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单
4)简单,不用做特征筛选
5)不用担心overfitting!
总之:adaboost是简单,有效。
下面我们举一个简单的例子来看看adaboost的实现过程:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:
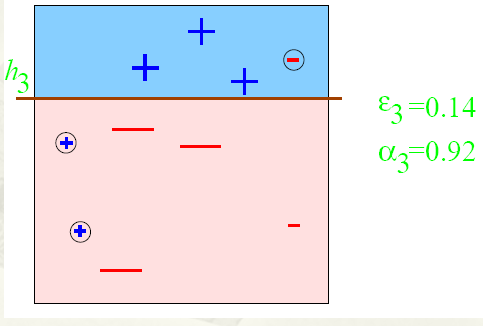
得到一个子分类器h3
整合所有子分类器:
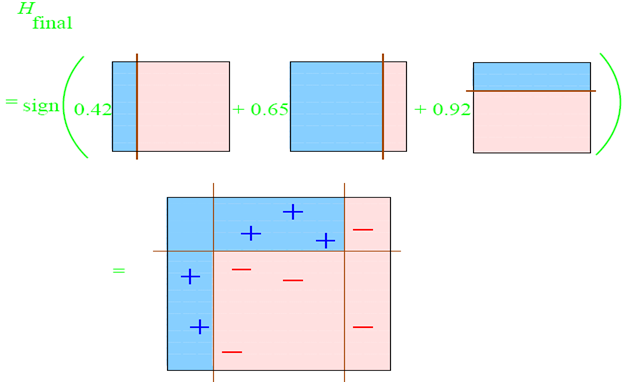
因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
Adaboost算法的某些特性是非常好的,在我们的报告中,主要介绍adaboost的两个特性。一是训练的错误率上界,随着迭代次数的增加,会逐渐下降;二是adaboost算法即使训练次数很多,也不会出现过拟合的问题。
下面主要通过证明过程和图表来描述这两个特性:
1)错误率上界下降的特性
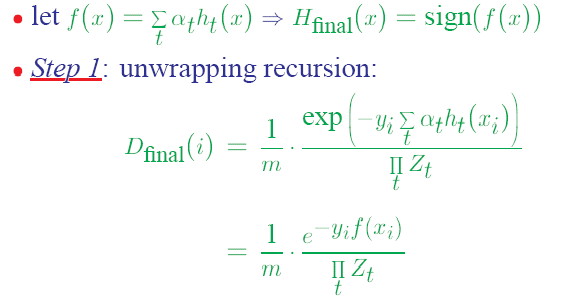


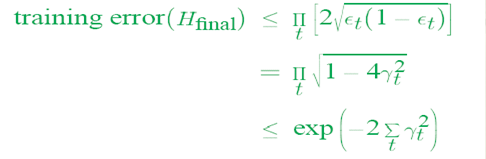
从而可以看出,随着迭代次数的增加,实际上错误率上界在下降。
2)不会出现过拟合现象
通常,过拟合现象指的是下图描述的这种现象,即随着模型训练误差的下降,实际上,模型的泛化误差(测试误差)在上升。横轴表示迭代的次数,纵轴表示训练误差的值。
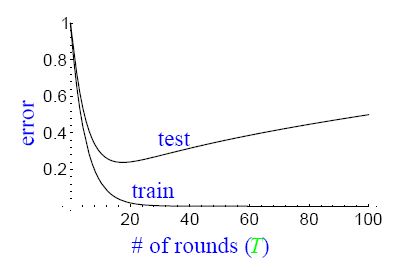
而实际上,并没有观察到adaboost算法出现这样的情况,即当训练误差小到一定程度以后,继续训练,返回误差仍然不会增加。
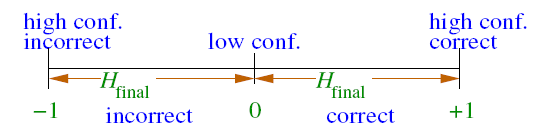
对这种现象的解释,要借助margin的概念,其中margin表示如下:
通过引入margin的概念,我们可以观察到下图所出现的现象:
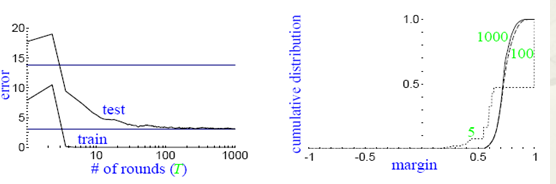
从图上左边的子图可以看到,随着训练次数的增加,test的误差率并没有升高,同时对应着右边的子图可以看到,随着训练次数的增加,margin一直在增加。这就是说,在训练误差下降到一定程度以后,更多的训练,会增加分类器的分类margin,这个过程也能够防止测试误差的上升。
三、多分类adaboost
在日常任务中,我们通常需要去解决多分类的问题。而前面的介绍中,adaboost算法只能适用于二分类的情况。因此,在这一小节中,我们着重介绍如何将adaboost算法调整到适合处理多分类任务的方法。
目前有三种比较常用的将二分类adaboost方法。
1、adaboost M1方法
主要思路: adaboost组合的若干个弱分类器本身就是多分类的分类器。
在训练的时候,样本权重空间的计算方法,仍然为:

在解码的时候,选择一个最有可能的分类
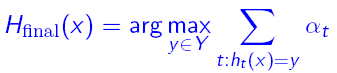
2、adaboost MH方法
主要思路: 组合的弱分类器仍然是二分类的分类器,将分类label和分类样例组合,生成N个样本,在这个新的样本空间上训练分类器。
可以用下图来表示其原理:
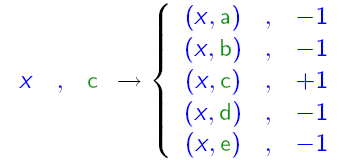
3、对多分类输出进行二进制编码
主要思路:对N个label进行二进制编码,例如用m位二进制数表示一个label。然后训练m个二分类分类器,在解码时生成m位的二进制数。从而对应到一个label上。
四、总结
最后,我们可以总结下adaboost算法的一些实际可以使用的场景:
1)用于二分类或多分类的应用场景
2)用于做分类任务的baseline
无脑化,简单,不会overfitting,不用调分类器
3)用于特征选择(feature selection)
4)Boosting框架用于对badcase的修正
只需要增加新的分类器,不需要变动原有分类器
由于adaboost算法是一种实现简单,应用也很简单的算法。Adaboost算法通过组合弱分类器而得到强分类器,同时具有分类错误率上界随着训练增加而稳定下降,不会过拟合等的性质,应该说是一种很适合于在各种分类场景下应用的算法。
Boosting算法简介的更多相关文章
- Gradient Boosting算法简介
最近项目中涉及基于Gradient Boosting Regression 算法拟合时间序列曲线的内容,利用python机器学习包 scikit-learn 中的GradientBoostingReg ...
- webrtc 的回声抵消(aec、aecm)算法简介(转)
webrtc 的回声抵消(aec.aecm)算法简介 webrtc 的回声抵消(aec.aecm)算法主要包括以下几个重要模块:1.回声时延估计 2.NLMS(归一化最小均方自适应算法) ...
- AES算法简介
AES算法简介 一. AES的结构 1.总体结构 明文分组的长度为128位即16字节,密钥长度可以为16,24或者32字节(128,192,256位).根据密钥的长度,算法被称为AES-128,AES ...
- 排列熵算法简介及c#实现
一. 排列熵算法简介: 排列熵算法(Permutation Entroy)为度量时间序列复杂性的一种方法,算法描述如下: 设一维时间序列: 采用相空间重构延迟坐标法对X中任一元素x(i)进行相空间 ...
- <算法图解>读书笔记:第1章 算法简介
阅读书籍:[美]Aditya Bhargava◎著 袁国忠◎译.人民邮电出版社.<算法图解> 第1章 算法简介 1.2 二分查找 一般而言,对于包含n个元素的列表,用二分查找最多需要\(l ...
- LARS 最小角回归算法简介
最近开始看Elements of Statistical Learning, 今天的内容是线性模型(第三章..这本书东西非常多,不知道何年何月才能读完了),主要是在看变量选择.感觉变量选择这一块领域非 ...
- AI - 机器学习常见算法简介(Common Algorithms)
机器学习常见算法简介 - 原文链接:http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/ 应 ...
- STL所有算法简介 (转) http://www.cnblogs.com/yuehui/archive/2012/06/19/2554300.html
STL所有算法简介 STL中的所有算法(70个) 参考自:http://www.cppblog.com/mzty/archive/2007/03/14/19819.htmlhttp://hi.baid ...
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
随机推荐
- vc 制作图片资源dll
方法一: 使用纯WIN32 DLL方法封装纯资源第一步,通过VS2005建立WIN32 DLL 空工程第二步,设置配置属性->链接器->高级->无入口点(是/NOENTRY)设置配置 ...
- [置顶] Asp.Net---css样式的使用方式
Css样式的使用大致分为三种 咱们先来看看一张总括图 1 使用连接的形式调用 有两种发方式调用: A 使用link标签 将样式规则写在.Css的样式文档中,再以<link>标签引入 如 ...
- Tomcat 配置WEB虚拟映射 及 配置虚拟主机
Tomcat 配置WEB虚拟映射 及 配置虚拟主机 配置WEB虚拟映射文件夹有三种方法例如以下: 第一(要重新启动server的): 打开路径 Tomcat 6.0\conf 下的 server.x ...
- InputStream中read()与read(byte[] b)(转)
read()与read(byte[] b)这两个方法在抽象类InputStream中前者是作为抽象方法存在的,后者不是,JDK API中是这样描述两者的: 1:read() : 从输入流中读取数据的下 ...
- Java泛型之<T>
这里不讲泛型的概念和基础知识,就单纯的就我的理解说一下泛型中的<T> 一. <T> 下面的一段码就可以简单使用了<T>参数,注释就是对<T>的解释. p ...
- SWT可视化设计
SWT可视化设计,可以使用Google的WindowBuilder. 在Google Code中,搜索WindowBuilder就可以看到路径. 在Eclipse中 Help--->Inst ...
- 使用VS插件在VS2012/2013上编辑和调试Quick-Cocos2d-x的Lua代码
vs 也能够做lua 开发,并进行代码调试 依照以下文档,调试没问题. 參考文档: 点击打开链接
- expdp时遇到ORA-31693&ORA-02354&ORA-01466
expdp时遇到ORA-31693&ORA-02354&ORA-01466 对一个schema运行expdp导出,expdp命令: nohup expdp HQ_X1/HQ_X1 DU ...
- Ubuntu Manpage: ajaxterm - Web based terminal written in python
Ubuntu Manpage: ajaxterm - Web based terminal written in python hardy (1) ajaxterm.1.gz Provided by: ...
- UVA1455 - Kingdom(并查集 + 线段树)
UVA1455 - Kingdom(并查集 + 线段树) 题目链接 题目大意:一个平面内,给你n个整数点,两种类型的操作:road x y 把city x 和city y连接起来,line fnum ...