Spring之AntPathMatcher
前言
AntPathMatcher是什么?主要用来解决什么问题?
背景:在做uri匹配规则发现这个类,根据源码对该类进行分析,它主要用来做类URLs字符串匹配;
效果
可以做URLs匹配,规则如下
- ?匹配一个字符
- *匹配0个或多个字符
- **匹配0个或多个目录
用例如下
- /trip/api/*x 匹配 /trip/api/x,/trip/api/ax,/trip/api/abx ;但不匹配 /trip/abc/x;
- /trip/a/a?x 匹配 /trip/a/abx;但不匹配 /trip/a/ax,/trip/a/abcx
- /**/api/alie 匹配 /trip/api/alie,/trip/dax/api/alie;但不匹配 /trip/a/api
- /**/*.htmlm 匹配所有以.htmlm结尾的路径
核心
AntPathMatcher API接口
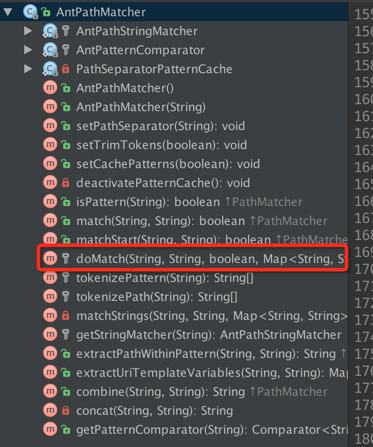
由上图可知,AntPathMatcher提供了丰富的API,主要以doMatch为主,下边来讲doMatch的实现上(其中pattern为制定的url模式,path为具体的url,下边以英文为主讲解):
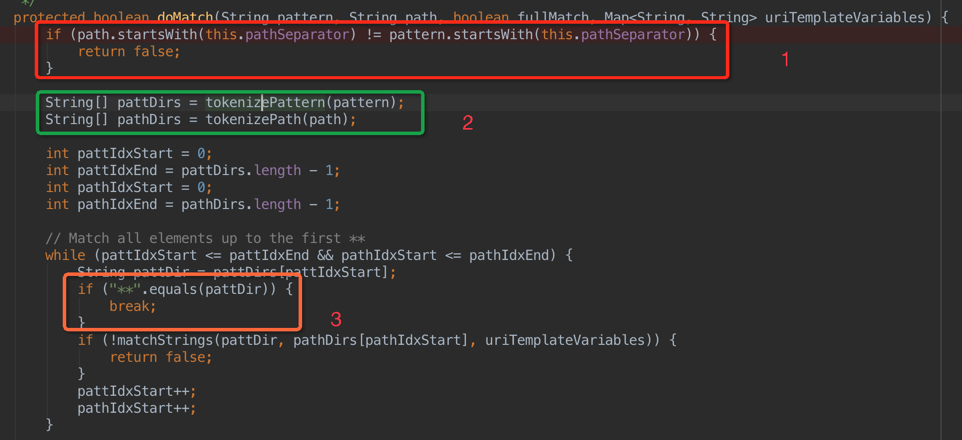
1 首先判断pattern和path的首字符是否同时为设置的分隔符,结果不一致则直接返回false,不进行下边的操作;
2 分别对pattern和path进行分词,形成各自的字符串数组,其中分词的主要代码如下(这段代码很清晰):
public static String[] tokenizeToStringArray(String str, String delimiters, boolean trimTokens, boolean ignoreEmptyTokens) {
if (str == null) {
return null;
}
StringTokenizer st = new StringTokenizer(str, delimiters);
List<String> tokens = new ArrayList<String>();
while (st.hasMoreTokens()) {
String token = st.nextToken();
if (trimTokens) {
token = token.trim();
}
if (!ignoreEmptyTokens || token.length() > 0) {
tokens.add(token);
}
}
return toStringArray(tokens);
}
注:str代表要进行分词的字符串,delimiters是进行分词的分隔符,trimTokens表示是否对每一个分词进行首尾去空字符串,ignoreEmptyTokens代表分割之后是否保留空字符串;
我们发现,每次计算这个也是要花费一定的时间消耗,那每次真的是要重新计算么 ?看下边的代码来找答案(下边的代码是在上个方法tokenizeToStringArray调用之前进行):
private final Map<String, String[]> tokenizedPatternCache = new ConcurrentHashMap<String, String[]>(256);
......
protected String[] tokenizePattern(String pattern) {
String[] tokenized = null;
Boolean cachePatterns = this.cachePatterns;
if (cachePatterns == null || cachePatterns.booleanValue()) {
tokenized = this.tokenizedPatternCache.get(pattern);
}
if (tokenized == null) {
tokenized = tokenizePath(pattern);
if (cachePatterns == null && this.tokenizedPatternCache.size() >= CACHE_TURNOFF_THRESHOLD) {
// Try to adapt to the runtime situation that we're encountering:
// There are obviously too many different patterns coming in here...
// So let's turn off the cache since the patterns are unlikely to be reoccurring.
deactivatePatternCache();
return tokenized;
}
if (cachePatterns == null || cachePatterns.booleanValue()) {
this.tokenizedPatternCache.put(pattern, tokenized);
}
}
return tokenized;
}
我们看到,这里存了一个pattern的cache tokenizedPatternCache,key为pattern,value为分次之后的字符串数组,每次先到cache获取,没有的话则计算,然后放入到cache里边,这样在做频繁的url mapping的时候,由于规则是有限的,可以很大程度减少计算;
同理,path也是通过同样的计算,不过,path则不会缓存,每次都需要调用tokenizeToStringArray进行分词(为什么呢?[1])
接着来说3:
3 对分词之后的pattern数组和path数组从begin进行遍历,一旦pattern的第一个字符串是**的话,则跳出来,此时没有直接返回true,为什么呢[2]?
下边接着看doMatch的中间部分代码(也就是说当break或者运行完毕while循环的时候,在退出之前会接着执行下边的代码)
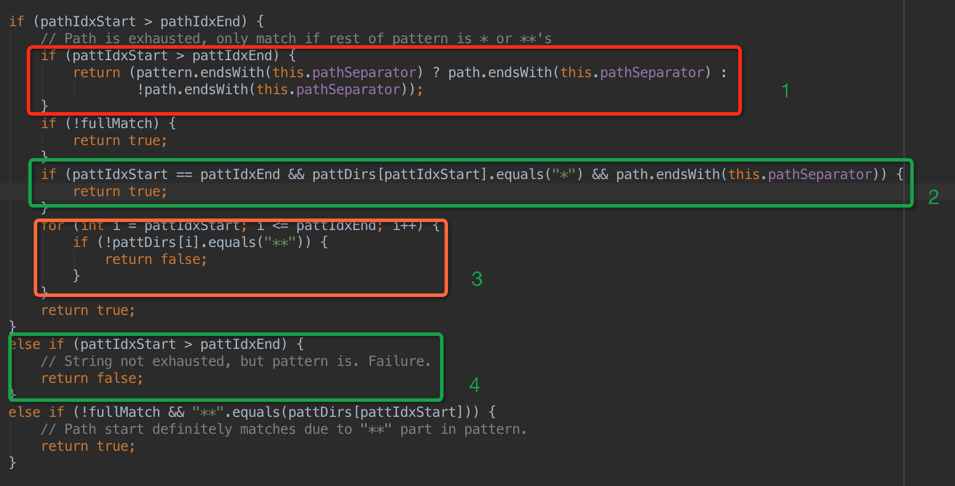
1 如果path分词数组正常执行完毕,则pathIdxStart是会比pathIdxEnd大1的,这个时候,如果pattern的字符串数组也正常耗尽,则来判断pattern和path的最后一个字符是否同步,按结果返回;
2 如果上边的循环只执行了一次,则这时候pattIdxStart则和pattIdxEnd相等,同时pattern的最后一个字符是*且path最后是一个分隔符,则直接返回true;
3 如果pattern的最后一个字符串是**则path不需要判断直接返回true;
4 这一步代表,pattern已经耗尽但是path还没耗尽,这时候肯定不匹配,直接返回false
接下来接着看,紧接着上边第二幅黑色背景图,如果第一次因为**弹出来,看下边如何处理:

这个时候,开始从后往前遍历,如果再次弹出来不是因为遇到了**,是正常遍历完成,这个时候,pathIdxStart是大于pathIdxEnd,这个时候字符串已经耗尽,如果pattern还没有耗尽,并且最后并不是**,则直接返回false;
如果中间再次出现**,并且path并没有耗尽,则进行下边的步骤:

这一部分代码主要用来循环处理中间再次**的情况,直到完全处理完成,这里边用到了Java的标签语法:strLoop,符合条件则跳转到strLoop(类似goto);
总结
这一部分的处理理解起来不是非常难懂,但是这个关于字符串匹配的过程是及其细致的,每一个边界问题都想得比较完美,这一点是相当值得学习的。
后记
其中,每一个path的分词是如何匹配到pattern的分词是怎么做的呢?答案就在 matchStrings 这个方法里边了:
首先用path来匹配pattern的时候,要获取一个matcher,代码如下:
final Map<String, AntPathStringMatcher> stringMatcherCache = new ConcurrentHashMap<String, AntPathStringMatcher>(256);
......
protected AntPathStringMatcher getStringMatcher(String pattern) {
AntPathStringMatcher matcher = null;
Boolean cachePatterns = this.cachePatterns;
if (cachePatterns == null || cachePatterns.booleanValue()) {
matcher = this.stringMatcherCache.get(pattern);
}
if (matcher == null) {
matcher = new AntPathStringMatcher(pattern);
if (cachePatterns == null && this.stringMatcherCache.size() >= CACHE_TURNOFF_THRESHOLD) {
// Try to adapt to the runtime situation that we're encountering:
// There are obviously too many different patterns coming in here...
// So let's turn off the cache since the patterns are unlikely to be reoccurring.
deactivatePatternCache();
return matcher;
}
if (cachePatterns == null || cachePatterns.booleanValue()) {
this.stringMatcherCache.put(pattern, matcher);
}
}
return matcher;
}
这里new AntPathStringMatcher(AntPathMatcher的一个内部类)的时候也是需要一些计算,matcher构建的精华全部在这里了:
public AntPathStringMatcher(String pattern) {
StringBuilder patternBuilder = new StringBuilder();
Matcher m = GLOB_PATTERN.matcher(pattern);
int end = 0;
while (m.find()) {
patternBuilder.append(quote(pattern, end, m.start()));
String match = m.group();
if ("?".equals(match)) {
patternBuilder.append('.');
}
else if ("*".equals(match)) {
patternBuilder.append(".*");
}
else if (match.startsWith("{") && match.endsWith("}")) {
int colonIdx = match.indexOf(':');
if (colonIdx == -1) {
patternBuilder.append(DEFAULT_VARIABLE_PATTERN);
this.variableNames.add(m.group(1));
}
else {
String variablePattern = match.substring(colonIdx + 1, match.length() - 1);
patternBuilder.append('(');
patternBuilder.append(variablePattern);
patternBuilder.append(')');
String variableName = match.substring(1, colonIdx);
this.variableNames.add(variableName);
}
}
end = m.end();
}
patternBuilder.append(quote(pattern, end, pattern.length()));
this.pattern = Pattern.compile(patternBuilder.toString());
}
这部分计算比较频繁,也会耗费一定量的时间,所以这里用到了一个叫做 stringMatcherCache 的cache,上文中提到的两个cache的数量都不能超过65536,有其中任意一个cache超过这个限制,则会清空整个cache。
Spring之AntPathMatcher的更多相关文章
- Spring 使用介绍(三)—— 资源
一.Resource接口 Spring提供Resource接口,代表底层外部资源,提供对底层外部资源的一致性访问接口 public interface InputStreamSource { Inpu ...
- Spring Security 5.0.x 参考手册 【翻译自官方GIT-2018.06.12】
源码请移步至:https://github.com/aquariuspj/spring-security/tree/translator/docs/manual/src/docs/asciidoc 版 ...
- 资源 之 4.4 Resource通配符路径(拾贰)
4.4.1 使用路径通配符加载Resource 前面介绍的资源路径都是非常简单的一个路径匹配一个资源,Spring还提供了一种更强大的Ant模式通配符匹配,从能一个路径匹配一批资源. Ant路径通配 ...
- 资源 之 4.4 Resource通配符路径 ——跟我学spring3
4.4.1 使用路径通配符加载Resource 前面介绍的资源路径都是非常简单的一个路径匹配一个资源,Spring还提供了一种更强大的Ant模式通配符匹配,从能一个路径匹配一批资源. Ant路径通配 ...
- spring--资源--4
4.1.1 概述 在日常程序开发中,处理外部资源是很繁琐的事情,我们可能需要处理URL资源.File资源资源.ClassPath相关资源.服务器相关资源(JBoss AS 5.x上的VFS资源)等等 ...
- 开涛spring3(4.4) - 资源 之 4.4 Resource通配符路径
4.4.1 使用路径通配符加载Resource 前面介绍的资源路径都是非常简单的一个路径匹配一个资源,Spring还提供了一种更强大的Ant模式通配符匹配,从能一个路径匹配一批资源. Ant路径通配 ...
- Spring-Resource接口
4.1.1 概述 在日常程序开发中,处理外部资源是很繁琐的事情,我们可能需要处理URL资源.File资源资源.ClassPath相关资源.服务器相关资源(JBoss AS 5.x上的VFS资源)等等很 ...
- spring3: 4.4 使用路径通配符加载Resource
4.4.1 使用路径通配符加载Resource 前面介绍的资源路径都是非常简单的一个路径匹配一个资源,Spring还提供了一种更强大的Ant模式通配符匹配,从能一个路径匹配一批资源. Ant路径通配 ...
- 玩转 SpringBoot 2 快速整合 | 丝袜哥(Swagger)
概述 首先让我引用 Swagger 官方的介绍: Design is the foundation of your API development. Swagger makes API design ...
随机推荐
- Atitit 图像处理知识点 知识体系 知识图谱
Atitit 图像处理知识点 知识体系 知识图谱 图像处理知识点 图像处理知识点体系 v2 qb24.xlsx 基本知识图像金字塔op膨胀叠加混合变暗识别与检测分类肤色检测other验证码生成 基本 ...
- iOS-网络爬虫
1.iOS开发——网络实用技术OC篇&网络爬虫-使用青花瓷抓取网络数据 2.iOS开发——网络使用技术OC篇&网络爬虫-使用正则表达式抓取网络数据 3.iOS—网络实用技术OC篇&am ...
- JS util
一.返回上一页(history) 发觉有两种用法: 1.javascript:history.back(-1); 2.javascript:history.go(-1); 它们俩的区别是: histo ...
- Android 实现应用升级方案(暨第三方自动升级服务无法使用后的解决方案)
第三方推送升级服务不再靠谱: 以前在做Android开发的时候,在应用升级方面都是使用的第三方推送升级服务,但是目前因为一些非技术性的问题,一些第三方厂商不再提供自动升级服务,比如友盟,那么当第三方推 ...
- 《PHP Manual》阅读笔记2
本次笔记截止到 语言参考 流程控制. 1.没有结合的相同优先级的运算符不能连在一起使用,例如 1 < 2 > 1 在PHP是不合法的.但另外一方面表达式 1 <= 1 == 1 是合 ...
- 利用JSDOC快速生成注释文档,非常棒。
有时往往我们需要建一个文档来记录js中的一些代码注释,比如一些公共的函数,又或者一些类,在团队合作中,文档接口也是必不可少的,传统的方式多少有些不便,这里介绍一个工具,它叫JSDOC,它可以用来将注释 ...
- 使用Google产品以来遇到的最糟糕、最霸道、最让人抓狂的设计
很久没有登录cnblogs@gmail.com这个邮箱,今天通过gmail.com登录了一下,登录后出现一个对话框要求设置性别与出生日期,而且必须要设置,不设置不让登录. 这个邮箱是我们网站用的是邮箱 ...
- webstorm使用技巧
WebStorm快捷键收集:模式visual studio 代码提示:ctrl + alt + 空格 代码补全:alt + / 代码换行:ctrl + shift + 上下箭头 重新运行:ctrl + ...
- ECshop 快捷登录插件 支持QQ 支付宝 微博
亲自测试可以使用,分享给大家.(承接各种EcShop改版,二次开发等相关项目 QQ:377898650) 安装的时候按照里面说明.安装即可. 代码下载:http://pan.baidu.com/s/1 ...
- 轻松自动化---selenium-webdriver(python) (七)
本节知识点: 多层框架或窗口的定位: switch_to_frame() switch_to_window() 智能等待: implicitly_wait() 对于一个现代的web应用,经常会出现框架 ...