Solr整合Ansj中文分词器
Ansj的使用和相关资料下载参考:http://iamyida.iteye.com/blog/2220833
参考 http://www.cnblogs.com/luxh/p/5016894.html 配置和solr和tomcat的
1、从http://iamyida.iteye.com/blog/2220833下载好Ansj需要的相关的资料,下面是已下载好的。
Ansj资料: http://pan.baidu.com/s/1kTLGp7L
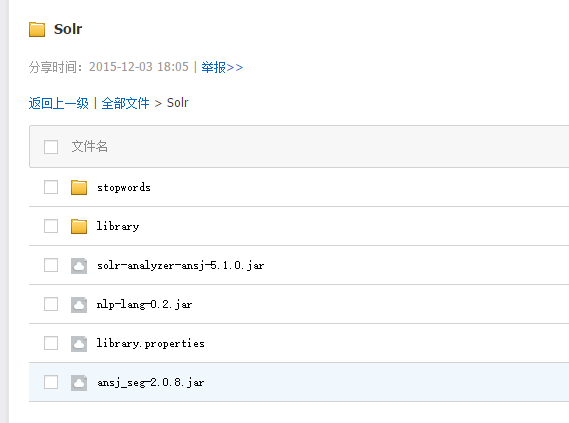
2、复制ansj相关文件到solr项目中
1)将ansj_seg-2.0.8.jar、nlp-lang-0.2.jar和solr-analyzer-ansj-5.1.0.jar放到solr项目中
放置目录:/luxh/solr/apache-tomcat-8.0.29/webapps/solr/WEB-INF/lib
2)将library.properties、libary目录和stopwords目录放置到solr项目中
放置目录:
[root@iZ23exixsjaZ classes]# pwd
/luxh/solr/apache-tomcat-8.0./webapps/solr/WEB-INF/classes
[root@iZ23exixsjaZ classes]# ls
library library.properties log4j.properties stopwords
[root@iZ23exixsjaZ classes]#
3)配置library.properties
按照自己的实际路径配置。
[root@iZ23exixsjaZ classes]# vi library.properties
#redress dic file path
ambiguityLibrary=/luxh/solr/apache-tomcat-8.0./webapps/solr/WEB-INF/classes/library/ambiguity.dic
#path of userLibrary this is default library
userLibrary=/luxh/solr/apache-tomcat-8.0./webapps/solr/WEB-INF/classes/library
#set real name
isRealName=true
3、在solr_home下建立一个collection
1)创建一个collection叫collection1
[root@iZ23exixsjaZ solr_home]# pwd
/luxh/solr/solr_home
[root@iZ23exixsjaZ solr_home]# mkdir collection1
2)拷贝/solr-5.3.1/server/solr/configsets/basic_configs下的内容到新建的collection1中
[root@iZ23exixsjaZ basic_configs]# pwd
/luxh/solr/solr-5.3./server/solr/configsets/basic_configs
[root@iZ23exixsjaZ basic_configs]# cp -r ./* /luxh/solr/solr_home/collection1/
4、配置collection1中的schema.xml,加入ansj分词配置
[root@iZ23exixsjaZ conf]# pwd
/luxh/solr/solr_home/collection1/conf
[root@iZ23exixsjaZ conf]# ls
currency.xml lang protwords.txt _rest_managed.json schema.xml solrconfig.xml stopwords.txt synonyms.txt
[root@iZ23exixsjaZ conf]# vi schema.xml
加入如下内容:
<fieldType name="text_ansj" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ansj.AnsjTokenizerFactory"
query="false" pstemming="true" stopwordsDir="stopwords/stopwords.dic"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ansj.AnsjTokenizerFactory"
query="true" pstemming="false"/>
</analyzer>
</fieldType>
5、启动tomcat
[root@iZ23exixsjaZ apache-tomcat-8.0.]# bin/startup.sh
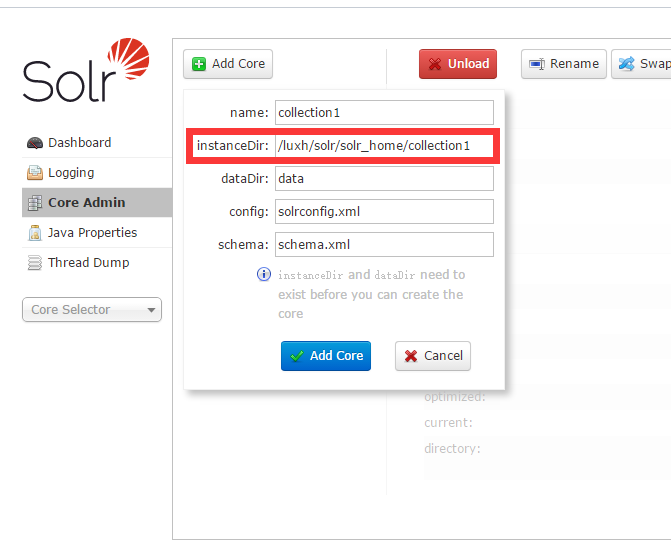
6、通过 http://你的ip:8080/solr/admin.html Add Core
instanceDir指向刚才创建的collection1
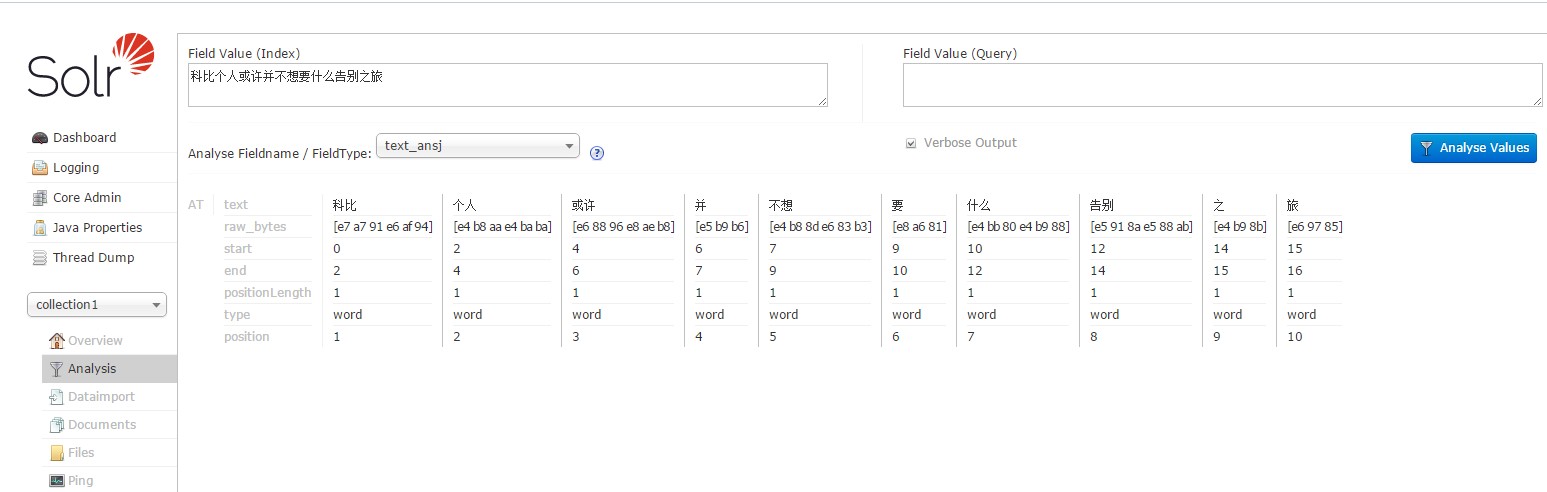
7、测试
1)英文

2)中文
Solr整合Ansj中文分词器的更多相关文章
- Solr集成IK中文分词器
1.将IKAnalyzer-2012-4x.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下: 2.在schema.xml文件中添加fieldType: &l ...
- 在eclipse中构建solr项目+添加core+整合mysql+添加中文分词器
最近在研究solr,这里只记录一下eclipse中构建solr项目,添加core,整合mysql,添加中文分词器的过程. 版本信息:solr版本6.2.0+tomcat8+jdk1.8 推荐阅读:so ...
- Solr4.10与tomcat整合并安装中文分词器
1.solr Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展,并对索引. ...
- solr 7+tomcat 8 + mysql实现solr 7基本使用(安装、集成中文分词器、定时同步数据库数据以及项目集成)
基本说明 Solr是一个开源项目,基于Lucene的搜索服务器,一般用于高级的搜索功能: solr还支持各种插件(如中文分词器等),便于做多样化功能的集成: 提供页面操作,查看日志和配置信息,功能全面 ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- 【solr】solr5.0整合中文分词器
1.solr自带的分词器远远满足不了中文分词的需求,经查使用最多的分词器是solr是mmseg4j分词器,具体整合大家可以参考 https://github.com/zhuomingliang/mms ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
随机推荐
- 登录phpmyadmin提示: #1045 无法登录 MySQL 服务器
打开phpmyadmin,进行登录,出现以下问题,提示:#1045 无法登录 MySQL 服务器 或许出现以下错误情况:phpmyadmin:#1045 无法登录 MySQL 服务器.Access d ...
- 接口 Post
public static StringBuilder HttpPost(string Url, byte[] Postdata, string i) { StringBuilder content ...
- Java中封装、继承和多态
封装: 封装实际上使用方法将类的数据隐藏起来,控制用户对类的修改和访问数据的程度. 适当的封装可以让程式码更容易理解和维护,也加强了程式码的安全性. 访问修饰符有public,private,prot ...
- 实现DevExpress GridControl 只有鼠标双击后才进行修改数据
1. 实现DevExpress GridControl 只有鼠标双击后才进行修改数据:修改GridView.OptionsBehavior.EditorShowMode属性为Click 2. 实现De ...
- 第一次在linux上登录博客
这是我第一次在linux操作系统上登录博客,额,虽然是在X-window上面.好吧,是我太激动了. 这意味着我已经步入linux的世界了,虽然中文输入法不太好用,但是我还是写一下我的心情吧. 从去年的 ...
- 【POJ3621】Sightseeing Cows
Sightseeing Cows Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8331 Accepted: 2791 ...
- Java Concurrent之 AbstractQueuedSynchronizer
ReentrantLock/CountDownLatch/Semaphore/FutureTask/ThreadPoolExecutor的源码中都会包含一个静态的内部类Sync,它继承了Abstrac ...
- HTML的文本格式化
文本格式化:<html> <body> <b>This text is bold</b> <br /> <strong>This ...
- 控制器(Controller) – ASP.NET MVC 4 系列
创建一个 ASP.NET MVC 4 Web Application 项目,将程序命名为 MvcMusicStore,如下图: 控制器 MVC 模式中,控制器主要负责响应用 ...
- CSRF攻击
1.什么是CSRF攻击CSRF(Cross-site request forgery),跨站请求伪造.CSRF攻击的原理如下:1)用户登录正常的网站A后,在本地生成Cookie2)在不登出A的情况下, ...