第01章 ElasticSearch简介
本章内容
Apache Lucene是什么。
Lucene的整体架构。
文本分析过程是如何实现的。
Apache Lucene的查询语言及其使用方法。
ElasticSearch的基本概念。
ELasticSearch内部是如何通信的。
1.1 Apache Lucene简介
1.1.2 Lucene的总体架构
Lucene一些概念:
- 文档(document):索引与搜索的主要数据载体,它包含一个或多个字段,存放将要写入索引或将从索引搜索出来的数据。
- 字段(field ):文档的一个片段,它包括两个部分:字段的名称和内容。
- 词项(term ):搜索时的一个单位,代表文本中的某个词。
- 词条(token ):词项在字段中的一次出现,包括词项的文本、开始和结束的位移以及类型。
索引示意图
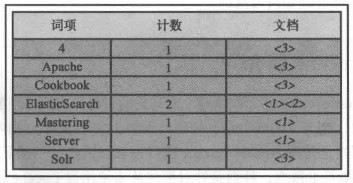
Segment
每个索引由多个段(segment )组成,每个段只会被创建一次但会被查询多次。索引期间,段经创建就不会再被修改。例如,文档被删除以后,删除信息被单独保存在一个文件中,而段本身并没有修改。
为什么要合并段
多个段会在一个叫作段合并(segments merge)的阶段被合并在一起,而且要么强制执行,要么由Lucene的内在机制决定在某个时刻执行,合并后段的数量更少,但是更大。段合并非常耗I/O,且合并期间有些不再使用的信息也将被清理掉,例如,被删除的文档。对于容纳相同数据的索引,段的数量较少时,搜索速度更快。
1.1.3 分析你的数据
文本分析由分析器来执行,而分析器由分词器(tokenizer)、过滤器(filter)和字符映射器组成(character mapper)。
一些过滤器的例子:
- 小写过滤器:将所有词条转化为小写。
- ASCII过滤器:移除词条中所有非ASCII字符。
- 同义词过滤器:根据同义词规则,将一个词条转化为另一个词条。
- 多语言词干还原过滤器:将词条的文本部分归约到它们的词根形式,即词干还原。
1.2 ElasticSearch简介
1.2.1 ElasticSearch基本概念
分片
除了ElasticSearch本身自动进行分片处理外,用户为具体的应用进行参数调优也是至关重要的,因为分片的数量在索引创建时就已经配置好,而且之后无法改变,至少对目前的版本是这样的。副本
支持在任意时间点添加或移除副本,所以一旦有需要可随时调整副本的数量。网关
在ElasticSearch的工作过程中,关于集群状态,索引设置的各种信息都会被收集起来,并在网关(gateway)中被持久化。
1.2.2 ElasticSearch架构背后的关键概念
ElasticSearch主要特征:
- 合理的默认配置。使得用户在简单安装以后能直接使用ElasticSearch而不需要任何额外的调试,这包括内置的发现(如字段类型检测)和自动配置功能。
- 默认的分布式工作模式。每个节点总是假定自己是某个集群的一部分或将是某个集群的一部分,一旦工作启动节点便会加人某个集群。
- 对等架构(P2P)可以避免单点故障( SPOF )。节点会自动连接到集群中的其他节点,进行相互的数据交换和监控操作。这其中就包括索引分片的自动复制。
- 易于向集群扩充新节点,不论是从数据容量的角度还是数量角度。
- ElasticSearch没有对索引中的数据结构强加任何限制,从而允许用户调整现有的数据模型。
- 准实时(Near Real Time , NRT)搜索和版本同步(versioning )。考虑到ElasticSearch的分布式特性,查询延迟和节点之间临时的数据不同步是难以避免的。ElasticSearch尝试消除这些问题并且提供额外的机制用于版本同步。
1.2.3 ElasticSearch的工作流程
启动过程
当ElasticSearch节点启动时,它使用广播技术(也可配置为单播)来发现同一个集群中的其他节点(这里的关键是配置文件中的集群名称)并与它们连接。
集群中会有一个节点被选为管理节点(master node)。该节点负责集群的状态管理以及在集群拓扑变化时做出反应,分发索引分片至集群的相应节点上。
Note
请记住,从用户的角度来看,ElasticSearch中的管理节点并不比其他节点重要,这与其他某些分布式系统不同(如数据库)。实际上,你不需要知道哪个节点是管理节点,所有操作可以发送至任意节点,ElasticSearch内部会自行处理这些不可思议的事情。如果有需要,任意节点可以并行发送子查询给其他节点,并合并搜索结果,然后返回给用户。所有这些操作并不需要经过管理节点处理(请记住,ElasticSearch是基于对等架构的)。
管理节点读取集群的状态信息,并在必要时进行恢复处理。在该阶段,管理节点会检查所有索引分片并决定哪些分片将用于主分片。然后,整个集群进人黄色状态。这意味着集群可以执行查询,但是系统的吞吐量以及各种可能的状况是未知的,因而接下来就是要寻找到冗余的分片并用作副本。
故障检测
管理节点会发送ping请求至其他节点,然后等待响应。如果没有响应,则该节点会从集群中移除。
与ElasticSearch通信
索引数据
ElasticSearch提供了四种方式来创建索引。
-XPUT
最简单的方式是使用索引API,它允许用户发送一个文档至特定的索引。例如,使用curl工具,并用如下命令创建一个文档:

- bulk API(UDP bulk API)
第二种或第三种方式允许用户通过bulk API或UDP bulk API来一次性发送多个文档至集群。两者的区别在于网络连接方式,前者使用HTTP协议,后者使用UDP协议,且后者速度快,但是不可靠。 - river
第四种方式使用插件发送数据,称为河流(river ),河流运行在ElasticSearch节点上,能够从外部系统获取数据。
有一件事情需要记住,建索引操作只会发生在主分片上,而不是副本上。当把一个索引请求发送至某节点时,如果该节点没有对应的主分片或者只有副本,那么这个请求会被转发到拥有正确的主分片的节点(如下图所示)。
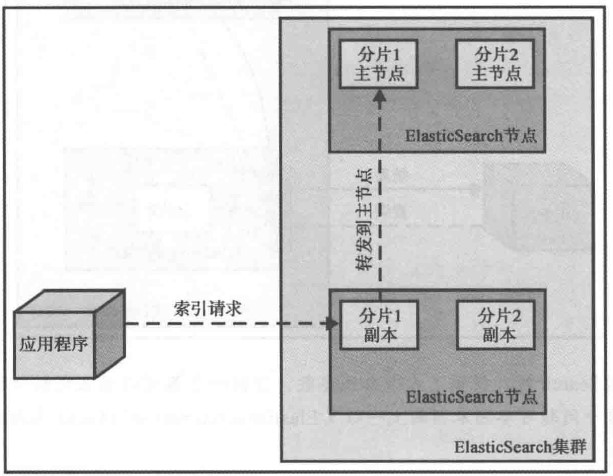
查询数据
查询API占据了ElasticSearch API的大部分内容。使用查询DSL(基于JSON的可用于构建复杂查询的语言),我们可以做下面这些事情:
- 使用各种查询类型,包括:简单的词项查询、短语查询、范围查询、布尔查询、模糊查询、区间查询、通配符查询、空间查询等。
- 组合简单查询构建复杂查询。
- 文档过滤,在不影响评分的前提下抛弃那些不满足特定查询条件的文档。
- 查找与特定文档相似的文档。
- 查找特定短语的查询建议和拼写检查。
- 使用切面构建动态导航和计算各种统计量。
- 使用预搜索(prospective search)并查找与指定文档匹配的query集合。
对于查询操作,读者应该要重点了解:查询并不是一个简单的、单步骤的操作。一般来说,查询分为两个阶段:分散阶段(scatter phase)和合并阶段(gather phase)。分散阶段将query分发到包含相关文档的多个分片中去执行查询,合并阶段则从众多分片中收集返回结果,然后对它们进行合并、排序、后续处理,然后返回给客户端。该机制可以由下图描述。
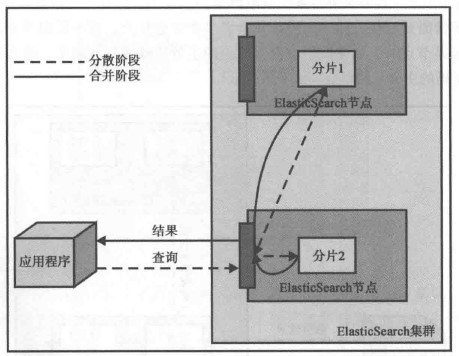
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
第01章 ElasticSearch简介的更多相关文章
- 异步编程系列第01章 Async异步编程简介
p { display: block; margin: 3px 0 0 0; } --> 2016.10.11补充 三个月过去了,回头来看,我不得不承认这是一系列失败的翻译.过段时间,我将重新翻 ...
- Windows程序设计(第五版)学习:第二章 Unicode简介
第二章 Unicode简介 1,Windows通过双字节技术DBCS解决这个问题,代码页定义不同的字符集,称为ANSI字符集,比如日文为CP932,韩文为CP949,繁体中文为CP950,简体中文为C ...
- 《深入浅出Node.js》第1章 Node简介
@by Ruth92(转载请注明出处) 第1章 Node简介 一.Node的起源 高性能Web服务器的要点:事件驱动.非阻塞I/O. 选择JavaScript的原因:高性能.符合事件驱动.没有历史包袱 ...
- 第一章 C++简介
第一章 C++简介 1.1 C++特点 C++融合了3种不同的编程方式:C语言代表的过程性语言,C++在C语言基础上添加的类代表的面向对象语言,C++模板支持的泛型编程. 1.2 C语言及其编程 ...
- 1、elasticsearch简介
1.elasticsearch简介 中文帮助文档地址:http://es.xiaoleilu.com/ • Elasticsearch是一个基于Lucene的实时的分布式搜索和分析引擎.设计用于云计算 ...
- <算法图解>读书笔记:第1章 算法简介
阅读书籍:[美]Aditya Bhargava◎著 袁国忠◎译.人民邮电出版社.<算法图解> 第1章 算法简介 1.2 二分查找 一般而言,对于包含n个元素的列表,用二分查找最多需要\(l ...
- Elasticsearch 简介
1. 背景 Elasticsearch 在公司的使用越来越广,很多同事之前并没有接触过 Elasticsearch,所以,最近在公司准备了一次关于 Elasticsearch 的分享,整理成此文.此文 ...
- 《gradle 用户指南中文版》 第1章、简介
第1章.简介 目录 1.1 关于本用户指南 Gradle是一个基于Apache Ant和Apache Maven概念的项目自动化构建工具. 这里我们将介绍Gradle,我们认为gradle让java项 ...
- 第1章WCF简介(WCF全面解析读书笔记2)
第1章 WCF简介 面向服务架构(SOA)是近年来备受业界关注的一个主题,它代表了软件架构的一种方向.顺应SOA发展潮流,微软于2006年年底推出了一种新的分布式通信框架Windows Communi ...
随机推荐
- 【POJ】2385 Apple Catching(dp)
Apple Catching Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 13447 Accepted: 6549 D ...
- 查看Unix/Linux的CPU个数和内存大小,系统位数(转载)
一.AIX 1.查看CPU数: (1) smtctl 从AIX5.3起,对于power5的机器,系统引入了SMT(Simultaneousmulti-threading)的功能,其允许两个处理线程在同 ...
- 推荐一篇mysql优化干货
淘宝的技术一直比较前沿,特别是LVS的作者加入淘宝后,淘宝和阿里的开源做的有声有色,君不见淘宝出了tengine,tairs,tddl,hsf(soa框架,未开源),tfs(小文件存储系统)等等,阿里 ...
- sql之将一个表中的数据注入另一个表中
sql之将一个表中的数据注入另一个表中 需求:现有两张表t1,t2,现需要将t2的数据通过XZQHBM相同对应放入t1表中 t1: t2: 思路:left join 语句: select * from ...
- leetcode844
class Solution { public: bool backspaceCompare(string S, string T) { stack<char> ST1; ; i < ...
- ajax传递给后台数组参数方式
出自:http://blog.csdn.net/lingxyd_0/article/details/10428785 在项目上用到了批量删除与批量更改状态,前台使用了EasyUI的DataGrid,用 ...
- Git 联机版
简介: 之前研究了 Git 单机版 ( 单兵作战 ),今天来研究一下 Git 联机版 ( 团队协作 )! GitHub 是一个开源的代码托管平台,可以分享自己的代码到该平台上,让大家参与开发或供大家使 ...
- sublime +react+es6开发环境
Babel Sublime3才有的插件,支持ES6.JSX语法高亮. 菜单->View->Syntax->Open all with current extension as...- ...
- mysql存储过程(procedure)
#创建带参数的存储过程 delimiter // ),out p int) begin ; end // delimiter call pro_stu_name_pass(@n,@p); select ...
- 解剖Nginx·自动脚本篇(5)编译器相关主脚本
在 Nginx 的自动脚本中,auto/cc目录下的所有脚本都是用于编译器相关配置使用的.Nginx的出色跨平台性(Linux.Darwin.Solaris.Win32 等)就有这些脚本的贡献.该目录 ...