【Network Architecture】Feature Pyramid Networks for Object Detection(FPN)论文解析(转)
0. 前言
这篇论文提出了一种新的特征融合方式来解决多尺度问题, 感觉挺有创新性的, 如果需要与其他网络进行拼接,还是需要再回到原文看一下细节。这里转了两篇比较好的博客作为备忘。
1. 博客一
这篇论文是CVPR2017年的文章,采用特征金字塔做目标检测,有许多亮点,特来分享。
论文:feature pyramid networks for object detection
论文链接:https://arxiv.org/abs/1612.03144
论文概述:
作者提出的多尺度的object detection算法:FPN(feature pyramid networks)。原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
代码的话应该过段时间就会开源。
论文详解:
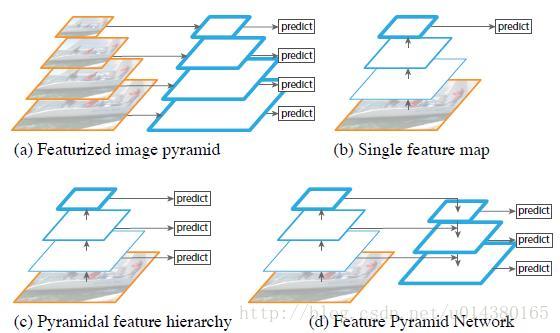
下图FIg1展示了4种利用特征的形式:
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
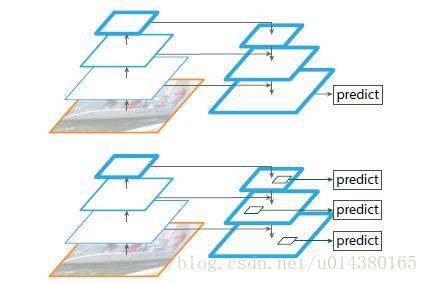
如下图Fig2。上面一个带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。而下面一个网络结构和上面的类似,区别在于预测是在每一层中独立进行的。后面有这两种结构的实验结果对比,非常有意思,因为之前只见过使用第一种特征融合的方式。
作者的主网络采用ResNet。
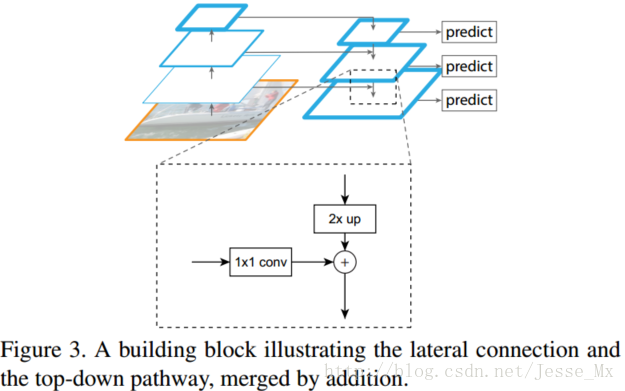
作者的算法大致结构如下Fig3:一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
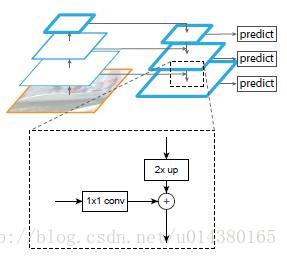
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
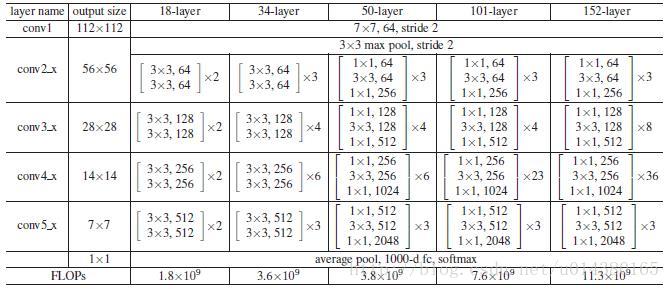
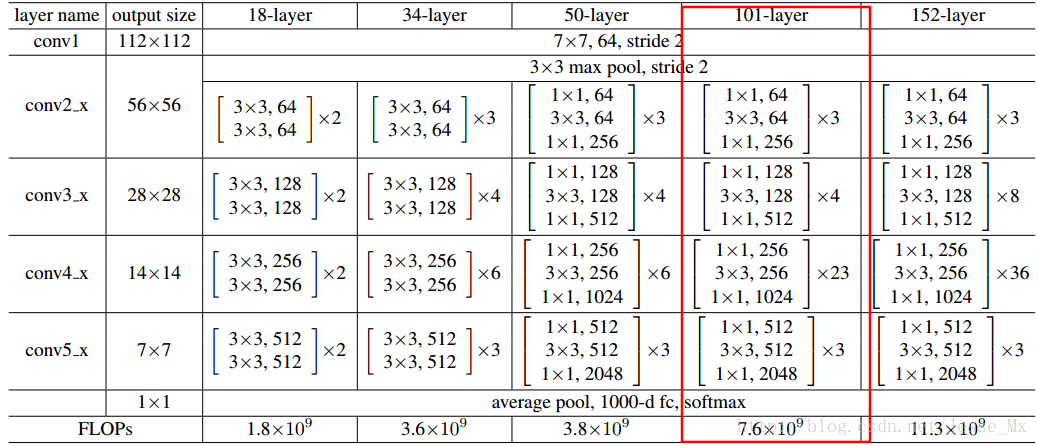
贴一个ResNet的结构图:这里作者采用Conv2,CONV3,CONV4和CONV5的输出。因此类似Conv2就可以看做一个stage。
作者一方面将FPN放在RPN网络中用于生成proposal,原来的RPN网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为32^2,64^2,128^2,256^2,512^2,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
正负样本的界定和Faster RCNN差不多:如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
看看加入FPN的RPN网络的有效性,如下表Table1。网络这些结果都是基于ResNet-50。评价标准采用AR,AR表示Average Recall,AR右上角的100表示每张图像有100个anchor,AR的右下角s,m,l表示COCO数据集中object的大小分别是小,中,大。feature列的大括号{}表示每层独立预测。
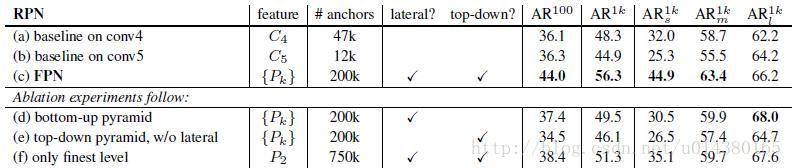
从(a)(b)(c)的对比可以看出FRN的作用确实很明显。另外(a)和(b)的对比可以看出高层特征并非比低一层的特征有效。
(d)表示只有横向连接,而没有自顶向下的过程,也就是仅仅对自底向上(bottom-up)的每一层结果做一个1*1的横向连接和3*3的卷积得到最终的结果,有点像Fig1的(b)。从feature列可以看出预测还是分层独立的。作者推测(d)的结果并不好的原因在于在自底向上的不同层之间的semantic gaps比较大。
(e)表示有自顶向下的过程,但是没有横向连接,即向下过程没有融合原来的特征。这样效果也不好的原因在于目标的location特征在经过多次降采样和上采样过程后变得更加不准确。
(f)采用finest level层做预测(参考Fig2的上面那个结构),即经过多次特征上采样和融合到最后一步生成的特征用于预测,主要是证明金字塔分层独立预测的表达能力。显然finest level的效果不如FPN好,原因在于PRN网络是一个窗口大小固定的滑动窗口检测器,因此在金字塔的不同层滑动可以增加其对尺度变化的鲁棒性。另外(f)有更多的anchor,说明增加anchor的数量并不能有效提高准确率。
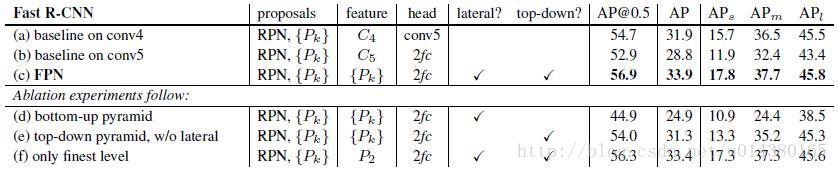
另一方面将FPN用于Fast R-CNN的检测部分。除了(a)以外,分类层和卷积层之前添加了2个1024维的全连接层。细节地方可以等代码出来后再研究。
实验结果如下表Table2,这里是测试Fast R-CNN的检测效果,所以proposal是固定的(采用Table1(c)的做法)。与Table1的比较类似,(a)(b)(c)的对比证明在基于区域的目标卷积问题中,特征金字塔比单尺度特征更有效。(c)(f)的差距很小,作者认为原因是ROI pooling对于region的尺度并不敏感。因此并不能一概认为(f)这种特征融合的方式不好,博主个人认为要针对具体问题来看待,像上面在RPN网络中,可能(f)这种方式不大好,但是在Fast RCNN中就没那么明显。
同理,将FPN用于Faster RCNN的实验结果如下表Table3。

下表Table4是和近几年在COCO比赛上排名靠前的算法的对比。注意到本文算法在小物体检测上的提升是比较明显的。
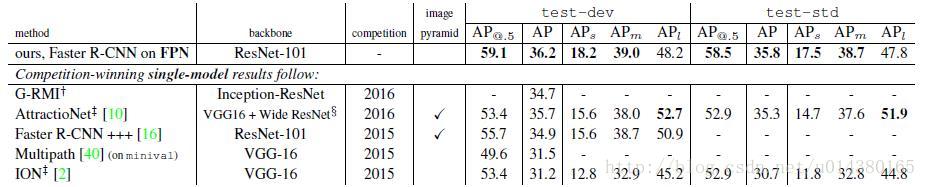
另外作者强调这些实验并没有采用其他的提升方法(比如增加数据集,迭代回归,hard negative mining),因此能达到这样的结果实属不易。
总结
作者提出的FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
期待代码
2.。 博客二
论文地址:Feature Pyramid Networks for Object Detection
Github: https://github.com/BigcowPeking/FPN
前言
这篇论文主要使用特征金字塔网络来融合多层特征,改进了CNN特征提取。论文在Fast/Faster R-CNN上进行了实验,在COCO数据集上刷到了第一的位置,意味着其在小目标检测上取得了很大的进步。论文整体思想比较简单,但是实验部分非常详细和充分。此博文对主要内容进行了翻译和理解工作,不足之处,欢迎讨论。
摘要
特征金字塔是多尺度目标检测系统中的一个基本组成部分。近年来深度学习目标检测却有意回避这一技巧,部分原因是特征金字塔在计算量和用时上很敏感(一句话,太慢)。这篇文章,作者利用了深度卷积神经网络固有的多尺度、多层级的金字塔结构去构建特征金字塔网络。使用一种自上而下的侧边连接,在所有尺度构建了高级语义特征图,这种结构就叫特征金字塔网络(FPN)。其在特征提取上改进明显,把FPN用在Faster R-CNN上,在COCO数据集上,一举超过了目前所有的单模型(single-model)检测方法,而且在GPU上可以跑到5帧。代码暂未开源。
概述
多尺度目标检测是计算机视觉领域的一个基础且具挑战性的课题。在图像金字塔基础上构建的特征金字塔(featurized image pyramids ,Figure1[a])是传统解决思路,具有一定意义的尺度不变性。直观上看,这种特性使得模型可以检测大范围尺度的图像。
Featurized image pyramids 主要在人工特征中使用,比如DPM就要用到它产生密集尺度的样本以提升检测水平。目前人工特征式微,深度学习的CNN特征成为主流,CNN特征的鲁棒性很好,刻画能力强。即使如此,仍需要金字塔结构去进一步提升准确性,尤其在多尺度检测上。金字塔结构的优势是其产生的特征每一层都是语义信息加强的,包括高分辨率的低层。
对图像金字塔每一层都处理有很大的局限性,首先运算耗时会增加4倍,训练深度网络的时候太吃显存,几乎没法用,即使用了,也只能在检测的时候。因为这些原因,Fast/Faster R-CNN 都没使用featurized image pyramids 。
当然,图像金字塔并不是多尺度特征表征的唯一方式,CNN计算的时候本身就存在多级特征图(feature map hierarchy),且不同层的特征图尺度就不同,形似金字塔结构(Figure1[b])。结构上虽不错,但是前后层之间由于不同深度(depths)影响,语义信息差距太大,主要是高分辨率的低层特征很难有代表性的检测能力。
SSD方法在借鉴利用featurized image pyramid上很是值得说,为了避免利用太低层的特征,SSD从偏后的conv4_3开始,又往后加了几层,分别抽取每层特征,进行综合利用(Figure1[c])。但是SSD对于高分辨率的底层特征没有再利用,而这些层对于检测小目标很重要。

这篇论文的特征金字塔网络(Figure1[d])做法很简单,如下图所示。把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息。这种结构是在CNN网络中完成的,和前文提到的基于图片的金字塔结构不同,而且完全可以替代它。
本文特征金字塔网络自上而下的结构,和某些论文有一定的相似之处,但二者目的不尽不同。作者做了检测和分割实验,COCO数据集的结果超过了现有水平,具体结果参见论文中实验部分。值得说的是,本文方法在训练的时间和显存使用上都是可接受的,检测的时间也没增加。
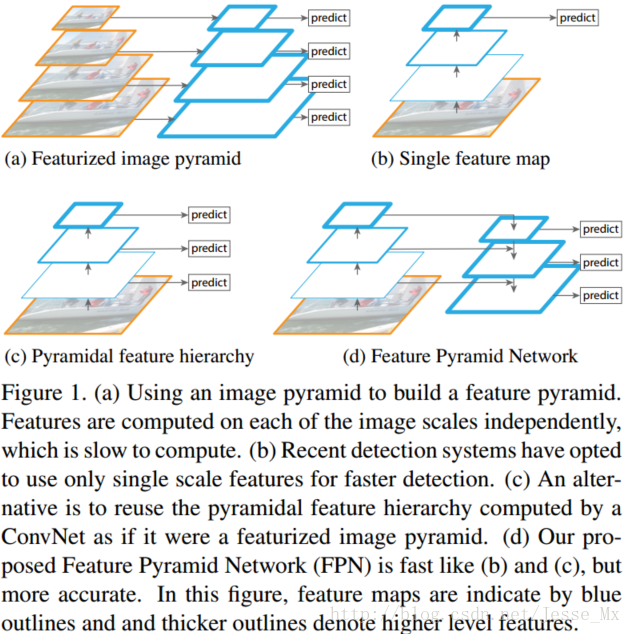
上图简要说下:(作者的创新之处就在于既使用了特征金字塔,又搞了分层预测)
(a) 用图片金字塔生成特征金字塔
(b) 只在特征最上层预测
(c) 特征层分层预测
(d) FPN从高层携带信息传给底层,再分层预测
特征金字塔网络
论文的目标是利用CNN的金字塔层次结构特性(具有从低到高级的语义),构建具有高级语义的特征金字塔。得到的特征金字塔网络(FPN)是通用的,但在论文中,作者先在RPN网络和Fast R-CNN中使用这一成果,也将其用在instance segmentation proposals 中。
该方法将任意一张图片作为输入,以全卷积的方式在多个层级输出成比例大小的特征图,这是独立于CNN骨干架构(本文为ResNets)的。具体结构如图Figure 2。
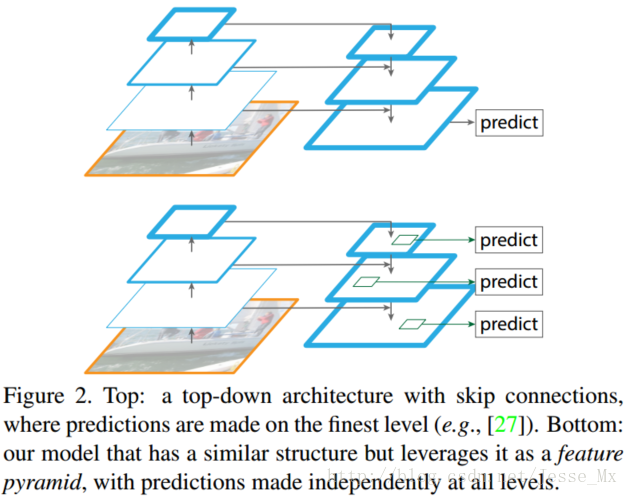
自下而上的路径
CNN的前馈计算就是自下而上的路径,特征图经过卷积核计算,通常是越变越小的,也有一些特征层的输出和原来大小一样,称为“相同网络阶段”(same network stage )。对于本文的特征金字塔,作者为每个阶段定义一个金字塔级别, 然后选择每个阶段的最后一层的输出作为特征图的参考集。 这种选择是很自然的,因为每个阶段的最深层应该具有最强的特征。具体来说,对于ResNets,作者使用了每个阶段的最后一个残差结构的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出,并且注意它们相对于输入图像具有{4, 8, 16, 32}像素的步长。考虑到内存占用,没有将conv1包含在金字塔中。
自上而下的路径和横向连接
自上而下的路径(the top-down pathway )是如何去结合低层高分辨率的特征呢?方法就是,把更抽象,语义更强的高层特征图进行上取样,然后把该特征横向连接(lateral connections )至前一层特征,因此高层特征得到加强。值得注意的是,横向连接的两层特征在空间尺寸上要相同。这样做应该主要是为了利用底层的定位细节信息。
Figure 3显示连接细节。把高层特征做2倍上采样(最邻近上采样法),然后将其和对应的前一层特征结合(前一层要经过1 * 1的卷积核才能用,目的是改变channels,应该是要和后一层的channels相同),结合方式就是做像素间的加法。重复迭代该过程,直至生成最精细的特征图。迭代开始阶段,作者在C5层后面加了一个1 * 1的卷积核来产生最粗略的特征图,最后,作者用3 * 3的卷积核去处理已经融合的特征图(为了消除上采样的混叠效应),以生成最后需要的特征图。{C2, C3, C4, C5}层对应的融合特征层为{P2, P3, P4, P5},对应的层空间尺寸是相通的。
金字塔结构中所有层级共享分类层(回归层),就像featurized image pyramid 中所做的那样。作者固定所有特征图中的维度(通道数,表示为d)。作者在本文中设置d = 256,因此所有额外的卷积层(比如P2)具有256通道输出。 这些额外层没有用非线性(博主:不知道具体所指),而非线性会带来一些影响。
实际应用
本文方法在理论上早CNN中是通用的,作者将其首先应用到了RPN和Fast R-CNN中,应用中尽量做较小幅度的修改。
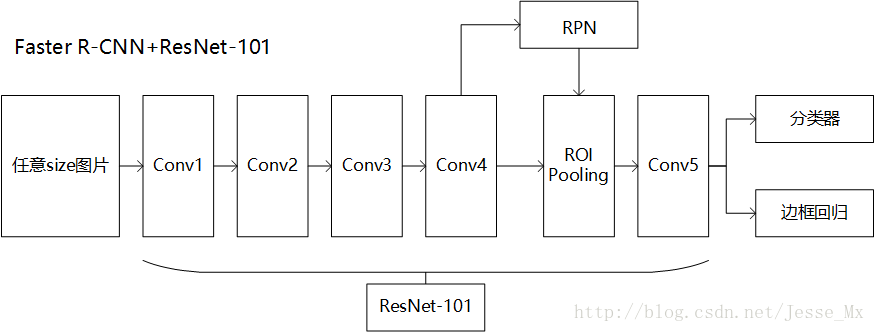
Faster R-CNN+Resnet-101
要想明白FPN如何应用在RPN和Fast R-CNN(合起来就是Faster R-CNN),首先要明白Faster R-CNN+Resnet-101的结构,这部分在是论文中没有的,博主试着用自己的理解说一下。
直接理解就是把Faster-RCNN中原有的VGG网络换成ResNet-101,ResNet-101结构如下图:
Faster-RCNN利用conv1到conv4-x的91层为共享卷积层,然后从conv4-x的输出开始分叉,一路经过RPN网络进行区域选择,另一路直接连一个ROI Pooling层,把RPN的结果输入ROI Pooling层,映射成7 * 7的特征。然后所有输出经过conv5-x的计算,这里conv5-x起到原来全连接层(fc)的作用。最后再经分类器和边框回归得到最终结果。整体框架用下图表示:
RPN中的特征金字塔网络
RPN是Faster R-CNN中用于区域选择的子网络,具体原理就不详细解释了,可阅读论文和参考博客:faster-rcnn 之 RPN网络的结构解析 。
RPN是在一个13 * 13 * 256的特征图上应用9种不同尺度的anchor,本篇论文另辟蹊径,把特征图弄成多尺度的,然后固定每种特征图对应的anchor尺寸,很有意思。也就是说,作者在每一个金字塔层级应用了单尺度的anchor,{P2, P3, P4, P5, P6}分别对应的anchor尺度为{32^2, 64^2, 128^2, 256^2, 512^2 },当然目标不可能都是正方形,本文仍然使用三种比例{1:2, 1:1, 2:1},所以金字塔结构中共有15种anchors。这里,博主尝试画一下修改后的RPN结构(没有完整画出来,大概就是这样):
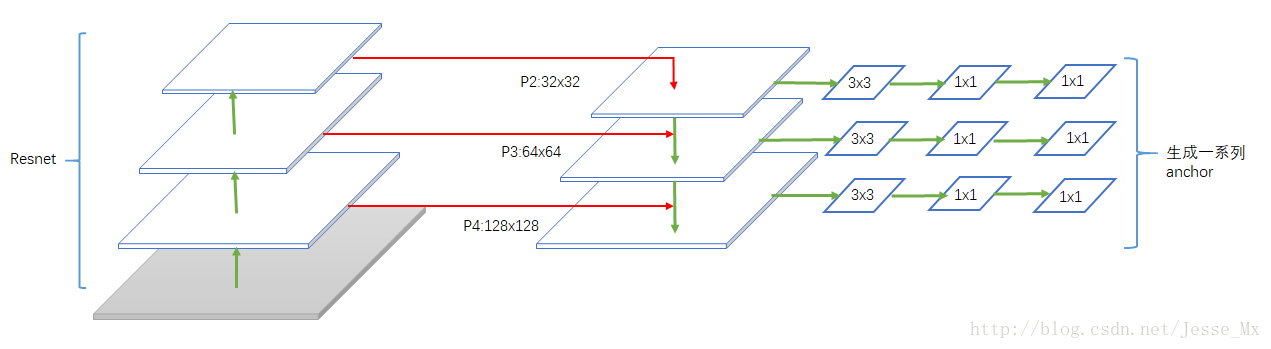
训练中,把重叠率(IoU)高于0.7的作为正样本,低于0.3的作为负样本。特征金字塔网络之间有参数共享,其优秀表现使得所有层级具有相似程度的语义信息。具体性能在实验中评估。
Fast R-CNN 中的特征金字塔网络
Fast R-CNN的具体原理也不详解了,参考博客:Fast R-CNN论文详解 ,其中很重要的是ROI Pooling层,需要对不同层级的金字塔制定不同尺度的ROI。
此部分的理解不太肯定,请各位辩证看待。博主认为,这里要把视角转换一下,想象成有一种图片金字塔在起作用。我们知道,ROI Pooling层使用region proposal的结果和中间的某一特征图作为输入,得到的结果经过分解后分别用于分类结果和边框回归。
然后作者想的是,不同尺度的ROI,使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用那个层的输出呢?这里作者定义了一个系数Pk,其定义为:
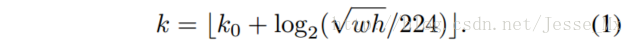
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数。
然后,因为作者把conv5也作为了金字塔结构的一部分,那么从前全连接层的那个作用怎么办呢?这里采取的方法是增加两个1024维的轻量级全连接层,然后再跟上分类器和边框回归。作者认为这样还能使速度更快一些。
目标检测实验
这个篇幅过长,不好搬上博客,只能大家自己去看了。实验部分也没有什么特别难懂的地方,该说的前面基本都讲了一下。
【Network Architecture】Feature Pyramid Networks for Object Detection(FPN)论文解析(转)的更多相关文章
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- Feature Pyramid Networks for Object Detection比较FPN、UNet、Conv-Deconv
https://vitalab.github.io/deep-learning/2017/04/04/feature-pyramid-network.html Feature Pyramid Netw ...
- 『计算机视觉』FPN:feature pyramid networks for object detection
对用卷积神经网络进行目标检测方法的一种改进,通过提取多尺度的特征信息进行融合,进而提高目标检测的精度,特别是在小物体检测上的精度.FPN是ResNet或DenseNet等通用特征提取网络的附加组件,可 ...
- Feature Pyramid Networks for Object Detection
Feature Pyramid Networks for Object Detection 特征金字塔网络用于目标检测 论文地址:https://arxiv.org/pdf/1612.03144.pd ...
- 论文阅读 | FPN:Feature Pyramid Networks for Object Detection
论文地址:https://arxiv.org/pdf/1612.03144v2.pdf 代码地址:https://github.com/unsky/FPN 概述 FPN是FAIR发表在CVPR 201 ...
- FPN-Feature Pyramid Networks for Object Detection
FPN-Feature Pyramid Networks for Object Detection 标签(空格分隔): 深度学习 目标检测 这次学习的论文是FPN,是关于解决多尺度问题的一篇论文.记录 ...
- FPN(feature pyramid networks)
多尺度的object detection算法:FPN(feature pyramid networks). 原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征 ...
- Paper Reading: Relation Networks for Object Detection
Relation Networks for Object Detection笔记 写在前面:关于这篇论文的背景知识,请参考我前面的两篇随笔(<关于目标检测>和<关于注意力机制> ...
- 特征金字塔网络Feature Pyramid Networks
小目标检测很难,为什么难.想象一下,两幅图片,尺寸一样,都是拍的红绿灯,但是一副图是离得很近的拍的,一幅图是离得很远的拍的,红绿灯在图片里只占了很小的一个角落,即便是对人眼而言,后者图片中的红绿灯也更 ...
随机推荐
- Network Security Services If you want to add support for SSL, S/MIME, or other Internet security standards to your application, you can use Network Security Services (NSS) to implement all your securi
Network Security Services | MDN https://developer.mozilla.org/zh-CN/docs/NSS 网络安全服务 (NSS) 是一组旨在支持支持安 ...
- H5 localStorage入门
定义 只读的 localStorage 允许你访问一个 Document 的远端(origin)对象 Storage:数据存储为跨浏览器会话.localStorage 类似于 sessionStora ...
- Spring AOP和事务的相关陷阱
1.前言 2.嵌套方法拦截失效 2.1 问题场景 2.2 解决方案 2.3 原因分析 2.3.1 原理 2.3.2 源代码分析 3.Spring事务在多线程环境下失效 3.1 问题场景 3.2 解决方 ...
- BitCoin Trading Strategies BackTest With PyAlgoTrade
Written by Khang Nguyen Vo, khangvo88@gmail.com, for the RobustTechHouse blog. Khang is a graduate f ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- react 日期
1.首先安装moment : npm install moment --save 2.在文件中引用: import moment from 'moment' 3.使用方式: 当前时间:moment() ...
- 获取当前文件夹以及子文件夹下所有文件C++
void getFiles( string path,vector<string>& files) { //文件句柄 ; //文件信息 struct _finddata_t fil ...
- 持续集成之戏说Check-in Dance(转)
add by zhj: 先说一下持续集成的定义,这是ThoughtWorks首席科学家Martin Fowler在<持续集成>第二版中给出的,“持续集成是一种软件开发实践.在持续集成中,团 ...
- java 多线程 day15 CyclicBarrier 路障
import java.util.concurrent.CyclicBarrier;import java.util.concurrent.ExecutorService;import java.ut ...
- 基于Flume+Kafka+ Elasticsearch+Storm的海量日志实时分析平台(转)
0背景介绍 随着机器个数的增加.各种服务.各种组件的扩容.开发人员的递增,日志的运维问题是日渐尖锐.通常,日志都是存储在服务运行的本地机器上,使用脚本来管理,一般非压缩日志保留最近三天,压缩保留最近1 ...