最直白、最易懂的话带你认识和学会---数据分析基础包之numpy的使用
前言
numpy是一个很基础很底层的模块,其重要性不言而喻,可以说对于新手来说是最基础的入门必须要学习的其中之一。在很多数据分析,深度学习,机器学习亦或是人工智能领域的模块中,很多的底层都会用到这个模块,是必知必会的一个基础模块。
那么numpy作为这么基础的一个模块,它是干什么的,它的主要功能是处理什么的,我可以直接告诉你,numpy主要用于数组的批量运算。
anaconda的安装
anaconda是一个开源的python版本,其包含了大量用于科学计算的包以及依赖项,所以数据分析或者科学计算,我们通常都会使用anaconda这个python版本,因为其中就包括了诸如numpy、pandas等模块,使用很方便。
anaconda的简单使用介绍
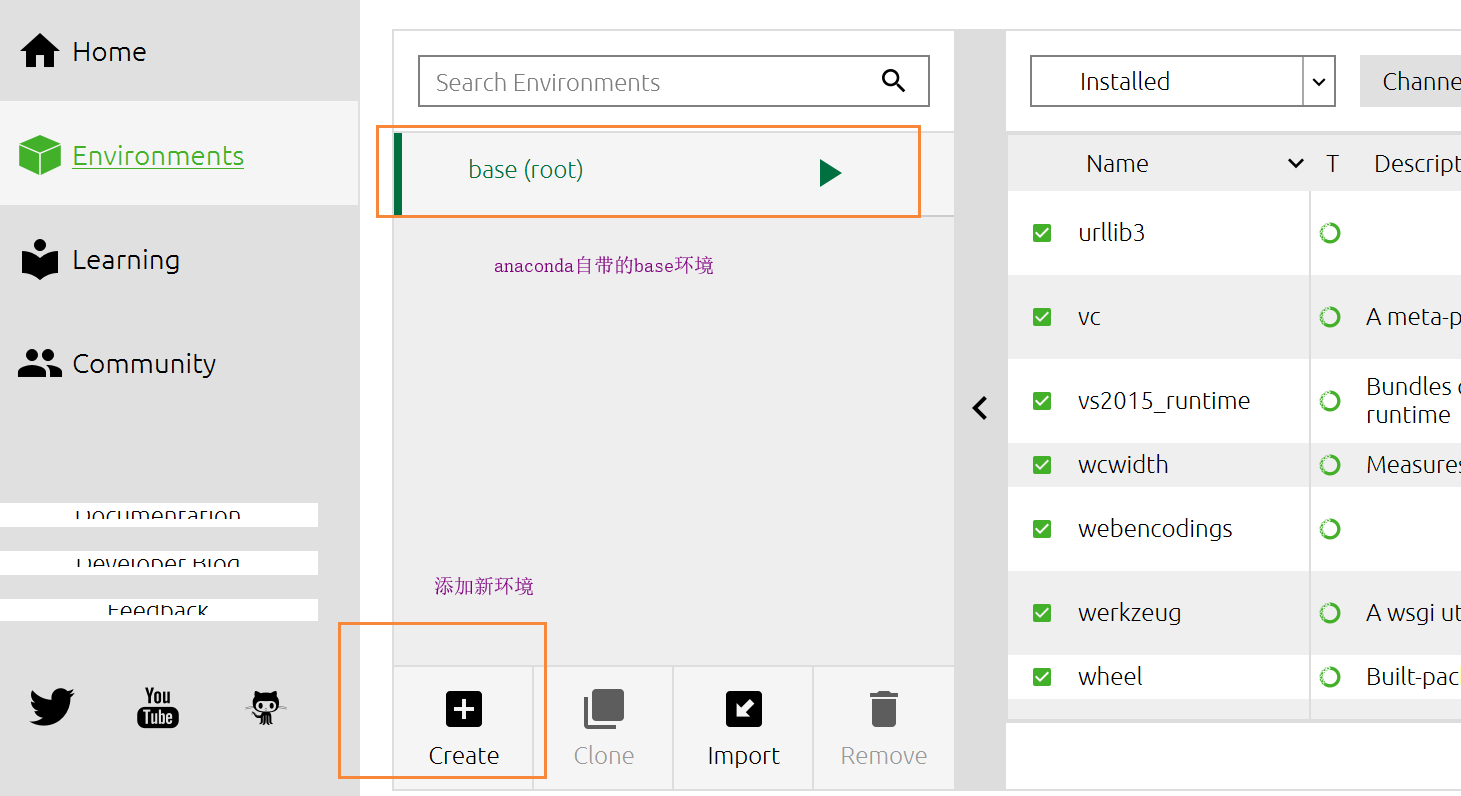
打开anaconda,Windows下命令行直接搜素anaconda,就会出来一个anaconda navigator,点击运行,就会出现如下界面

home页面会出现好多很好用的工具,包括自带的IDE,诸如 vscode、Spyder、jupyter等
environments就是用于环境的管理,类似于虚拟环境,可以自己定制自己需要的环境
learning里面都是很多的document文档
小结:
1.使用anaconda时,包管理器有两种,一种是conda <比如:conda install django>,另一种是pip,最好使用conda这个包管理器,因为在anaconda中继续使用python原本的包管理器pip,下载的包会默认下载到base中,所以最好使用conda
2.IPython解释器的不同,IPython的交互命令特别好看,更加友好,而且可以使用很多高级的命令,比如可以使用tab键进行补全后者查看所有可用的方法,在这些方法后加?可以查看当前方法的使用文档,还有IPython的命令行跟linux的很多基础命令是一样的,当然如果要在IPython的命令行中使用Windows的一些命令,需要在命令前加!
3.jupyter notebook 的使用,为啥不用其他IDE比如pycharm,因为所有的数据科学计算都是尝试性的工作,比如:做一个简单的求和运算,我们的做法就是先将数据读进来,然后运算,发现结果不行,再次进行其他运算就需要再次读入数据,如果数据量很大,一般数据科学的数据都很大,就会导致花费大量的时间进行读数据的操作,很浪费时间,而jupyter在这方面做得很好,它里面包含了很多单元格,每个单元格都是独立的,我们完全可以其中一个单元格运来存放读入的数据,然后在下面的单元格中使用,就会很方便。
接下来,回到我们今天本篇博客的主题上来,numpy的使用
numpy的使用
诚如上面所说,numpy是一个高性能科学计算和数据分析的基础包,它是pandas等其他各种工具的基础。
numpy的主要功能:
1. ndarray,一个多维数据结构,高效且节省空间
2. 无需循环对整组数据进行快速运算的数学函数
3. 读写磁盘数据的工具以及用于操作内存映射文件的工具
4. 线性代数、随机数生成和傅里叶变换功能
5. 用户集成C、C++等代码的工具
安装
pip/conda install numpy
备注:使用时,引入numpy时,大家约定成俗为 import numpy as np
使用
1.创建ndarray的方式:np.array()
np.array(li...) ---> ndarray 使用array方法,传入任意的列表,都可以转化为ndarray数据格式
ndarray是多维数组结构,与列表的区别:
1.数组对象内的元素类型必须相同
2.数组大小不可修改
ndarray格式的好处:
1.运行和执行效率快<更底层的优化处理,针对CPU做的批量处理的优化>,省内存<列表的存储是存储的对应数据的地址,而数组存储的是数据本身>
2.可以快速简单实现对大量的数据进行批量的运算 ,ndarray直接可以运算

备注: 使用jupyter时,输入输出结束时,可以使用快捷键 shift+enter 执行该单元格。上图输出为ndarray数据格式的输出格式
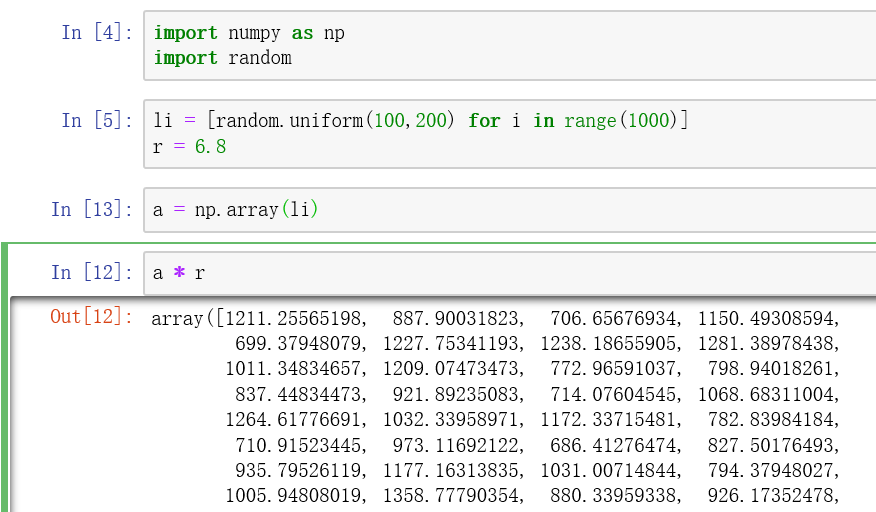
3. 两个相同长度为 m 的ndarray相乘,结果为m个值,两个对应的索引相乘,执行了一层循环,区别于两个相同长度的列表相乘,为两层循环,结果为 m**2个值
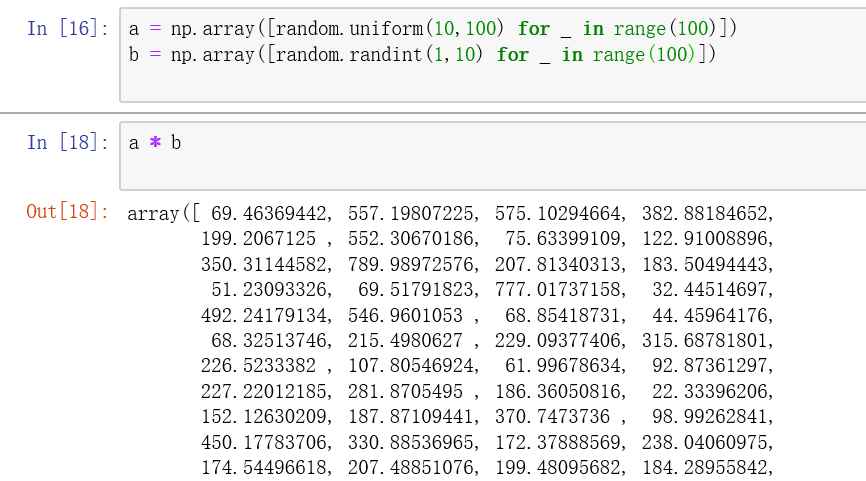
4.ndarray的求和运算 直接使用 ndarray.sum(), 或者也可以使用sum(ndarray),个人还是推荐使用前一种,为啥,感觉这个方法是numpy自身提供的,感觉内部肯定做了处理,运行和性能更好。
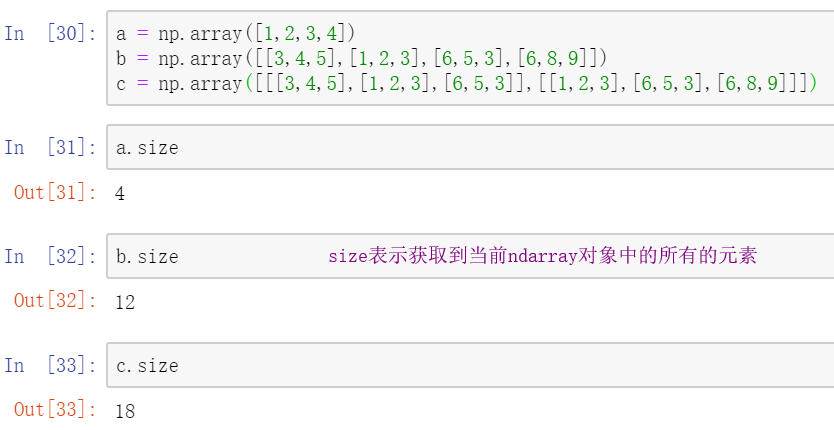
5. ndarray.size 获取ndarray中的元素个数,不管是几维列表,都可以获得所有的元素
6. ndarray.shape 以元组的形式返回当前ndarray对象的形状,即 是几维的列表
7. ndarray.ndim 用于判断当前ndarray对象的维度,几维就返回几

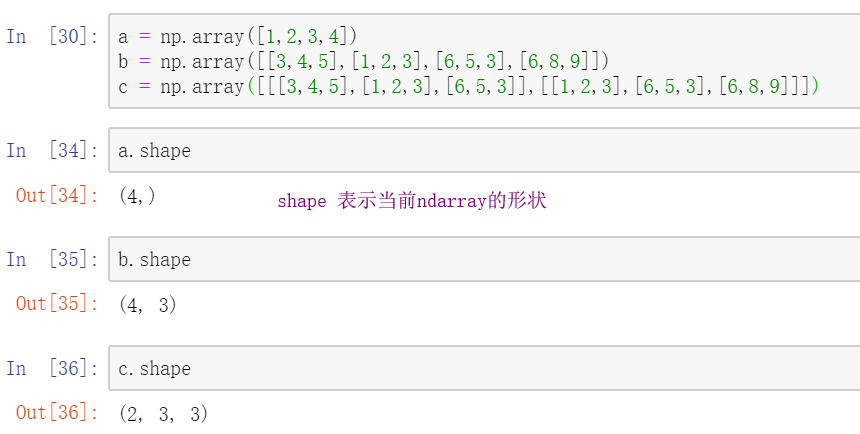
8. ndarray.T 只使用于高维列表(二维以上), 表示将数组转置,即将数组转90度,行变成列,列变成行
如图: 二维的转置

三维的转置
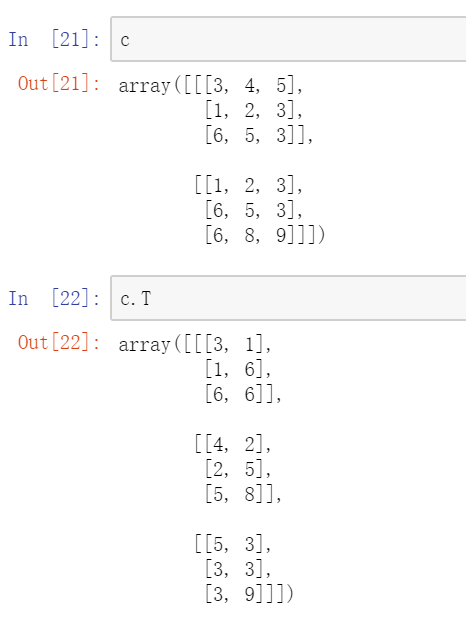
9. ndarray.dtype 返回当前ndarray的数据类型, 类型的转换 ndarray.astype("类型名")
备注: numpy是顶层使用的python语法,而底层是基于c自己实现了很多数据类型
ndarray的所有的数据类型:

特别注意: 为了区别于python中 的bool、int、float等类型,numpy的bool为bool_ 会加一个_
补充:我们都知道,int32表示32位的整数,在计算机中,32位的整数是有范围的,从 -2**31 ~ 2 **31-1,如果超过这个数就会造成内存的溢出

一般情况下不会出现这种现象,如果需要或者出现这种场景,如何解决呢?ndarray提供了一种数据类型转化或者说是声明的一种方式:ndarray.astype("int64") 注意:括号中为要转换的字符串格式的数据类型
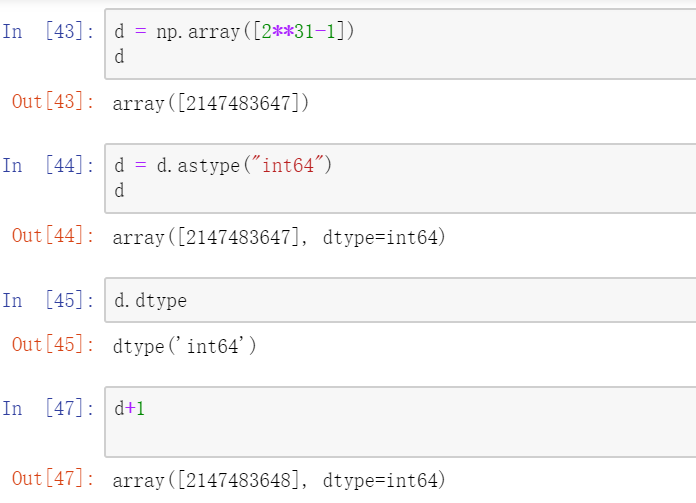
另外,我们在创建ndarray对象时,可以指定要创建的ndarray的类型 np.array([...], dtype="类型")

以上都是ndarray这个对象的使用方法,除了创建一个ndarray之外,numpy还有其他的一些方法
比如:
2、np.arange()
同python的range方法一样,返回一个数组,可以设置起点,终点,步长,比python中range这个方法更nb的是,他还支持小数级别的步长,默认情况下,arange的步长为1

补充:默认情况下np.arange生成的数组为一维的,那如何生成二维或者更多维的呢? np.arange提供了一个方法: np.arange(n).reshape(维度)

通过上图,心细的小伙伴肯定会问,你这有问题啊,reshape(3,5) 跟 reshape(3,-1) 结果都是生成了一个3行5列的二维数组啊,是一样的结果,其实这就是numpy底层实现的机制了,通过总数量,在已知n个维度上的n-1个数,numpy内部会默认计算出剩下的一位,所以才会如此。
3. np.linspace() 类似于arange方法,不同于arange的是,linspace的第三个参数不是步长,而是指定当前数组的元素个数
可以这么理解:比如 np.linspace(1,8,10) 将1到8之间分成9(10-1)份,使得最后的数组中有十个数,而且每个数之间的差值是一样的

4. np.zeros() np.ones() np.empty() 这三个是一组,表示创建一个指定形状的数组,可以额外使用dtype参数指定要创建数组的数据类型
区别: zeros 表示创建一个值都为0的数组, ones 表示创建一个值都为 1 的数组, empty 表示创建一个数组,不指定值

备注: zeros和ones的内部是这样的,程序向申请一块多少大小的内存,然后再将这个内存中的值全换替换为0或1,而empty只是申请一块内部才能,而不会去赋值,所有empty的执行效率会更好一些,如果我们只是申请一个数组,同时能够保证这个数组中的每个数都会有值,就可以直接使用empty。
5 np.eye() 和 np.identity() 创建指定形状和dtype的单位矩阵

索引和切片
数组的索引
一维数组与列表的索引是一样的,直接 : array[3]
对于多维数组,使用索引时,有两种表示方式:
1. 直接按照该维度数组的顺序取,比如: 二维数组取第3行第5列的数 :array[3][5]
2. 更推荐的写法,多个维度之间使用逗号隔开 array[3,5]
数组的切片
一维的数组切片跟列表是一样的
多维的列表,切片时,比如: 二维数组从第2行第3列切到第4行第8列 : array[2:4,3:8] 前面的表示先从第2行切到第4行,在取第3列到第8列
备注:
python中对列表进行切片,用一个新的变量指向他,我们修改这段切片的值,是不会修改原来列表中对应的值的,而数组不同,修改切片的值,就会修改原来数组的值。
比如:python的列表
li = [1,2,3,4,5,6,7,8]
a = li[3:5]
a[0] = 12
print(li) # 结果不变
数组对应的情形

数组的切片不同于列表的切片的原因:在python中,对列表切片等同于浅copy,浅拷贝第一层的地址是独立的,因为python的列表的底层实现不同于数组的底层实现,数组中存的就是该值,所以,数组的大小是无法改变的,而python的列表大小是可以随便改变的,因为python的底层中列表中存的是一个地址,一个指向该值的地址,python的切片就会copy一份该段列表的地址,改变其中某一个值,只是改变了copy出来的这段地址的一个指向的地址,而原列表中该值的指向地址是不变的,所以修改python的切片中的某一个值并不会改变原列表。而数组中存的就是该值,数组的切片只是告诉计算机,我这个变量表示的是这一段,类似了数据库中的视图,修改视图就会修改原来的。
那我如果想修改数组切片的值还不改变原数组值,那怎么办呢,很简单,直接使用 copy方法 a = array[3:6].copy(),这样在修改a的值,原数组是不会发生改变的,如图,不信自己试试

接下来是numpy的重头戏,最长用的操作
numpy的布尔型索引
可能很多人跟我一样,刚开始看到这个名字还有点晕,这是什么鬼,没关系,我们通过几个例子,带你真正的理解和使用它
例一:给一个数组,选出数组中所有大于5的数

相信看完这个例子后,会有一些小伙伴明白什么是布尔型索引了吧,而且很使用,因为实际的数据的过滤、筛选中都会碰到这样类似的问题,numpy简单、直接、高效的可以轻松解决这个问题。
明白了它的语法是怎么一回事了,那你知道他的原理吗?
在解释他的原理之前,先看两个东西
第一: 我们在文章的开头就提到了ndarray有一个特点,可以进行各种运算,支持+-*/操作,对数组中的每个元素都进行相应的操作,同时它也支持 > < 等操作,结果返回bool值

看到这里,你是不是有一种似懂非懂的感觉呢,不要急,请看第二
第二: 看下图
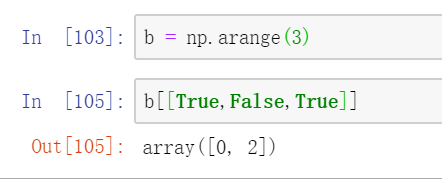
解释:将同样大小的布尔数组传进索引,会返回一个由所有True对应位置上元素的数组
综合上述两点,这就是 a[a>5]的原理,也是布尔型索引的原理
例二 : 给一个数组,选出数组中所有大于5的偶数
两种方法: 复杂的麻烦的方法:

推荐方法:

例三: 给一个数组,选出数组中所有大于5的数和偶数

例四 : 给一个数组,选出数组中所有不大于5的数

numpy的花式索引
懵逼了吧,看例子
例一: 对于一个数组,选出其第1,3,4,6,7个元素,组成新的数组

解释:将一个包含有对应元素所在位置的索引(整数)的数组传进索引,会返回一个由所有对应位置上元素的数组
例二: 对于一个二维数组,选出其第一列和第三列,组成新的二维数组

备注: 如果行或者列没有要求,就全切,使用 [:]表示行或者列
总结一下,上面我们总共罗列出了四种方式,常规的切片,常规的索引,布尔值索引,花式索引四种,这四种对于多维的数组,可以混合搭配使用
比如:

补充:特别注意,使用花式索引时,如果两边都是花式索引,会出问题,或者报错

两边都为花式索引时,就会换一种解析的方式,会取出,按照类似了坐标的取法,取出 [1,2]和[3,4]这么两个数,而不是二维数组的形式,因为取法类似于坐标,所以两边使用花式索引时,要保证两边的个数时一样的。
那我们就想这么取,而且还能达到我们想要的结果,怎么办?
思路:分两步, 先切行,再切列

numpy通用函数
通用函数:能同时对数组中所有元素进行运算的函数,即能够批量运算
常见的通用函数:
一元函数(函数中传一个参数的就是一元函数):
abs:取绝对值
sqrt:开根号
exp: 指数
log:对数
ceil:向上取整
floor:向下取整
rint:四舍五入取整
trunc:向0取整(截断取整)
modf:将原数组拆成两个数组,一个放原数组的小数部分,一个放原数组的整数部分(以小数的形式)

cos,sin,tan:三角函数
isnan:判断是不是nan类型的浮点数
备注:nan 是特殊的浮点数,但是他的语义却是:not a number 不是一个数
特别说明:这是唯一一个自己不等于自己的类型,即 x == x 为False,那我们如何判断一个数是不是nan呢?

判断一个变量是不是nan的方法:

那哪些情况下的结果为nan呢? 即不合法的数,比如 对负数开根号、0/0(当然能除尽的情况下)等

isinf: 判断是否为无穷大小数
备注:inf 也是一个特殊的浮点类型
inf这个数怎么得来呢,整数除以无限趋近于零的数就是无限趋近inf这个数,负数就是-inf


inf这个数怎么得来,示例如下:

补充:
nan 不等于任何浮点数 inf(infinity)比任何浮点数都大
numpy中创建特殊值:np.nan,np.inf ,创建-inf为:np.NINF
在数据分析中,nan常被用作表示数据缺失值
一个数组,怎么过滤掉nan或inf呢,直接使用布尔型索引

二元函数(函数中传两个参数的就是二元函数):
add(加) substract(减) multiply(乘) divide(除) power(乘方) mod(取模)
maximum minimum 两个相同长度的数组中批量性的一一对应的取最大或者最小

numpy中的数学和统计方法
np.sum() 求和 np.cumsum() 求前缀和或累计和 np.mean() 求平均数 np.std() 求标准差 np.var() 求方差
np.min() 求最小值 np.max() 求最大值 np.argmin() 求最小值索引 np.argmax()求最大值索引
这些方法中重点说cumsum ---前缀和,那什么是前缀和,就是一个数组中对应的位置上之前的所有数的和。
比如:

有的同学肯定会问这样的方法有什么用呢?
比如这样一个场景,求出这个数组中第3个数到第7个数之前数的和
这样的问题我们会怎么做,for循环或者切片,在求和,时间复杂度O(n),而cumsum方法貌似时间复杂度也是O(n)啊,没有感觉快啊,但是,如果这样的请求有k个,那我们之前的方法的时间复杂度就是O(nk)了。
所有,cumsum主要用于求一段区间的和, b[7]-b[3-1]
方差和标准差, 标准差是方差开根号,方差是一堆数的平均数与每一个数相减的平方和在除以这堆数的长度
Numpy的随机数
熟悉python的小伙伴都知道python中的标准库random模块,用来生成随机数,那numpy中的random有什么作用呢?
numpy中的random支持批量生成随机数
numpy中的random是numpy的一个子包,用法跟python中的random几乎一样。
那它们不一样的是啥呢?
首先,在python中 生成随机(0,1)之间小数的方法为 random.random(),而numpy中为 numpy.random.rand(),但是numpy的rand中支持出入一个数字,用于批量生成多个随机小数
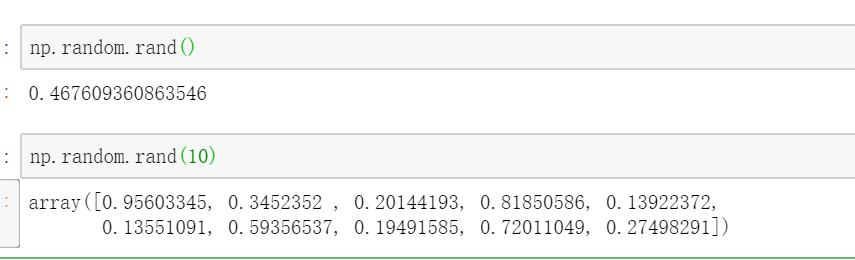
那如何批量生成多维数组呢? 很简单,多传参数即可 ,比如,批量生成二维的数组为 numpy.random.rand(10,8)
其他用法:
np.random.randint(m,n) 随机生成m到n的整数
np.random.randint(m,n,k) 随机生成k个m到n的整数
np.random.randint(m,n,(k,j)) 随机生成k行j列的m到n的整数的二维数组
小结:
np.random中其他的用法跟np.random.randint类似,对传一个参数,表示批量生成对个随机数(一维的),传一个元组,表示批量生成二维的
最直白、最易懂的话带你认识和学会---数据分析基础包之numpy的使用的更多相关文章
- weblogic自带的jdk是在工程的包部署后编译使用
weblogic自带的jdk是在工程的包部署后编译使用的.当用户把项目打包部署到weblogic上面,运行该项目的java环境jdk就是用的weblogic自带的jdk了,工程中的jdk和编译时的jd ...
- SVN服务器的配置(简单易懂,带配置文件,有注释)
这两天在服务器搭建了一个SVN服务器,一些经验,也留作后用把,有不详细的欢迎批评指正 另外关于子目录的访问配置,这块我还是不懂,希望有前辈能教我一下 1.安装SVN Serveryum install ...
- Jmeter 老司机带你一小时学会Jmeter
Jmeter的安装 官网下载地址:http://jmeter.apache.org/download_jmeter.cgi 作为Java应用,是需要JDK环境的,因此需要下载安装JAVA,并且作必 ...
- fiddler教程:抓包带锁的怎么办?HTTPS抓包介绍。
点击上方↑↑↑蓝字[协议分析与还原]关注我们 " 介绍Fiddler的HTTPS抓包功能." 这里首先回答下标题中的疑问,fiddler抓包带锁的原因是HTTPS流量抓包功能开启, ...
- HashMap源码深度剖析,手把手带你分析每一行代码,包会!!!
HashMap源码深度剖析,手把手带你分析每一行代码! 在前面的两篇文章哈希表的原理和200行代码带你写自己的HashMap(如果你阅读这篇文章感觉有点困难,可以先阅读这两篇文章)当中我们仔细谈到了哈 ...
- [kuangbin带你飞]专题十二 基础DP1
ID Origin Title 167 / 465 Problem A HDU 1024 Max Sum Plus Plus 234 / 372 Problem B HDU 1 ...
- 【算法系列学习】[kuangbin带你飞]专题十二 基础DP1 G - 免费馅饼
https://vjudge.net/contest/68966#problem/G 正解一: http://www.clanfei.com/2012/04/646.html #include< ...
- 【算法系列学习】[kuangbin带你飞]专题十二 基础DP1 F - Piggy-Bank 【完全背包问题】
https://vjudge.net/contest/68966#problem/F http://blog.csdn.net/libin56842/article/details/9048173 # ...
- 【算法系列学习】[kuangbin带你飞]专题十二 基础DP1 E - Super Jumping! Jumping! Jumping!
https://vjudge.net/contest/68966#problem/E http://blog.csdn.net/to_be_better/article/details/5056334 ...
随机推荐
- Linux网络接口配置文件解析
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0# Intel Corporation 82545EM Gigabit ...
- 使用adb命令查看apk版本
adb devices (显示连接的设备) adb root (获取手机root权限) adb remount (重新挂载系统分区,使系统分区重新可写) adb shell (进入目标设备的L ...
- tmp_table_size ---> 优化 MYSQL 经验总结
数据库连接突然增多到1000的问题 查看了一下,未有LOCK操作语句. 但是明显有好多copy to tmp table的SQL语句,这条语读的时间比较长,且这个表会被加读锁,相关表的update语句 ...
- 课程14:get和post是神马
http://www.codeschool.cn/lesson/14.html get和post是神马? get和post是http中两种最常用到的请求类型 简单理解get请求 get请求多用于获取信 ...
- 大自然的搬运工:Ubuntu环境下gedit的一些个简单配置
gedit是Ubuntu默认的文本编辑器,个人觉得还是不错的,用它来编程写一些小的demo也很方便,原谅我比较菜,vim用起来感觉打字速度真的很慢呀. 下面对gedit做一些简单配置,方便编程. 一. ...
- angular 有关侦测组件变化的 ChangeDetectorRef 对象
我们知道,如果我们绑定了组件数据到视图,例如使用 <p>{{content}}</p>,如果我们在组件中改变了content的值,那么视图也会更新为对应的值. angular ...
- C++标准库头文件找不到的问题
当你写C++程序时,在头文件中包含C++标准库的头文件,比如#include <string>,而编译器提示你找不到头文件! 原因就是你的实现源文件扩展名是".c"而不 ...
- z-index详细攻略
概念 z-index 属性设置元素的堆叠顺序.拥有更高堆叠顺序的元素总是会处于堆叠顺序较低的元素的前面. 层级关系的比较 1. 对于同级元素,默认(或position:static)情况下文档流后面的 ...
- Python学习笔记(十八)@property
# 请利用@property给一个Screen对象加上width和height属性, # 以及一个只读属性resolution: # -*- coding: utf-8 -*- class Scree ...
- void指针和NULL指针
Void指针和NULL指针 Void指针: Void指针我们称之为通用指针,就是可以指向任意类型的数据.也就是说,任何类型的指针都可以赋值给Void指针. 举例: #include<stdio. ...