hbase(二)
一、HBase简介
1.1简介
hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
1.2 Hbase与传统数据库的对比
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族(row family)。
我们可以先来看一下传统的关系型数据库中的表:
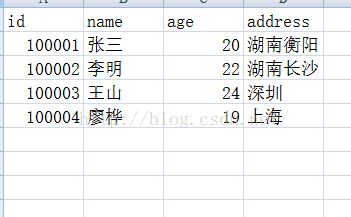
然后与HBase的表进行对比,hbase的表结构,与传统的关系型数据库有较大的差别
我们就可以发现很多不同地方:
hbase不支持sql语句,它是一个nosql的一种,如果没有学过nosql或rubey,我们可以用help
1、定义表时不指定字段
2、定义表的时候只要指定列族名,列族数量不限
3、每一行都有一个固定的字段(行键),具有唯一性
4、对值的修改,原来的值是保留着的,每个值可以保留多个版本。默认查询的是最新版本的的值。(默认保留一个版本)
1.3 HBase中的重要概念
列族:hbase表中的每个列,都归属与某个列族。列族是表的chema的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history , courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因 为隐私的原因不能浏览所有数据)。
时间戳:HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
Cell:由{row key, column( =<family> + <label>),version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。

二、HBase体系结构
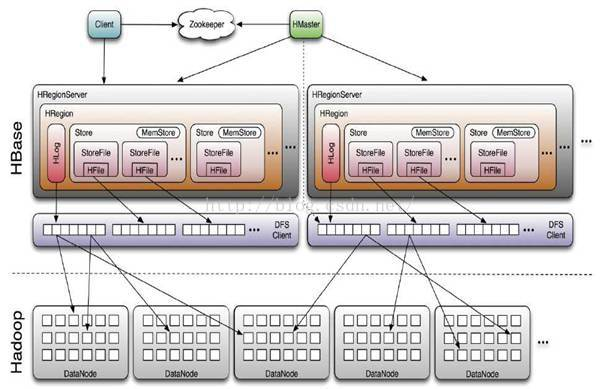
2、每一个region内部还要一句列族划分为若干个HStore
3、每个HStore中的数据会落地到若干个HFILE文件中
4、region体积会随着数据插入而不断增长,到一定阈值后分裂
5、随着region的分裂,一台regionserver上管理的region会越来越多
6、HMASTER会根据regionserver上管理的region数做负载均衡
7、region中的数据拥有一个内存缓存:memstore,数据的访问优先在memstore中进行
8、memstore中的数据因为空间有限,所以需要定期flush到文件storefile中,每次flush都是生成新的storefile
9、storefile的数量随着时间也会不断增加,regionserver会定期将大量storefile进行合并(merge)
行键的设计对数据查询效率的影响非常大。
hbase可以作为一个线上系统的底层系统的功能。
Hmaster可以做负载均衡,监控到各个节点之间的数据存储情况。
每一个store(列族)会有一个内存缓存,存放的是一些最热的数据(最近访问的),这样的话读取数据的速度会快很多。
文件都是有索引的,所以查起来会比较快的。
三、HBase shell的使用
create 'user-info',{NAME=>'base_info',VERSIONS=>},{NAME=>'extra_info'}
put 'user-info','rk-100001','base_info:name','huang****'
put 'user-info','rk-100001','base_info:age',''
put 'user-info','rk-100001','base_info:address','Xinyang'
put 'user-info','rk-100001','base_info:tel',''
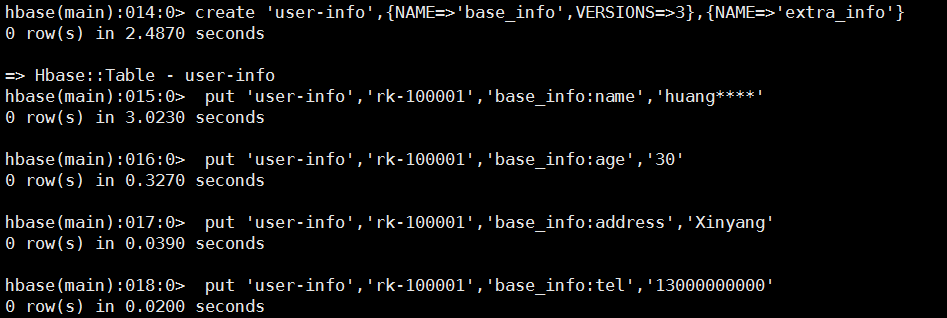
scan 'user-info'

四、eclipse中使用HBase
// 与HBase数据库的连接对象
Connection conn;
@Before
public void setUp() throws Exception { // 取得一个数据库连接的配置参数对象
Configuration conf = HBaseConfiguration.create();
// 设置连接参数:HBase数据库所在的主机IP
conf.set("hbase.zookeeper.quorum", "master,node1,node2");
// 设置连接参数:HBase数据库使用的端口
conf.set("hbase.zookeeper.property.clientPort", "2181"); // 取得一个数据库连接对象
conn = ConnectionFactory.createConnection(conf);
} @Test
public void put() throws Exception { // 通过连接工厂创建连接对象
//conn = ConnectionFactory.createConnection(conf);
// 通过连接查询tableName对象
TableName tname = TableName.valueOf("ns1:t1");
// 获得table
Table table = conn.getTable(tname); // 通过bytes工具类创建字节数组(将字符串)
byte[] rowid = Bytes.toBytes("row3"); // 创建put对象
Put put = new Put(rowid); byte[] f1 = Bytes.toBytes("f1");
byte[] id = Bytes.toBytes("id");
byte[] value = Bytes.toBytes(102);
put.addColumn(f1, id, value); // 执行插入
table.put(put);
} @Test
public void bigInsert() throws Exception { DecimalFormat format = new DecimalFormat();
format.applyPattern("0000"); long start = System.currentTimeMillis();
TableName tname = TableName.valueOf("ns1:t1");
HTable table = (HTable) conn.getTable(tname);
// 不要自动清理缓冲区
table.setAutoFlush(false); for (int i = 1; i < 10000; i++) {
Put put = new Put(Bytes.toBytes("row" + format.format(i)));
// 关闭写前日志
put.setWriteToWAL(false);
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("id"), Bytes.toBytes(i));
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"), Bytes.toBytes("tom" + i));
put.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"), Bytes.toBytes(i % 100));
table.put(put); if (i % 2000 == 0) {
table.flushCommits();
}
}
//
table.flushCommits();
System.out.println(System.currentTimeMillis() - start);
} /**
* 遍历
*/
@Test
public void scan() throws IOException {
TableName tname = TableName.valueOf("ns1:t1");
Table table = conn.getTable(tname);
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("row5000"));
scan.setStopRow(Bytes.toBytes("row8000"));
ResultScanner rs = table.getScanner(scan);
Iterator<Result> it = rs.iterator();
while (it.hasNext()) {
Result r = it.next();
byte[] name = r.getValue(Bytes.toBytes("f1"), Bytes.toBytes("name"));
System.out.println(Bytes.toString(name));
}
} /**
* 动态遍历
*/
@Test
public void scan2() throws IOException {
//Configuration conf = HBaseConfiguration.create();
//Connection conn = ConnectionFactory.createConnection(conf);
TableName tname = TableName.valueOf("ns1:t1");
Table table = conn.getTable(tname);
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("row5000"));
scan.setStopRow(Bytes.toBytes("row8000"));
ResultScanner rs = table.getScanner(scan);
Iterator<Result> it = rs.iterator();
while (it.hasNext()) {
Result r = it.next();
Map<byte[],byte[]> map = r.getFamilyMap(Bytes.toBytes("f1"));
for(Map.Entry<byte[],byte[]> entrySet : map.entrySet()){
String col = Bytes.toString(entrySet.getKey());
String val = Bytes.toString(entrySet.getValue());
System.out.print(col + ":" + val + ",");
} System.out.println();
}
}
参考:http://blog.csdn.net/sdksdk0/article/details/51680296
http://blog.csdn.net/u011308691/article/details/51476383
hbase(二)的更多相关文章
- HBase二次开发之搭建HBase调试环境,如何远程debug HBase源代码
版本 HDP:3.0.1.0 HBase:2.0.0 一.前言 之前的文章也提到过,最近工作中需要对HBase进行二次开发(参照HBase的AES加密方法,为HBase增加SMS4数据加密类型).研究 ...
- Hbase(二)【shell操作】
目录 一.基础操作 1.进入shell命令行 2.帮助查看命令 二.命名空间操作 1.创建namespace 2.查看namespace 3.删除命名空间 三.表操作 1.查看所有表 2.创建表 3. ...
- HBase(二): c#访问HBase之股票行情Demo
上一章完成了c#访问hbase的sdk封装,接下来以一个具体Demo对sdk进行测试验证.场景:每5秒抓取指定股票列表的实时价格波动行情,数据下载后,一方面实时刷新UI界面,另一方面将数据放入到在内存 ...
- HBase 二次开发 java api和demo
1. 试用thrift python/java以及hbase client api.结论例如以下: 1.1 thrift的安装和公布繁琐.可能会遇到未知的错误,且hbase.thrift的版本 ...
- 【Hbase二】环境搭建
此笔记仅用于作者记录复习使用,如有错误地方欢迎留言指正,作者感激不尽,如有转载请指明出处 Hbase环境搭建 Hbase环境搭建 hadoop为HA的Hbase配置 Zookeeper集群的正常部署并 ...
- SHDP--Working With HBase (二)之HBase JDBC驱动Phoenix与SpringJDBCTemplate的集成
Phoenix:Phoenix将SQL查询语句转换成多个scan操作,并编排执行最终生成标准的JDBC结果集. Spring将数据库访问的样式代码提取到JDBC模板类中,JDBC模板还承担了资源管 ...
- Hive(五):hive与hbase整合
配置 hive 与 hbase 整合的目的是利用 HQL 语法实现对 hbase 数据库的增删改查操作,基本原理就是利用两者本身对外的API接口互相进行通信,两者通信主要是依靠hive_hbase-h ...
- org.apache.hadoop.hbase.MasterNotRunningException解决策略
执行HBase时常会遇到个错误,我就有这种经历. ERROR: org.apache.hadoop.hbase.MasterNotRunningException: Retried 7 times 检 ...
- HBase(六)HBase整合Hive,数据的备份与MR操作HBase
一.数据的备份与恢复 1. 备份 停止 HBase 服务后,使用 distcp 命令运行 MapReduce 任务进行备份,将数据备份到另一个地方,可以是同一个集群,也可以是专用的备份集群. 即,把数 ...
随机推荐
- PHP curl_setopt函数用法介绍中篇
此篇已实例为主. 一.一般的实例 demo1.php <?php $user = "admin123"; $pass = "admin456"; // $ ...
- UILabel 行间距设置
NSMutableAttributedString * attributedString1 = [[NSMutableAttributedString alloc] initWithString:te ...
- poj_1258 prim最小生成树
题目大意 给定N个点,以及每两个点之间的路径长度,求出一个连接这N个点的方案,使得连接这N个点的总长度最短,求出该总长度. 题目分析 求最小生成树MST的模板题,直接使用prim算法进行求解. 实现( ...
- js小功能实现
发送随机数手机验证码60秒倒计时 mm.mobileCheck = function(t){ var mobile = $("#user_mobile").val(); if(&q ...
- jquery将具有相同名称的元素的值提取出来放到一个数组内
jquery将具有相同名称的元素的值提取出来放到一个数组内 var arrInputValues = new Array(); $("input[name='xxx']").ea ...
- Android StaggeredGrid 加下拉刷新功能 PullToRefresh
https://github.com/etsy/AndroidStaggeredGrid 用的github上面提供瀑布流,继承于abslistview,回收机制不错,并且提供了OnScrollLis ...
- Hibernate的调用数据库的存储过程
Hibernate并没有给出直接调用数据库的存储过程的API,所以咋们就要通过调用原生的的connection对象来实现对存储过程的条用 Hibernate调用存储过程的步骤: 1:获得原生conne ...
- OSharp DbContent初始化分析
DBContent初始化 —— 关联Entity查找 一. 关联到具体的Entity 二. 通过EntityTypeConfiguration 关联到DbContent 三. ...
- If the parts of an organization (e.g., teams, departments, or subdivisions) do not closely reflect the essential parts of the product, or if the relationship between organizations do not reflect the r
https://en.wikipedia.org/wiki/Conway%27s_law
- 在Win10上,Android Studio检测不到设备的解决方案
下载ADB驱动程序安装器 运行ADBDriverInstaller.exe,可以看到设备状态不正常,点击Install 可能会弹出这样的对话框,点击Got it, Restart Now,按照提示完成 ...