HBase安装过程
1).上传,解压,重命名,修改环境变量/etc/profile
2).修改 hbase-env.sh 文件
export JAVA_HOME=/usr/java/jdk1.7.0_27 //Java 安装路径
export HBASE_CLASSPATH=/hadoop/hbase-0.96.2 //HBase 类路径
export HBASE_MANAGES_ZK=true //由 HBase 自己负责启动和关闭 Zookeeper
3).编辑 hbase-site.xml 文件
<property>
<name>hbase.rootdir</name>
//hbase 中数据存放的HDFS根路径
<value>hdfs://hadoop01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
//hbase 是否安装在分布式环境中
<value>true</value>
</property>
<property>
//指定 Hbase 的 ZK 节点位置,由于上述已指定 Hbase 自己管理 ZK
<name>hbase.zookeeper.quorum</name>
<value>hadoop01</value>
</property>
<property>
<name>dfs.replication</name>
//伪分布环境,副本数为 1
<value>1</value>
</property>
4).(可选)文件regionservers
//这个文件指定了 regionservers,即子节点所在的位置
hadoop01(即本机主机名或IP)
5).启动 HBase
******启动 hbase 之前,确保 hadoop 是运行正常的,并且可以写入文件*******
启动脚本:start-hbase.sh
验证方式:(1)执行 jps,发现新增加了 3 个 java 进程,分别是 HMaster、HRegionServer、HQuorumPeer
(2)使用浏览器访问 http://hadoop01:60010
6).shell 操作
命令:hbase shell 进入 shell 操作的终端。
***对于在使用 SecureCRT 在 shell 终端无法使用删除键的问题:在 secureCRT 中,点击【选项】【会话选项】【终端】【仿真】,右边的终端选择 linux,在 hbase shell 中如输入出错,按住 Ctrl+删除键 即可删除!
7).基本操作
创建表 Create
--Create '表名称','列族1','列族2','列族N'
--【注意结尾处没有;】【RowKey 是天然自带的,不用手动指定】

查看表信息 List 和 Describe


插入数据 Put
--Put '表名','行键Row Key','列族:列','列值'
put 'users','xiaoming','user_id:id','' --批量插入,每行结尾木有;
put 'users','xiaoming','info:age',''
put 'users','xiaoming','info:birthday','1987-06-17'
put 'users','xiaoming','info:company','alibaba'
put 'users','xiaoming','address:contry','china'
put 'users','xiaoming','address:province','zhejiang'
put 'users','xiaoming','address:city','hangzhou'
put 'users','zhangyifei','info:birthday','1987-4-17'
put 'users','zhangyifei','info:favorite','movie'
put 'users','zhangyifei','info:company','alibaba'
put 'users','zhangyifei','address:contry','china'
put 'users','zhangyifei','address:province','guangdong'
put 'users','zhangyifei','address:city','jieyang'
put 'users','zhangyifei','address:town','xianqiao'
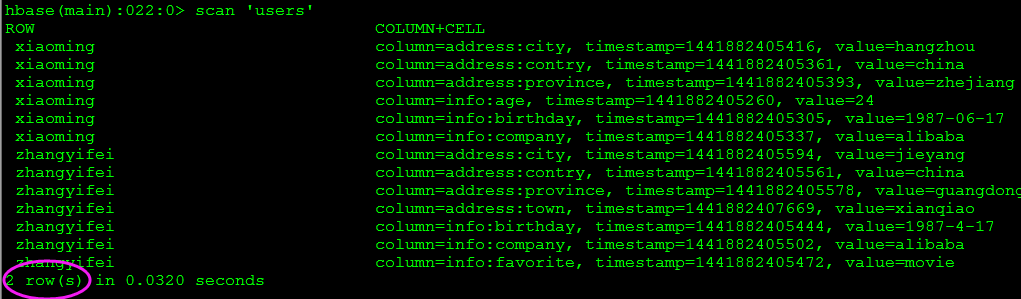
全表扫描 Scan
两个RowKey:‘xiaoming’和'zhangyifeng'对应两行记录
查询一个 RowKey 中所有数据(即一行数据) Get

查询一个RowKey中一个列族的所有数据

查询一个RowKey的列族中一个列的所有数据

同时查询两个列族的所有数据(两种方法)
注意:第二种方法中的COLUMN关键字大小写敏感


同时查询两个列族中两个列的所有数据(两种方法)


更新表中的数据 Put
由于hdfs只支持写入和追加操作,所以hbase对于修改数据,只能进行准加覆盖操作


获取单元格Cell数据的时间戳


对于操作VERSIONS=>2也只返回一行数据,这是由于在创建表时,没有显示指定VERSIONS版本个数,则会设置为默认值1。通过命令describe ‘users’可以发现VERSION=>’1’。
通过TIMESTAMP读取数据

删除某行数据 Delete
deleteall 'users','xiaoming'
删除某一列的数据 Delete
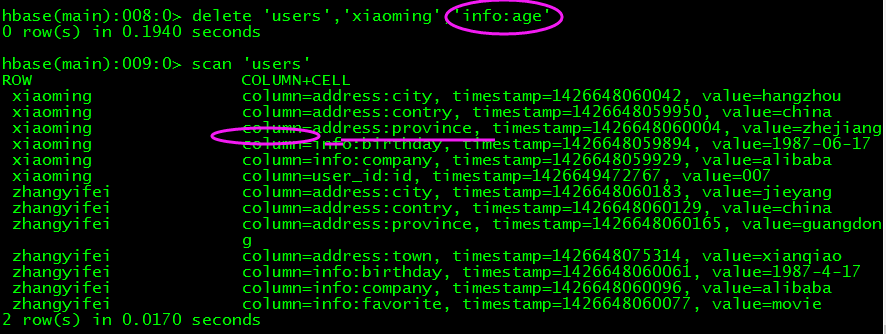
这里和SQL有区别:SQL中删除某一列的话整行数据都会被删除。而HBase则不然,它可以删除指定的列而不影响其它列的数据
修改表的结构:删除某一列族 Alter

全表扫描 Scan
红圈表示此表中现在只有两条记录,因为只有两个RowKey: ’xiaoming’ + ‘zhangyifei’

这时我们发现,表中的”user_id”这个列族已经被删掉,并且它对应的值‘007’也一并被删除---这是DDL的操作。
统计表的行数 Count

清空表的数据 Truncat
这个指令实际包含三个操作:disable + drop + create

判断一个表是否存在 exists
exit是退出HBase shell,切记

判断表是否enable或disable is_enabled 'users'
删除表Drop TableName之前,必须先使其disable:disable TableName 不然报错


HBase安装过程的更多相关文章
- HBase 安装过程记录
http://blog.csdn.net/chenxingzhen001/article/details/7756129 环境: 操作系统Centos 6.4 32-bit 三台节点 ip ...
- HBase - 安装过程中的问题
问题1:启动时start-hbase.sh 报 权限不够 原因:在移动文件时,使用root用户在/usr/local下创建的hbase,所以hbase文件夹的使用者为root,其他人没权限 解决方案: ...
- hbase 1.1.7在centor6.5安装过程
1.自己安装的最新版一直没成功,换成了1.1.7稳定版的.中间遇到的问题记录下 1) jdk 用的1.7版本的,安装过程省略. 2)下载hbase zip包:https://mirrors.tuna ...
- HBASE的安装过程及运行HBASE程序的需要配置的内容
HBase安装配置 ①下载压缩包(选择与自己安装的Hadoop版本的兼容版本,见后面附录) 官网下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hba ...
- hbase安装
HBase的安装 本篇介绍两种HBase的安装方式:本地安装方式和伪分布式安装方式. 安装的前提条件是已经成功安装了hadoop,而且hadoop的版本要和hbase的版本相匹配. 我将要安装的hba ...
- Hadoop第12周练习—HBase安装部署
1 1.1 1.2 :安装HBase 2.1 内容 运行环境说明 1.1 硬软件环境 线程,主频2.2G,6G内存 l 虚拟软件:VMware® Workstation 9.0.0 build-8 ...
- Hbase总结(一)-hbase命令,hbase安装,与Hive的区别,与传统数据库的区别,Hbase数据模型
Hbase总结(一)-hbase命令 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令表达式 创建表 create '表名称', ...
- HBase安装inAction
在安装Hbase之前,需要有hadoop的运行环境,关于hadoop的安装过程,请查看我之前的blog:hadoop安装笔记:或者另一个博主的超详细文章http://weixiaolu.iteye.c ...
- hbase总结(二)-hbase安装
本篇介绍两种HBase的安装方式:本地安装方式和伪分布式安装方式. 安装的前提条件是已经安装成功了hadoop,并且hadoop的版本号要和hbase的版本号相匹配. 我将要安装的hbase是hbas ...
随机推荐
- Hadoop伪分布安装详解(一)
注:以下截图针对Ubuntu操作系统,对Centos步骤类似.请读者选择不同镜像即可. 第一部分:VMware WorkStation10 安装 1.安装好VMware10虚拟机软件并下载好Ubunt ...
- java递归构建菜单树
package testSimple; import java.util.ArrayList; import java.util.List; public class BuildTree { publ ...
- [iOS微博项目 - 3.5] - 封装业务
github: https://github.com/hellovoidworld/HVWWeibo A.封装微博业务 1.需求 把微博相关业务(读取.写微博) 界面控制器不需要知道微博操作细节( ...
- node.js使用require给flume提交请求
node.js使用require给flume提交请求 - 简书 https://www.jianshu.com/p/02c20e2d011a 玄月府的小妖在debug 关注 2017.04 ...
- $obj->0
w对象 数组 分别对内存的 消耗 CI result() This method returns the query result as an array of objects, or an empt ...
- Apache Kafka源码分析 – Replica and Partition
Replica 对于local replica, 需要记录highWatermarkValue,表示当前已经committed的数据对于remote replica,需要记录logEndOffsetV ...
- Spark源码分析 – Deploy
参考, Spark源码分析之-deploy模块 Client Client在SparkDeploySchedulerBackend被start的时候, 被创建, 代表一个application和s ...
- JSON 序列化与反序列化(二)使用TypeReference 构建类型安全的异构容器
1. 泛型通常用于集合,如Set和Map等.这样的用法也就限制了每个容器只能有固定数目的类型参数,一般来说,这也确实是我们想要的. 然而有的时候我们需要更多的灵活性,如数据库可以用任意多的Column ...
- git子模块submodule
添加submodule: git submodule add 子模块git地址 把这个module放置的文件夹(这个文件夹须事先不存在) git submodule add http://xxx.x ...
- PAT 1145 Hashing - Average Search Time [hash][难]
1145 Hashing - Average Search Time (25 分) The task of this problem is simple: insert a sequence of d ...