Redis 数据结构-字符串源码分析
相关文章
本文将从以下几个部分进行介绍
1.前言
2.常用命令
3.字符串结构
4.字符串实现
5.命令是如果操作字符串的
前言
平时在使用 Redis 的时候,只会使用简单的 set,get,并不明白其中的道理,为了探个究竟,搞个明白,就看了下其底层的实现,本人的C言语水平只停留在大学上课堂上,所以看起来还是有点吃力,好在一些关键流程,数据结构还是看得懂 ^ ^。
Redis 的字符串是 Redis 中最基本的一种数据结构,所有的 key 都用字符串表示,且它是二进制安全的;它在内部使用一种称为动态字符串的结构来表示,可以动态的进行扩展,可以在 O(1) 的时间内获取字符串的长度等,此外,一个字符串的长度最多不能超过 512M。
常用命令
字符串的一些常用命令如下:
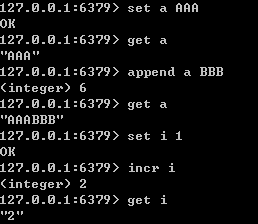
set key value - 设置值
get key -获取值
append key value - 追加值
decr key - 原子减1
incr key - 原子加1
.......
动态字符串(SDS)结构定义
在解析动态字符串之前,先来看看 Redis 中 Object 的定义,源码在 object.c 中,在该Object的中,定义了创建对象的一些方法,如创建字符串,创建list,创建set等,之外,还指定了对象的编码方法;接下来看下和字符串相关的方法:
指定对象的编码方式:
<code class="language-cpp"># object.c
char *strEncoding(int encoding) {
switch(encoding) {
case OBJ_ENCODING_RAW: return "raw";
case OBJ_ENCODING_INT: return "int";
case OBJ_ENCODING_HT: return "hashtable";
case OBJ_ENCODING_QUICKLIST: return "quicklist";
case OBJ_ENCODING_ZIPLIST: return "ziplist";
case OBJ_ENCODING_INTSET: return "intset";
case OBJ_ENCODING_SKIPLIST: return "skiplist";
case OBJ_ENCODING_EMBSTR: return "embstr";
default: return "unknown";
}
}
字符串存储主要的编码方式主要有两种 : embstr 和 raw
这两种方式有什么区别呢?在什么情况下使用 embstr,在什么情况下使用 raw 呢?
当存储的字符串很短的时候,会使用 embstr 进入编码,当存储的字符串超过 44 个字符的时候,会使用 raw 进行编码;可以使用 debug object key 来查看编码方式,看以下的实验:
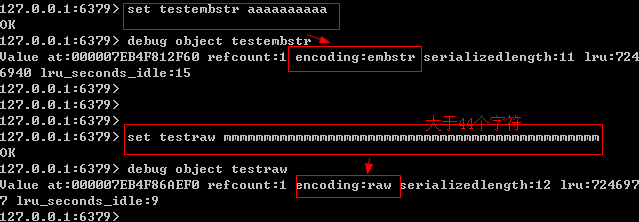
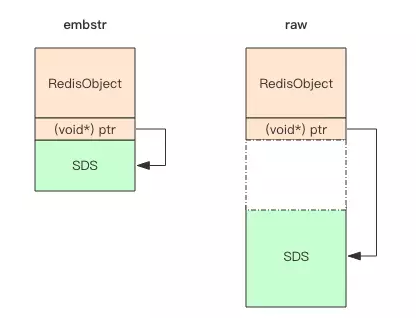
embstr 编码的存储方式为 将 RedisObject 对象头和 SDS 对象连续存在一起,使用 malloc 方法一次分配内存,而 raw 它需要两次 malloc 分配内存,两个对象头在内存地址上一般是不连续的,它们的结构如下所示:
在 object.c 源码中看下两种字符串的创建方式:
<code class="language-cs"># object.c
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o)); // 只是申请对象头的空间,会把指针指向 SDS
o->type = type;
o->encoding = OBJ_ENCODING_RAW; // 编码格式为 raw,为默认的编码方式
o->ptr = ptr; // 指针指向 SDS
o->refcount = 1;
// 可忽略
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
// 把对象头和SDS 连续存在一起
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR; // 为 embstr 编码方式
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
SDS 定义
接下来看下动态字符串(SDS)的结构定义,该定义是在 sds.h 文件中,
<code class="language-cs">//
typedef char *sds;
// 该结构体不再使用
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
SDS 结构定义了五种不同 header 类型,不同字符串的长度使用不同的 header 类型,从而可以节省内存。
每种 header 类型包含以下几个属性:
1. len : 字符串的长度
2. alloc : 表示字符串的最大容量,不包含 header 和空的终止符
3. flags : header的类型
4. buf: 存放字符串的数组
这几种类型使用如下的宏表示:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
在该定义文件中,还定义了一些方法,如下:
获取 sds 的长度,其中, SDS_HDR 表示获取 header 指针。
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
获取存储字符串的数组中还剩多少容量,用最大容量 - 字符串的长度
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}
接下来,看一下字符串的一些常用的方法,这些方法主要是在 sds.c 文件中:
1. 根据字符串的大小来获取请求的 header 类型
static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5) // 32
return SDS_TYPE_5;
if (string_size < 1<<8) // 256
return SDS_TYPE_8;
if (string_size < 1<<16) // 65536
return SDS_TYPE_16;
#if (LONG_MAX == LLONG_MAX)
if (string_size < 1ll<<32)
return SDS_TYPE_32;
return SDS_TYPE_64;
#else
return SDS_TYPE_32;
#endif
}
2. 根据类型获取结构体大小
static inline int sdsHdrSize(char type) {
switch(type&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return sizeof(struct sdshdr5);
case SDS_TYPE_8:
return sizeof(struct sdshdr8);
case SDS_TYPE_16:
return sizeof(struct sdshdr16);
case SDS_TYPE_32:
return sizeof(struct sdshdr32);
case SDS_TYPE_64:
return sizeof(struct sdshdr64);
}
return 0;
}
3. 创建SDS
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
// 根据字符串长度获取请求类型
char type = sdsReqType(initlen);
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
// 根据类型获取结构体大小
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
// 申请内存,+1 是为了处理最后一位 \0 的情况
sh = s_malloc(hdrlen+initlen+1);
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1); //如果创建的sds为空,则以0填充
if (sh == NULL) return NULL;
s = (char*)sh+hdrlen; // 指向 buf
fp = ((unsigned char*)s)-1;
switch(type) { //根据type不同对sdshdr结构体进行赋值,len和alloc设置为initlen
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen); // copy 数据
s[initlen] = '\0';
return s;
}
4. 对SDS的空间进行扩容,当进行字符串追加的时候,需要判断剩余容量是否足够
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
// 剩余容量
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
// 如果当前容量足够,则不需要扩容
if (avail >= addlen) return s;
// 当前字符串的长度
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
// 扩容后的长度
newlen = (len+addlen);
// 如果扩容后的容量小于 1M 则扩大2倍,
if (newlen < SDS_MAX_PREALLOC) // #define SDS_MAX_PREALLOC (1024*1024)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC; // 否则等于当前容量 + 1M
// 获取新容量的结构体类型
type = sdsReqType(newlen);
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
// 根据类型获取结构体大小
hdrlen = sdsHdrSize(type);
// 如果扩容后类型相等则,直接使用s_realloc扩容,内容不变
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
// 如果类型已经改变,就需要使用 s_malloc 申请内存,使用 memcpy 填充数据
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh); // 释放旧内存
s = (char*)newsh+hdrlen;
s[-1] = type; // 设定新的类型
sdssetlen(s, len);
}
sdssetalloc(s, newlen);// 更新容量
return s;
}
5. 字符串连接函数
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
sds sdscatlen(sds s, const void *t, size_t len) {
当前字符串的长度
size_t curlen = sdslen(s);
对容量进行扩容
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
连接字符串
memcpy(s+curlen, t, len);
// 设置连接后的字符串长度
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
SDS 的实现
接下来看下动态字符串(SDS)的实现类,命令的操作都是调用实现类的方法,如set, get 等,SDS 的实现类在 t.string.c 文件中:
1. 字符串的长度检查
static int checkStringLength(client *c, long long size) {
if (size > 512*1024*1024) { // 512M
addReplyError(c,"string exceeds maximum allowed size (512MB)");
return C_ERR;
}
return C_OK;
}
从以上方法可以看到,如果字符串的大小超过 512M,则会抛出异常
当我们调用 SET, SETEX, PSETEX, SETNX 命令的话,会怎么操作的呢?
set 操作
以 SET 为例,看下是如何操作的,分为三步:
(1). 解析命令格式
(2). 设置 value 的编码方式
(3). 入库
1. 解析命令格式
/* SET key value [NX] [XX] [EX <seconds>] [PX <milliseconds>] */
// 解析命令格式
void setCommand(client *c) {
int j;
robj *expire = NULL;
int unit = UNIT_SECONDS;
int flags = OBJ_SET_NO_FLAGS;
// 获取各个各个参数的值
for (j = 3; j < c->argc; j++) {
char *a = c->argv[j]->ptr;
robj *next = (j == c->argc-1) ? NULL : c->argv[j+1];
if ((a[0] == 'n' || a[0] == 'N') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' &&
!(flags & OBJ_SET_XX))
{
flags |= OBJ_SET_NX;
} else if ((a[0] == 'x' || a[0] == 'X') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' &&
!(flags & OBJ_SET_NX))
{
flags |= OBJ_SET_XX;
} else if ((a[0] == 'e' || a[0] == 'E') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' &&
!(flags & OBJ_SET_PX) && next)
{
flags |= OBJ_SET_EX;
unit = UNIT_SECONDS;
expire = next;
j++;
} else if ((a[0] == 'p' || a[0] == 'P') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' &&
!(flags & OBJ_SET_EX) && next)
{
flags |= OBJ_SET_PX;
unit = UNIT_MILLISECONDS;
expire = next;
j++;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
// argv[1] 表示要存储的键,即key
// argv[2] 表示要存储的值,即value
// 对 vaue 设置编码方式
c->argv[2] = tryObjectEncoding(c->argv[2]);
// 入库操作
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}
2. 设置 value 的编码方式
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
// 断言必须为 String 类型,否则不必进行编码
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
//只对raw或embstr 编码的对象尝试一些专门的编码,如果不是 raw或embstr ,直接返回
if (!sdsEncodedObject(o)) return o;
// 如果该对象正在被使用,即引用次数大于1,则不会进行编码,不安全
if (o->refcount > 1) return o;
len = sdslen(s);
// 判断是不是long类型,大于20个字符表示的才是 String
// 如果是long,且String转换为long成功,转为 int 类型
if (len <= 20 && string2l(s,len,&value)) {
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
if (o->encoding == OBJ_ENCODING_RAW) sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT; // int 类型
o->ptr = (void*) value;
return o;
}
}
// 如果字符串的长度小于限制,即44个字符,且它是 raw 编码的话,转换为 embstr 编码
// #define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s)); // 使用 embstr 方式创建字符串
decrRefCount(o);
return emb;
}
// 如果字符串是 raw 编码,且剩余可用空间 > len/10, 则会进行内存空间回收
if (o->encoding == OBJ_ENCODING_RAW &&
sdsavail(s) > len/10)
{
o->ptr = sdsRemoveFreeSpace(o->ptr);
}
return o;
}
3. 入库
void setGenericCommand(client *c, int flags, robj *key, robj *val, robj *expire, int unit, robj *ok_reply, robj *abort_reply) {
long long milliseconds = 0; /* initialized to avoid any harmness warning */
if (expire) {
if (getLongLongFromObjectOrReply(c, expire, &milliseconds, NULL) != C_OK)
return;
if (milliseconds <= 0) {
addReplyErrorFormat(c,"invalid expire time in %s",c->cmd->name);
return;
}
if (unit == UNIT_SECONDS) milliseconds *= 1000;
}
if ((flags & OBJ_SET_NX && lookupKeyWrite(c->db,key) != NULL) ||
(flags & OBJ_SET_XX && lookupKeyWrite(c->db,key) == NULL))
{
addReply(c, abort_reply ? abort_reply : shared.nullbulk);
return;
}
// 入库
setKey(c->db,key,val);
server.dirty++;
// 处理过期时间
if (expire) setExpire(c,c->db,key,mstime()+milliseconds);
notifyKeyspaceEvent(NOTIFY_STRING,"set",key,c->db->id);
if (expire) notifyKeyspaceEvent(NOTIFY_GENERIC,
"expire",key,c->db->id);
// 返回
addReply(c, ok_reply ? ok_reply : shared.ok);
}
get 操作
void getCommand(client *c) {
getGenericCommand(c);
}
int getGenericCommand(client *c) {
robj *o;
// 从数据库中查找
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL)
return C_OK;
// 检查类型
if (o->type != OBJ_STRING) {
addReply(c,shared.wrongtypeerr);
return C_ERR;
} else {
addReplyBulk(c,o);
return C_OK;
}
}
append 操作
void appendCommand(client *c) {
size_t totlen;
robj *o, *append;
// 从数据库中查询对应的 key
o = lookupKeyWrite(c->db,c->argv[1]);
// 如果数据库中没有这个 key ,则会创建一个 key
if (o == NULL) {
// 对 value 设置编码
c->argv[2] = tryObjectEncoding(c->argv[2]);
// 入库
dbAdd(c->db,c->argv[1],c->argv[2]);
incrRefCount(c->argv[2]);
// 设置总长度
totlen = stringObjectLen(c->argv[2]);
} else {
// 如果在数据库中 key 已存在
// 检查类型
if (checkType(c,o,OBJ_STRING))
return;
// 要添加的值
append = c->argv[2];
totlen = stringObjectLen(o)+sdslen(append->ptr);
// 检查总长度是否超过 512M
if (checkStringLength(c,totlen) != C_OK)
return;
// 追加值
o = dbUnshareStringValue(c->db,c->argv[1],o);
o->ptr = sdscatlen(o->ptr,append->ptr,sdslen(append->ptr));
totlen = sdslen(o->ptr);
}
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"append",c->argv[1],c->db->id);
server.dirty++;
addReplyLongLong(c,totlen);
}
以上就是 Redis 的字符串的方式,会根据不同字符串的长度来选择不同的编码方式以达到节约内存的效果。
原文链接:https://my.oschina.net/mengyuankan/blog/1926320
Redis 数据结构-字符串源码分析的更多相关文章
- Redis学习——SDS字符串源码分析
0. 前言 这里对Redis底层字符串的实现分析,但是看完其实现还没有完整的一个概念,即不太清楚作者为什么要这样子设计,只能窥知一点,需要看完redis如何使用再回头来体会,有不足之处还望告知. 涉及 ...
- Redis 内存管理 源码分析
要想了解redis底层的内存管理是如何进行的,直接看源码绝对是一个很好的选择 下面是我添加了详细注释的源码,需要注意的是,为了便于源码分析,我把redis为了弥补平台差异的那部分代码删了,只需要知道有 ...
- Redis网络模型的源码分析
Redis的网络模型是基于I/O多路复用程序来实现的.源码中包含四种多路复用函数库epoll.select.evport.kqueue.在程序编译时会根据系统自动选择这四种库其中之一.下面以epoll ...
- Redis之quicklist源码分析
一.quicklist简介 Redis列表是简单的字符串列表,按照插入顺序排序.你可以添加一个元素到列表的头部(左边)或者尾部(右边). 一个列表最多可以包含 232 - 1 个元素 (4294967 ...
- Redis之ziplist源码分析
一.ziplist简介 从上一篇分析我们知道quicklist的底层存储使用了ziplist(压缩列表),由于压缩列表本身也有不少内容,所以重新开了一篇,在正式源码之前,还是先看下ziplist的特点 ...
- Redis网络库源码分析(1)之介绍篇
一.前言 Redis网络库是一个单线程EPOLL模型的网络库,和Memcached使用的libevent相比,它没有那么庞大,代码一共2000多行,因此比较容易分析.其实网上已经有非常多有关这个网络库 ...
- 第10课:[实战] Redis 网络通信模块源码分析(3)
redis-server 接收到客户端的第一条命令 redis-cli 给 redis-server 发送的第一条数据是 *1\r\n\$7\r\nCOMMAND\r\n .我们来看下对于这条数据如何 ...
- libmxml数据结构(源码分析)
libmxml是一个开源.小巧的C语言xml库.这里简单分析一下它是用什么样的数据结构来保存分析过的xml文档. mxml关键的结构体mxml_node_t是这样的实现的: struct mxml_n ...
- 第09课:【实战】Redis网络通信模块源码分析(2)
侦听 fd 与客户端 fd 是如何挂载到 EPFD 上去的 同样的方式,要把一个 fd 挂载到 EPFD 上去,需要调用系统 API epoll_ctl ,搜索一下这个函数名.在文件 ae_epoll ...
随机推荐
- [SCOI2010]传送带[三分]
//point(AB)->point(CD) 距离满足下凸性,用三分套三分实现 #include<cmath> #include<cstdio> #include< ...
- angular的属性绑定
1. 图片地址属性绑定 html文件 <img [src]="imgUrl"> ts文件 export class ProductComponent implement ...
- CH5301 石子合并【区间dp】
5301 石子合并 0x50「动态规划」例题 描述 设有N堆沙子排成一排,其编号为1,2,3,…,N(N<=300).每堆沙子有一定的数量,可以用一个整数来描述,现在要将这N堆沙子合并成为一堆, ...
- web安全之xss攻击
xss攻击的全称是Cross-Site Scripting (XSS)攻击,是一种注入式攻击.基本的做法是把恶意代码注入到目标网站.由于浏览器在打开目标网站的时候并不知道哪些脚本是恶意的,所以浏览器会 ...
- java WebSocket的实现以及Spring WebSocket
开始学习WebSocket,准备用它来实现一个在页面实时输出log4j的日志以及控制台的日志. 首先知道一些基础信息: java7 开始支持WebSocket,并且只是做了定义,并未实现 tomcat ...
- node.js使用require给flume提交请求
node.js使用require给flume提交请求 - 简书 https://www.jianshu.com/p/02c20e2d011a 玄月府的小妖在debug 关注 2017.04 ...
- How TCP clients and servers communicate using the TCP sockets interface
wTCP客户端和服务器是如何通过TCP套接字接口进行通讯的.服务器距离.负载,网络拥堵. HTTP The Definitive Guide We begin with the web server ...
- 前端开发 - CSS - 上
CSS: 1.css的引入方式 2.基础选择器 3.高级选择器 4.选择器的优先级 5.伪类选择器 6.字体样式 7.文本样式 8.背景 9.盒模型border 10.margin 11.paddin ...
- 【pentaho】【kettle】【Data Integration】试用
要做数据分析,领导让研究一下kettle. 先占个坑. 这里有个3.0的文档: http://wenku.baidu.com/link?url=hvw_cOBIXLXSGvftkGhXQic3CLC7 ...
- 聊聊高并发(三十四)Java内存模型那些事(二)理解CPU快速缓存的工作原理
在上一篇聊聊高并发(三十三)从一致性(Consistency)的角度理解Java内存模型 我们说了Java内存模型是一个语言级别的内存模型抽象.它屏蔽了底层硬件实现内存一致性需求的差异,提供了对上层的 ...