算法导论-矩阵乘法-strassen算法
目录
1、矩阵相乘的朴素算法
2、矩阵相乘的strassen算法
3、完整测试代码c++
4、性能分析
5、参考资料
内容
1、矩阵相乘的朴素算法 T(n) = Θ(n3)
朴素矩阵相乘算法,思想明了,编程实现简单。时间复杂度是Θ(n^3)。伪码如下
for i ← to n
do for j ← to n
do c[i][j] ←
for k ← to n
do c[i][j] ← c[i][j] + a[i][k]⋅ b[k][j]
2、矩阵相乘的strassen算法 T(n)=Θ(nlog7) =Θ (n2.81)
矩阵乘法中采用分治法,第一感觉上应该能够有效的提高算法的效率。如下图所示分治法方案,以及对该算法的效率分析。有图可知,算法效率是Θ(n^3)。算法效率并没有提高。下面介绍下矩阵分治法思想:

鉴于上面的分治法方案无法有效提高算法的效率,要想提高算法效率,由主定理方法可知必须想办法将2中递归式中的系数8减少。Strassen提出了一种将系数减少到7的分治法方案,如下图所示。
效率分析如下:

伪码如下:
Strassen (N,MatrixA,MatrixB,MatrixResult)
//splitting input Matrixes, into 4 submatrices each.
for i <- to N/
for j <- to N/
A11[i][j] <- MatrixA[i][j]; //a矩阵块
A12[i][j] <- MatrixA[i][j + N / ]; //b矩阵块
A21[i][j] <- MatrixA[i + N / ][j]; //c矩阵块
A22[i][j] <- MatrixA[i + N / ][j + N / ];//d矩阵块
B11[i][j] <- MatrixB[i][j]; //e 矩阵块
B12[i][j] <- MatrixB[i][j + N / ]; //f 矩阵块
B21[i][j] <- MatrixB[i + N / ][j]; //g 矩阵块
B22[i][j] <- MatrixB[i + N / ][j + N / ]; //h矩阵块
//here we calculate M1..M7 matrices .
//递归求M1
HalfSize <- N/
AResult <- A11+A22
BResult <- B11+B22
Strassen( HalfSize, AResult, BResult, M1 ); //M1=(A11+A22)*(B11+B22) p5=(a+d)*(e+h)
//递归求M2
AResult <- A21+A22
Strassen(HalfSize, AResult, B11, M2); //M2=(A21+A22)B11 p3=(c+d)*e
//递归求M3
BResult <- B12 - B22
Strassen(HalfSize, A11, BResult, M3); //M3=A11(B12-B22) p1=a*(f-h)
//递归求M4
BResult <- B21 - B11
Strassen(HalfSize, A22, BResult, M4); //M4=A22(B21-B11) p4=d*(g-e)
//递归求M5
AResult <- A11+A12
Strassen(HalfSize, AResult, B22, M5); //M5=(A11+A12)B22 p2=(a+b)*h
//递归求M6
AResult <- A21-A11
BResult <- B11+B12
Strassen( HalfSize, AResult, BResult, M6); //M6=(A21-A11)(B11+B12) p7=(c-a)(e+f)
//递归求M7
AResult <- A12-A22
BResult <- B21+B22
Strassen(HalfSize, AResult, BResult, M7); //M7=(A12-A22)(B21+B22) p6=(b-d)*(g+h)
//计算结果子矩阵
C11 <- M1 + M4 - M5 + M7;
C12 <- M3 + M5;
C21 <- M2 + M4;
C22 <- M1 + M3 - M2 + M6;
//at this point , we have calculated the c11..c22 matrices, and now we are going to
//put them together and make a unit matrix which would describe our resulting Matrix.
for i <- to N/
for j <- to N/
MatrixResult[i][j] <- C11[i][j];
MatrixResult[i][j + N / ] <- C12[i][j];
MatrixResult[i + N / ][j] <- C21[i][j];
MatrixResult[i + N / ][j + N / ] <- C22[i][j];
3、完成测试代码
Strassen.h
#ifndef STRASSEN_HH
#define STRASSEN_HH
template<typename T>
class Strassen_class{
public:
void ADD(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize );
void SUB(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize );
void MUL( T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize );//朴素算法实现
void FillMatrix( T** MatrixA, T** MatrixB, int length);//A,B矩阵赋值
void PrintMatrix(T **MatrixA,int MatrixSize);//打印矩阵
void Strassen(int N, T **MatrixA, T **MatrixB, T **MatrixC);//Strassen算法实现
};
template<typename T>
void Strassen_class<T>::ADD(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize )
{
for ( int i = ; i < MatrixSize; i++)
{
for ( int j = ; j < MatrixSize; j++)
{
MatrixResult[i][j] = MatrixA[i][j] + MatrixB[i][j];
}
}
}
template<typename T>
void Strassen_class<T>::SUB(T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize )
{
for ( int i = ; i < MatrixSize; i++)
{
for ( int j = ; j < MatrixSize; j++)
{
MatrixResult[i][j] = MatrixA[i][j] - MatrixB[i][j];
}
}
}
template<typename T>
void Strassen_class<T>::MUL( T** MatrixA, T** MatrixB, T** MatrixResult, int MatrixSize )
{
for (int i=;i<MatrixSize ;i++)
{
for (int j=;j<MatrixSize ;j++)
{
MatrixResult[i][j]=;
for (int k=;k<MatrixSize ;k++)
{
MatrixResult[i][j]=MatrixResult[i][j]+MatrixA[i][k]*MatrixB[k][j];
}
}
}
} /*
c++使用二维数组,申请动态内存方法
申请
int **A;
A = new int *[desired_array_row];
for ( int i = 0; i < desired_array_row; i++)
A[i] = new int [desired_column_size]; 释放
for ( int i = 0; i < your_array_row; i++)
delete [] A[i];
delete[] A; */
template<typename T>
void Strassen_class<T>::Strassen(int N, T **MatrixA, T **MatrixB, T **MatrixC)
{ int HalfSize = N/;
int newSize = N/; if ( N <= ) //分治门槛,小于这个值时不再进行递归计算,而是采用常规矩阵计算方法
{
MUL(MatrixA,MatrixB,MatrixC,N);
}
else
{
T** A11;
T** A12;
T** A21;
T** A22; T** B11;
T** B12;
T** B21;
T** B22; T** C11;
T** C12;
T** C21;
T** C22; T** M1;
T** M2;
T** M3;
T** M4;
T** M5;
T** M6;
T** M7;
T** AResult;
T** BResult; //making a 1 diminsional pointer based array.
A11 = new T *[newSize];
A12 = new T *[newSize];
A21 = new T *[newSize];
A22 = new T *[newSize]; B11 = new T *[newSize];
B12 = new T *[newSize];
B21 = new T *[newSize];
B22 = new T *[newSize]; C11 = new T *[newSize];
C12 = new T *[newSize];
C21 = new T *[newSize];
C22 = new T *[newSize]; M1 = new T *[newSize];
M2 = new T *[newSize];
M3 = new T *[newSize];
M4 = new T *[newSize];
M5 = new T *[newSize];
M6 = new T *[newSize];
M7 = new T *[newSize]; AResult = new T *[newSize];
BResult = new T *[newSize]; int newLength = newSize; //making that 1 diminsional pointer based array , a 2D pointer based array
for ( int i = ; i < newSize; i++)
{
A11[i] = new T[newLength];
A12[i] = new T[newLength];
A21[i] = new T[newLength];
A22[i] = new T[newLength]; B11[i] = new T[newLength];
B12[i] = new T[newLength];
B21[i] = new T[newLength];
B22[i] = new T[newLength]; C11[i] = new T[newLength];
C12[i] = new T[newLength];
C21[i] = new T[newLength];
C22[i] = new T[newLength]; M1[i] = new T[newLength];
M2[i] = new T[newLength];
M3[i] = new T[newLength];
M4[i] = new T[newLength];
M5[i] = new T[newLength];
M6[i] = new T[newLength];
M7[i] = new T[newLength]; AResult[i] = new T[newLength];
BResult[i] = new T[newLength]; }
//splitting input Matrixes, into 4 submatrices each.
for (int i = ; i < N / ; i++)
{
for (int j = ; j < N / ; j++)
{
A11[i][j] = MatrixA[i][j];
A12[i][j] = MatrixA[i][j + N / ];
A21[i][j] = MatrixA[i + N / ][j];
A22[i][j] = MatrixA[i + N / ][j + N / ]; B11[i][j] = MatrixB[i][j];
B12[i][j] = MatrixB[i][j + N / ];
B21[i][j] = MatrixB[i + N / ][j];
B22[i][j] = MatrixB[i + N / ][j + N / ]; }
} //here we calculate M1..M7 matrices .
//M1[][]
ADD( A11,A22,AResult, HalfSize);
ADD( B11,B22,BResult, HalfSize); //p5=(a+d)*(e+h)
Strassen( HalfSize, AResult, BResult, M1 ); //now that we need to multiply this , we use the strassen itself . //M2[][]
ADD( A21,A22,AResult, HalfSize); //M2=(A21+A22)B11 p3=(c+d)*e
Strassen(HalfSize, AResult, B11, M2); //Mul(AResult,B11,M2); //M3[][]
SUB( B12,B22,BResult, HalfSize); //M3=A11(B12-B22) p1=a*(f-h)
Strassen(HalfSize, A11, BResult, M3); //Mul(A11,BResult,M3); //M4[][]
SUB( B21, B11, BResult, HalfSize); //M4=A22(B21-B11) p4=d*(g-e)
Strassen(HalfSize, A22, BResult, M4); //Mul(A22,BResult,M4); //M5[][]
ADD( A11, A12, AResult, HalfSize); //M5=(A11+A12)B22 p2=(a+b)*h
Strassen(HalfSize, AResult, B22, M5); //Mul(AResult,B22,M5); //M6[][]
SUB( A21, A11, AResult, HalfSize);
ADD( B11, B12, BResult, HalfSize); //M6=(A21-A11)(B11+B12) p7=(c-a)(e+f)
Strassen( HalfSize, AResult, BResult, M6); //Mul(AResult,BResult,M6); //M7[][]
SUB(A12, A22, AResult, HalfSize);
ADD(B21, B22, BResult, HalfSize); //M7=(A12-A22)(B21+B22) p6=(b-d)*(g+h)
Strassen(HalfSize, AResult, BResult, M7); //Mul(AResult,BResult,M7); //C11 = M1 + M4 - M5 + M7;
ADD( M1, M4, AResult, HalfSize);
SUB( M7, M5, BResult, HalfSize);
ADD( AResult, BResult, C11, HalfSize); //C12 = M3 + M5;
ADD( M3, M5, C12, HalfSize); //C21 = M2 + M4;
ADD( M2, M4, C21, HalfSize); //C22 = M1 + M3 - M2 + M6;
ADD( M1, M3, AResult, HalfSize);
SUB( M6, M2, BResult, HalfSize);
ADD( AResult, BResult, C22, HalfSize); //at this point , we have calculated the c11..c22 matrices, and now we are going to
//put them together and make a unit matrix which would describe our resulting Matrix.
//组合小矩阵到一个大矩阵
for (int i = ; i < N/ ; i++)
{
for (int j = ; j < N/ ; j++)
{
MatrixC[i][j] = C11[i][j];
MatrixC[i][j + N / ] = C12[i][j];
MatrixC[i + N / ][j] = C21[i][j];
MatrixC[i + N / ][j + N / ] = C22[i][j];
}
} // 释放矩阵内存空间
for (int i = ; i < newLength; i++)
{
delete[] A11[i];delete[] A12[i];delete[] A21[i];
delete[] A22[i]; delete[] B11[i];delete[] B12[i];delete[] B21[i];
delete[] B22[i];
delete[] C11[i];delete[] C12[i];delete[] C21[i];
delete[] C22[i];
delete[] M1[i];delete[] M2[i];delete[] M3[i];delete[] M4[i];
delete[] M5[i];delete[] M6[i];delete[] M7[i];
delete[] AResult[i];delete[] BResult[i] ;
}
delete[] A11;delete[] A12;delete[] A21;delete[] A22;
delete[] B11;delete[] B12;delete[] B21;delete[] B22;
delete[] C11;delete[] C12;delete[] C21;delete[] C22;
delete[] M1;delete[] M2;delete[] M3;delete[] M4;delete[] M5;
delete[] M6;delete[] M7;
delete[] AResult;
delete[] BResult ; }//end of else } template<typename T>
void Strassen_class<T>::FillMatrix( T** MatrixA, T** MatrixB, int length)
{
for(int row = ; row<length; row++)
{
for(int column = ; column<length; column++)
{ MatrixB[row][column] = (MatrixA[row][column] = rand() %);
//matrix2[row][column] = rand() % 2;//ba hazfe in khat 50% afzayeshe soorat khahim dasht
} }
}
template<typename T>
void Strassen_class<T>::PrintMatrix(T **MatrixA,int MatrixSize)
{
cout<<endl;
for(int row = ; row<MatrixSize; row++)
{
for(int column = ; column<MatrixSize; column++)
{ cout<<MatrixA[row][column]<<"\t";
if ((column+)%((MatrixSize)) == )
cout<<endl;
} }
cout<<endl;
}
#endif
Strassen.h
Strassen.cpp
#include <iostream>
#include <ctime>
#include <Windows.h>
using namespace std;
#include "Strassen.h" int main()
{
Strassen_class<int> stra;//定义Strassen_class类对象
int MatrixSize = ; int** MatrixA; //存放矩阵A
int** MatrixB; //存放矩阵B
int** MatrixC; //存放结果矩阵 clock_t startTime_For_Normal_Multipilication ;
clock_t endTime_For_Normal_Multipilication ; clock_t startTime_For_Strassen ;
clock_t endTime_For_Strassen ;
srand(time()); cout<<"\n请输入矩阵大小(必须是2的幂指数值(例如:32,64,512,..): ";
cin>>MatrixSize; int N = MatrixSize;//for readiblity. //申请内存
MatrixA = new int *[MatrixSize];
MatrixB = new int *[MatrixSize];
MatrixC = new int *[MatrixSize]; for (int i = ; i < MatrixSize; i++)
{
MatrixA[i] = new int [MatrixSize];
MatrixB[i] = new int [MatrixSize];
MatrixC[i] = new int [MatrixSize];
} stra.FillMatrix(MatrixA,MatrixB,MatrixSize); //矩阵赋值 //*******************conventional multiplication test
cout<<"朴素矩阵算法开始时钟: "<< (startTime_For_Normal_Multipilication = clock()); stra.MUL(MatrixA,MatrixB,MatrixC,MatrixSize);//朴素矩阵相乘算法 T(n) = O(n^3) cout<<"\n朴素矩阵算法结束时钟: "<< (endTime_For_Normal_Multipilication = clock()); cout<<"\n矩阵运算结果... \n";
stra.PrintMatrix(MatrixC,MatrixSize); //*******************Strassen multiplication test
cout<<"\nStrassen算法开始时钟: "<< (startTime_For_Strassen = clock()); stra.Strassen( N, MatrixA, MatrixB, MatrixC ); //strassen矩阵相乘算法 cout<<"\nStrassen算法结束时钟: "<<(endTime_For_Strassen = clock()); cout<<"\n矩阵运算结果... \n";
stra.PrintMatrix(MatrixC,MatrixSize); cout<<"矩阵大小 "<<MatrixSize;
cout<<"\n朴素矩阵算法: "<<(endTime_For_Normal_Multipilication - startTime_For_Normal_Multipilication)<<" Clocks.."<<(endTime_For_Normal_Multipilication - startTime_For_Normal_Multipilication)/CLOCKS_PER_SEC<<" Sec";
cout<<"\nStrassen算法:"<<(endTime_For_Strassen - startTime_For_Strassen)<<" Clocks.."<<(endTime_For_Strassen - startTime_For_Strassen)/CLOCKS_PER_SEC<<" Sec\n";
system("Pause");
return ; }
输出:
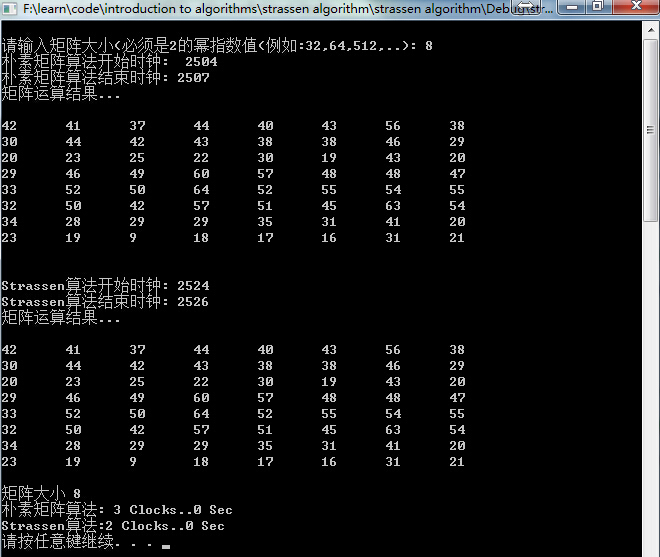
4、性能分析
| 矩阵大小 | 朴素矩阵算法(秒) | Strassen算法(秒) |
| 32 | 0.003 | 0.003 |
| 64 | 0.004 | 0.004 |
| 128 | 0.021 | 0.071 |
| 256 | 0.09 | 0.854 |
| 512 | 0.782 | 6.408 |
| 1024 | 8.908 | 52.391 |
可以发现:可以看到使用Strassen算法时,耗时不但没有减少,反而剧烈增多,在n=512时计算时间就无法忍受,效果没有朴素矩阵算法好。网上查阅资料,现罗列如下:
1)采用Strassen算法作递归运算,需要创建大量的动态二维数组,其中分配堆内存空间将占用大量计算时间,从而掩盖了Strassen算法的优势
2)于是对Strassen算法做出改进,设定一个界限。当n<界限时,使用普通法计算矩阵,而不继续分治递归。需要合理设置界限,不同环境(硬件配置)下界限不同
3)矩阵乘法一般意义上还是选择的是朴素的方法,只有当矩阵变稠密,而且矩阵的阶数很大时,才会考虑使用Strassen算法。
分析原因:(网上总结的说法)
http://blog.csdn.net/handawnc/article/details/7987107
仔细研究后发现,采用Strassen算法作递归运算,需要创建大量的动态二维数组,其中分配堆内存空间将占用大量计算时间,从而掩盖了Strassen算法的优势。于是对Strassen算法做出改进,设定一个界限。当n<界限时,使用普通法计算矩阵,而不继续分治递归。
改进后算法优势明显,就算时间大幅下降。之后,针对不同大小的界限进行试验。在初步试验中发现,当数据规模小于1000时,下界S法的差别不大,规模大于1000以后,n取值越大,消耗时间下降。最优的界限值在32~128之间。
因为计算机每次运算时的系统环境不同(CPU占用、内存占用等),所以计算出的时间会有一定浮动。虽然这样,试验结果已经能得出结论Strassen算法比常规法优势明显。使用下界法改进后,在分治效率和动态分配内存间取舍,针对不同的数据规模稍加试验可以得到一个最优的界限。
http://www.cppblog.com/sosi/archive/2010/08/30/125259.html
时间复杂度就马上降下来了。。但是不要过于乐观。
从实用的观点看,Strassen算法通常不是矩阵乘法所选择的方法:
1 在Strassen算法的运行时间中,隐含的常数因子比简单的O(n^3)方法常数因子大
2 当矩阵是稀疏的时候,为稀疏矩阵设计的算法更快
3 Strassen算法不像简单方法那样子具有数值稳定性
4 在递归层次中生成的子矩阵要消耗空间。
所以矩阵乘法一般意义上还是选择的是朴素的方法,只有当矩阵变稠密,而且矩阵的阶数>20左右,才会考虑使用Strassen算法。
5、参考资料
【1】http://blog.csdn.net/xyd0512/article/details/8220506
【2】http://blog.csdn.net/zhuangxiaobin/article/details/36476769
【3】http://blog.csdn.net/handawnc/article/details/7987107
【4】http://www.xuebuyuan.com/552410.html
【5】http://blog.csdn.net/chenhq1991/article/details/7599824
算法导论-矩阵乘法-strassen算法的更多相关文章
- 算法笔记_081:蓝桥杯练习 算法提高 矩阵乘法(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 有n个矩阵,大小分别为a0*a1, a1*a2, a2*a3, ..., a[n-1]*a[n],现要将它们依次相乘,只能使用结合率,求最 ...
- 蓝桥 ADV-232 算法提高 矩阵乘法 【区间DP】
算法提高 矩阵乘法 时间限制:3.0s 内存限制:256.0MB 问题描述 有n个矩阵,大小分别为a0*a1, a1*a2, a2*a3, ..., a[n-1]*a[n],现要 ...
- Java实现 蓝桥杯 算法提高 矩阵乘法(暴力)
试题 算法提高 矩阵乘法 问题描述 小明最近刚刚学习了矩阵乘法,但是他计算的速度太慢,于是他希望你能帮他写一个矩阵乘法的运算器. 输入格式 输入的第一行包含三个正整数N,M,K,表示一个NM的矩阵乘以 ...
- Java实现 蓝桥杯 算法训练 矩阵乘法
算法训练 矩阵乘法 时间限制:1.0s 内存限制:512.0MB 提交此题 问题描述 输入两个矩阵,分别是ms,sn大小.输出两个矩阵相乘的结果. 输入格式 第一行,空格隔开的三个正整数m,s,n(均 ...
- 算法提高 矩阵乘法 区间DP
这是神题,n <= 1000,如果是极限数据普通的n^3区间DP怎么可能过?可偏偏就过了. 刘汝佳大哥的训练指南上面说的存在nlgn的算法解决矩阵链乘问题,可是百度都找不到.... AC代码 # ...
- java 蓝桥杯算法提高 矩阵乘法
思路:根据提示的内容,我们可以得到c[i][j] += a[i][k]*b[k][j],k>=0&&k<s PS:这道题本身不难,但是当我定义A[m][s] B[s][n] ...
- MPI编程——分块矩阵乘法(cannon算法)
https://blog.csdn.net/a429367172/article/details/88933877
- 基于visual Studio2013解决算法导论之008快速排序算法
题目 快速排序 解决代码及点评 #include <stdio.h> #include <stdlib.h> #include <malloc.h> #in ...
- 【算法导论C++代码】Strassen算法
简单方阵矩乘法 SQUARE-MATRIX-MULTIPLY(A,B) n = A.rows let C be a new n*n natrix to n to n cij = to n cij=ci ...
随机推荐
- Java 中的值传递和引用传递问题
Java 中的值传递和引用传递问题 public class Operation { int data = 50; void change(int data) { data = data + 100; ...
- Java(静态)变量、(静态)代码块、构造方法的执行顺序
Java(静态)变量.(静态)代码块.构造方法的执行顺序 总结 1.父类静态变量和静态代码块(先声明的先执行); 2.子类静态变量和静态代码块(先声明的先执行); 3.父类的变量和代码块(先声明的先执 ...
- idea导入或者检出项目时发现编辑器左侧无法显示项目目录结构
按下列步骤操作: 1. 关闭IDEA, 2.然后删除项目文件夹下的.idea文件夹 3.重新用IDEA工具打开项目
- poj2078 Matrix(DFS)
题目链接 http://poj.org/problem?id=2078 题意 输入一个n×n的矩阵,可以对矩阵的每行进行任意次的循环右移操作,行的每一次右移后,计算矩阵中每一列的和的最大值,输出这些最 ...
- 图形管线之旅 Part6
原文:<A trip through the Graphics Pipeline 2011> 翻译:往昔之剑 转载请注明出处 欢迎回来.这次我们去看看三角形的光栅化.但在光栅化三角 ...
- 利用gmpy2破解rsa
gmpy2的相关文档: https://gmpy2.readthedocs.io/en/latest/ ================ 题目: 来自实验吧的rsarsa:http://www.shi ...
- shell 文件传 参数
n cross-platform, lowest-common-denominator sh you use: #!/bin/sh value=`cat config.txt` echo " ...
- 【转】全面了解Mysql中的事务
为什么要有事务? 事务广泛的运用于订单系统.银行系统等多种场景.如果有以下一个场景:A用户和B用户是银行的储户.现在A要给B转账500元.那么需要做以下几件事: 1. 检查A的账户余额>500元 ...
- JMS介绍:我对JMS的理解和认识
[ZT]JMS介绍:我对JMS的理解和认识 转自:http://blog.csdn.net/KimmKing/archive/2011/06/30/6577021.aspx,感谢作者KimmKing ...
- android remoteView
韩梦飞沙 韩亚飞 313134555@qq.com yue31313 han_meng_fei_sha remoteView 可以在 appWidget 和 notification 中 使 ...