mapper.xml文件
1. 概述
mybatis的真正强大在于它的映射语句。由于它的异常强大,映射器的XML文件就显得相对简单,如果拿它跟具有相同功能的JDBC代码进行对比,省掉将近95%的代码。mybatis是针对SQL构建的,并且比普通方法做的更好。
SQL映射文件有几个顶级元素(按照它们被定义的顺序):
- select:查询
- cache-ref:其他命名空间缓存配置的引用
- resultMap:是最复杂也是最强大的元素,用来描述如果和数据库结果集中加载对象
- parameterMap:已经废弃
- sql:可被其他语句引用的可重用语句块
- insert:插入
- update:更新
- delete:删除
- cache:给定命名空间的缓存配置
2. select
查询语句是mybatis中最常用的元素之一,多数应用也都是查询比修改要频繁。
<select id="selectPerson" parameterType="int" resultType="hashmap">
SELECT * FROM PERSON WHERE ID = #{id}
</select>
这个语句被称作selectPerson,接受一个int类型的参数,并返回一个HashMap类型的对象,其中的key是列名,value是结果行中的对应值。
#{id}
这个高速mybatis创建一个预处理语句参数,通过JDBC,这样一个参数在SQL中会由一个?来标识,并被传递到一个新的预处理语句中,就像:
String selectPerson = "SELECT * FROM PERSON WHERE ID=?";
PreparedStatement ps = conn.prepareStatement(selectPerson);
ps.setInt(1,id);
当然,这需要很多单独的JDBC的代码来提取结果并将它们映射到对象实例中,这就是mybatis节省时间的地方。
select元素有很多属性允许配置:
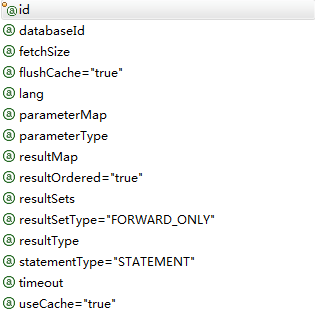
| 属性 | 描述 |
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句 |
| parameterType | 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为mybatis可以通过TypeHandler推断出具体传入语句的参数,默认值为unset。 |
| parameterMap | 已废弃 |
| resultType | 从这条语句中返回的期望类型的类的完全限定名或别名。注意如果是集合情形,那应该是集合可以包含的类型,而不能是集合本身。使用resultType或resultMap,但不能同时使用。 |
| resultMap | 外部resultMap的命名引用。 |
| flushCache | true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:false |
| useCache | true,导致本条语句的结果被二级缓存,默认值:对select元素为true |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为unset(依赖驱动) |
| fetchSize | 这是尝试影响驱动程序每次批量返回的结果行数和这个设置值相等。默认值为unset(依赖驱动) |
| statementType | STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
| resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE 或 SCROLL_INSENSITIVE 中的一个,默认值为 unset (依赖驱动)。 |
| databaseId | 如果配置了 databaseIdProvider,MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。 |
| resultOrdered | 这个设置仅针对嵌套结果 select 语句适用:如果为 true,就是假设包含了嵌套结果集或是分组了,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false。 |
| resultSets | 这个设置仅对多结果集的情况适用,它将列出语句执行后返回的结果集并每个结果集给一个名称,名称是逗号分隔的。 |
3. insert,update,delete
insert
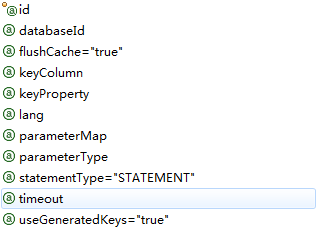
update
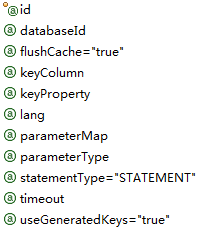
delete
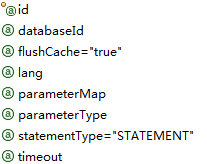
相同属性的与select意义都是相同的,可以参考上面,下面只介绍不同的几个:
| 属性 | 描述 |
| keyColumn | (仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像 PostgreSQL)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| keyProperty | (仅对 insert 和 update 有用)唯一标记一个属性,MyBatis 会通过 getGeneratedKeys 的返回值或者通过 insert 语句的 selectKey 子元素设置它的键值,默认:unset。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| useGeneratedKeys | (仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。 |
在插入语句里面有一些额外的属性和子元素用来处理主键的生成,而且有多种生成方法。
首先,数据库支持自动生成主键的字段(mysql和sql Server),那么可以设置useGeneratedKeys=true,然后再把keyProperty设置到目标属性上就OK了。例如,author表堆id使用了自动生成的列类型,那么:
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
insert into user(user_name, birthday) values(#{user_name},#{birthday})
</insert>
如果数据库还支持多行插入,也可以传入一个author数组或集合,并返回自动生成的主键。
<insert id="insertManyUser">
insert into user(user_name, birthday) values
<foreach collection="list" item="item" separator="," >
(#{item.user_name}, #{item.birthday})
</foreach>
</insert>
4. sql
这个元素可以被用来定义可重用的SQL代码段,可以包含在其他语句中。它可以被静态地(在加载参数)参数化,不同的属性值通过包含的实例变化。
<sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql>
<select id="selectUsers" resultType="map">
select
<include refid="userColumns"><property name="alias" value="t1"/></include>,
<include refid="userColumns"><property name="alias" value="t2"/></include>
from some_table t1
cross join some_table t2
</select>
5. 参数
前面的所有语句中都是简单参数的例子,实际上参数是mybatis非常强大的元素,对于简单的做法,大概90%的情况参数都很少。
默认情况下,使用#{ }格式的语法会导致mybatis创建PreparedStatement参数并安全地设置参数,这样做更安全,更迅速,通常也是首选做法,不过有时你就是想直接在SQL语句中插入一个不转义的字符串,比如,像order by,可以这样:
ORDER BY ${columnName}
这里mybatis不会修改或转义字符串。
注意:用这种方式接受用户的输入,并将其用于语句中的参数是不安全的,会导致潜在的SQL注入攻击,因此要么不允许用户输入这些字段,要么自行转义并检验。
6. resultMap
6.1 基本用法
resultMap元素是mybatis中最重要最强大的元素,它可以让你从90%的JDBC ResultSets数据提取代码中解放出来。ResultMap的设计思想是,简单的语句不需要明确的结果映射,而复杂一点的语句只需要描述它们的关系就行了。
<select id="selectUserById" resultType="map">
select * from user where id = #{id}
</select>
上述语句只是简单地将所有的列映射到HashMap的key上,这由resultType属性指定。虽然在大部分情况下都够用,但是HashMap不是一个很好的领域模型。可以使用JavaBean或POJO(Plain Old Java Objects,普通Java对象)作为领域模型。
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private int id;
private String n;
private Date birthday;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getN() {
return n;
}
public void setUser_name(String user_name) {
this.n = user_name;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + n + ", birthday=" + birthday + "]";
}
}
<select id="selectUserById" resultType="org.mybatis.mapper.User">
select * from user where id = #{id}
</select>
这样一个JavaBean可以被映射到ResultSet,就像映射到HashMap一样简单。
mybatis会在幕后自动创建一个ResultMap,在基于属性名来映射列到JavaBean属性上。如果列名和属性名没有精确匹配,可以在Select语句中对列使用别名(这是SQL特性)。
下面的实例使用外部的resultMap,这也是解决列名不匹配的另外一种方式:
<resultMap type="org.mybatis.mapper.User" id="UserMap">
<id column="id" property="id"/>
<result column="user_name" property="n"/>
<result column="birthday" property="birthday"/>
</resultMap> <select id="selectUserById" resultMap="UserMap">
select * from user where id = #{id}
</select>
引用语句使用resultMap属性就行了(去掉了resultType属性)。
6.2 高级结果映射
有如下表结构:user,role,user_role
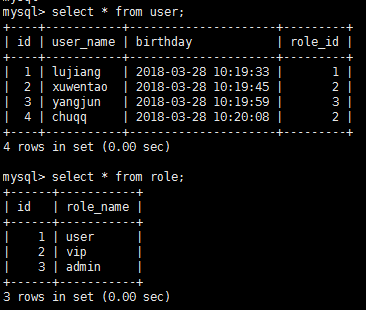
6.2.1 id & result
id和result都讲一个列的值映射到一个简单数据类型(字符串,整型,双精度浮点数,日期等)的属性或字段。
这两者之间的唯一不同是,id标示的结果将是对象的标示属性,这会在比较对象实例时用到。
两个元素都有一些属性:
| 属性 | 描述 |
| property | 映射到列结果的字段或属性。如果用来匹配的 JavaBeans 存在给定名字的属性,那么它将会被使用。否则 MyBatis 将会寻找给定名称 property 的字段。 无论是哪一种情形,你都可以使用通常的点式分隔形式进行复杂属性导航。比如,你可以这样映射一些简单的东西: “username” ,或者映射到一些复杂的东西: “address.street.number” 。 |
| column | 数据库中的列名,或者是列的别名。一般情况下,这和 传递给 resultSet.getString(columnName) 方法的参数一样。 |
| javaType | 一个 Java 类的完全限定名,或一个类型别名(参考上面内建类型别名 的列表) 。如果你映射到一个 JavaBean,MyBatis 通常可以断定类型。 然而,如果你映射到的是 HashMap,那么你应该明确地指定 javaType 来保证期望的行为。 |
| jdbcType | JDBC 类型,所支持的 JDBC 类型参见这个表格之后的“支持的 JDBC 类型”。 只需要在可能执行插入、更新和删除的允许空值的列上指定 JDBC 类型。这是 JDBC 的要求而非 MyBatis 的要求。如果你直接面向 JDBC 编程,你需要对可能为 null 的值指定这个类型。 |
| typeHandler | 我们在前面讨论过的默认类型处理器。使用这个属性,你可以覆盖默认的类型处理器。这个属性值是一个类型处理 器实现类的完全限定名,或者是类型别名。 |
6.2.2 构造方法(constructor)
通过吸怪对象属性的方式,可以满足大多数的数据传输对象以及大部分领域模型的要求。但有些情况下你想使用不可变类。通常来说,很少或基本不变的、包含引用或查询数据的表,很适合使用不可变类。构造方法注入允许你在初始化时设置属性的值,而不用暴露公共方法。mybatis也支持私有属性和私有javabean属性来达到这个目的,但有些人更青睐于构造方法注入。
public User(int id, String name, Date birthday) {
this.id = id;
this.name = name;
this.birthday = birthday;
}
为了将结果注入构造方法,mybatis需要通过某种方法定位相应的构造方法。在下面的例子中,mybatis搜索一个声明了三个形参的构造方法,以int,String和Date的顺序排列。(可以通过添加name属性,不按照顺序排列)
<constructor>
<idArg column="id" javaType="int"/>
<arg column="name" javaType="String"/>
<arg column="birthday" javaType="Date"/>
</constructor>
6.2.3 关联(association)
关联关系处理“有一个”类型的关系。比如,一个用户有一个角色。
关联中需要告诉mybatis如何加载关联数据。mybatis提供了2种不同的方式:
- 嵌套查询:通过执行另外一个SQL映射语句来返回预期的复杂类型;
- 嵌套结果:使用嵌套结果映射来处理重复的联合结果的子集。
(1)关联的嵌套查询
查询User信息,包括角色信息。
<resultMap type="org.mybatis.mapper.User" id="UserMap">
<id column="id" property="id" />
<result column="user_name" property="name"/>
<result column="birthday" property="birthday"/>
<association property="role" column="role_id" select="selectRoleById"/>
</resultMap> <select id="selectUserById" resultMap="UserMap">
select * from user where id = #{id}
</select> <select id="selectRoleById" resultType="org.mybatis.mapper.Role">
select * from role where id = #{id}
</select>
| 属性 | 描述 |
| column | 来自数据库的列名,或重命名的列标签。这和通常传递给 resultSet.getString(columnName)方法的字符串是相同的。 column 注 意 : 要 处 理 复 合 主 键 , 你 可 以 指 定 多 个 列 名 通 过 column= ” {prop1=col1,prop2=col2} ” 这种语法来传递给嵌套查询语 句。这会引起 prop1 和 prop2 以参数对象形式来设置给目标嵌套查询语句。 |
| select | 另外一个映射语句的ID,可以加载这个属性映射需要的复杂类型。获取的在列属性中指定的列的值将被传递给目标select语句作为参数。表格后面有一个详细的示例。select注意 : 要处理复合主键,你可以指定多个列名通过 column= ” {prop1=col1,prop2=col2} ” 这种语法来传递给嵌套查询语句。这会引起prop1和prop2以参数对象形式来设置给目标嵌套查询语句。 |
| fetchType | 可选的。有效值为 lazy和eager。 如果使用了,它将取代全局配置参数lazyLoadingEnabled。 |
嵌套查询这种方式简单,但是对于大型数据集合和列表性能不好。会有“N + 1”问题:
- 执行了一个单独的SQL语句来获取结果列表(1)
- 对返回的每条记录,又执行了一个查询语句来为每个加载细节(N)
这个问题会导致成百上千的SQL语句被执行。
(2)关联嵌套结果
查询用户信息和角色信息:
<select id="selectUserAndRole" resultMap="userAndRoleMap">
select u.id, u.user_name,u.birthday,u.role_id, r.id,r.role_name from user u left join role r on u.role_id = r.id where u.id = #{id}
</select> <resultMap type="org.mybatis.mapper.User" id="userAndRoleMap">
<id property="id" column="id"/>
<result property="name" column="user_name"/>
<result property="birthday" column="birthday"/>
<association property="role" column="role_id" javaType="org.mybatis.mapper.Role">
<id property="id" column="id"/>
<result property="name" column="role_name"/>
</association>
</resultMap>
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private int id;
private String name;
private Date birthday;
private Role role;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
public Role getRole() {
return role;
}
public void setRole(Role role) {
this.role = role;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", birthday=" + birthday + ", role=" + role + "]";
}
}
6.2.4 集合(collection)
上面已经处理了“有一个”类型关联,但是“有很多”是怎样的?与关联是很相似的。
继续上面的实例,一个用户有一个角色,但是一个角色有多个用户。在角色类中,可以增加
private List<User> users;
要映射嵌套结果集合到List中,我们使用集合元素。就像关联元素一样,可以从连接中使用嵌套查询或嵌套结果。
(1)集合的嵌套查询
查询某个角色和所有用户
<select id="selectRole" resultMap="roleResult">
select * from role where id = #{id}
</select>
<resultMap type="org.mybatis.mapper.Role" id="roleResult">
<id property="id" column="id" />
<result property="name" column="role_name" />
<collection property="users" javaType="list" column="id"
ofType="org.mybatis.mapper.Usesr" select="selectUserByRoleId" />
</resultMap>
<select id="selectUserByRoleId" resultType="org.mybatis.mapper.User">
select * from user where role_id = #{id}
</select>
运行及结果:
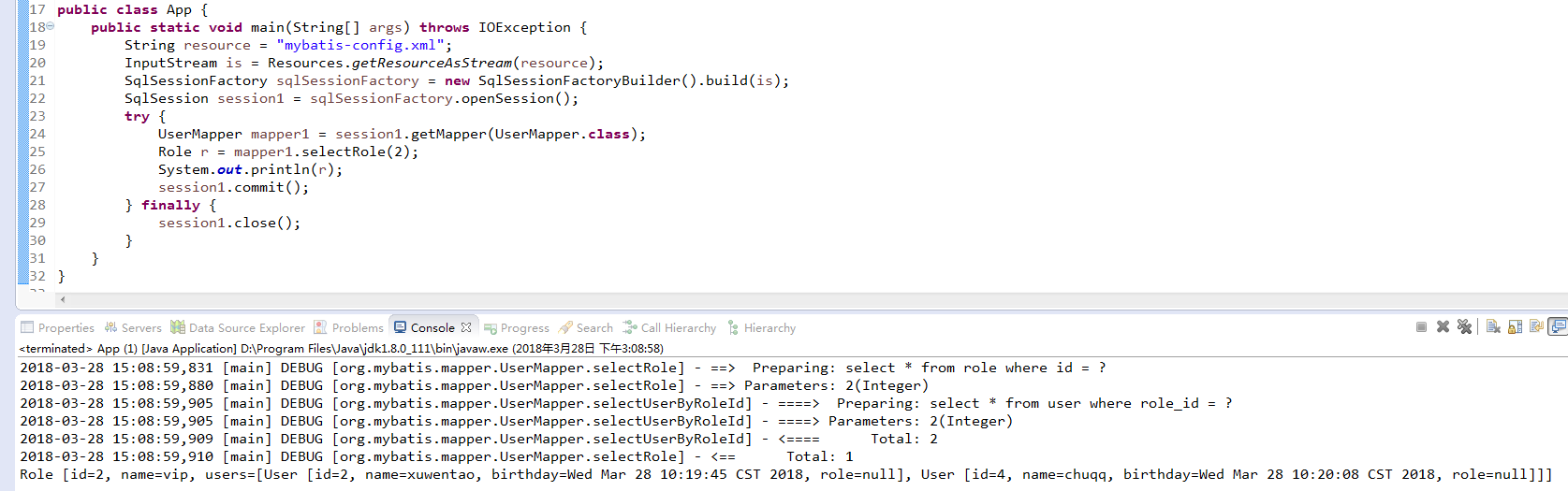
(2)集合的嵌套结果
如果两表联查,主表和明细表的主键都是id的话,明细表的多条只能查询出来第一条?
级联查询的时候,主表和从表有一样的字段名的时候,在mysql上命令查询是没问题的。但在mybatis中主从表需要为相同字段名设置别名。设置了别名就OK了。
<select id="selectRoleAndUsers" resultMap="roleAndUsers">
select r.id, r.role_name, u.id as uid, u.user_name, u.birthday from role r left outer join user u on r.id = u.role_id where r.id = #{id}
</select> <resultMap type="org.mybatis.mapper.Role" id="roleAndUsers">
<id property="id" column="id"/>
<result property="name" column="role_name"/>
<collection property="users" ofType="org.mybatis.mapper.User" javaType="list">
<id property="id" column="uid"/>
<result property="name" column="user_name"/>
<result property="birthday" column="birthday"/>
</collection>
</resultMap>
6.2.5 鉴别器(discriminator)
鉴别器在于确定使用那个ResultMap来映射SQL查询语句,在实现中我们往往有一个基类,然后可以派生一些类。比如我们要选择一群人可以用List<Person>,然而Person里面有个性别sex,根据它还可以分为Male或者Female。鉴别器就要根据sex决定用Male还是用Female相关的Mapper进行映射。
7. 自动映射
当自动映射查询结果时,mybatis会获取sql返回的列名并在Java类中查找相同名字的属性(忽略大小写)。这意味着如果mybatis发现了ID列和id属性,mybatis会将ID的值赋给id。
通常数据库列使用大写单词命名,单词间用下划线分隔;而Java属性一般遵循驼峰命名法。为了在这两种命名方式之间启动自动映射,需要将mapUnderscoreToCamelCase设置为true。
自动映射甚至在特定的result map下也能工作。在这种情况下,对于每一个result map,所有的ResultSet提供的列, 如果没有被手工映射,则将被自动映射。自动映射处理完毕后手工映射才会被处理。
有是那种自动映射等级:
NONE:禁用自动映射,仅设置手动映射属性;
PARTIAL:将自动映射结果除了那些有内部定义内嵌结果映射的;
FULL:自动映射所有。
8. 缓存
默认情况下是没有开启缓存的,除了局部session一级缓存。要开启二级缓存,你需要在你的SQL映射文件中添加一行:
<cache/>
字面上看就是这样。这个简单语句的效果如下:
- 映射语句文件中的所有 select 语句将会被缓存。
- 映射语句文件中的所有 insert,update 和 delete 语句会刷新缓存。
- 缓存会使用 Least Recently Used(LRU,最近最少使用的)算法来收回。
- 根据时间表(比如 no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序 来刷新。
- 缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。
- 缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而 且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
所有的这些属性都可以通过缓存元素的属性来修改。比如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会 导致冲突。
可用的收回策略有:
- LRU – 最近最少使用的:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
- WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
默认的是 LRU。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒 形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的 可用内存资源数目。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓 存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存 会返回缓存对象的拷贝(通过序列化) 。这会慢一些,但是安全,因此默认是 false。
参照缓存
也许将来的某个时候,想在命名空间中共享相同的缓存配置和实例。在这样的情况下可以使用cache-ref元素来引用另外一个缓存:
<cache-ref namespace="xxx"/>
9. 动态SQL
9.1 if
动态SQL通常要做的事情是根据条件包含where子句的一部分,比如:
<select id="queryUser" resultType="org.mybatis.mapper.User" parameterType="int">
select * from user
<if test="id != null">
where id = #{id}
</if>
</select>
注:有可能出现如下错误https://blog.csdn.net/aitcax/article/details/44337271
9.2 choose,when,otherwise
有时我们不想应用到所有的条件语句,而只想从中择其一项。针对这种情况,MyBatis提供了choose元素,它有点像Java中的switch语句。
实例:如果提供id就通过id查询,如果id未提供name提供则按照name查询,如果两个都不提供,则查询所有。
<select id="queryUser" resultType="org.mybatis.mapper.User">
select * from user
<choose>
<when test="id != null">
where id = #{id}
</when> <when test="name != null">
where user_name = #{name}
</when> <otherwise></otherwise>
</choose>
</select>
9.3 where,set
看下面的语句:每个分支里面都要写where。
<select id="queryUser" resultType="org.mybatis.mapper.User">
select * from user
<choose>
<when test="id != null">
where id = #{id}
</when> <when test="name != null">
where user_name = #{name}
</when> <otherwise></otherwise>
</choose>
</select>
可以改写为:
<select id="queryUser" resultType="org.mybatis.mapper.User">
select * from user
<where>
<choose>
<when test="id != null">
id = #{id}
</when> <when test="name != null">
user_name = #{name}
</when> <otherwise></otherwise>
</choose>
</where>
</select>
<where>元素只会在至少有一个子元素的条件返回SQL子句的情况下才去插入“Where”子句,而且,若语句的开头为“and”或“or”,where元素会将他们去除。
类似的用于动态更新语句的解决方案叫做set。set元素可以用于动态包含需要更新的列,而舍去其他的。比如:
<update id="updateUser">
update user
<set>
<if test="id != null"> id = #{id},</if>
<if test="name != null"> user_name = #{name},</if>
</set>
</update>
这里,set元素会动态前置SET关键字,同时也会删掉无关的逗号,因为用了条件语句之后很可能就会在生成的 SQL语句的后面留下这些逗号。(译者注:因为用的是“if”元素,若最后一个“if”没有匹配上而前面的匹配上,SQL语句的最后就会有一个逗号遗留)
9.4 foreach
动态 SQL 的另外一个常用的操作需求是对一个集合进行遍历,通常是在构建 IN 条件语句的时候。比如:
<select id="queryUser" resultType="org.mybatis.mapper.User">
select * from user
where id in
<foreach collection="list" item ="item" open="(" close=")" separator=",">
#{item}
</foreach>
</select>
foreach元素,允许指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。也允许你指定开头(open)语结尾(close)的字符串,以及在迭代结果之间放置分隔符(separator)。
注:可以迭代对象有list,set,map,数组等。当使用可迭代对象或数组时,index是当前迭代的次数,item是本次迭代获取的元素。当时用map时,index是key,item是value。
9.5 bind
bind元素可以从OGNL表达式中创建一个变量并将其绑定到上下文。比如:
<select id="queryUser" resultType="org.mybatis.mapper.User">
<bind name="uid" value="2"/>
select * from user where id = #{uid}
</select>
x. 参考资料
https://blog.csdn.net/ykzhen2015/article/details/51249963
http://www.mybatis.org/mybatis-3/zh/sqlmap-xml.html#Auto-mapping
https://blog.csdn.net/aitcax/article/details/44337271
mapper.xml文件的更多相关文章
- MyBatis Mapper.xml文件中 $和#的区别
MyBatis Mapper.xml文件中 $和#的区别 网上有很多,总之,简略的写一下,作为备忘.例子中假设参数名为 paramName,类型为 VARCHAR . 1.优先使用#{paramN ...
- Java数据持久层框架 MyBatis之API学习六(Mapper XML 文件详解)
对于MyBatis的学习而言,最好去MyBatis的官方文档:http://www.mybatis.org/mybatis-3/zh/index.html 对于语言的学习而言,马上上手去编程,多多练习 ...
- Java数据持久层框架 MyBatis之API学习五(Mapper XML 文件)
对于MyBatis的学习而言,最好去MyBatis的官方文档:http://www.mybatis.org/mybatis-3/zh/index.html 对于语言的学习而言,马上上手去编程,多多练习 ...
- maven项目打包的时候,*Mapper.xml 文件会打不不进去解决办法
打包的时候,不同版本的 Eclipse 还有IDEA 会有打包打不进去Mapper.xml 文件,这个时候要加如下代码, 在<build> 标签内加入即可 <resources> ...
- idea找不到package下的mapper.xml文件
由于开发人员使用不同的开发工具,导致eclipse的开发人员将mapper.xml文件习惯性的放到package下,以便查看,而eclipse编译时,不会忽略package下的xml以及dtl文件,所 ...
- 【MyBatis】Mapper XML 文件
Mapper XML文件 MyBatis 的真正强大在于它的映射语句,也是它的魔力所在.由于它的异常强大,映射器的 XML 文件就显得相对简单.如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立 ...
- 启动项目时,mapper.xml文件没有导入
原因分析:绑定的statement没有发现,原因是只有mapper接口的java文件,没有xml文件 解决方法:需要在pom文件中进行配置 <!-- 如果不添加此节点mybatis的mapper ...
- mybatis mapper xml文件的导入方式和查询方式
mybatis mapper xml文件的导入方式和查询方式 ssm框架 Mybatis mapper与SQLSession的关系 每个基于MyBatis的应用都是以一个SqlSessionFact ...
- maven工程中防止mapper.xml文件被漏掉、未加载的方法
maven工程中防止mapper.xml文件被漏掉.未加载的方法 就是在pom.xml文件中添加以下内容 <!-- 如果不添加此节点mybatis的mapper.xml文件都会被漏掉. --&g ...
- maven 结合mybaits整合框架,打包时mapper.xml文件,mapper目录打不进war包去问题
首先,来看下MAVENx项目标准的目录结构: 一般情况下,我们用到的资源文件(各种xml,properites,xsd文件等)都放在src/main/resources下面,利用maven打包时,ma ...
随机推荐
- Linux系统/etc/sysconfig目录下没有iptables文件
在新安装的linux系统中,防火墙默认是被禁掉的,一般也没有配置过任何防火墙的策略,所有不存在/etc/sysconfig/iptables文件. 解决办法: 1.键入以下命令,新建文件 2.复制以下 ...
- gridview展开嵌套显示
最近实在是太忙了,好几个月没有更新博客了,近来项目需要用到GRIDVIEW嵌套的,在这里跟大家分享一下,大家如有更好的解决方案,请不吝贴出.在ASP.NET中,GridView嵌套可以显示当前选定的父 ...
- 三大UML建模工具Visio、Rational Rose、PowerDesign
UML建模工具Visio .Rational Rose.PowerDesign的比较 应用最广的由两种种1. Rational Rose,它是ibm的 .2.Microsoft的 Microsoft ...
- JS的数组相关知识
创建数组方法一: var a1=new Array(5); console.log(a1.length); console.log(a1); //[] ,数组是空的 var a2=new Array( ...
- javascript配置ckfinder的路径
<script type="text/javascript" src="ckfinder/ckfinder.js"></script> ...
- ArcGIS Server 10中的切图/缓存机制深入【转】
http://blog.newnaw.com/?p=789 两年前我写过一篇关于ArcGIS地图切图/缓存原理的文章,<ArcGIS Server的切图原理深入>,里面以tiling sc ...
- 从项目上一个子查询扩展学习开来:mysql的查询、子查询及连接查询
上面这样的数据,想要的结果是:如果matchResult为2的话,代表是黑名单.同一个softId,version,pcInfoId的代表是同一个软件,需要去重:同时,如果相同软件里面只要有一个mat ...
- ci框架(二)
自定义SQL语句 当提供的API满足不了我们对S ...
- 使用MapReduce实现二度人脉搜索算法
一,背景介绍 在新浪微博.人人网等社交网站上,为了使用户在网络上认识更多的朋友,社交网站往往提供类似“你可能感兴趣的人”.“间接关注推荐”等好友推荐的功能,其中就包含了二度人脉算法. 二,算法实现 原 ...
- 聊聊jvm的PermGen与Metaspace
转载:https://segmentfault.com/a/1190000012577387 序 本文主要讲述一下jvm的PermGen与Metaspace java memory结构 分代概念 对于 ...