solr 高亮显示
官网:https://lucene.apache.org/solr/guide/6_6/highlighting.html#Highlighting-TheUnifiedHighlighter
前言
solr的高亮允许匹配用户查询的文档的片段包含在查询响应中返回,高亮包含在返回结果的单独部分(highlighting部分).
solr提供了一个高亮工具的集合,这个工具允许控制大量字段的片段,片段的大小和片段的格式.高亮工具还可以被多种请求处理程序(Request Handler)调用,如DisMax,Extend DisMax,和标准查询解析器.
这里有四种种可以使用的高亮实现:
Unified Highlighter :这是最灵活和最具选择性的选项,它支持最常见的突出显示参数,并且可以准确地处理任何查询,甚至是SpanQueries(例如从环绕解析器中可以看到)。 这种方式的的强大优势在于,
您可以选择配置Solr以将更多信息放入底层索引中,以加速突出显示大型文档; 即使在每个字段的基础上,也支持多种配置。 其他方式几乎没有这种灵活性
Original Highlighter:这个Original Highlighter是高亮的一个典型.它拥有三个高亮的最复杂的和最细粒度的查询表示法.比如,高亮能够提供精确的匹配,甚至用于如surround这样的查询解析器。
它不要求任何的特殊的数据结果如termVectors.对于一个宽泛种类的搜索情况,这是一个很好的选择.
FastVector Highlighter:FastVector Highlighter要求字段的term vector选项(termVectors,termPositions,termOffsets).并考虑到是最优化的,对于多语言环境它往往比standard highlighter会更好的工作。
因为它支持Unicode breakiterators(分解迭代).另一方面,它的查询表示没有standard highlighter那么高级.例如,它将不会很好的工作于surround解析器.它经常使用于大文档和多种类语言的高亮文本.
Postings Highlighter:Postings Highlighter要求存储storeOffsetsWithPositions(位置偏移量),需要在字段中配置.这是一个比vectors更简单有效的结果,但是不适合于大数量的查询terms。
像FastVector Highlighter,它支持Unicode算法来分割文档.另一方面,它有很粗略的查询表示:它注重于摘要的质量,完全忽略查询的结构,仅仅基于查询term和统计排序.
Original Highlighter
标准高亮不要求任何特别的参数加载字段之上.尽管如此,你可以选择的对每个高亮字段打开termVectors,termPositions和termOffsets.这可以避免在查询时通过分析链(analysis chain)运行文档,可以使更快高亮.
标准高亮参数,这些参数可以定义在高亮搜索组件中,在request handler中指定默认参数.或者通过query传递给request handler.
1、hl :默认为空白(不高亮).为true时,开启高亮功能,为false或者空白或者缺少时,关闭高亮功能.
2、hl.fl:默认空白,指定高亮字段列表.多个字段之间以逗号或空格分开.如果为空白,对于StandardRequestHandler,高亮默认搜索字段(或者指定的df参数).对于DisMaxRequestHandler,qf作为默认的。
"*"可以用于匹配全局,如"text_*"或者"*",当使用"*"时,hl.requireFieldMatch=true必填.
3、hl.snippets : 默认为1.指定每个字段生成的高亮字段的最大数量.
4、hl.fragsize : 每个snippet返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回。
5、hl.mergeContiguous : 默认为false. 知识solr将邻近相连的片段合并为一个单独的片段.true表示合并.默认值为false,为向后兼容设置.
6、hl.requireFieldMatch: 默认为fasle. 如果置为true,除非该字段的查询结果不为空才会被高亮。它的默认值是false,意味 着它可能匹配某个字段却高亮一个不同的字段。如果hl.fl使用了通配符,那么就要启用该参数。
尽管如此,如果你的查询是all字段(可能是使用 copy-field 指令),那么还是把它设为false,这样搜索结果能表明哪个字段的查询文本未被找到
7、hl.maxAnalyzedChars: 默认51200. 会搜索高亮的最大字符,默认值为51200,如果你想禁用,设为-1
8、hl.maxMultiValuedToExamine: 默认integer.MAX_VALUE.在停止之前,指定检查的多值字段的最大条木数.在任何匹配没有找到之前,如果达到限制,可能会返回0个结果.
9、 hl.maxMultiValuedToMatch: 默认integer.MAX_VALUE.在停止之前,指定在多值字段中找到的最大匹配数.如果hl.maxMultiValuedToExamine也已经定义了,首先达到的限制将决定何时停止查找。
10、 hl.alternateField: 默认blank.如果没有生成snippet(没有terms 匹配),那么使用另一个字段值作为返回。
11、hl.maxAlternateFieldLength :默认 unlimited.如果hl.alternateField启用,则有时需要制定alternateField的最大字符长度,默认0是即没有限制。所以合理的值是应该为
hl.snippets * hl.fragsize这样返回结果的大小就能保持一致。
12、hl.formatter :默认 simple.一个提供可替换的formatting算法的扩展点。默认值是simple,这是目前仅有的选项。显然这不够用,你可 以看看org.apache.solr.highlight.HtmlFormatter.java 和
solrconfig.xml中highlighting元素是如何配置的。 注意在不论原文中被高亮了什么值的情况下,如预先已存在的em tags,也不会被转义,所以在有时会导致假的高亮。
13、hl.simple.pre hl.simple.post : 默认<em> and </em> .
14、hl.fragmenter : 默认gap.这个是solr制定fragment算法的扩展点。gap是默认值。regex是另一种选项,这种选项指明 highlight的边界由一个正则表达式确 定。这是一种非典型 的高级选项。
为了知道默认设置和fragmenters (and formatters)是如何配置的,可以看看solrconfig.xml中的highlight段。
15、 hl.usePhraseHighlighter :默认true.如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮
16、hl.highlightMultiTerm : 默认true.如果设置为true,solr将会高亮出现在多terms查询中的短语。
17、 hl.regex.slop:默认0.6.在使用hl.fragmenter=regex时,意思是如果hl.fragsize=100那么fragment的大小会从40-160.
18、hl.regex.pattern: 默认空白.为fragmenting指定正则表达式.这个可以用作提取句子。
19、 hl.regex.maxAnalyzedChars:默认10000. 搜索高亮的最大字符,对一个大字段使用一个复杂的正则表达式是非常昂贵的。
20、 hl.preserveMulti :默认false.如果为true,多值字段将会按照它们在索引中顺序返回所有的值.如果false,只有匹配高亮请求的值返回。
FastVector Highlighter
FastVectorHighlighter是一个基于TermVector的高亮工具.在很多情况中,它提供了比标准高亮更高的性能.要使用FastVectorHighlighter,需要设置hl.useFastVectorHighlighter参数为true.
必须对每个高亮字段打开termVectors,termPositions,termOffsets.最后你需要使用一个界限扫描器来阻止FastVectorHighlighter截取你得terms.在大多数例子中,使用breakIterator边界
扫描器将会给出一个更精确的结果.参考Using Boundary Scanners with the Fast Vector Highlighter获取更多的详细信息。
FastVector 高亮参数大部分重复了standard highlighter的参数.这些参数可以在高亮搜索组件中定义.作为指定request handler的默认参数.或者使用查询query传递给request handler。
hl.useFastVectorHighligter:默认false. true:开启FastVector Highlighter.
Using Boundary Scanners with the Fast Vector Highlighter
和Fast Vector Highlighter 一起使用边界扫描器.
这个 Fast vector highlight 偶尔会截短高亮词语.为了防止这种情况,在solrconfig.xml中实现一个边界扫描器.然后使用hl.boundaryScanner参数来指定高亮使用的边界扫描器.
solr支持两种边界扫描器:breakIterator和simple.
1、 breakIterator
界扫描器提供出色的性能,一开始就考虑本地和边界类型在内.在多数例子中使用breakIterator边界扫描器.为了实现这个breakIterator边界扫描器,将下面代码加入到solrconfig.xml文件中的highlighting部分.
调整类型,语言,国家:
- <boundaryScanner name="breakIterator"
- class="solr.highlight.BreakIteratorBoundaryScanner">
- <lst name="defaults">
- <str name="hl.bs.type">WORD</str>
- <str name="hl.bs.language">en</str>
- <str name="hl.bs.country">US</str>
- </lst>
- </boundaryScanner>
hl.bs.type参数的可能值是:WORD, LINE, SENTENCE, 和 CHARACTER。
2、simple
simple边界扫描器通过一个指定的最大字符数值(hl.bs.maxScan)和常用的分隔符(hl.bs.chars)来 扫描term边界.
- <boundaryScanner name="simple"
- class="solr.highlight.SimpleBoundaryScanner" default="true">
- <lst name="defaults">
- <str name="hl.bs.maxScan">10</str>
- <str name="hl.bs.chars">.,!?\t\n</str>
- </lst>
- </boundaryScanner>
Postings Highlighter
PostingsHighlighter比较关注好的文档摘要和效率,但是没有其他高亮工具灵活.它使用比价少的硬盘空间,专注好的文档摘要,提供一个高性能方法,如果相对于每页结果数查询有一个较低的terms数。
但是,缺点就是它不是一个匹配debugger的查询,it does not allow broken analysis chains。
要使用这个高亮,必须打开字段的storeOffsetsWithPositions参数,不需要打开字段的termVectors,termPositions,termOffsets.因为这个高亮器不使用term向量。
例子测试
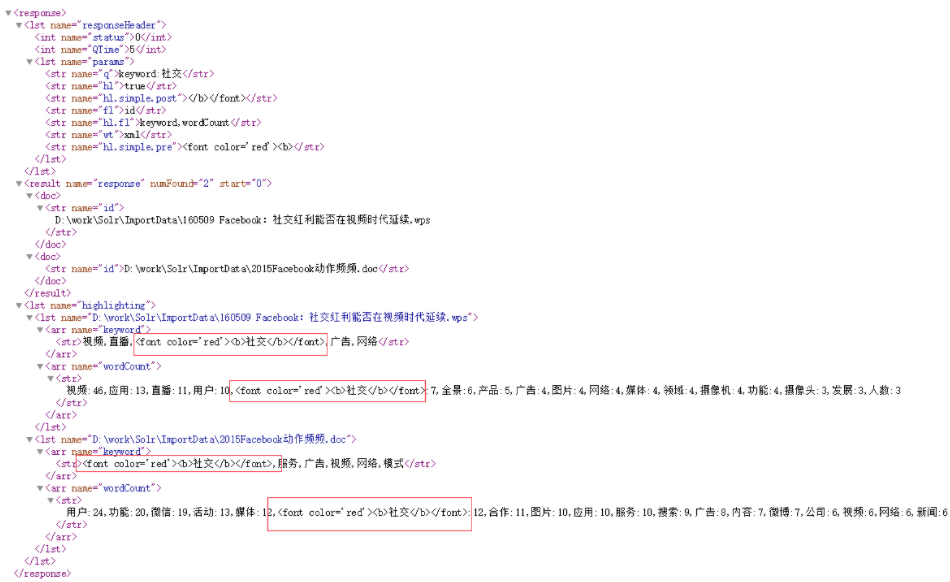
例子:http://localhost:8983/solr/test/select?hl=true&q=keyword:社交&wt=xml&hl.fl=keyword,wordCount&fl=id&hl.simple.pre=<font color='red'><b>&hl.simple.post=</b></font>
1、hl = true : 开启高亮,要高亮显示,首先设置为true
2、hl.fl=keyword,wordCount: 高亮字段,这是要进行高亮显示的字段
3、hl.simple.pre = <font color='red'><b> : 高亮单词的前缀标记,红色粗体
4、hl.simple.post=</b></font>: 高亮单词的后缀标记
查询结果:
java实现代码
- package main.java;
- import org.apache.solr.client.solrj.SolrClient;
- import org.apache.solr.client.solrj.SolrQuery;
- import org.apache.solr.client.solrj.SolrServerException;
- import org.apache.solr.client.solrj.impl.HttpSolrClient;
- import org.apache.solr.client.solrj.response.QueryResponse;
- import java.io.IOException;
- import java.util.*;
- /**
- * @Author:sks
- * @Description:
- * @Date:Created in 17:03 2018/2/1
- * @Modified by:
- **/
- public class highlight {
- public static void main(String[] args) throws SolrServerException,IOException {
- String urlString = "http://localhost:8983/solr/test";
- Init(urlString);
- getHighlightData();
- }
- private static SolrClient solr;
- /**
- * @Author:sks
- * @Description:初始化solr客户端
- * @Date:
- */
- public static void Init(String urlString){
- solr = new HttpSolrClient.Builder(urlString).build();
- }
- public static void getHighlightData() throws SolrServerException,IOException {
- SolrQuery params = new SolrQuery();
- //设置高亮
- params.setQuery("keyword:社交");
- params.setFields("id");
- //开启高亮设置
- params.setHighlight(true);
- //params.setParam("hl.mergeContiguous","true");
- params.setParam("hl.method","original");
- //params.setParam("hl.method","fastVector");
- //params.setParam("hl.useFastVectorHighligter","true");
- //params.setParam("hl.method","unified");
- //红色粗体显示
- //标签前缀
- params.setHighlightSimplePre("<font color='red'><b>");
- //标签后缀
- params.setHighlightSimplePost("</b></font>");
- //params.addHighlightField("text");
- //高亮字段
- params.addHighlightField("keyword");
- //高亮字段
- params.addHighlightField("wordCount");
- /**
- * @Fragsize: 参数是摘要信息的长度。默认值是100,这个长度是出现关键字的位置向前移6个字符,再往后100个字符,如果为0,那么该字段不会被fragmented且整个字段的值会被返回
- * @Snippets: 参数是返回高亮摘要的段数,因为我们的文本一般都比较长,含有搜索关键字的地方有多处,如果hl.snippets的值大于1的话
- * 会返回多个摘要信息,即文本中含有关键字的几段话,默认值为1,返回含关键字最多的一段描述。solr会对多个段进行排序
- */
- params.setHighlightSnippets(4);
- params.setHighlightFragsize(0);//如果为0,那么该字段不会被fragmented且整个字段的值会被返回
- QueryResponse response = solr.query(params);
- //高亮集合
- Map<String, Map<String, List<String>>> results = response.getHighlighting();
- Set<String> keys = results.keySet();
- Map<String, List<String>> innermap ;
- Set<String> innerkeys ;
- List<String> list ;
- for(String key:keys){
- System.out.println("id = " +key);
- innermap = results.get( key);
- innerkeys = innermap.keySet();
- for(String innerKey:innerkeys){
- list = innermap.get(innerKey);
- for (String kk:list){
- System.out.println(innerKey +" = "+kk);
- }
- }
- System.out.println("\n");
- }
- }
- }
输出结果

参考:http://www.cnblogs.com/a198720/p/4344231.html
solr 高亮显示的更多相关文章
- Solr高亮显示highlight的三种实现
高亮显示在搜索中使用的比较多,比较常用的有三种使用方式,如果要对某field做高亮显示,必须对该field设置stored=true 第一种是普通的高亮显示Highlighter,根据查询的 ...
- 10.solr学习速成之高亮显示
Solr高亮显示的三种实现 高亮显示在搜索中使用的比较多,比较常用的有三种使用方式,如果要对某field做高亮显示,必须对该field设置stored=true . 第一种是普通的高 ...
- Solr分组查询
项目中需要实时的返回一下统计的东西,因此就要进行分组,在获取一些东西,代码拿不出来,因此分享一篇,还是很使用的. facet搜索 /** * * 搜索功能优化-关键词搜索 * 搜索范围:商品名称.店 ...
- Solr.NET快速入门(三)【高亮显示】
此功能会"高亮显示"匹配查询的字词(通常使用标记),包括匹配字词周围的文字片段. 要启用高亮显示,请包括HighlightingParameters QueryOptions对象, ...
- spring data solr 搜索关键字高亮显示
spring data solr 搜索关键字高亮显示 public Map<String, Object> highSearch(Map searchMap) { Map map = ne ...
- 跨域请求获取Solr json检索结果并高亮显示
Solr提供了json格式的检索结果,然而在跨域的情况下如何调用呢?我们可以利用jquery提供的jsonp的方式获取Solr检索结果. <script type="text/java ...
- 使用spring data solr 实现搜索关键字高亮显示
后端实现: @Service public class ItemSearchServiceImpl implements ItemSearchService { @Autowired private ...
- solr 查询 实例分析
solr索引查询接口:http://localhost:8080/solr/query 首先了解一下查询参数的含义. q Solr 中用来搜索的查询.可以通过追加一个分号和已索引且未进行断词的字段(下 ...
- solr使用语法笔记
http://127.0.0.1:8095/shangbiao_sale/select?sort=id+desc&fq=&wt=json&json.nl=map&q=s ...
随机推荐
- 部署Nginx
部署Nginx #下载nginx wget http://nginx.org/download/nginx-1.12.2.tar.gz#安装依赖 yum install pcre-devel open ...
- Sort List——经典(链表中的归并排序)
Sort a linked list in O(n log n) time using constant space complexity. 对一个链表进行排序,且时间复杂度要求为 O(n lo ...
- “无法在web服务器上启动调试,不是Debugger User组成员..."
在使用VS.net2003开发asp.net项目时,有时候在你调试项目时,会提示”无法在web服务器上启动调试,不是Debugger User组成员..."这样一个错误信息.很是让人头疼,一 ...
- Oracle SQL中实现indexOf和lastIndexOf功能
Oracle SQL中实现indexOf和lastIndexOf功能 https://www.2cto.com/database/201305/210470.html
- NOIP模拟2017.6.11解题报告
T1: 水题: 代码: #include <cstdio> #include <iostream> #include <algorithm> using names ...
- Ljava/lang/Iterable与AbstractMethodError
java.lang.AbstractMethodError: com.example.demo.repository.UserRepositoryImpl.findAll()Ljava/lang/It ...
- Markdown 表情包
- mysql 如何给root用户设置密码
用root 进入mysql后mysql>set password =password('你的密码');mysql>flush privileges;
- 17-7-24-react入门
先说明下为什么说好每天一更,周五周六周日都没有更新.因为在周五的时候,上司主动找我谈了转正后的工资4-4.5K.本来想好是6K的,后来打听了一圈公司的小伙伴,都是5-5.5,我就把自己定到了5K.万万 ...
- SPOJ11469 Subset(折半枚举)
题意 给定一个集合,有多少个非空子集,能划分成和相等的两份.\(n\leq 20\) 题解 看到这个题,首先能想到的是\(3^n\)的暴力枚举,枚举当前元素是放入左边还是放入右边或者根本不放,但是显然 ...