Scala学习笔记(一)编程基础
强烈推荐参考该课程:http://www.runoob.com/scala/scala-tutorial.html
1. Scala概述
1.1. 什么是Scala
Scala是一种多范式的编程语言,其设计的初衷是要集成面向对象编程和函数式编程的各种特性。Scala运行于Java平台(Java虚拟机),并兼容现有的Java程序。
1.2. 为什么要学Scala
1.优雅:这是框架设计师第一个要考虑的问题,框架的用户是应用开发程序员,API是否优雅直接影响用户体验。
2.速度快:Scala语言表达能力强,一行代码抵得上Java多行,开发速度快;Scala是静态编译的,所以和JRuby,Groovy比起来速度会快很多。
3.能融合到Hadoop生态圈:Hadoop现在是大数据事实标准,Spark并不是要取代Hadoop,而是要完善Hadoop生态。JVM语言大部分可能会想到Java,但Java做出来的API太丑,或者想实现一个优雅的API太费劲。
2. Scala编译器安装
2.1. 安装JDK
因为Scala是运行在JVM平台上的,所以安装Scala之前要安装JDK。
2.2. 安装Scala
2.2.1. Windows安装Scala编译器
访问Scala官网http://www.scala-lang.org/下载Scala编译器安装包,下载scala-2.12.2.msi后点击下一步就可以了。
2.2.2. Linux安装Scala编译器
下载Scala地址http://downloads.typesafe.com/scala/2.12.2/scala-2.12.2.tgz,然后解压Scala到指定目录。
tar -zxvf scala-2.12..tgz -C /usr/java
配置环境变量,将scala加入到PATH中。
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1..0_45
export PATH=$PATH:$JAVA_HOME/bin:/usr/java/scala-2.12./bin
2.2.3. Scala开发工具安装
目前Scala的开发工具主要有两种:Eclipse和IDEA,这两个开发工具都有相应的Scala插件,如果使用Eclipse,直接到Scala官网下载即可http://scala-ide.org/download/sdk.html。
由于IDEA的Scala插件更优秀,大多数Scala程序员都选择IDEA,可以到http://www.jetbrains.com/idea/download/下载社区免费版,点击下一步安装即可,安装时如果有网络可以选择在线安装Scala插件。这里我们使用离线安装Scala插件:
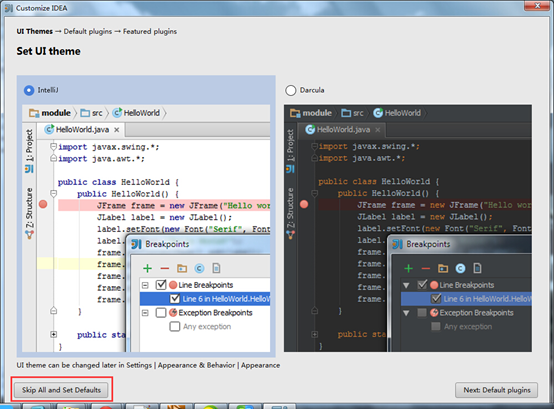
1.安装IDEA,点击下一步即可。由于我们离线安装插件,所以点击Skip All and Set Defaul
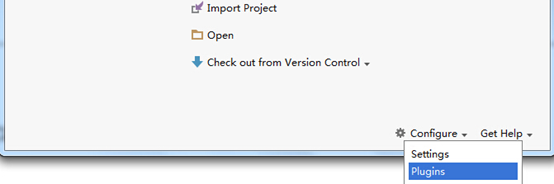
2.下载IEDA的scala插件,地址http://plugins.jetbrains.com/?idea_ce
3.安装Scala插件:Configure -> Plugins -> Install plugin from disk -> 选择Scala插件 -> OK -> 重启IDEA

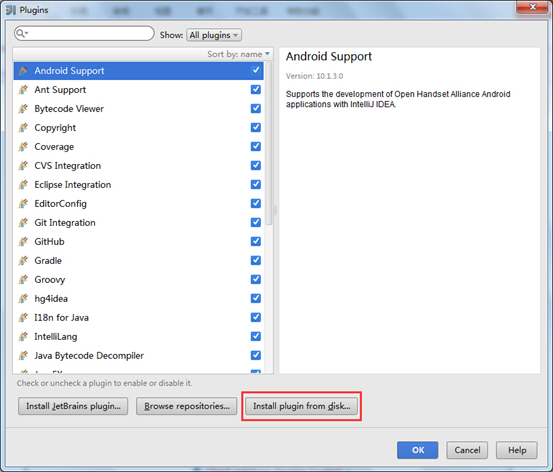
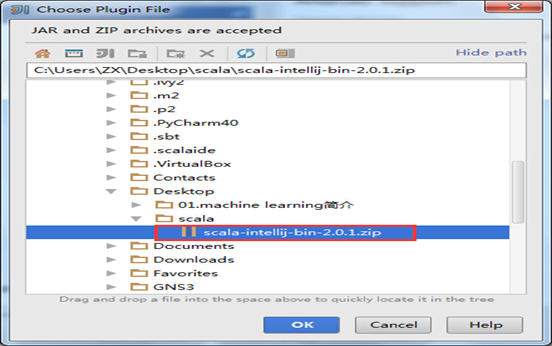
这里下载插件,一定要对应好scala版本,否则报错。建议参考:http://blog.csdn.net/a2011480169/article/details/52712421
3. Scala基础
3.1. 声明变量
package cn.itcast.scala
object VariableDemo {
def main(args: Array[String]) {
//使用val定义的变量值是不可变的,相当于java里用final修饰的变量
val i = 1
//使用var定义的变量是可变得,在Scala中鼓励使用val
var s = "hello"
//Scala编译器会自动推断变量的类型,必要的时候可以指定类型
//变量名在前,类型在后
val str: String = "itcast"
}
}
3.2. 常用类型
Scala和Java一样,有7种数值类型Byte、Char、Short、Int、Long、Float和Double(无包装类型)和一个Boolean类型
3.3. 条件表达式
Scala的的条件表达式比较简洁,例如:
package cn.itcast.scala
object ConditionDemo {
def main(args: Array[String]) {
val x = 1
//判断x的值,将结果赋给y
val y = if (x > 0) 1 else -1
//打印y的值
println(y) //支持混合类型表达式
val z = if (x > 1) 1 else "error"
//打印z的值
println(z) //如果缺失else,相当于if (x > 2) 1 else ()
val m = if (x > 2) 1
println(m) //在scala中每个表达式都有值,scala中有个Unit类,写做(),相当于Java中的void
val n = if (x > 2) 1 else ()
println(n) //if和else if
val k = if (x < 0) 0
else if (x >= 1) 1 else -1
println(k)
}
}
3.4. 块表达式
package cn.itcast.scala
object BlockExpressionDemo {
def main(args: Array[String]) {
val x = 0
//在scala中{}中课包含一系列表达式,块中最后一个表达式的值就是块的值
//下面就是一个块表达式
val result = {
if (x < 0){
-1
} else if(x >= 1) {
1
} else {
"error"
}
}
//result的值就是块表达式的结果
println(result)
}
}
3.5. 循环
在scala中有for循环和while循环,用for循环比较多
for循环语法结构:for (i <- 表达式/数组/集合)
package cn.itcast.scala
object ForDemo {
def main(args: Array[String]) {
//for(i <- 表达式),表达式1 to 10返回一个Range(区间)
//每次循环将区间中的一个值赋给i
for (i <- 1 to 10)
println(i)
//for(i <- 数组)
val arr = Array("a", "b", "c")
for (i <- arr)
println(i)
//to是含首含尾,until是含首不含尾
for (i <- (0 until arr.length))
println(arr(i))
//高级for循环
//每个生成器都可以带一个条件,注意:if前面没有分号
for(i <- 1 to 3; j <- 1 to 3 if i != j)
print((10 * i + j) + " ")
println()
//for推导式:如果for循环的循环体以yield开始,则该循环会构建出一个集合
//每次迭代生成集合中的一个值
val v = for (i <- 1 to 10) yield i * 10
println(v)
}
}
3.6. 调用方法和函数
Scala中的+ - * / %等操作符的作用与Java一样,位操作符 & | ^ >> <<也一样。只是有
一点特别的:这些操作符实际上是方法。例如:
a + b
是如下方法调用的简写:
a.+(b)
a 方法 b可以写成 a.方法(b)
3.7. 定义方法和函数
3.7.1. 定义方法

方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归函数,必须指定返回类型。
3.7.2. 定义函数
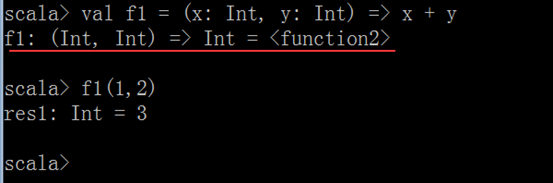
两种写法:
Val func1 = (x:Int, y:Double) => (y, x)
Val func2 = (Int, Double) => (Double, Int) = {
(a, b)=>(b, a)
}
3.7.3. 方法和函数的区别
在函数式编程语言中,函数是“头等公民”,它可以像任何其他数据类型一样被传递和操作。
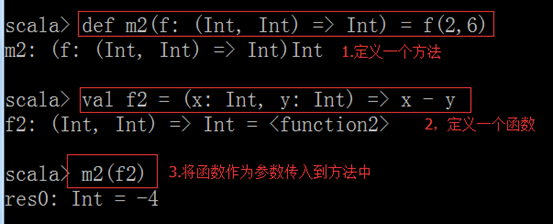
案例:首先定义一个方法,再定义一个函数,然后将函数传递到方法里面。
package cn.itcast.scala
object MethodAndFunctionDemo {
//定义一个方法
//方法m2参数要求是一个函数,函数的参数必须是两个Int类型
//返回值类型也是Int类型
def m1(f: (Int, Int) => Int) : Int = {
f(2, 6)
}
//定义一个函数f1,参数是两个Int类型,返回值是一个Int类型
val f1 = (x: Int, y: Int) => x + y
//再定义一个函数f2
val f2 = (m: Int, n: Int) => m * n
//main方法
def main(args: Array[String]) {
//调用m1方法,并传入f1函数
val r1 = m1(f1)
println(r1)
//调用m1方法,并传入f2函数
val r2 = m1(f2)
println(r2)
}
}
3.7.4. 将方法转换成函数(神奇的下划线)

4. 数组、映射、元组、集合
4.1. 数组
4.1.1. 定长数组和变长数组
package cn.itcast.scala
import scala.collection.mutable.ArrayBuffer
object ArrayDemo {
def main(args: Array[String]) {
//初始化一个长度为8的定长数组,其所有元素均为0
val arr1 = new Array[Int](8)
//直接打印定长数组,内容为数组的hashcode值
println(arr1) //将数组转换成数组缓冲,就可以看到原数组中的内容了
//toBuffer会将数组转换长数组缓冲
println(arr1.toBuffer) //注意:如果不用new,相当于调用了数组的apply方法,直接为数组赋值
//初始化一个长度为1的定长数组
val arr2 = Array[Int](10)
println(arr2.toBuffer) //定义一个长度为3的定长数组
val arr3 = Array("hadoop", "storm", "spark")
//使用()来访问元素
println(arr3(2)) //变长数组(数组缓冲)
//如果想使用数组缓冲,需要导入import scala.collection.mutable.ArrayBuffer包
val ab = ArrayBuffer[Int]()
//向数组缓冲的尾部追加一个元素
//+=尾部追加元素
ab += 1 //追加多个元素
ab += (2, 3, 4, 5) //追加一个数组++=
ab ++= Array(6, 7) //追加一个数组缓冲
ab ++= ArrayBuffer(8,9)//在数组某个位置插入元素用insert
ab.insert(0, -1, 0)
//删除数组某个位置的元素用remove
ab.remove(8, 2) println(ab)
}
}
4.1.2. 遍历数组
1.增强for循环。
2.好用的until会生成脚标,0 until 10 包含0不包含10。

package cn.itcast.scala
object ForArrayDemo {
def main(args: Array[String]) {
//初始化一个数组
val arr = Array(1,2,3,4,5,6,7,8)
//增强for循环
for(i <- arr)
println(i)
//好用的until会生成一个Range
//reverse是将前面生成的Range反转
for(i <- (0 until arr.length).reverse)
println(arr(i))
}
}
4.1.3. 数组转换
yield关键字将原始的数组进行转换会产生一个新的数组,原始的数组不变。

package cn.itcast.scala
object ArrayYieldDemo {
def main(args: Array[String]) {
//定义一个数组
val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
//将偶数取出乘以10后再生成一个新的数组
val res = for (e <- arr if e % 2 == 0) yield e * 10
println(res.toBuffer)
//更高级的写法,用着更爽
//filter是过滤,接收一个返回值为boolean的函数
//map相当于将数组中的每一个元素取出来,应用传进去的函数
val r = arr.filter(_ % 2 == 0).map(_ * 10)
println(r.toBuffer)
}
}
4.1.4. 数组常用算法
在Scala中,数组上的某些方法对数组进行相应的操作非常方便!

arr.sortBy(key)
arr.sortWith(_>_):从大到小
arr.sortWith(_<_):从小到大
arr.sortWith((x,y)=>x>y):从大到小
arr.sortWith((x,y)=>x<y):从小到大
4.2. 映射
在Scala中,把哈希表这种数据结构叫做映射。
4.2.1. 构建映射

4.2.2. 获取和修改映射中的值
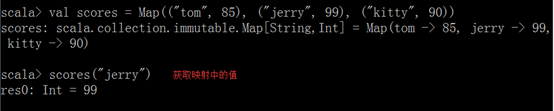
好用的getOrElse。

注意:在Scala中,有两种Map,一个是immutable包下的Map,该Map中的内容不可变;另一个是mutable包下的Map,该Map中的内容可变。
例子:

注意:通常我们在创建一个集合是会用val这个关键字修饰一个变量(相当于java中的final),那么就意味着该变量的引用不可变,该引用中的内容是不是可变,取决于这个引用指向的集合的类型。
4.3. 元组
映射是K/V对偶的集合,对偶是元组的最简单形式,元组可以装着多个不同类型的值。
4.3.1. 创建元组
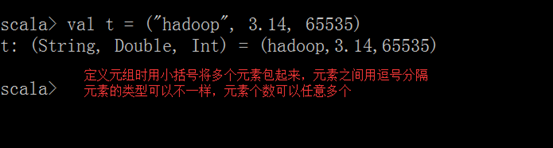
4.3.2. 获取元组中的值
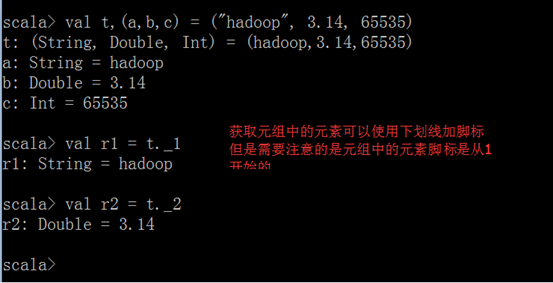
4.3.3. 将对偶的集合转换成映射

4.3.4. 拉链操作
zip命令可以将多个值绑定在一起
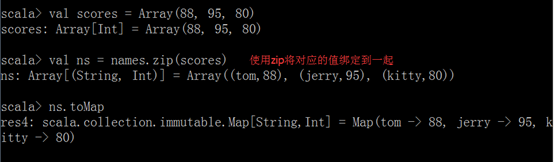
注意:如果两个数组的元素个数不一致,拉链操作后生成的数组的长度为较小的那个数组的元素个数。
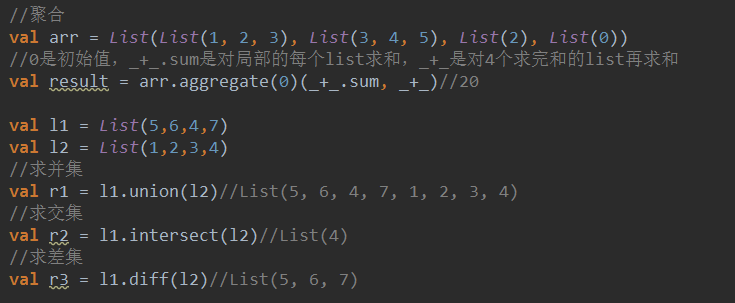
4.4. 集合
Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质
在Scala中集合有可变(mutable)和不可变(immutable)两种类型,immutable类型的集合初始化后就不能改变了(注意与val修饰的变量进行区别)。
4.4.1. 序列
不可变的序列 import scala.collection.immutable._
在Scala中列表要么为空(Nil表示空列表)要么是一个head元素加上一个tail列表。
9 :: List(5, 2) :: 操作符是将给定的头和尾创建一个新的列表
注意::: 操作符是右结合的,如9 :: 5 :: 2 :: Nil相当于 9 :: (5 :: (2 :: Nil))
package cn.itcast.collect
object ImmutListDemo {
def main(args: Array[String]) {
//创建一个不可变的集合
val lst1 = List(1,2,3)
//将0插入到lst1的前面生成一个新的List
val lst2 = 0 :: lst1
val lst3 = lst1.::(0)
val lst4 = 0 +: lst1
val lst5 = lst1.+:(0)
//将一个元素添加到lst1的后面产生一个新的集合
val lst6 = lst1 :+ 3
val lst0 = List(4,5,6)
//将2个list合并成一个新的List
val lst7 = lst1 ++ lst0
//将lst1插入到lst0前面生成一个新的集合
val lst8 = lst1 ++: lst0
//将lst0插入到lst1前面生成一个新的集合
val lst9 = lst1.:::(lst0)
println(lst9)
}
}
可变的序列 import scala.collection.mutable._
package cn.itcast.collect
import scala.collection.mutable.ListBuffer
object MutListDemo extends App{
//构建一个可变列表,初始有3个元素1,2,3
val lst0 = ListBuffer[Int](1,2,3)
//创建一个空的可变列表
val lst1 = new ListBuffer[Int]
//向lst1中追加元素,注意:没有生成新的集合
lst1 += 4
lst1.append(5) //将lst1中的元素最近到lst0中, 注意:没有生成新的集合
lst0 ++= lst1 //将lst0和lst1合并成一个新的ListBuffer 注意:生成了一个集合
val lst2= lst0 ++ lst1 //将元素追加到lst0的后面生成一个新的集合
val lst3 = lst0 :+ 5
}
4.4.2. Set
不可变的Set。
package cn.itcast.collect
import scala.collection.immutable.HashSet
object ImmutSetDemo extends App{ val set1 = new HashSet[Int]()
//将元素和set1合并生成一个新的set,原有set不变
val set2 = set1 + 4
//set中元素不能重复
val set3 = set1 ++ Set(5, 6, 7)
val set0 = Set(1,3,4) ++ set1
println(set0.getClass)
}
可变的Set。
package cn.itcast.collect
import scala.collection.mutable object MutSetDemo extends App{
//创建一个可变的HashSet
val set1 = new mutable.HashSet[Int]()
//向HashSet中添加元素
set1 += 2
//add等价于+=
set1.add(4)
set1 ++= Set(1,3,5)
println(set1) //删除一个元素
set1 -= 5
set1.remove(2)
println(set1)
}
4.4.3. Map
package cn.itcast.collect
import scala.collection.mutable
object MutMapDemo extends App{
val map1 = new mutable.HashMap[String, Int]()
//向map中添加数据
map1("spark") = 1
map1 += (("hadoop", 2))
map1.put("storm", 3)
println(map1) //从map中移除元素
map1 -= "spark"
map1.remove("hadoop")
println(map1)
}
补充:练习

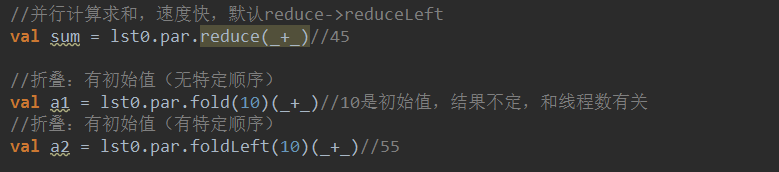
实现单机版的WordCount
val lines = List("hello tom hello jerry", "hello jerry", "hello kitty")
lines.flatMap(_.split(" ")).map((_, 1)).groupBy(_._1).mapValues(_.foldLeft(0)(_+_._2)).toList.sortBy(_._2).reverse
lines.flatMap(_.split(" ")).map((_, 1)).groupBy(_._1).map(t=>(t._1, t._2.size)).toList.sortBy(_._2).reverse
Scala学习笔记(一)编程基础的更多相关文章
- shell学习笔记1---shell编程基础
Shell是什么? Shell 是一个应用程序,它连接了用户和 Linux 内核,让用户能够更加高效.安全.低成本地使用 Linux 内核,这就是 Shell 的本质. Shell 本身并不是内核的一 ...
- Scala学习笔记--函数式编程
一.定义 简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论. 它属于"结构化编程&qu ...
- python学习笔记--python编程基础
一.一个隆重的仪式 我们在学习语言的时候,第一个写的程序肯定都是hello world.来写第一个程序吧,其实很简单,python的语法就是简单.优雅,一个print就搞定. 1 print('hel ...
- Scala学习笔记及与Java不同之处总结-从Java开发者角度
Scala与Java具有很多相似之处,但又有很多不同.这里主要从一个Java开发者的角度,总结在使用Scala的过程中所面临的一些思维转变. 这里仅仅是总结了部分两种语言在开发过程中的不同,以后会陆续 ...
- ufldl学习笔记和编程作业:Feature Extraction Using Convolution,Pooling(卷积和汇集特征提取)
ufldl学习笔记与编程作业:Feature Extraction Using Convolution,Pooling(卷积和池化抽取特征) ufldl出了新教程,感觉比之前的好,从基础讲起.系统清晰 ...
- ufldl学习笔记和编程作业:Softmax Regression(softmax回报)
ufldl学习笔记与编程作业:Softmax Regression(softmax回归) ufldl出了新教程.感觉比之前的好,从基础讲起.系统清晰,又有编程实践. 在deep learning高质量 ...
- ufldl学习笔记与编程作业:Softmax Regression(vectorization加速)
ufldl学习笔记与编程作业:Softmax Regression(vectorization加速) ufldl出了新教程,感觉比之前的好.从基础讲起.系统清晰,又有编程实践. 在deep learn ...
- ufldl学习笔记与编程作业:Multi-Layer Neural Network(多层神经网络+识别手写体编程)
ufldl学习笔记与编程作业:Multi-Layer Neural Network(多层神经网络+识别手写体编程) ufldl出了新教程,感觉比之前的好,从基础讲起,系统清晰,又有编程实践. 在dee ...
- 基于.net的分布式系统限流组件 C# DataGridView绑定List对象时,利用BindingList来实现增删查改 .net中ThreadPool与Task的认识总结 C# 排序技术研究与对比 基于.net的通用内存缓存模型组件 Scala学习笔记:重要语法特性
基于.net的分布式系统限流组件 在互联网应用中,流量洪峰是常有的事情.在应对流量洪峰时,通用的处理模式一般有排队.限流,这样可以非常直接有效的保护系统,防止系统被打爆.另外,通过限流技术手段,可 ...
- ufldl学习笔记与编程作业:Logistic Regression(逻辑回归)
ufldl学习笔记与编程作业:Logistic Regression(逻辑回归) ufldl出了新教程,感觉比之前的好,从基础讲起.系统清晰,又有编程实践. 在deep learning高质量群里面听 ...
随机推荐
- 【云计算】CloudFoundry参考资料
开源PaaS平台 Cloud Foundry:http://www.oschina.net/p/cloud+foundry/ 详解CloudFoundry中各个组件的作用:http://www.cst ...
- Activex打包于发布完整版---微软证书制作
众所周知,Activex组件没有进行有效的签名,在IE上无法安装的,除非你让用户手工开启“接收任何未签名的ActiveX”,这个很明显不现实.而组件签名需要证书,证书从哪里来,你可以选择付1000到3 ...
- 网页制作,网站制作中put和get的区别
Http定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE.URL全称是资源描述符,我们可以这样认为:一个URL地址,它用于描述一个网络上的资源,而HTTP ...
- windows Server2012 之 IIS8.0配置安装完整教程
IIS8.0是windows Server2012自带的服务器管理系统,和以往不同,IIS8.0安装和操作都比较简单,界面很简洁,安装也很迅速.今天我们重点完整的演示下Internet Informa ...
- Word2007中插入公式之后,公式上下有很大的空白
word 2007 选中一个公式,选择页面布局,点击页面设置右下角的小箭头,在弹出的对话框中,选择文档网格,在网格选项中选择无网格,确定,行距正常了. 选择一个公式,所有的公式行距都会变. Word ...
- CAS(Central Authentication Service)——windows上简单搭建及測试
入手文章,大神绕行. 一.服务端搭建 我使用的服务端版本号为:cas-server-3.4.11-release.zip.解压之后,将\cas-server-3.4.11-release\cas-se ...
- Unity3D优化之合并网格
原文地址点击这里
- 算法笔记_085:蓝桥杯练习 9-3摩尔斯电码(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 摩尔斯电码破译.类似于乔林教材第213页的例6.5,要求输入摩尔斯码,返回英文.请不要使用"zylib.h",只能使用 ...
- VUE 方法
1.$event 变量 $event 变量用于访问原生DOM事件. <!DOCTYPE html> <html lang="zh"> <head> ...
- SQLiteDatabase 源码
/** * Copyright (C) 2006 The Android Open Source Project * * Licensed under the Apache License, Vers ...