Python面试题之Python正则表达式指南
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程: 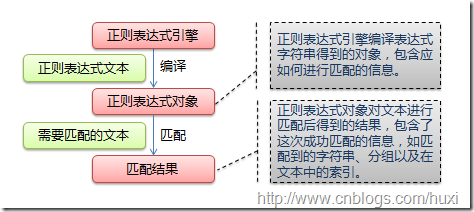
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:
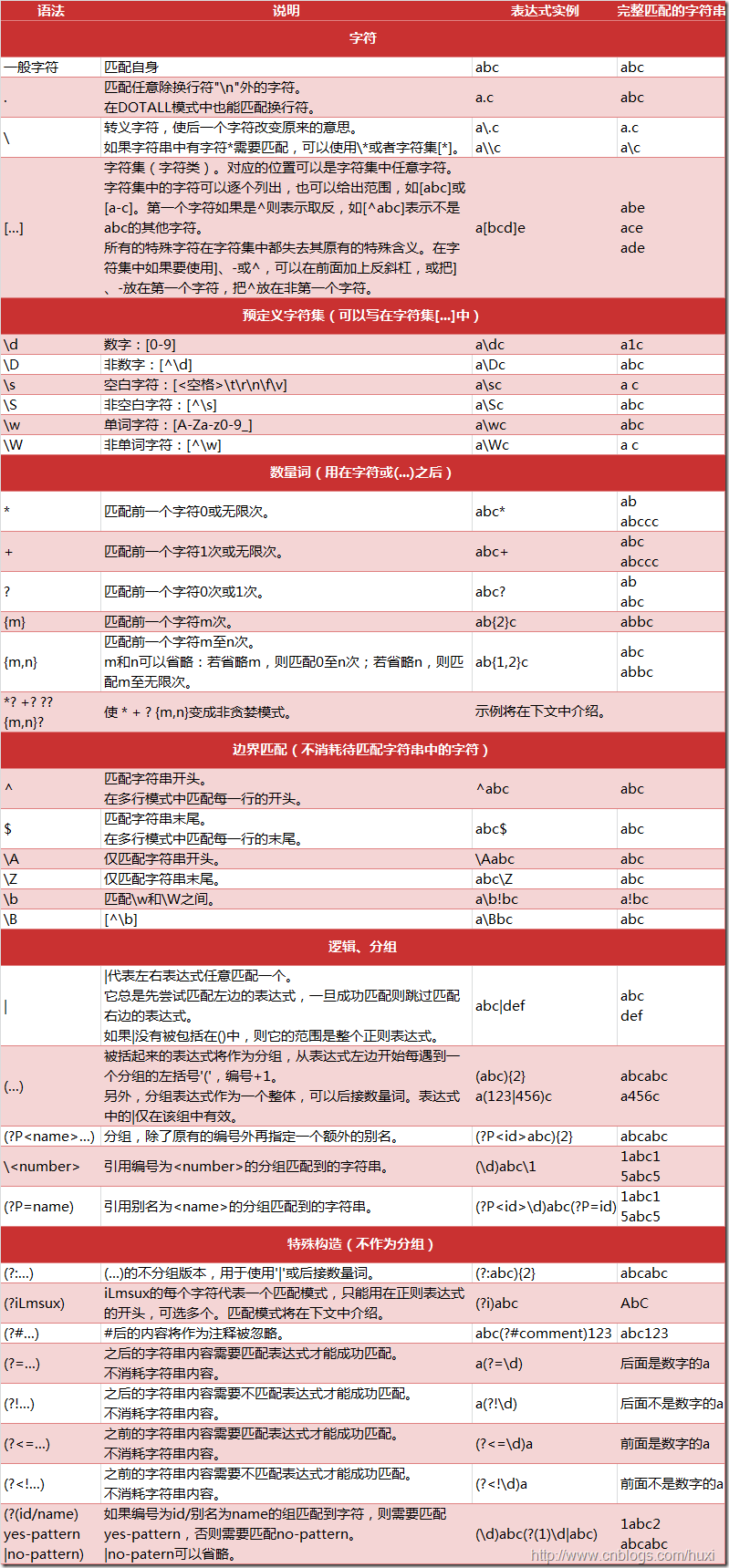
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# encoding: UTF-8import re# 将正则表达式编译成Pattern对象pattern = re.compile(r'hello')# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回Nonematch = pattern.match('hello world!')if match: # 使用Match获得分组信息 print match.group()### 输出 #### hello |
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
- S(DOTALL): 点任意匹配模式,改变'.'的行为
- L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
|
1
2
3
4
|
a = re.compile(r"""\d + # the integral part \. # the decimal point \d * # some fractional digits""", re.X)b = re.compile(r"\d+\.\d*") |
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
|
1
2
|
m = re.match(r'hello', 'hello world!')print m.group() |
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
- groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
- groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 - start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
- end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 - span([group]):
返回(start(group), end(group))。 - expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import rem = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')print "m.string:", m.stringprint "m.re:", m.reprint "m.pos:", m.posprint "m.endpos:", m.endposprint "m.lastindex:", m.lastindexprint "m.lastgroup:", m.lastgroupprint "m.group(1,2):", m.group(1, 2)print "m.groups():", m.groups()print "m.groupdict():", m.groupdict()print "m.start(2):", m.start(2)print "m.end(2):", m.end(2)print "m.span(2):", m.span(2)print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')### output #### m.string: hello world!# m.re: <_sre.SRE_Pattern object at 0x016E1A38># m.pos: 0# m.endpos: 12# m.lastindex: 3# m.lastgroup: sign# m.group(1,2): ('hello', 'world')# m.groups(): ('hello', 'world', '!')# m.groupdict(): {'sign': '!'}# m.start(2): 6# m.end(2): 11# m.span(2): (6, 11)# m.expand(r'\2 \1\3'): world hello! |
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import rep = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL)print "p.pattern:", p.patternprint "p.flags:", p.flagsprint "p.groups:", p.groupsprint "p.groupindex:", p.groupindex### output #### p.pattern: (\w+) (\w+)(?P<sign>.*)# p.flags: 16# p.groups: 3# p.groupindex: {'sign': 3} |
实例方法[ | re模块方法]:
- match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。
- search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
12345678910111213141516# encoding: UTF-8importre# 将正则表达式编译成Pattern对象pattern=re.compile(r'world')# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None# 这个例子中使用match()无法成功匹配match=pattern.search('hello world!')ifmatch:# 使用Match获得分组信息printmatch.group()### 输出 #### world - split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。1234567importrep=re.compile(r'\d+')printp.split('one1two2three3four4')### output #### ['one', 'two', 'three', 'four', ''] - findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。1234567importrep=re.compile(r'\d+')printp.findall('one1two2three3four4')### output #### ['1', '2', '3', '4'] - finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。12345678importrep=re.compile(r'\d+')forminp.finditer('one1two2three3four4'):printm.group(),### output #### 1 2 3 4 - sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
123456789101112131415importrep=re.compile(r'(\w+) (\w+)')s='i say, hello world!'printp.sub(r'\2 \1', s)deffunc(m):returnm.group(1).title()+' '+m.group(2).title()printp.sub(func, s)### output #### say i, world hello!# I Say, Hello World! - subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。123456789101112131415importrep=re.compile(r'(\w+) (\w+)')s='i say, hello world!'printp.subn(r'\2 \1', s)deffunc(m):returnm.group(1).title()+' '+m.group(2).title()printp.subn(func, s)### output #### ('say i, world hello!', 2)# ('I Say, Hello World!', 2)
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
参考
Python面试题之Python正则表达式指南的更多相关文章
- 千万不要错过这几道Python面试题,Python面试题No16
第1题: python下多线程的限制以及多进程中传递参数的方式? python多线程有个全局解释器锁(global interpreter lock),简称GIL,这个GIL并不是python的特性, ...
- Python面试题之Python面试题汇总
在这篇文章中: Python基础篇 1:为什么学习Python 2:通过什么途径学习Python 3:谈谈对Python和其他语言的区别 Python的优势: 4:简述解释型和编译型编程语言 5:Py ...
- python面试题之Python支持什么数据类型?
所属网站分类: 面试经典 > python 作者:外星人入侵 链接:http://www.pythonheidong.com/blog/article/67/ 来源:python黑洞网,专注py ...
- Python面试题之Python正则表达式re模块
一.Python正则表达式re模块简介 正则表达式,是一门相对通用的语言.简单说就是:用一系列的规则语法,去匹配,查找,替换等操作字符串,以达到对应的目的:此套规则,就是所谓的正则表达式.各个语言都有 ...
- python面试题三:Python 网络编程与并发
1 简述 OSI 七层协议. OSI七层协议模型主要是: 应用层(Application):为用户的应用程序(例如电子邮件.文件传输和终端仿真)提供网络服务. 表示层(Presentation):使用 ...
- Python面试题之python是一种什么语言及优缺点
1.说说python是一种什么语言? 参考答案:python是一门动态解释性的强类型定义语言 编译型vs解释型 编译型优点:编译器一般会有预编译的过程对代码进行优化.因为编译只做一次,运行时不需要编译 ...
- python面试题之Python是如何进行内存管理的
python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收. ...
- python面试题之python下多线程的限制
python多线程有个全局解释器锁(global interpreter lock). 这个锁的意思是任一时间只能有一个线程使用解释器,跟单cpu跑多个程序一个意思,大家都是轮着用的,这叫“并发”,不 ...
- Python面试题之Python中的类和实例
0x00 前言 类,在学习面向对象我们可以把类当成一种规范,这个思想就我个人的体会,感觉很重要,除了封装的功能外,类作为一种规范,我们自己可以定制的规范,从这个角度来看,在以后我们学习设计模式的时候, ...
随机推荐
- 《Windows游戏编程大师技巧》学习笔记——关于创建显示表面
1.如你所知,显示在屏幕上的图像仅仅只是是以某种格式存储在内存中的有色像素组成的矩阵.或是调色板化的或是RGB模式的.在不论什么一种情况下.要想做点什么你都必须知道如何绘制图到内存中,然而Direct ...
- MAC Ruby版本需要升级至2.2.2以上
第一例: 默认情况下,Mac OS X 系统已经安装好 Ruby(最新的 Mavericks 随机的 Ruby 版本为 2.0.0p247),安装在 /System/Library/Framework ...
- Mac 终端命令行颜色高亮显示
一.颜色高亮显示 针对terminal采用bash模式: 编辑 ~/.bash_profile, 加入以下代码: export CLICOLOR=1 export LSCOLORS=gxfxaxdxc ...
- BZOJ 3261 最大异或和 可持久化Trie树
题目大意:给定一个序列,提供下列操作: 1.在数组结尾插入一个数 2.给定l,r,x,求一个l<=p<=r,使x^a[p]^a[p+1]^...^a[n]最大 首先我们能够维护前缀和 然后 ...
- Response响应对象
1.HttpServletResponse HttpServletResponse是一个定义在Servlet API中的接口,继承自ServletReponse接口,用于封装HTTP响应消息.HTTP ...
- 一个Demo展示Storyboard的强大
本文转载至http://www.cocoachina.com/ios/20150330/11440.html 今天我通过完成一个长按cell删除的Demo,向你们展示熟练运用storyboard和Au ...
- CentOS 安装 dotnetcore
参考官方教程:https://www.microsoft.com/net/core#linuxcentos 安装.NET CORE SDK sudo yum install libunwind lib ...
- pandas 读取文件
import pandas as pd import matplotlib.pyplot as plt data = pd.read_csv('G:timeCompare.txt', sep=' ', ...
- AtCoder Tak and Hotels
题目链接:传送门 题目大意:有 n 个点排成一条直线,每次行动可以移动不超过 L 的距离,每次行动完成必须停在点上, 数据保证有解,有 m 组询问,问从 x 到 y 最少需要几次行动? 题目思路:倍增 ...
- log4j中将SocketAppender将日志内容发送到远程服务器
1.服务端配置 1)服务端配置文件log4j-server.properties #Define a narrow log category. A category like debug will p ...