大规模分布式数据处理平台Hadoop的介绍 一种可靠、高效、可伸缩的处理方案
http://www.nowamagic.net/librarys/veda/detail/1767 Hadoop是什么
Hadoop原来是Apache Lucene下的一个子项目,它最初是从Nutch项目中分离出来的专门负责分布式存储以及分布式运算的项目。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。例如,如果您要 grep 一个 10TB 的巨型文件,会出现什么情况?在传统的系统上,这将需要很长的时间。但是 Hadoop 在设计时就考虑到这些问题,采用并行执行机制,因此能大大提高效率。
Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
下面列举hadoop主要的一些特点:
- 扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
- 成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
- 高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
- 可靠性(Reliable):hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
Hadoop还实现了MapReduce分布式计算模型。MapReduce将应用程序的工作分解成很多小的工作小块(small blocks of work)。HDFS为了做到可靠性(reliability)创建了多份数据块(data blocks)的复制(replicas),并将它们放置在服务器群的计算节点中(compute nodes),MapReduce就可以在它们所在的节点上处理这些数据了。
如下图所示: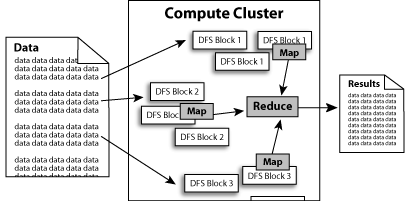
.gif)
Hadoop API被分成(divide into)如下几种主要的包(package):
- org.apache.hadoop.conf: 定义了系统参数的配置文件处理API。
- org.apache.hadoop.fs: 定义了抽象的文件系统API。
- org.apache.hadoop.dfs: Hadoop分布式文件系统(HDFS)模块的实现。
- org.apache.hadoop.io: 定义了通用的I/O API,用于针对网络,数据库,文件等数据对象做读写操作。
- org.apache.hadoop.ipc: 用于网络服务端和客户端的工具,封装了网络异步I/O的基础模块。
- org.apache.hadoop.mapred: Hadoop分布式计算系统(MapReduce)模块的实现,包括任务的分发调度等。
- org.apache.hadoop.metrics: 定义了用于性能统计信息的API,主要用于mapred和dfs模块。
- org.apache.hadoop.record: 定义了针对记录的I/O API类以及一个记录描述语言翻译器,用于简化将记录序列化成语言中性的格式(language-neutral manner)。
- org.apache.hadoop.tools: 定义了一些通用的工具。
- org.apache.hadoop.util: 定义了一些公用的API。
Hadoop的框架结构
Map/Reduce是一个用于大规模数据处理的分布式计算模型,它最初是由Google工程师设计并实现的,Google已经将它完整的MapReduce论文公开发布了。其中对它的定义是,Map/Reduce是一个编程模型(programming model),是一个用于处理和生成大规模数据集(processing and generating large data sets)的相关的实现。用户定义一个map函数来处理一个key/value对以生成一批中间的key/value对,再定义一个reduce函数将所有这些中间的有着相同key的values合并起来。很多现实世界中的任务都可用这个模型来表达。
.jpg)
Hadoop的Map/Reduce框架也是基于这个原理实现的。
MapReduce的工作流程很不复杂。如上图所示,每个Map(worker)分别读入一定数量的以key-value格式存储的数据块(split0 – split4,64MB/block)。如果是对文本文件做单词统计,那么key-value格式的数据可以这么定义:<String filename, String file_content>。
然后每个Map分别对各自数据进行处理,输出以key-value格式组织的中间结果(Intermediate files)。仍以单词统计为例,Map对数据中每一个出现的单词,输出一个记录<word, "1">。这就是说,在一个Map的输出结果中,有可能出现重复n次<word, "1">(可以通过Combiner对其进行优化,使之输出为<word, "n">,以此来减少网络流量)。
随后通过Shuffle把相同key的中间结果汇集到相同节点上,比如说,上图中3个Map phase的worker都有<word, "1">的中间结果,那么通过Shuffle将这些相同key的记录汇集到同一个Reduce phase的worker上,进而使用一个Reduce处理包含相同key的所有记录。也就是说,所有在Map phase阶段产生的<word, "1">,都会到Reduce phase上的一个worker上被一个Reduce处理,进行归并。最后输出结果。
大规模分布式数据处理平台Hadoop的介绍 一种可靠、高效、可伸缩的处理方案的更多相关文章
- 互联网大规模数据分析技术(自主模式)第五章 大数据平台与技术 第10讲 大数据处理平台Hadoop
大规模的数据计算对于数据挖掘领域当中的作用.两大主要挑战:第一.如何实现分布式的计算 第二.分布式并行编程.Hadoop平台以及Map-reduce的编程方式解决了上面的几个问题.这是谷歌的一个最基本 ...
- 批量搞机(二):分布式ELK平台、Elasticsearch介绍、Elasticsearch集群安装、ES 插件的安装与使用
一.分布式ELK平台 ELK的介绍: ELK 是什么? Sina.饿了么.携程.华为.美团.freewheel.畅捷通 .新浪微博.大讲台.魅族.IBM...... 这些公司都在使用 ELK!ELK! ...
- Hadoop笔记系列 一 用Hadoop进行分布式数据处理(1)
学习资料参考地址: 1.http://blog.csdn.net/zhoudaxia/article/details/8801769 1.先说说什么是Hadoop? 个人理解:一个分布式文件存储系统+ ...
- Hadoop与分布式数据处理 Spark VS Hadoop有哪些异同点?
Spark是一个开源的通用并行分布式计算框架,由加州大学伯克利分校的AMP实验室开发,支持内存计算.多迭代批量处理.即席查询.流处理和图计算等多种范式.Spark内存计算框架适合各种迭代算法和交互式数 ...
- hadoop大数据处理平台与案例
大数据可以说是从搜索引擎诞生之处就有了,我们熟悉的搜索引擎,如百度搜索引擎.360搜索引擎等可以说是大数据技处理技术的最早的也是比较基础的一种应用.大概在2015年大数据都还不是非常火爆,2015年可 ...
- 分布式配置管理平台 - Disconf介绍
原博客地址:http://blog.csdn.net/zhu_tianwei/article/details/47984545 Disconf专注于各种分布式系统配置管理的通用组件/通用平台,提供统一 ...
- hadoop生态圈介绍
原文地址:大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- Hadoop生态圈介绍及入门(转)
本帖最后由 howtodown 于 2015-4-2 23:15 编辑 问题导读 1.Hadoop生态圈介绍了哪些组件,分别都是什么? 2.大数据与Hadoop是什么关系? 本章主要内容: 理解大数据 ...
随机推荐
- 【模拟退火】poj2420 A Star not a Tree?
题意:求平面上一个点,使其到给定的n个点的距离和最小,即费马点. 模拟退火的思想是随机移动,然后100%接受更优解,以一定概率接受更劣解.移动的过程中温度缓慢降低,接受更劣解的概率降低. 在网上看到的 ...
- 【数论】【莫比乌斯反演】【线性筛】bzoj2301 [HAOI2011]Problem b
对于给出的n个询问,每次求有多少个数对(x,y),满足a≤x≤b,c≤y≤d,且gcd(x,y) = k,gcd(x,y)函数为x和y的最大公约数. 100%的数据满足:1≤n≤50000,1≤a≤b ...
- 【动态规划】CDOJ1651 Uestc的命运之旅
要处理从四个角出发的答案.最后枚举那个交点,然后讨论一下来的方向即可. #include<cstdio> #include<algorithm> using namespace ...
- MySort
实验概述: 本次试验的内容:模拟实现Linux下Sort -t : -k 2的功能.参考Sort的实现.提交码云链接和代码运行截图. 截图如下 实验过程 在实验课上真的很崩溃,可以说脑子里一团乱麻,下 ...
- Maven的内置属性
Maven共有6类属性: ①内置属性(Maven预定义属性,用户可以直接使用) ${basedir}表示项目的根路径,即包含pom.xml文件的目录 ${version}表示项目版本 ${projec ...
- static_cast, dynamic_cast, reinterpret_cast, const_cast的区别
static_cast最像C风格的强制转换,很多时候都需要程序员自身去判断转换是否安全.但是相对C风格的强制转换,在无关类的类指针之间转换上,有安全性的提升. dynamic_cast是运行时的转换吧 ...
- Problem A: 自定义函数strcomp(),实现两个字符串的比较
#include<stdio.h> int strcmp(char *str1,char *str2) { if(str1!=NULL&&str2!=NULL) { whi ...
- ERROR 1044: Access denied for user: 'songyan' to database 'yikexiao' 的错误。
问题描述:新买的服务器,刚安装了mysql,创建了一个用户,也忘记了给他分配了什么权限,今天在建库的时候出现了这个问题. 出错原因:度娘告诉我是因为songyan用户没有建库的权限报的错. 解决: ( ...
- mongo基础---增删改查
正文 MongoDB 是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案.MongoDB是一个介于关系型数据库和非关系数据库之间的产品,是非关系数据 ...
- FIREMONEY手机虚拟键盘遮挡的解决
FIREMONEY手机虚拟键盘遮挡的解决 尝遍了网上人们提供的N种方法之后,发现还是老猫的方法才是彻底解决问题的办法. 老猫“不看后悔XXX”--->RAD10.2.3 Flying Wang ...