Mysql 工作原理
刚开始接触一个新的事物的时候,我觉得很有必要从其工作原理入手,弄清楚这个东西的来龙去脉,为接下来的继续深入学习做好铺垫,掌握好其原理有助于我们从整体上来把握这个东西,并且帮助我们在排错过程中理清思路。接下来,还是从mysql的工作原理开始入手,下面先来一张经典的图:
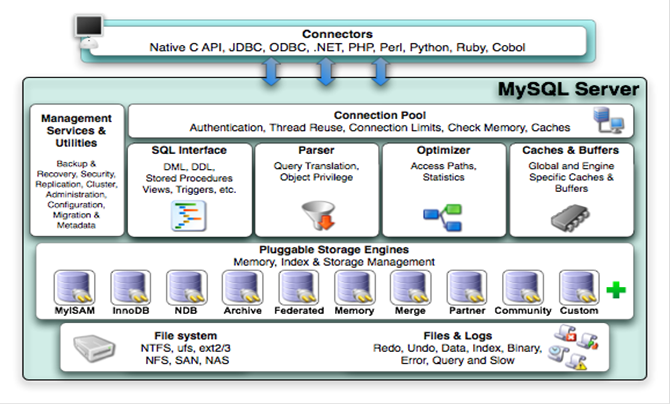
上面的图就是mysql的内部架构,可以清楚的看到Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的。
-+-----------------------------------------------------------------------------------+-
下面是关于上述部件的介绍:
1. connectors
与其他编程语言中的sql 语句进行交互,如php、java等。
2. Management Serveices & Utilities
系统管理和控制工具
3. Connection Pool (连接池)
管理缓冲用户连接,线程处理等需要缓存的需求
8.Engine (存储引擎)
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。
-+-----------------------------------------------------------------------------------+-
SQL 语句执行过程
数据库通常不会被直接使用,而是由其他编程语言通过SQL语句调用mysql,由mysql处理并返回执行结果。那么Mysql接受到SQL语句后,又是如何处理的呢?
首先程序的请求会通过mysql的connectors与其进行交互,请求到处后,会暂时存放在连接池(connection pool)中并由处理器(Management Serveices & Utilities)管理。当该请求从等待队列进入到处理队列,管理器会将该请求丢给SQL接口(SQL Interface)。SQL接口接收到请求后,它会将请求进行hash处理并与缓存中的结果进行对比,如果完全匹配则通过缓存直接返回处理结果;否则,需要完整的走一趟流程:
(1)由SQL接口丢给后面的解释器(Parser),上面已经说到,解释器会判断SQL语句正确与否,若正确则将其转化为数据结构。
(2)解释器处理完,便来到后面的优化器(Optimizer),它会产生多种执行计划,最终数据库会选择最优化的方案去执行,尽快返会结果。
(3)确定最优执行计划后,SQL语句此时便可以交由存储引擎(Engine)处理,存储引擎将会到后端的存储设备中取得相应的数据,并原路返回给程序。
这里有几点需要注意:
(1)如何缓存查询数据?
存储引擎处理完数据,并将其返回给程序的同时,它还会将一份数据保留在缓存中,以便更快速的处理下一次相同的请求。具体情况是,mysql会将查询的语句、执行结果等进行hash,并保留在cache中,等待下次查询。
(2)buffer与cache的区别?
从上面的图可以看到,缓存那里实际上有buffer和cache两个,那它们之间是否有什么不同呢?简单的说就是,buffer是写缓存,cache是读缓存。
(3)如何判断缓存中是否已缓存需要的数据
这里可能有一个误区,觉得处理SQL语句的时候,为了判断是否已缓存查询结果,会将整个流程走一遍,取得执行结果后再与需要的进行对比,看看是否命中,并以此说,既然不管缓存中有没有缓存到查询内容,都要整个流程走一遍,那么缓存的优势又在哪里??
实际上,并非如此,在第一次查询后,mysql便将查询语句以及查询结果进行hash处理并保留在缓存中,SQL查询到达之后,对其进行同样的hash处理后,将两个hash值进行对照,如果一样,则命中,从缓存中返回查询结果;否则,需要整个流程走一遍。
Mysql 工作原理的更多相关文章
- mysql工作原理(网络搜索整理的)
原文网址:Mysql 工作原理 原文网址:MySQL运行原理与基础架构 mysql基本用法原文网址:MySQL(一):基本原理 SQL 语句执行过程 数据库通常不会被直接使用,而是由其他编程语言通过S ...
- MySQL工作原理
Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的. mysql原理图各个组件说明: 1. connectors 与其他编程语言中的sql 语句进行交互,如php.java等. 2. M ...
- mysql索引工作原理、分类
一.概述 在mysql中,索引(index)又叫键(key),它是存储引擎用于快速找到所需记录的一种数据结构.在越来越大的表中,索引是对查询性能优化最有效的手段,索引对性能影响非常关键.另外,mysq ...
- mysql(一)工作原理 & 数据库引擎
参考文档 http://www.cnblogs.com/xiaotengyi/articles/3641983.html innodb:https://www.cnblogs.com/Aiapple/ ...
- MySQL Replication--复制基本工作原理
复制工作原理(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events):(2) slave将master的binary lo ...
- MySQL MHA工作原理
MHA工作组件 MHA(Master High Availability)是一种MySQL高可用解决方案,由日本DeNA公司开发,主要用于在故障切换和主从提升时进行快速切换,并最大程度保证数据一致性. ...
- MySQL/MariaDB数据库的索引工作原理和优化
MySQL/MariaDB数据库的索引工作原理和优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 实际工作中索引这个技术是影响服务器性能一个非常重要的指标,因此我们得花时间去了 ...
- 《Mysql - Order By 的工作原理?》
一:概述 - order by 用于 SQL 语句中的排序. - 以 select city,name,age from t where city='杭州' order by name limit ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
随机推荐
- 【MYSQL笔记】
1.去重取出id最小的记录 tip:在laravel框架里配置信息database设置了'strict' => true,所以在groupBy时只能select出groupBy后的字段,当想搜索 ...
- 基于Geomesa服务查询轨迹数据无法根据空间和时间范围进行结果查询
一.Geomesa - QuickStart(教程工程包) 百度网盘下载地址:geomesa-tutorials-master.7z 二.解压后,IDEA编译如下 百度网盘下载地址:IDEA201 ...
- GitLab 基本操作
登录 在浏览其中输入http://192.168.3.11:8888 如图1登录界面. 图1 注:第一次新增用户,会发送修改密码链接到用户的邮箱中,用户会收到如图2邮件. 图2 2. 修改密码 点 ...
- 中国大学MOOC-C程序设计(浙大翁恺)—— 时间换算
时间换算(10分) 题目内容: UTC是世界协调时,BJT是北京时间,UTC时间相当于BJT减去8.现在,你的程序要读入一个整数,表示BJT的时和分.整数的个位和十位表示分,百位和千位表示小时.如果小 ...
- python类的多态
1. 什么是多态 多态指的是同一种/类事物的不同形态 2. 为何要用多态 多态性:在多态的背景下,可以在不用考虑对象具体类型的前提下而直接使用对象 多态性的精髓:统一 ...
- Maximum sum
描述 Given a set of n integers: A={a1, a2,-, an}, we define a function d(A) as below: t1 t2 d(A) = max ...
- nodejs multer
nodejs上传文件multer var multer = require('multer') var storage = multer.diskStorage({ destination: func ...
- 【Hutool】Hutool工具类之String工具——StrUtil
类似的是commons-lang中的StringUtils 空与非空的操作——经典的isBlank/isNotBlank.isEmpty/isNotEmpty isBlank()——是否为空白,空白的 ...
- Git项目的目录结构
branch是分支 trunk是主干 bug修正和新功能的添加一般在branch进行 测试好了没问题了就可以合并到trunk 每隔一段时间就可以打包成一个版本放到tags 用于发布的版本一般 ...
- 北京Uber优步司机奖励政策(2月17日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...