Hadoop1.x HDFS系统架构
1.1 数据块
1.2 NameNode和DataNode
1.2.1 管理者:Namenode
1.2.1 工作者:Datanode
1.3 Secondary Namenode
1.4 HDFS的优缺点
2. HDFS的架构
2.1 HDFS架构之NameNode和DataNode
2.2 Namenode和Secondary Namenode运行关系
3. HDFS文件的读写流程
3.1 HDFS文件的读取
3.2 HDFS文件的写入
1. HDFS中的一些概念
HDFS(Hadoop Distributed File System):分布式文件系统,将一个文件分成多个块,分别存储(拷贝)到不同的节点上,它是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
1.1 数据块
每个磁盘都有数据块的概念,在HDFS中也有数据块的概念,HDFS中的所有文件都是分割成块存储在Datanode上的,每个块默认64M。。每个块都有多个副本存储在不同的机器上:默认有3个副本,3个副本不可能存放在同一个机器上。
HDFS副本存放策略
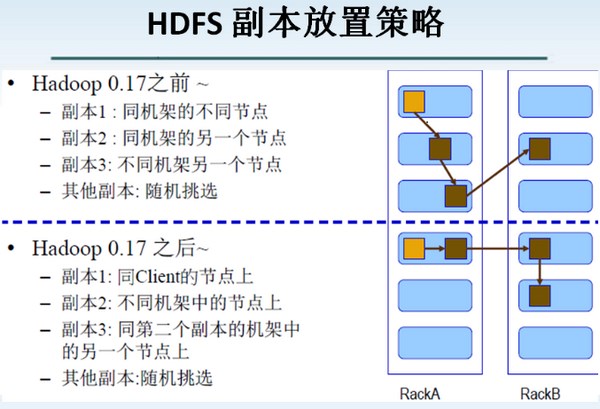
以下是HDFS文件存储架构图
黄色:表示每台机器
绿色:文件被分割出的块
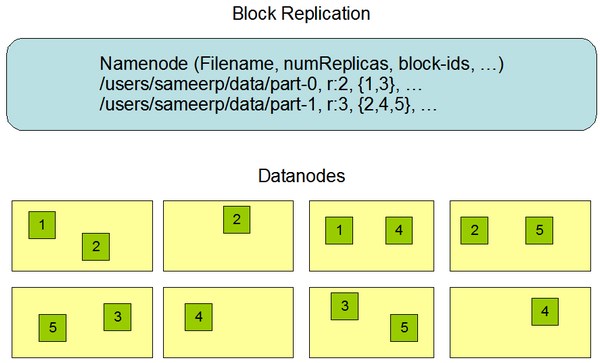
例如:
上图中part-0文件,有2个块。块1和块3只在2个机器上分别出现过2次。
上图中part-1文件,有3个块。块2,4,5分别在不同的机器上各出现3次
HDFS中也可以显示块信息,使用fsck命令
例如:下面的命令将列出文件系统中各个文件由哪些块构成
$ hadoop fsck / -files -blocks
1.2 NameNode和DataNode
HDFS的设计是主(Master)从(Slave)结构的。也就是,一个管理者(NameNode)和多个工作者(DataNode)组成。
1.2.1 管理者:Namenode
NameNode是主节点,它是一个中心服务器,负责管理整个文件系统的命名空间和控制着客户端对文件的访问。它不保存文件的内容,而是保存着文件的元数据(文件名称,所在目录,文件权限,文件拥有者,文件有多少块,每个块有多少副本,块都存在哪些节点上)。
Namenode负责文件的元数据操作,Datanode处理文件内容的读写请求。
跟文件相关的流不经过Namenode,只会询问该文件跟哪个Datanode有关系。
副本存放在哪些Datanode上是由Namenode来控制。读取文件时,Namenode尽量让用户先读取最近的副本。
Namenode全权管理数据块的复制,周期性的从集群中的每个Datanode接收心跳信号和块状态报告。
Namenode和Datanode就是通过这两种方式来进行通信:
心跳信号:意味着该Datanode节点工作正常
块状态报告:包含了一个该Datanode上所有数据块的列表
元数据保存在内存中
Namenode维护着整个文件系统树以及树内的所有文件。这些信息以两个文件的形式永久保存在磁盘上。命名空间镜像文件(fsimage)和操作日志(fsedits)文件
1. fsimage是什么?
fsimage是元数据镜像文件:Namenode启动后,文件的元数据被加载到内存中,加载到内存后也会把这些元数据写入到本地的磁盘中,这个文件就是fsimage文件。
元数据镜像在内存中保存一份最新的,内存中的镜像=fsimage+fsedit
2. fsedits是什么?
fsedits是元数据操作日志文件:客户端要对文件进行读写操作,在这些操作产生的日志就存在了fsedit文件中。
1.2.1 工作者:Datanode
DataNode是从节点,它的作用很简单,就是存储文件的块数据。以及块数据的校验和。
一个数据块在Ddtanode以文件存储在磁盘上,包括两个文件:数据本身和元数据(数据块的长度,块数据的校验和,时间戳)
Datanode启动后向Namenode注册,通过后,周期性(1小时)的向Namenode上报所有块信息。
心跳是3秒一次,如果超过10分钟没有收到某个Datanode的心跳。则认为该节点不可用。
1.3 Secondary Namenode
Secondary Namenode:Secondary表示助手的意思,也就是说Secondary Namenode表示NameNode的助手,辅助NameNode工作的一个节点。要了解Secondary Namenode节点都辅助NameNode做了哪些工作,我们需要先回顾下NameNode是做什么的?
NameNode是HDFS中的一个主节点,主要是来管理其他DataNode从节点。它存储了HDFS系统的namespace和控制着客户端对HDFS文件系统的访问。NameNode在维护整个文件系统树的时候是以两个文件的形式永久保存在磁盘上。镜像文件(fsimage)和操作日志文件(fsedits)。考虑以下,这两个文件一直这样运行存在着有什么问题?
- fsedits操作日志文件会越来越大,因为它保存着客户端对HDFS文件系统的访问日志。
- 只有在NameNode重启后,edits logs才会合并到fsimage中,产生一个新的文件系统快照。但是NameNode是很少重启的。
为了保证edit logs文件不会太大和fsimage是一个最新的文件,此时需要一个节点来备份这些文件。定期的合并这两个文件然后再推送给NameNode,这样就减轻NameNode工作的压力,同时也保证了假如Namenode节点宕机后数据无法恢复问题。虽然可能不会把所有的数据全部恢复出来,但是至少丢失的很少。
所以,Secondary Namenode做的就是这些辅助工作
- Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。
- SecondaryNameNode有两个作用,一是镜像备份,二是日志与镜像的定期合并。两个过程同时进行,称为checkpoint
在core-site.xml配置文件中有2个参数可配置,但一般来说我们不做修改。fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。fs.checkpoint.size表示一次记录多大的size,默认64M。
<property><name>fs.checkpoint.period</name><value>3600</value><description>The number of seconds between two periodic checkpoints.</description></property><property><name>fs.checkpoint.size</name><value>67108864</value><description>The size of the current edit log (in bytes) that triggers a periodic checkpoint even if the fs.checkpoint.period hasn’t expired.</description></property>
可以参考这篇博客,写的还是很详细的Secondary NameNode:它究竟有什么作用?
1.4 HDFS的优缺点
优点:
- 高容错性
数据自动保存多个副本
副本丢失后,自动恢复 - 适合批处理
移动计算而非数据
数据位置暴露给计算框架 - 适合大数据处理
GB、TB、甚至PB级数据
百万规模以上的文件数量
10K+节点规模 - 流式文件访问
一次性写入,多次读取
保证数据一致性 - 可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复机制
缺点:
- 低延迟与高吞吐率的数据访问 ,比如毫秒级
- 小文件存取
占用NameNode大量内存
寻道时间超过读取时间 - 并发写入、文件随机修改
一个文件同一个时间只能有一个写者
仅支持append
2. HDFS的架构
HDFS以流式数据访问(一次写入,多次读取)模式来存储超大文件,运行于商用硬件集群上。超大文件是指GB,TB,PB的文件。目前已经有存储到PB级别的Hadoop集群了。
计算机字节关系

Hadoop1.x HDFS官方架构图
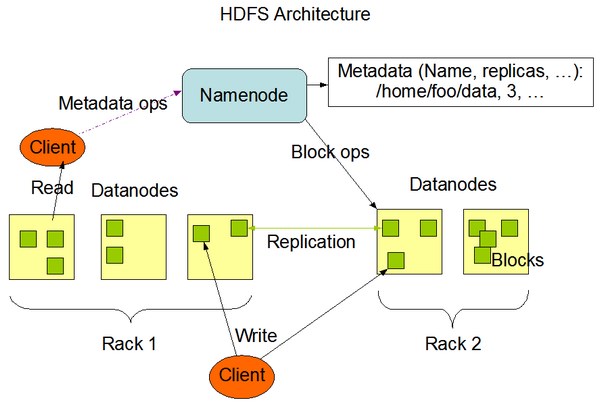
2.1 HDFS架构之NameNode和DataNode
HDFS架构图
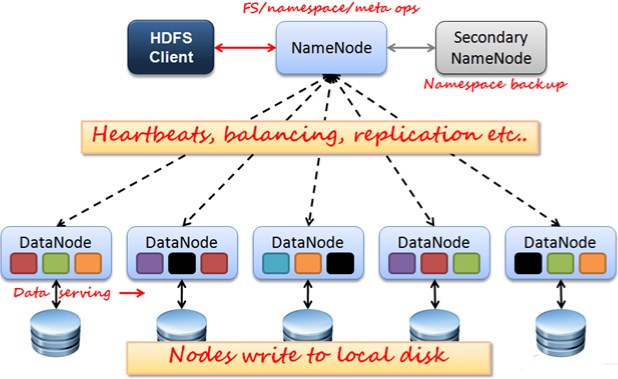
- 客户端(HDFS Client):如果想对文件进行读写的话,首先需要通过Namenode来获取一些信息。Namenode存储着命名空间(namespace)和元数据(metadata)
客户端有如下工作:- 文件的切分
- 与Namenode交互,获取文件位置信息
- 与Datanode交互,读取或者写入数据
- 管理HDFS
- 访问HDFS(浏览器,Shell命令,JavaAPI)
- 辅助节点(Secondary):用于辅助Namenode工作,分担其工作量。主要工作是nameSpace的冷备份工作,并非热备份。定期将Namenode的镜像文件(fsimage)和操作日志(fsedit)进行合并,然后推送给Namenode
1. fsimage是什么?
是元数据镜像文件:Namenode启动后,文件的元数据被加载到内存中,加载到内存后也会把这些元数据写入到本地的磁盘中,这个文件就是fsimage文件。
元数据镜像在内存中保存一份最新的,内存中的镜像=fsimage+fsedit
2. fsedits是什么?
是元数据操作日志文件:客户端要对文件进行读写操作,在这些操作产生的日志就存在了fsedit文件中。 - 数据节点(Datanode):Namenode和Datanode通信是通过心跳和块报告。每个文件被分割成不同的块,存在不同的机器的本地磁盘上。
2.2 Namenode和Secondary Namenode运行关系
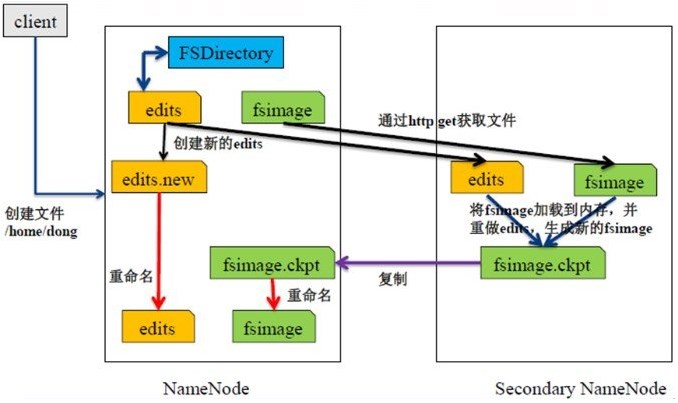
Secondarynamenode工作原理
日志与镜像的定期合并总共分以下五步:
- Secondary Namenode通知Namenode切换editlog
- Secondary Namenode通过Http方式从Namenode获取fsimage和editlog
- Secondary Namenode将fsimage载入内存,然后开始合并editlog
- Secondary Namenode将新的fsimage发回给Namenode
- Namenode收到fsiamge后将新的fsimage替换旧的fsimage
3. HDFS文件的读写流程
3.1 HDFS文件的读取
HDFS文件读取:

- 首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例
- DistributedFileSystem通过rpc获得文件的第一批个block的locations,同一block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面.
- 前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
- 数据从datanode源源不断的流向客户端。
- 如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
- 如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。
3.2 HDFS文件的写入
HDFS文件写入:
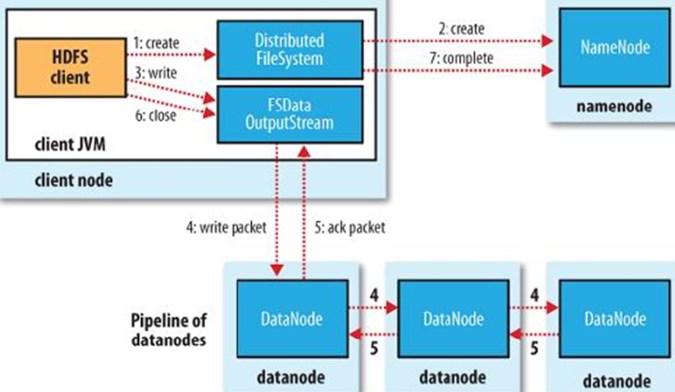
- 客户端通过调用DistributedFileSystem的create方法创建新文件
- DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常.
- 前两步结束后会返回FSDataOutputStream的对象,和读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data quene。
- DataStreamer会去处理接受data quene,他先问询namenode这个新的block最适合存储的在哪几个datanode里,比如重复数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline.DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,以此类推。
- DFSOutputStream还有一个对列叫ack quene,也是有packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc quene才会把对应的packet包移除掉。
- 客户端完成写数据后调用close方法关闭写入流
- DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知datanode把文件标示为已完成。
读写流程参考自:HDFS笔记(特点、原理与基本架构)
Hadoop1.x HDFS系统架构的更多相关文章
- 1.8-1.10 大数据仓库的数据收集架构及监控日志目录日志数据,实时抽取之hdfs系统上
一.数据仓库架构 二.flume收集数据存储到hdfs 文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hd ...
- hbase基础-系统架构
HBase 系统架构 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列 ...
- 【转发】揭秘Facebook 的系统架构
揭底Facebook 的系统架构 www.MyException.Cn 发布于:2012-08-28 12:37:01 浏览:0次 0 揭秘Facebook 的系统架构 www.MyExcep ...
- Hbase系统架构
HBase 系统架构 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列 ...
- 大型网站系统架构演化之路【mark】
前言 一 个成熟的大型网站(如淘宝.天猫.腾讯等)的系统架构并不是一开始设计时就具备完整的高性能.高可用.高伸缩等特性的,它是随着用户量的增加,业务功能的 扩展逐渐演变完善的,在这个过程中,开发模式. ...
- HBase 系统架构
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型.它存储的是 ...
- 系统架构师JD
#################################################################################################### ...
- 初步掌握HDFS的架构及原理
目录 HDFS 是做什么的 HDFS 从何而来 为什么选择 HDFS 存储数据 HDFS 如何存储数据 HDFS 如何读取文件 HDFS 如何写入文件 HDFS 副本存放策略 Hadoop2.x新特性 ...
- 大数据高并发系统架构实战方案(LVS负载均衡、Nginx、共享存储、海量数据、队列缓存)
课程简介: 随着互联网的发展,高并发.大数据量的网站要求越来越高.而这些高要求都是基础的技术和细节组合而成的.本课程就从实际案例出发给大家原景重现高并发架构常用技术点及详细演练. 通过该课程的学习,普 ...
随机推荐
- 怎么应对 domino文档损坏然后损坏文档别删除导致数据丢失
对于domino 有个机制是同步 ..然后如果文档被损坏之后会通过同步或者压缩 之类的 然后将损坏文档删除 那么这样就有个风险..知识管理文档会被删除. 并且删除了之后管理员如果不仔细看日志的话也不会 ...
- 005-spring cache-配置缓存存储
一.概述 缓存抽象提供了多种存储集成.要使用它们,需要简单地声明一个适当的CacheManager - 一个控制和管理Caches的实体,可用于检索这些实体以进行存储. 1.1.基于JDK Concu ...
- java map典型排序
List<Map.Entry<TbDiseases, Double>> list = new ArrayList<Map.Entry<TbDiseases,Doub ...
- 常用linux shell脚本记录
遍历目录下所有的文件是目录还是文件 for file in ./* do if test -f $file then echo $file 是文件 fi if test -d $file then e ...
- 关于eval 与new Function 到底该选哪个?
废话不多说,直接上测试代码 复制代码 代码如下: var aa = "{name:'cola',item:[{age:11},{age:22},{age:23},{age:23}]}&quo ...
- 系统管理命令之last
Linux系统中使用以下命令来查看文件的内容: cat 由第一行开始显示文件内容 tac 从最后一行开始显示,可以看出 tac 是 cat 的倒著写! nl 显示的时候,顺道输出行号! mor ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON SetWindowExtent
zw版[转发·台湾nvp系列Delphi例程]HALCON SetWindowExtent unit Unit1;interfaceuses Windows, Messages, SysUtils, ...
- Java StringBuffer 和 StringBuilder 类
当对字符串进行修改的时候,需要使用 StringBuffer 和 StringBuilder 类. 和 String 类不同的是,StringBuffer 和 StringBuilder 类的对象能够 ...
- 面试官问:JS的this指向
前言 面试官出很多考题,基本都会变着方式来考察this指向,看候选人对JS基础知识是否扎实.读者可以先拉到底部看总结,再谷歌(或各技术平台)搜索几篇类似文章,看笔者写的文章和别人有什么不同(欢迎在评论 ...
- linux内核分析第三周-跟踪分析Linux内核的启动过程
一.实验流程 1.打开环境 执行命令:cd LinuxKernel/ 执行命令:qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd root ...