深度学习(四) softmax函数
softmax函数
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
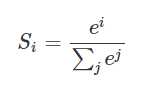
更形象的如下图表示:
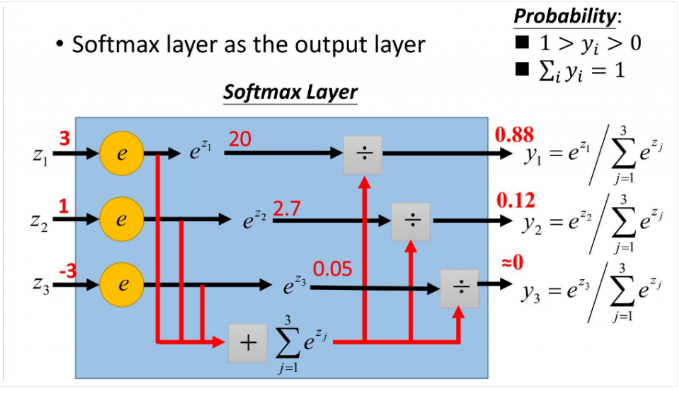
softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
softmax相关求导
当我们对分类的Loss进行改进的时候,我们要通过梯度下降,每次优化一个step大小的梯度,这个时候我们就要求Loss对每个权重矩阵的偏导,然后应用链式法则。那么这个过程的第一步,就是对softmax求导传回去,不用着急,我后面会举例子非常详细的说明。在这个过程中,你会发现用了softmax函数之后,梯度求导过程非常非常方便!
下面我们举出一个简单例子,原理一样,目的是为了帮助大家容易理解!
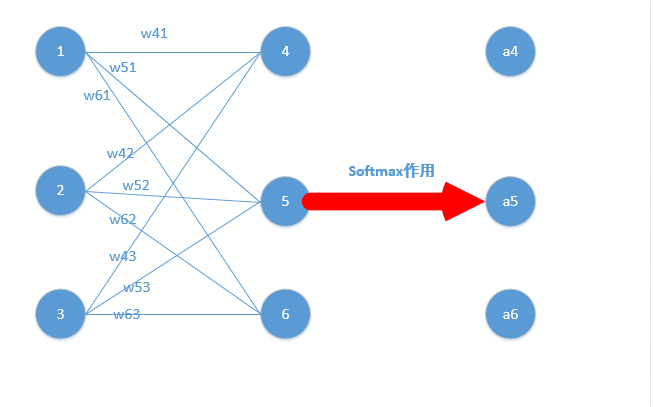
我们能得到下面公式:
z4 = w41*o1+w42*o2+w43*o3
z5 = w51*o1+w52*o2+w53*o3
z6 = w61*o1+w62*o2+w63*o3
z4,z5,z6分别代表结点4,5,6的输出,01,02,03代表是结点1,2,3往后传的输入.
那么我们可以经过softmax函数得到
好了,我们的重头戏来了,怎么根据求梯度,然后利用梯度下降方法更新梯度!
要使用梯度下降,肯定需要一个损失函数,这里我们使用交叉熵作为我们的损失函数,为什么使用交叉熵损失函数,不是这篇文章重点,后面有时间会单独写一下为什么要用到交叉熵函数(这里我们默认选取它作为损失函数)
交叉熵函数形式如下:
其中y代表我们的真实值,a代表我们softmax求出的值。i代表的是输出结点的标号!在上面例子,i就可以取值为4,5,6三个结点(当然我这里只是为了简单,真实应用中可能有很多结点)
现在看起来是不是感觉复杂了,居然还有累和,然后还要求导,每一个a都是softmax之后的形式!
但是实际上不是这样的,我们往往在真实中,如果只预测一个结果,那么在目标中只有一个结点的值为1,比如我认为在该状态下,我想要输出的是第四个动作(第四个结点),那么训练数据的输出就是a4 = 1,a5=0,a6=0,哎呀,这太好了,除了一个为1,其它都是0,那么所谓的求和符合,就是一个幌子,我可以去掉啦!
为了形式化说明,我这里认为训练数据的真实输出为第j个为1,其它均为0!
那么Loss就变成了,累和已经去掉了,太好了。现在我们要开始求导数了!
我们在整理一下上面公式,为了更加明白的看出相关变量的关系:
其中,那么形式变为
那么形式越来越简单了,求导分析如下:
参数的形式在该例子中,总共分为w41,w42,w43,w51,w52,w53,w61,w62,w63.这些,那么比如我要求出w41,w42,w43的偏导,就需要将Loss函数求偏导传到结点4,然后再利用链式法则继续求导即可,举个例子此时求w41的偏导为:
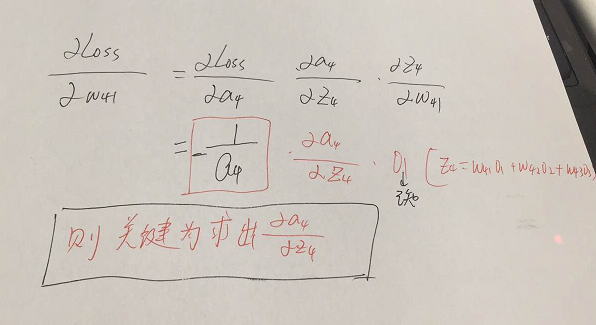
w51.....w63等参数的偏导同理可以求出,那么我们的关键就在于Loss函数对于结点4,5,6的偏导怎么求,如下:
这里分为俩种情况:
一:当选定的节点(我们要求误差项的节点)是我们期望的节点,则它的误差项为:
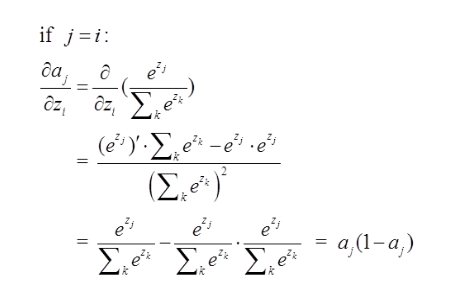
那么由上面求导结果再乘以交叉熵损失函数求导
,它的导数为
,与上面
相乘为
(形式非常简单,这说明我只要正向求一次得出结果,然后反向传梯度的时候,只需要将它结果减1即可,后面还会举例子!)那么我们可以得到Loss对于4结点的偏导就求出了了(这里假定4是我们的预计输出)
二:当节点不上真正的期望节点,则它的误差项(梯度)求法如下:
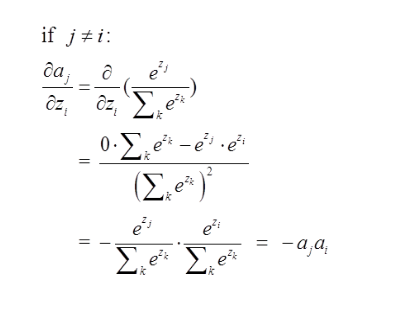
那么由上面求导结果再乘以交叉熵损失函数求导
,它的导数为
,与上面
相乘为
(形式非常简单,这说明我只要正向求一次得出结果,然后反向传梯度的时候,只需要将它结果保存即可,后续例子会讲到)这里就求出了除4之外的其它所有结点的偏导,然后利用链式法则继续传递过去即可!我们的问题也就解决了!
下面我举个例子来说明为什么计算会比较方便,给大家一个直观的理解
举个例子,通过若干层的计算,最后得到的某个训练样本的向量的分数是[ 2, 3, 4 ],
那么经过softmax函数作用后概率分别就是=[
,,
] = [0.0903,0.2447,0.665],如果这个样本正确的分类是第二个的话,那么计算出来的偏导就是[0.0903,0.2447-1,0.665]=[0.0903,-0.7553,0.665],是不是非常简单!!然后再根据这个进行back propagation就可以了。
深度学习(四) softmax函数的更多相关文章
- 从极大似然估计的角度理解深度学习中loss函数
从极大似然估计的角度理解深度学习中loss函数 为了理解这一概念,首先回顾下最大似然估计的概念: 最大似然估计常用于利用已知的样本结果,反推最有可能导致这一结果产生的参数值,往往模型结果已经确定,用于 ...
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 【深度学习】softmax回归——原理、one-hot编码、结构和运算、交叉熵损失
1. softmax回归是分类问题 回归(Regression)是用于预测某个值为"多少"的问题,如房屋的价格.患者住院的天数等. 分类(Classification)不是问&qu ...
- 深度学习之softmax回归
前言 以下内容是个人学习之后的感悟,转载请注明出处~ softmax回归 首先,我们看一下sigmod激活函数,如下图,它经常用于逻辑回归,将一个real value映射到(0, ...
- go微服务框架go-micro深度学习(四) rpc方法调用过程详解
上一篇帖子go微服务框架go-micro深度学习(三) Registry服务的注册和发现详细解释了go-micro是如何做服务注册和发现在,服务端注册server信息,client获取server的地 ...
- 深度学习TensorFlow常用函数
tensorflow常用函数 TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU.一般你不需要显式指定使用 CPU 还是 GPU, Tensor ...
- 深度学习四从循环神经网络入手学习LSTM及GRU
循环神经网络 简介 循环神经网络(Recurrent Neural Networks, RNN) 是一类用于处理序列数据的神经网络.之前的说的卷积神经网络是专门用于处理网格化数据(例如一个图像)的神经 ...
- 深度学习:Sigmoid函数与损失函数求导
1.sigmoid函数 sigmoid函数,也就是s型曲线函数,如下: 函数: 导数: 上面是我们常见的形式,虽然知道这样的形式,也知道计算流程,不够感觉并不太直观,下面来分析一下. 1.1 ...
- 深度学习中的batch_size,iterations,epochs等概念的理解
在自己完成的几个有关深度学习的Demo中,几乎都出现了batch_size,iterations,epochs这些字眼,刚开始我也没在意,觉得Demo能运行就OK了,但随着学习的深入,我就觉得不弄懂这 ...
- go微服务框架go-micro深度学习-目录
go微服务框架go-micro深度学习(一) 整体架构介绍 go微服务框架go-micro深度学习(二) 入门例子 go微服务框架go-micro深度学习(三) Registry服务的注册和发现 go ...
随机推荐
- UI 设计概念介绍
UI 设计概念介绍 http://www.slideshare.net/tedzhaoxa/ui-and-ue-design-basic
- [C#] ??雙問號的意思及用法
int? x = null; int y = x ?? -1; 上面二行中,第一行是將x變數放入null,為什麼int能放null,可以參考另一篇文章http://charleslin74.pixne ...
- Solr相似度算法二:BM25Similarity
BM25算法的全称是 Okapi BM25,是一种二元独立模型的扩展,也可以用来做搜索的相关度排序. Sphinx的默认相关性算法就是用的BM25.Lucene4.0之后也可以选择使用BM25算法(默 ...
- 安装git出现templates not found的问题
背景 goods.api需要在新机器上部署,该机器上没有安装git,需要安装git,查询git版本为2.4.5-1.el6 ,使用yum 一顿安装后,执行git clone命令告知warning: t ...
- 使用NPOI时ICSharpCode.SharpZipLib版本冲突问题解决
系统原来引用的ICSharpCode.SharpZipLib是0.84版本的, 添加了2.3版本的NPOI引用后,报版本冲突错误,因为NPOI用的ICSharpCode.SharpZipLib是0.8 ...
- WPF 降低.net framework到4.0
1. 问题背景 由于xp系统上面最高只能安装.net framework 4.0,所以公司项目需要将原来项目的.net framework版本降低到4.0,具体的降版本很简单,只要把项目属性中的目标框 ...
- 虚拟化安全 sandbox 技术分析
原文链接:https://cloud.tencent.com/developer/news/215218 前言: libvirt-4.3搭配qemu-2.12使用,如果使用默认的编译选项,可能会让qe ...
- Neutron FWaaS 原理
理解概念 Firewall as a Service(FWaaS)是 Neutron 的一个高级服务.用户可以用它来创建和管理防火墙,在 subnet 的边界上对 layer 3 和 layer 4 ...
- linux进程管理(一)
进程介绍 程序和进程 程序是为了完成某种任务而设计的软件,比如OpenOffice是程序.什么是进程呢?进程就是运行中的程序. 一个运行着的程序,可能有多个进程. 比如自学it网所用的WWW服务器是a ...
- soapui加载天气预报接口报错Characters larger than 4 bytes are not supported: byte 0xb1 implies a length of more than 4 byte的解决办法
soapui加载天气预报接口时报错如下: Error loading [http://www.webxml.com.cn/WebServices/WeatherWebService.asmx?wsdl ...