scrapyd的安装
.安装
pip3 install scrapyd
二.配置
安装完毕之后,需要新建一个配置文件/etc/scrapyd/scrapyd.conf,Scrapyd在运行的时候会读取此配置文件。
在Scrapyd 1.2版本之后,不会自动创建该文件,需要我们自行添加。
首先,执行如下命令新建文件:
mkdir /etc/scrapyd
vi /etc/scrapyd/scrapyd.conf
接着写入如下内容:
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root [services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
中之一是max_proc_per_cpu官方默认为4,即一台主机每个CPU最多运行4个Scrapy任务,在此提高为10。另外一个是bind_address,默认为本地127.0.0.1,在此修改为0.0.0.0,以使外网可以访问。
三.后台运行
Scrapyd是一个纯Python项目,这里可以直接调用它来运行。为了使程序一直在后台运行,Linux和Mac可以使用如下命令:
(scrapyd > /dev/null &)
这样Scrapyd就会在后台持续运行了,控制台输出直接忽略。当然,如果想记录输出日志,可以修改输出目标,如
(scrapyd > ~/scrapyd.log &)
时会将Scrapyd的运行结果输出到~/scrapyd.log文件中。
当然也可以使用screen、tmux、supervisor等工具来实现进程守护。
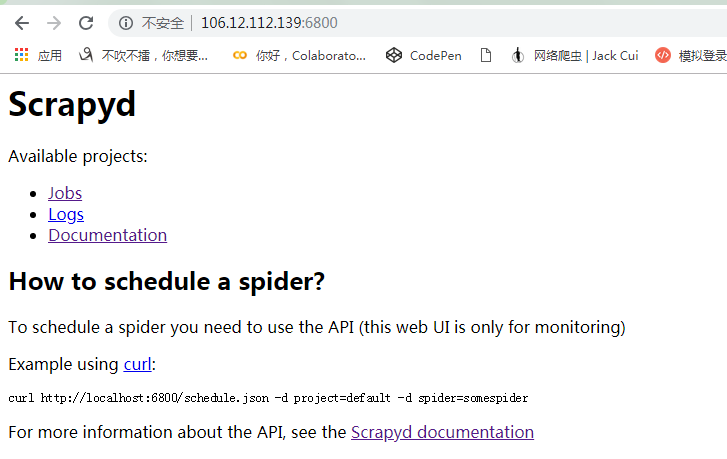
运行之后,便可以在浏览器的6800端口访问Web UI了,从中可以看到当前Scrapyd的运行任务、日志等内容,如图所示。

就需要回退版本
Scrapy==1.6.0 Twisted==18.9.0
五.访问认证
配置完成后,Scrapyd和它的接口都是可以公开访问的。如果想配置访问认证的话,可以借助于Nginx做反向代理,这里需要先安装Nginx服务器。
yum install nginx
然后修改Nginx的配置文件nginx.conf,增加如下配置:
http {
server {
listen 6801;
location / {
proxy_pass http://127.0.0.1:6800/;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
}
这里使用的用户名和密码配置放置在/etc/nginx/conf.d目录下,我们需要使用htpasswd命令创建。例如,创建一个用户名为admin的文件,命令如下:
htpasswd -c .htpasswd admin
接着就会提示我们输入密码,输入两次之后,就会生成密码文件。此时查看这个文件的内容:
cat .htpasswd
admin:5ZBxQr0rCqwbc
配置完成后,重启一下Nginx服务,运行如下命令:
nginx -s reload
这样就成功配置了Scrapyd的访问认证了。
六.接口
import requests
import json baseUrl ='http://127.0.0.1:6800/'
daemUrl ='http://127.0.0.1:6800/daemonstatus.json'
listproUrl ='http://127.0.0.1:6800/listprojects.json'
listspdUrl ='http://127.0.0.1:6800/listspiders.json?project=%s'
listspdvUrl= 'http://127.0.0.1:6800/listversions.json?project=%s'
listjobUrl ='http://127.0.0.1:6800/listjobs.json?project=%s'
delspdvUrl= 'http://127.0.0.1:6800/delversion.json' #http://127.0.0.1:6800/daemonstatus.json
#查看scrapyd服务器运行状态
r= requests.get(daemUrl)
print '1.stats :\n %s \n\n' %r.text #http://127.0.0.1:6800/listprojects.json
#获取scrapyd服务器上已经发布的工程列表
r= requests.get(listproUrl)
print '1.1.listprojects : [%s]\n\n' %r.text
if len(json.loads(r.text)["projects"])>0 :
project = json.loads(r.text)["projects"][0] #http://127.0.0.1:6800/listspiders.json?project=myproject
#获取scrapyd服务器上名为myproject的工程下的爬虫清单
listspd=listspd % project
r= requests.get(listspdUrl)
print '2.listspiders : [%s]\n\n' %r.text
if json.loads(r.text).has_key("spiders")>0 :
spider =json.loads(r.text)["spiders"][0] #http://127.0.0.1:6800/listversions.json?project=myproject
##获取scrapyd服务器上名为myproject的工程下的各爬虫的版本
listspdvUrl=listspdvUrl % project
r = requests.get(listspdvUrl)
print '3.listversions : [%s]\n\n' %rtext
if len(json.loads(r.text)["versions"])>0 :
version = json.loads(r.text)["versions"][0] #http://127.0.0.1:6800/listjobs.json?project=myproject
#获取scrapyd服务器上的所有任务清单,包括已结束,正在运行的,准备启动的。
listjobUrl=listjobUrl % proName
r=requests.get(listjobUrl)
print '4.listjobs : [%s]\n\n' %r.text #schedule.json
#http://127.0.0.1:6800/schedule.json -d project=myproject -d spider=myspider
#启动scrapyd服务器上myproject工程下的myspider爬虫,使myspider立刻开始运行,注意必须以post方式
schUrl = baseurl + 'schedule.json'
dictdata ={ "project":project,"spider":spider}
r= reqeusts.post(schUrl, json= dictdata)
print '5.1.delversion : [%s]\n\n' %r.text #http://127.0.0.1:6800/delversion.json -d project=myproject -d version=r99'
#删除scrapyd服务器上myproject的工程下的版本名为version的爬虫,注意必须以post方式
delverUrl = baseurl + 'delversion.json'
dictdata={"project":project ,"version": version }
r= reqeusts.post(delverUrl, json= dictdata)
print '6.1.delversion : [%s]\n\n' %r.text #http://127.0.0.1:6800/delproject.json -d project=myproject
#删除scrapyd服务器上myproject工程,注意该命令会自动删除该工程下所有的spider,注意必须以post方式
delProUrl = baseurl + 'delproject.json'
dictdata={"project":project }
r= reqeusts.post(delverUrl, json= dictdata)
print '6.2.delproject : [%s]\n\n' %r.text
scrapyd的安装的更多相关文章
- 芝麻HTTP:Scrapyd的安装
Scrapyd是一个用于部署和运行Scrapy项目的工具,有了它,你可以将写好的Scrapy项目上传到云主机并通过API来控制它的运行. 既然是Scrapy项目部署,基本上都使用Linux主机,所以本 ...
- scrapyd的安装和scrapyd-client
1.创建虚拟环境 ,虚拟环境名为sd mkvirtualenv sd #方便管理 2. 安装 scrapyd pip3 install scrapyd 3. 配置 mkdir /etc/scrapy ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- Scrapyd+Gerapy部署Scrapy爬虫进行可视化管理
Scrapy是一个流行的爬虫框架,利用Scrapyd,可以将其部署在远程服务端运行,并通过命令对爬虫进行管理,而Gerapy为我们提供了精美的UI,可以在web页面上直接点击操作,管理部署在scrap ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 五十一 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:https://github.com/scrapy/scrapyd 建议安装 pip3 install s ...
- scrapy——8 scrapyd使用
scrapy——8 scrapyd使用 什么是scrapyd 怎么安装scrapyd 如何使用scrapyd--运行scrapyd 如何使用scrapyd--配置scrapy.cfg 如何使用s ...
- scrapy-redis(七):部署scrapy
一般我们写好scrapy爬虫,如果需要启动的话,需要进入scrapy项目的根目录,然后运行以下命令: scrapy crawl {spidername} 这样我们就可以在终端查看到爬虫信息了.但爬虫运 ...
- scrapy项目部署
什么是scrapyd Scrapyd是部署和运行Scrapy.spider的应用程序.它使您能够使用JSON API部署(上传)您的项目并控制其spider. 特点: 可以避免爬虫源码被看到. 有版本 ...
随机推荐
- CodeForces 687B Remainders Game(数学,最小公倍数)
题意:给定 n 个数,一个数 k,然后你知道一个数 x 取模这个 n 个的是几,最后问你取模 k,是几. 析:首先题意就看了好久,其实并不难,我们只要能从 n 个数的最小公倍数是 k的倍数即可,想想为 ...
- python使用git进行版本控制2
对上一次的readme文件进行修改 现在,运行git status命令看看结果 $ git statusOn branch masterChanges not staged for commit: ...
- swift po 实现动态按钮2
// // ButtonViewController.swift // PopInstall // // Created by su on 15/12/11. // Copyright © 2 ...
- VC 调试技术与异常(错误)处理 VC 调试技术与异常(错误)处理
调试技术与异常(错误)处理 (1) 转载自 52PK游戏论坛 跟踪与中间过程输出 也许一个开发人员一半以上的时间都是在面对错误,所以好的调试/查错方法(工具)会减轻我们工作的负担,也可以让枯燥的D ...
- Oracle数据泵导出导入(expdp/impdp)
一.创建表空间 create tablespace atp logging datafile 'D:\oracle\oradata\orcl\atp.dbf' size 50m autoextend ...
- FusionCharts的使用方法 - 公司所用的flash式的图像统计工具
我们公司一直用这个图表统计, 最近整理了一下相关文档,提供大家学习. 首先可以看看 http://www.cnblogs.com/xuhongfei/archive/2013/04/12/301688 ...
- layui select 禁止点击
$('select').attr('disabled', 'disabled'); form.render('select'); 注意事项: 1. 必须写 layui.use([form]) 2. 先 ...
- “全栈2019”Java第一百零三章:匿名内部类详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- HTTP请求报文支持的各种方法
常见的HTTP方法如下: 1.GET GET是最常用的方法.通常用于请求服务器发送某个资源. 2.HEAD HEAD与GET的行为类似,但服务器在响应中只返回首部,不会返回实体的部分.这就允许客户端在 ...
- 记一次MBR锁机病毒分析
有一天,在机缘巧合之下我获得了一个锁机软件(是多巧合阿喂!),然后兴高采烈的把它拖入了虚拟机里蹂躏(>_<!). 很巧,软件有虚拟机检测... Emmmm好吧,随便过一下... 我用的虚拟 ...