图的基础---关键路径理解和实现(Java)
引言
之前所说的拓扑排序是为了解决一个工程能否顺利进行的问题。但在生活中,我们还会经常遇到如何解决工程完成需要的最短时间问题。
举个例子,我们需要制作一台汽车,我们需要先造各种各样的零件,然后进行组装,这些零件基本上都是在流水线上同时成产的。加入造一个轮子需要0.5天的时间,造一个发动机需要3天的时间,造一个车底盘需要2天的时间,造一个外壳需要2天的时间,其他零部件需要2天的时间,全部零部件集中到一个地方需要0.5天的时间,组装成车需要2天的时间,那么请问汽车厂造一辆车,最短需要多少时间。
因为这些零部件都是分别在流水线上同时生产的,也就是说在生产发动机的这3天当中,可能已经生产了6个轮子,1.5个外壳,1.5个车底盘,而组装是在这些零部件都生产好之后才能进行,因此最短的时间就是零件生产时间最长的发动机3天+集中零部件0.5天+组成成车2天,以供需要5.5天完成一辆车的生产。
所以,我们如果对一个流程获得最短时间,就需要分析它的拓扑关系,找到最关键的流程,这个流程的时间就是最短的时间。
AOE网的定义
在一个表示工程的带权有向图中,用顶点表示时间,用有向边表示活动,用边上的权值表示活动的持续时间,这种有向图的边表示活动的网,我们称之为AOE网。
把AOE网中没有入边的顶点称之为始点或源点,没有出边的顶点称之为终点或汇点。
摘自:《大话数据结构》
关键路径的定义
我们把路径上各个活动所持续的时间之和称之为路径长度,从源点到汇点具有最大的长度的路径叫做关键路径,在关键路径上的活动叫关键活动。
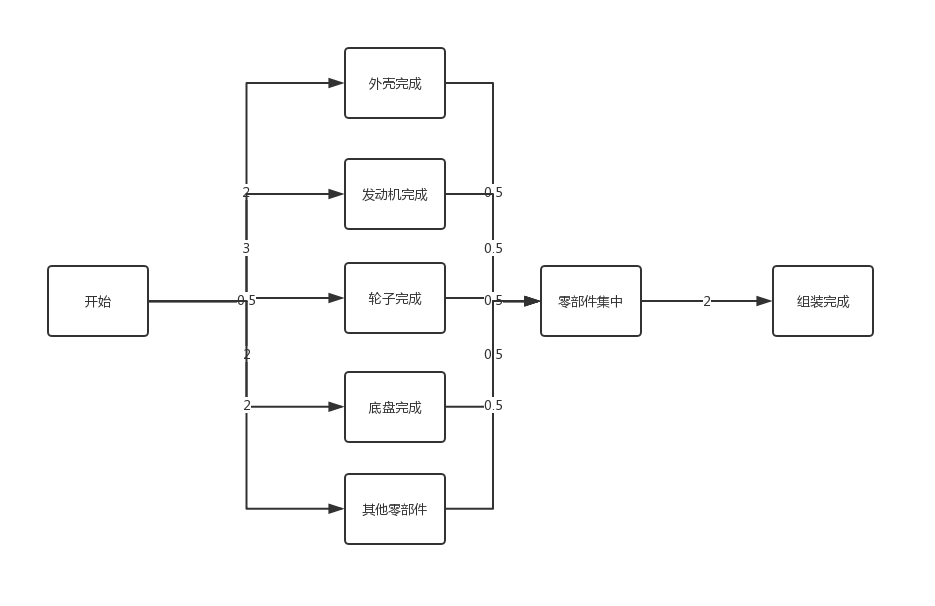
对上面的AOE网来说,其关键路径就是:开始->发动机完成->部件集中->组装完成。路径长度为5.5。
关键路径算法原理
对于一个活动来说,有活动的最早开始时间和最晚开始时间,比较这个活动的最早开始时间和最晚开始时间,如果最早开始时间和最晚开始时间相等,那么就意味着该活动是关键活动,活动间的路径为关键路径。如果不相等,那么这个活动就不是关键活动。
名词解释
- 事件的最早发生时间etv:即顶点vkv_kvk的最早发生时间
- 事件的最晚发生时间ltv:即顶点vkv_kvk的最晚发生时间,也就是每个顶点对应的事件最晚需要开始的时间,超过此时间将会延误整个工期。
- 活动的最早开工时间ete:即弧aka_kak的最早发生时间
- 活动的最晚开工时间lte:即弧aka_kak的最晚发生时间,也就是不推迟工期的最晚开工时间。
算法分析
假设起点为v0v_0v0,则我们从v0v_0v0到viv_ivi的最长路径的长度为顶点(事件)viv_ivi的最早发生时间。
同时viv_ivi的最早发生时间也是所有以viv_ivi为尾的弧所表示的活动的最早开工时间(即ete),
定义活动最晚开工时间表示在不会延误所有工期(即lte)。通过根据ete[k]是否与lte[k]相等来判断aka_kak是关键活动。
同时,因为我们采用邻接表来存储AOE网,并且对于表示活动的每条边都具有活动的持续时间(即该边的权重),所以,我们需要修改边表节点,增加一个weight来存储弧的权值。
首先我们要求顶点vkv_kvk即求etv[k]的最早发生时间,公式:
etv[k]={0,当k=0时max[etv[i]+len<vi,vk>],当k不等于0且<vi,vk>属于P[k]时etv[k]=
\left \{\begin{array}{cc}
0, &当k=0时\\
max[etv[i]+len<vi, vk>], & 当k不等于0且<vi, vk>属于P[k]时
\end{array}\right.
etv[k]={0,max[etv[i]+len<vi,vk>],当k=0时当k不等于0且<vi,vk>属于P[k]时
在计算ltv时,其实就是对拓扑序列倒过来进行,所以我们可以计算顶点vkv_kvk即求ltv[k]的最晚发生时间。公式:
ltv[k]={etv[k],当k=n−1时min[ltv[j]−len<vk,vj>],当k<n−1且<vk,vj>属于S[k]时ltv[k]=
\left \{\begin{array}{cc}
etv[k], &当k=n-1时\\
min[ltv[j]-len<vk, vj>], & 当k<n-1且<vk, vj>属于S[k]时
\end{array}\right.
ltv[k]={etv[k],min[ltv[j]−len<vk,vj>],当k=n−1时当k<n−1且<vk,vj>属于S[k]时
这两个公式怎么理解呢
我的理解是,对于事件vkv_kvk的最早发生时间,表现为以vkv_kvk为弧头,viv_ivi为弧尾的其他所有弧(注意:i的值可能没有,表示vkv_kvk的入度为0;可能为n,表示vkv_kvk的入度为n)的活动持续时间+viv_ivi的最早开工时间列表中的最大值。以上面的流程图为例,零部件集中这项事件只有等生产时间最长的发动机造好之后才能进行。
对于vkv_kvk的最晚发生时间,表现为事件vjv_jvj的最晚发生时间 减去 以vkv_kvk为弧尾,vjv_jvj为弧头的其他所有弧(注意:j的值可能没有,表示vkv_kvk的出度为0;可能为n,表示vkv_kvk的出度为n)的活动持续时间。
求关键路径的步骤
- 根据图的描述建立该图的邻接表
- 从源点v0v_0v0出发,根据拓扑序列算法求源点到汇点每个顶点的etv,如果得到的拓扑序列个数小于网的顶点个数,则该网中存在环,无关键路径,结束程序。
- 从汇点vnv_nvn出发,且ltv[n-1]=etv[n-1],按照逆拓扑序列,计算每个顶点的ltv。
- 根据每个顶点的etv和ltv求每条弧的ete和lte,若ete=lte,说明该活动是关键活动。
代码实现
示例AOE网:
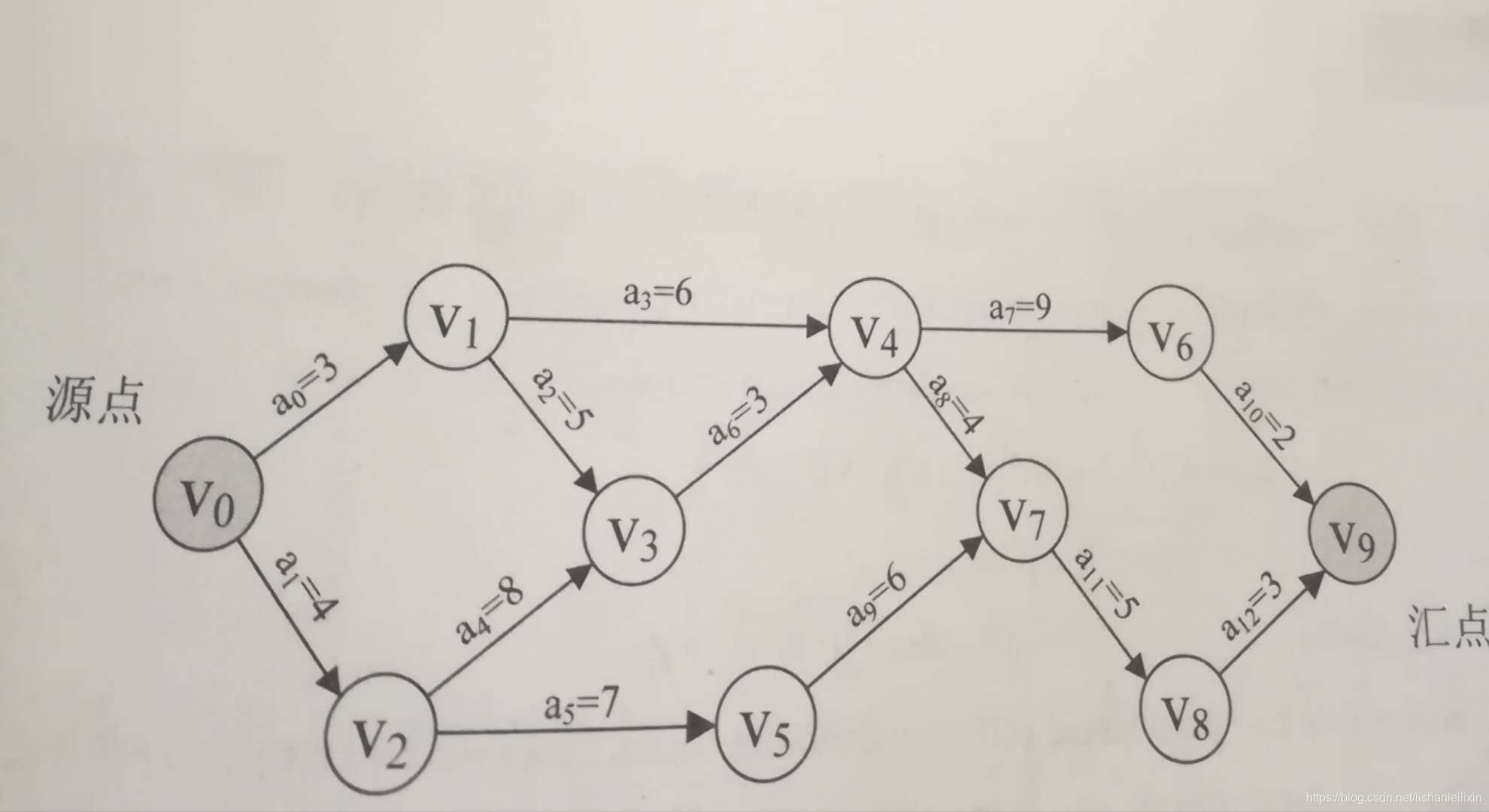
该网的邻接表结构:
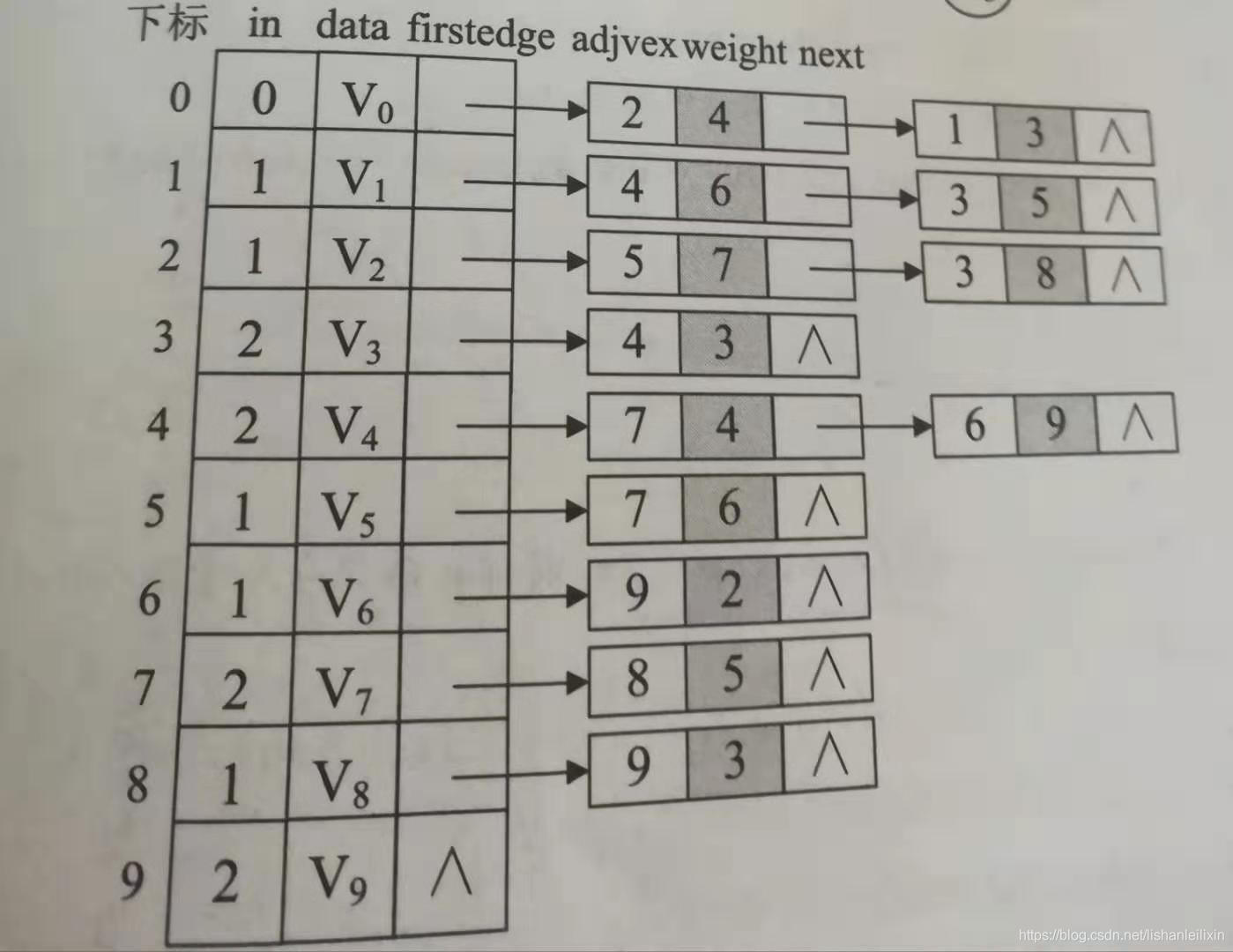
数据结构
边表节点:
public class EdgeNode {
public int adjevex;
public int weight;
public EdgeNode next;
public EdgeNode(int adjevex, EdgeNode next) {
this.adjevex = adjevex;
this.next = next;
}
public EdgeNode(int adjevex, int weight, EdgeNode next) {
this.adjevex = adjevex;
this.weight = weight;
this.next = next;
}
}
顶点节点:
public class VertexNode {
public int in;
public Object data;
public EdgeNode firstedge;
public VertexNode(Object data, int in, EdgeNode firstedge) {
this.data = data;
this.in = in;
this.firstedge = firstedge;
}
}
通过拓扑排序求得etv
public boolean ToplogicalSort() {
EdgeNode e;
int k, gettop;
int count = 0;
etv = new int[adjList.length];
for (int i = 0; i < adjList.length; i++) {
if(adjList[i].in == 0) {
stack.push(i);
}
}
for (int i = 0; i < adjList.length; i++) {
etv[i] = 0;
}
while(!stack.isEmpty()) {
gettop = (int) stack.pop();
count++;
stack2.push(gettop);
for (e = adjList[gettop].firstedge; e != null; e = e.next) {
k = e.adjevex;
if((--adjList[k].in) == 0) {
stack.push(k);
}
if(etv[gettop] + e.weight > etv[k]) {
etv[k] = etv[gettop] + e.weight;
}
}
}
if(count < adjList.length) return false;
else return true;
}
关键路径算法:
public void CriticalPath() {
EdgeNode e;
int gettop, k, j;
int ete, lte;
if(!this.ToplogicalSort()) {
System.out.println("该网中存在回路!");
return;
}
ltv = new int[adjList.length];
for (int i = 0; i < adjList.length; i++) {
ltv[i] = etv[etv.length - 1];
}
while(!stack2.isEmpty()) {
gettop = (int) stack2.pop();
for(e = adjList[gettop].firstedge; e != null; e = e.next) {
k = e.adjevex;
if(ltv[k] - e.weight < ltv[gettop]) {
ltv[gettop] = ltv[k] - e.weight;
}
}
}
for (int i = 0; i < adjList.length; i++) {
for(e = adjList[i].firstedge; e != null; e = e.next) {
k = e.adjevex;
ete = etv[i];
lte = ltv[k] - e.weight;
if(ete == lte) {
System.out.print("<" + adjList[i].data + "," + adjList[k].data + "> length: " + e.weight + ",");
}
}
}
}
完整代码:
public class CriticalPathSort {
int[] etv, ltv;
Stack stack = new Stack(); //存储入度为0的顶点,便于每次寻找入度为0的顶点时都遍历整个邻接表
Stack stack2 = new Stack(); //将顶点序号压入拓扑序列的栈
static VertexNode[] adjList;
public boolean ToplogicalSort() {
EdgeNode e;
int k, gettop;
int count = 0;
etv = new int[adjList.length];
for (int i = 0; i < adjList.length; i++) {
if(adjList[i].in == 0) {
stack.push(i);
}
}
for (int i = 0; i < adjList.length; i++) {
etv[i] = 0;
}
while(!stack.isEmpty()) {
gettop = (int) stack.pop();
count++;
stack2.push(gettop);
for (e = adjList[gettop].firstedge; e != null; e = e.next) {
k = e.adjevex;
if((--adjList[k].in) == 0) {
stack.push(k);
}
if(etv[gettop] + e.weight > etv[k]) {
etv[k] = etv[gettop] + e.weight;
}
}
}
if(count < adjList.length) return false;
else return true;
}
public void CriticalPath() {
EdgeNode e;
int gettop, k, j;
int ete, lte;
if(!this.ToplogicalSort()) {
System.out.println("该网中存在回路!");
return;
}
ltv = new int[adjList.length];
for (int i = 0; i < adjList.length; i++) {
ltv[i] = etv[etv.length - 1];
}
while(!stack2.isEmpty()) {
gettop = (int) stack2.pop();
for(e = adjList[gettop].firstedge; e != null; e = e.next) {
k = e.adjevex;
if(ltv[k] - e.weight < ltv[gettop]) {
ltv[gettop] = ltv[k] - e.weight;
}
}
}
for (int i = 0; i < adjList.length; i++) {
for(e = adjList[i].firstedge; e != null; e = e.next) {
k = e.adjevex;
ete = etv[i];
lte = ltv[k] - e.weight;
if(ete == lte) {
System.out.print("<" + adjList[i].data + "," + adjList[k].data + "> length: " + e.weight + ",");
}
}
}
}
public static EdgeNode getAdjvex(VertexNode node) {
EdgeNode e = node.firstedge;
while(e != null) {
if(e.next == null) break;
else
e = e.next;
}
return e;
}
public static void main(String[] args) {
int[] ins = {0, 1, 1, 2, 2, 1, 1, 2, 1, 2};
int[][] adjvexs = {
{2, 1},
{4, 3},
{5, 3},
{4},
{7, 6},
{7},
{9},
{8},
{9},
{}
};
int[][] widths = {
{4, 3},
{6, 5},
{7, 8},
{3},
{4, 9},
{6},
{2},
{5},
{3},
{}
};
adjList = new VertexNode[ins.length];
for (int i = 0; i < ins.length; i++) {
adjList[i] = new VertexNode("V"+i, ins[i],null);
if(adjvexs[i].length > 0) {
for (int j = 0; j < adjvexs[i].length; j++) {
if(adjList[i].firstedge == null)
adjList[i].firstedge = new EdgeNode(adjvexs[i][j], widths[i][j], null);
else {
getAdjvex(adjList[i]).next = new EdgeNode(adjvexs[i][j], widths[i][j], null);
}
}
}
}
CriticalPathSort c = new CriticalPathSort();
c.CriticalPath();
}
}
注意:这个例子中只有唯一一条关键路径,这并不表示不存在多条关键路径的有向无环图。如果是多条关键路径,则单是提高一条关键路径上的关键活动速度并不能导致整个工期缩短,而必须提高同时在几条关键路径上的活动的速度。
图的基础---关键路径理解和实现(Java)的更多相关文章
- Java基础之理解Annotation(与@有关,即是注释)
Java基础之理解Annotation 一.概念 Annontation是Java5开始引入的新特征.中文名称一般叫注解.它提供了一种安全的类似注释的机制,用来将任何的信息或元数据(metadata) ...
- 零基础的人怎么学习Java
编程语言Java,已经21岁了.从1995年诞生以来,就一直活跃于企业中,名企应用天猫,百度,知乎......都是Java语言编写,就连现在使用广泛的XMind也是Java编写的.Java应用的广泛已 ...
- java基础知识(四)java内存机制
Java内存管理:深入Java内存区域 上面的文章对于java的内存管理机制讲的非常细致,在这里我们只是为了便于后面内容的理解,对java内存机制做一个简单的梳理. 程序计数器:当前线程所执行的字节码 ...
- Java基础:三步学会Java Socket编程
Java基础:三步学会Java Socket编程 http://tech.163.com 2006-04-10 09:17:18 来源: java-cn 网友评论11 条 论坛 第一步 ...
- 从零基础到拿到网易Java实习offer,谈谈我的学习经验
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 从零基础到拿到网易Java实习offer,我做对了哪些事
作为一个非科班小白,我在读研期间基本是自学Java,从一开始几乎零基础,只有一点点数据结构和Java方面的基础,到最终获得网易游戏的Java实习offer,我大概用了半年左右的时间.本文将会讲到我在这 ...
- 076 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 01 初识面向对象 01 Java面向对象导学
076 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 01 初识面向对象 01 Java面向对象导学 本文知识点:Java面向对象导学 说明:因为时间紧张,本人 ...
- Atitit 深入理解命名空间namespace java c# php js
Atitit 深入理解命名空间namespace java c# php js 1.1. Namespace还是package1 1.2. import同时解决了令人头疼的include1 1.3 ...
- [原]Java修炼 之 基础篇(二)Java语言构成
上次的博文中Java修炼 之 基础篇(一)Java语言特性我们介绍了一下Java语言的几个特性,今天我们介绍一下Java语言的构成. 所谓的Java构成,主要是指Java运行环境的组成, ...
随机推荐
- RabbitMQ学习在windows下安装配置
RabbitMQ学习一. 在windows下安装配置 1.下载并安装erlang,http://www.erlang.org/download.html,最新版是R15B01(5.9.1).由于我机器 ...
- php解决时间超过2038年
问题 超过2038年的时间 php怎么处理? echo date('Y-m-d',2147483647); //date函数能处理的最大整数2147483647 ->2038-01-19 就是2 ...
- jmeter 计数器 (可自动生成新数字、注册专用)
1.打开jmeter,创建好线程组后,添加计数器 2.设置计数器 3.添加HTTP请求,验证所设置的计数器 4.填写对应参数 5.添加查看结果树,查看结果 6.修改一下线程属性 7.跑一下,看下结果就 ...
- 23 DesignPatterns学习笔记:C++语言实现 --- 1.4 Builder
23 DesignPatterns学习笔记:C++语言实现 --- 1.4 Builder 2016-07-21 (www.cnblogs.com/icmzn) 模式理解
- Java垃圾收集调优实战
1 资料 JDK5.0垃圾收集优化之--Don't Pause(花钱的年华) 编写对GC友好,又不泄漏的代码(花钱的年华) JVM调优总结 JDK 6所有选项及默认值 2 GC日志打印 GC调 ...
- android AlertDialog.Builder(Context context)换行
今天无意中发现AlertDialog的 setMessage(String)的换行问题,很多人都说\n可以,不过的却原来就在java里面写好的是可以换行 ,但是如果这个string是在网页或者是其地方 ...
- 遇到了IE10不能登录的问题,很早就有解决方案了
1..net 2.0 的程序,请打开项目,打开vs开发环境的工具菜单下的 Package Manager Console ,中文名:程序包管理控制台,在打开的控制台中输入如下命令:Install-P ...
- jdk-7u40-windows-i586的安装
1.预备知识: i586 指的是windows 32bit版本 Oracle.微软.IBM这些大佬们最“贵族”了-----他们都很喜欢 C盘 2.关键 JDK必须装在C盘目录下,才能在命令行下正确运行 ...
- Android / iOS 招聘
1. 面试题 https://github.com/ChenYilong/iOSInterviewQuestions 2. 一些不错的idea CDI - Développeur iOS/Androi ...
- python中的MRO和C3算法
一. 经典类和新式类 1.python多继承 在继承关系中,python子类自动用友父类中除了私有属性外的其他所有内容.python支持多继承.一个类可以拥有多个父类 2.python2和python ...