1.3:Render Pipeline and GPU Pipeline
文章著作权归作者所有。转载请联系作者,并在文中注明出处,给出原文链接。
本系列原更新于作者的github博客,这里给出链接。
在学习SubShader之前,我们有必要对 Render Pipeline (渲染流水线)和 GPU Pipeline (图形硬件流水线)有一个比较细致的了解。这是一篇干货,内容主要参考了《Unity Shader入门精要》、《Real-Time Rendering》以及众多博客,其中加入了一些个人的见解,里面涉及到的知识能够为我们以后的Shader编写提供指导。有错误的地方欢迎联系指正。
什么是流水线
在第0章我们简单地提到了渲染流水线的大概过程。但是,只知道大概过程会给我们以后的学习带来疑惑,所以我们还是要熟悉整个渲染的流程。在这之前,我们首先要清楚Pipeline(流水线)是什么。我们都知道,工厂的生产都是基于流水线的,那为什么我们会选择使用这种模式呢?我们先回到传统模式,假设一件商品需要经过四道工序完成,而这四道工序都由同一个工人去完成。显然,工序是拓扑有序的,也就是说,我们必须严格按照1-2-3-4的顺序进行,在计算机上,这对应着串行计算,这也就意味着,上一道工序如果没有完成,我们便永远无法开展下一步的工作,这无疑是低效的。在注重效率的现代社会,最重要的协作方式肯定是各司其职,所有人在同一个时间段完成不同的工作,再把各自的阶段产物递交给下一道工序的执行者,这对应着计算机的并行计算。因为各自负责了自己擅长的工作,在时间上又是同时开展的,效率显然远远高过传统方式。值得庆幸的是,GPU(图形显卡)的特长正是并行计算。
渲染流水线是怎样运作的
了解了流水线模式的好处之后,可能会有这样的疑问:为什么渲染也需要用到流水线呢?这是因为渲染工作也是由若干阶段组成的。接下来我们将深入流水线中看看渲染的实质。在《Real-Time Rendering》一书中,作者把渲染流程分为了三个概念阶段,分别是Application Stage(应用阶段)、Geometry Stage(几何阶段)、Rasterizer Stage(光栅化阶段),这也是目前被广泛认可的一种描述。
应用阶段
在应用阶段,我们需要准备好场景数据,如视角位置,光照设置,但最重要的输出是Render Primitives(渲染图元),这一阶段在CPU中完成,对应到Unity中就是我们需要在场景中摆放Light,设置Main Camera,摆放游戏物体,设置好所有的参数。
几何阶段
从上一阶段获取到图元信息后,几何阶段会进行所有和几何相关的工作,决定哪些图元需要被绘制,需要怎样绘制,在哪里绘制。处理之后,我们会得到每个顶点在二维屏幕空间的坐标,以及各顶点的深度、颜色信息,这些会被传输到光栅化阶段。这一阶段通常在GPU上进行。
纯CPU的渲染流水线通常称为软渲染,即用软件模拟硬件进行渲染操作。
光栅化阶段
这一阶段通常也在GPU进行,这个时候,渲染已经接近尾声。利用上一阶段得到的数据,我们可以在GPU的插值寄存器中进行插值运算得到足够数量的像素信息,并最终确定逐像素确认,哪些像素应该显示在屏幕上。
CPU和GPU之间的通信
我们可以看到,应用阶段的数据在CPU中,这些数据是怎样传输给GPU进行几何阶段的操作呢?
在CPU中,所有和渲染有关的数据都会进入显存中,这是因为显卡对于显存的访问速度更快,随后,CPU会设置一些渲染状态,最后,CPU会调用Draw Call。Draw Call是一个CPU调度命令,它会指定那些需要被渲染的图元并通知GPU,这些被指定的数据会通过数据总线传输到GPU中。Draw Call其实就是调用图形编程语言(如DX,GL,Cg)的接口,通过这一层抽象与硬件层打交道。
数据总线是计算机内部各设备之间交换设备的一个通道,既然是通道,那么它肯定有传输速度的上限,频繁地提交Draw Call会导致CPU过载,这也是一个常见的性能瓶颈。
GPU流水线
应用阶段进行的计算都是为硬件层的渲染做准备,这个阶段结束后,就正式进入了GPU的流水线中。在一些比较老的GPU中采用的是固定渲染流水线,这也就意味着所有的操作都是受限的,我们只能做一些简单的配置。随着硬件设备的发展,现代的图形显卡几乎都支持可编程渲染流水线,定制化程度得到了提高。固定渲染流水线已经逐渐被淘汰了,这里不对其展开说明,下面主要了解一下可编程渲染管线的各个阶段:
Vertex Shader(顶点着色器)
顶点着色器是完全可编程的。输入其中的每一个顶点都会调用一次顶点着色器,它无法创建和销毁顶点,也无法获取顶点之间的关系,但这一特性适合用来进行高速的并行计算。输入顶点着色器的有顶点的位置信息,法线信息,切线信息等。它的主要工作是进行坐标变换和顶点光照计算最终得到Normalized Device Coordinates(NDC,归一化的设备坐标)。这个坐标通常会在光栅化后传递给片元着色器进行处理。但是顶点着色器的作用远不止于此,输入顶点的法线、切线等信息也会在这一步进行处理,比如生成副切线,把顶点转换到切线空间进行计算,或者进行法线外扩,实现描边效果。
涉及到坐标变换,就绕不开矩阵和线性代数,数学部分的内容可以参考《3D数学基础:图形与游戏开发》等图书,或者参考3D数学概要。
Tessellation Shader(曲面细分着色器)& Geometry Shader(几何着色器)
顶点着色器为了追求速度不得不舍弃一些操作,但这些舍弃的操作会在一定程度上影响画面的美感。在硬件的支持下,便诞生了具有特异功能的曲面细分着色器和几何着色器。这两个着色器不可编程,但可以配置。
由于计算机的数据离散性,我们只能使用折线表示曲线,使用多平面表示曲面,如果粒度不够,曲线和曲面就显得没那么平滑。而曲面细分着色器的作用就是解决这个问题:生成新的顶点,“插入”到直线上或平面内,让曲线和曲面显得更圆滑。
而几何着色器的优势在于它可以创建和销毁顶点。但这些创建出来的顶点不是用于细分,而是用于扩展;同时,它也可以销毁那些我们不想输出到下一阶段的顶点。
由于Shaderlab的高度封装性,Unity对这两种着色器的支持度比较低。
经过若干着色器的计算筛选,顶点规模已经基本确定了,接下来对顶点做最后的处理。
Clipping(裁剪)
由于我们输出的不可能是整个空间,出于性能考虑,我们自然会想到,舍去那些不会出现在屏幕上的顶点,这也就是裁剪。在这一阶段,我们会把顶点变换到裁剪空间,裁剪空间是一个单位立方体空间,因此我们只需要判断哪些线、面在立方体内,哪些在立方体外,即可知道我们真正需要处理的是哪些。特殊情况是,如果有一条直线或者一个平面部分可见,那么裁剪操作会在立方体边界生成新的顶点,取代那些不会出现的顶点。裁剪操作虽然不可编程,但是我们可以定制裁剪视锥,远近平面,视角大小等信息控制裁剪范围,这一部分内容也会在3D数学概要中有所体现。
Screen Mapping(屏幕映射)
现在我们已经得到了屏幕内的所有顶点信息,但它仍位于裁剪空间中,因此我们有必要把这些顶点映射到屏幕坐标系。映射过程中使用了两个维度的坐标信息,而我们知道空间坐标是一个三维信息,丢失的那一维我们并没有真正地舍弃,而是将他作为顶点的深度信息,为以后的片元操作提供依据。
至此,概念流水线的几何阶段工作就结束了,我们回顾一下,上述阶段,我们接收了顶点的原始信息,最终得到的是渲染所需的屏幕坐标,顶点深度值等信息。需要注意的是,在Shaderlab中编写的顶点着色器包含了裁剪部分,这是因为接下来这些顶点数据会被提交给光栅化阶段,这一阶段接受的输入是裁剪空间下的信息。接下来是光栅化阶段的工作了。
首先是光栅化以及插值过程,它包含了三角形设置和三角形遍历,目的是计算图元覆盖的像素。
Triangle Setup(三角形设置)
计算三角形网格表示的数据。
Triangle Traversal(三角形遍历)
这个阶段接收的数据仍是顶点级别。这里是真正栅格化数据的阶段,这个阶段会逐像素检查其是否有被三角形网格覆盖,如果有,就生成一个片元。因此,它也被称为扫描变换过程,覆盖信息计算完成后,整个覆盖区域会使用顶点信息进行插值,生成像素级别的数据,这些数据会传递到片元着色器中。
这些像素级别的数据仍然是以片元为载体的,并不真正对应屏幕上的像素。
接下来是片元着色器环节,也是第二个和最后一个完全可编程环节。
Fragment Shader(片元着色器)
在DirectX中,它也被称为Pixel Shader(像素着色器),但个人感觉片元是更适合的名称,因为这个阶段的输出并不会真正影响屏幕的像素颜色,接下来还有逐片元操作,对这些片元进行筛选,以确定最终显示的颜色。这一阶段最重要的技术是纹理采样。为了得到采样结果,我们通常会在顶点着色器中计算每个顶点的纹理坐标,采样器会根据这个坐标采样纹理数据。由于我们已经在顶点着色器中计算好了每个顶点的颜色信息,也在上一阶段得到了像素级别的插值颜色,因此现在我们只需要根据我们想实现的效果,做相应的颜色计算即可。
Per-Fragment Operations(逐片元操作)
在DirectX中也称为Output Merger(输出合并)。这一阶段具有高度的配置性。进行到这里,渲染工作也基本完成了。经过上一阶段,我们得到了许多色彩斑斓的片元,是时候进行最后的筛选了。在这一阶段,我们会对每一个片元都进行一系列的测试操作以及最终的混合操作,目的是确定这个片元是否可见,以及可见时它的颜色对应的权重。测试主要有Stencil Test(模板测试)和Depth Test(深度测试),在测试前,首先要判断这个片元是否开启了对应的测试操作。在测试中,我们会利用对应的缓冲和片元进行比较,对应的有Stencil Buffer(模板缓冲)和Depth Buffer(深度缓冲)。通过了模板测试的片元会被保留,同时更改模板缓冲区的值,随后进行深度测试(假设这个片元同时开启了两种测试)。深度测试具有更高的配置性。即使这个片元通过了深度测试,我们也可以关闭深度写入,让这个片元的深度值不影响深度缓冲区。透明效果的实现离不开深度测试的高配置性。
经过深度测试后我们会发现,我们舍弃了许多片元,这样也就意味着这些片元对应的片元着色环节所做的一切都是徒劳。自然我们会想,能否将深度测试提前?答案是肯定的,这项技术被称为Early-Z,它会在片元着色器之前进行深度测试,但这并不意味着我们可以舍弃真正的深度测试环节。如果我们把深度测试提前,这些检验结果可能会和片元着色器的某些操作发生冲突,这个时候我们就不得不放弃Early-Z,选择传统的深度测试。
通过测试的片元会来到最后一个环节,Blend(混合),与之对应的是颜色缓冲区。我们可以选择开启/关闭混合操作。对于不透明的物体,我们会关闭混合操作,这样,这个片元的颜色会完全覆盖掉颜色缓冲区的像素值;对于半透明物体,我们需要开启混合选项,以达到透明效果。这一阶段也是高度配置的,我们可以自定义混合的比例。Photoshop的图层混合模式的实现也是类似的操作。
GPU流水线之后
当所有片元都经过逐片元操作后,我们得到的颜色缓冲区就可以作为最终呈现在屏幕上的图像了。但一般来说我们会把这个颜色缓冲区的内容输出到Frame Buffer(帧缓冲)。这是因为光栅化过程的进度是不可知的,也就是说有可能我们读取的屏幕图像还包含了部分上一帧的内容(这个转场很炫酷,但并不是我们希望看到的)。对应的解决方案是,使用Double Buffer(双缓冲)技术,我们准备两个缓冲区,一个用于当前屏幕图像显示,一个用于幕后渲染下一帧的图像。不仅如此,我们得到了帧缓冲后,还可以进行Post-Processing(屏幕后处理),实现更丰富的视觉效果。
最后
我们已经梳理了一遍GPU渲染的详细过程,但由于抽象层(Shader Language)提供给我们的接口的区别,以及GPU为我们做的额外优化,许多细节或者顺序可能不尽相同,但也足以让我们对计算机图形学和渲染有比较清晰的认识了,至少可以知道计算机,或者说硬件,在背后为我们做了些什么。
下面给出一张流水线对照图以供参考(打开图片可查看原图)。
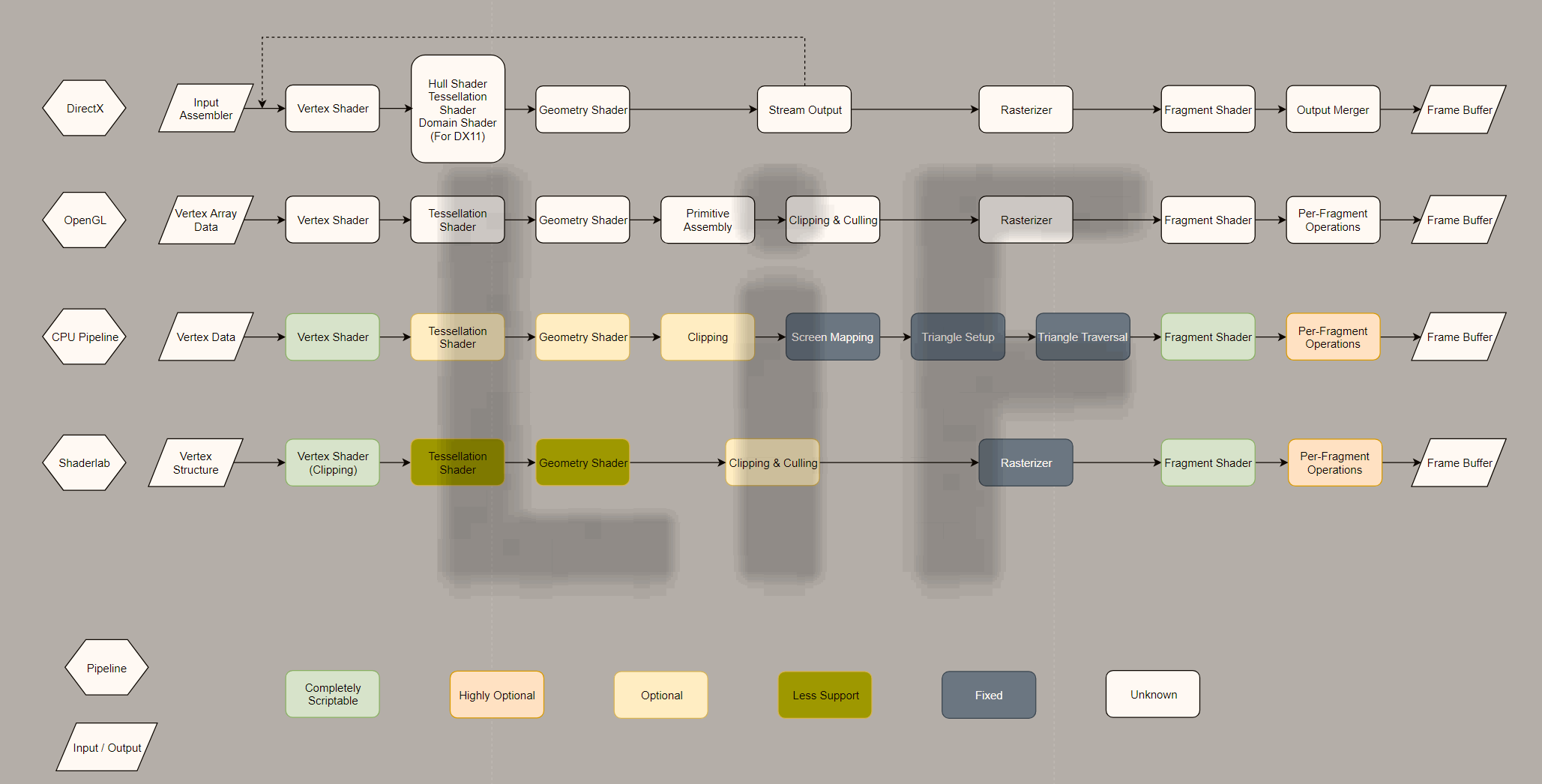
在Shaderlab中,顶点和片元着色器可以通过插入CG/GLSL代码块实现,剔除阶段和逐片元操作则可以通过Tags和CommonState实现高度配置。
1.3:Render Pipeline and GPU Pipeline的更多相关文章
- ASP.NET Process Model之二:ASP.NET Http Runtime Pipeline - Part II
https://www.cnblogs.com/artech/archive/2007/09/13/891266.html 二.ASP.NET Runtime Pipeline(续ASP.NET Ht ...
- ASP.NET Process Model之二:ASP.NET Http Runtime Pipeline[上篇]
链接:https://www.cnblogs.com/artech/archive/2007/09/13/891262.html 相信大家都使用过ASP.NET进行过基于Web的应用开发,ASP.NE ...
- devops-2:Jenkins的使用及Pipeline语法讲解
DevOps-Jenkins Jenkins简介 Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件项目可以进行持续 ...
- mxnet:结合R与GPU加速深度学习
转载于统计之都,http://cos.name/tag/dmlc/,作者陈天奇 ------------------------------------------------------------ ...
- [CB]Intel 2018架构日详解:新CPU&新GPU齐公布 牙膏时代有望明年结束
Intel 2018架构日详解:新CPU&新GPU齐公布 牙膏时代有望明年结束 北京时间12月12日晚,Intel在圣克拉拉举办了架构日活动.在五个小时的演讲中,Intel揭开了2021年CP ...
- AI解决方案:边缘计算和GPU加速平台
AI解决方案:边缘计算和GPU加速平台 一.适用于边缘 AI 的解决方案 AI 在边缘蓬勃发展.AI 和云原生应用程序.物联网及其数十亿的传感器以及 5G 网络现已使得在边缘大规模部署 AI 成为可能 ...
- mxnet:结合R与GPU加速深度学习(转)
近年来,深度学习可谓是机器学习方向的明星概念,不同的模型分别在图像处理与自然语言处理等任务中取得了前所未有的好成绩.在实际的应用中,大家除了关心模型的准确度,还常常希望能比较快速地完成模型的训练.一个 ...
- Caffe源码理解2:SyncedMemory CPU和GPU间的数据同步
目录 写在前面 成员变量的含义及作用 构造与析构 内存同步管理 参考 博客:blog.shinelee.me | 博客园 | CSDN 写在前面 在Caffe源码理解1中介绍了Blob类,其中的数据成 ...
- 问题✅:render json的格式支持。to_json被改成as_json,功能一样
class StudentsController < ApplicationController def show @student = Student.find(params[:id]) re ...
随机推荐
- jexus System.BadImageFormatException Details: Non-web exception. Exception origin (name of application or object): App_global.asax_ai3fjolq.
Application ExceptionSystem.BadImageFormatExceptionInvalid method header format 0Description: HTTP 5 ...
- 20175320 2018-2019-2 《Java程序设计》第8周学习总结
20175320 2018-2019-2 <Java程序设计>第8周学习总结 教材学习内容总结 本周学习了教材的第十五章的内容,在这章中介绍了泛型和集合框架,着重讲了泛型类的概念,并介绍了 ...
- c++ 库函数cmath
cmath中常用库函数: int abs(int i);//返回整型参数i的绝对值double fabs(double x);//返回双精度参数x的绝对值long labs(long n);//返回长 ...
- delphi 自动获取串口
delphi 自动获取串口 https://blog.csdn.net/Nevermore_anger/article/details/79012875 版权声明:本文为博主原创文章,未经博 ...
- redis相关操作
#连接主机 redis-cli -h 192.168.2.109 -p 6379 #通过密码登录 auth "yourpassword" #存取值 set hello world ...
- LeetCode 705 Design HashSet 解题报告
题目要求 Design a HashSet without using any built-in hash table libraries. To be specific, your design s ...
- Zookeeper节点增删改查与集群搭建(笔记)
1.上传文件目录说明 上传的文件一般放在 /home/下 安装文件一般在 /usr/local/下 2. 安装zookeeper 2.1将zookeeper-3.4.11.tar.gz拷贝到/home ...
- Appium IOS 使用多模拟器并发执行测试
申明一下 转载请注明出处 复制粘贴请滚蛋 !!!!!!!! 最近在是用appium进行app的并发测试,并且Android已经实现在同一台PC机使用多个模拟器并发测试的功能 这里说一句模拟器使 ...
- C# 字典Dictionary
Dictionary<TKey, TValue> 泛型类提供了从一组键到一组值的映射.通过键来检索值的速度是非常快的,接近于 O(1),这是因为 Dictionary<TKey, T ...
- 【菜鸟学Python】案例一:汇率换算
汇率换算V1.0 案例描述: 设计一个汇率换算器程序,其功能是将外币换算成人民币,或者相反 案例分析: 分析问题:分析问题的计算部分: 确定问题:将问题划分为输入.处理及输出部分: 设计算法:计算部分 ...