使用有序GUID:提升其在各数据库中作为主键时的性能
原文出处:https://www.codeproject.com/articles/388157/guids-as-fast-primary-keys-under-multiple-database ,避免今后忘记了再去阅读原英文。【】是感觉理解有问题的地方
正确的使用有序GUID在大部分数据库中可以获得和 整型作为主键 时相媲美的性能。
介绍
这篇文章概述了一种方法去规避 当使用GUID作为主键/聚焦索引时一些常见的弊端,借鉴了 Jimmy Nilsson 的文章 GUID作为主键的成本 。尽管这一基本实现已被集成在众多库和框架中(包括 NHibernate,译者注:ABP框架中集成有 SequentialGuidGenerator),但大多数只针对 Microsoft SQL Server。这里将尝试适配其他一些常见的数据库如 Oracle, PostgreSQL, 及 MySQL 解决一些.NET Framework中不寻常的诡谲问题。
背景说明
从以往来看,一种很常见的数据库设计是使用连续的整型作为标识,该字段通常由服务器本身在插入新数据行时自动生成。这种简介的方法适用与很多应用程序。
然而在某些情况并不是很理想。随着越来越多的使用Nhibernate和EntityFramework等对象关系映射(ORM)框架,依赖服务器自动生成主键的这种方式引发了许多 大多数人都希望避免的 并发问题。同样,复制方案的时候这种依靠【单一认证机构源(single authoritative source)】生成的键值也会产生问题——因此,关键点是减少【单一权利机构的作用(the role of a single authority)】。
一种很诱人的选择是使用GUID作为唯一键值。GUID(全局唯一标识符),也称为UUID,长128-bit的值,能保证在所有时间和空间上独一无二。RFC 41222 描述了创建标准GUID,如今大多数GUID生成算法通常是一个很长的随机数,再结合一些像网络mac地址这种随机本地组件信息。
GUID允许开发人员自行创建而不需要服务器去检查是否已被他人使用导致冲突,咋一看,这是一种很好的解决方案。
那么问题是什么呢?性能。为了得到最好的新能,很多数据库都使用聚焦索引,意味着表中的行的顺序(通常基于主键)也是对应存储在磁盘中的的顺序。这使得其能通过索引快速查找,但它也导致在插入 【主键不是在列表的末尾的(their primary key doesn't fall at the end of the list)】 新行时变得很慢。例如下面的数据:
| ID | Name |
| 1 | Holmes, S. |
| 4 | Watson, J. |
| 7 | Moriarty, J. |
此时很简单:数据行对应ID列顺序储存。如果我们新添加一行ID为8,也不会产生问题,新行会附加的末尾。
| ID | Name |
| 1 | Holmes, S. |
| 4 | Watson, J. |
| 7 | Moriarty, J. |
| 8 | Lestrade, I. |
但如果我们想插入一行的ID为5:
| ID | Name |
| 1 | Holmes, S. |
| 4 | Watson, J. |
| 5 | Hudson, Mrs. |
| 7 | Moriarty, J. |
| 8 | Lestrade, I. |
ID7,8行必须移动。虽然在这里不算什么事儿,但当你的数据量达到数百万行的级别之后,这就是个问题了。如果你还想要每秒处理上百次这种请求,那可真是难上加难了。
这就是GUID主键引发的问题:它可能是真正随机生成的,至少表面看起来很像是随机的,因为它们通常不会产生任何特定的顺序。正因为如此,使用一个 GUID 值作为任何规模的数据库中的主键的一部分被认为是非常糟糕的做法。 导致插入会很慢,还会涉及大量的不必要的磁盘活动。
有规则的GUID
所以,GUID最关键的问题就是它缺乏规则。那么,就让我们来制定一个规则。COMB 方法(这里联合GUID/时间戳)使用一个保持增长(或至少不会减少)的值去替换GUID的某一组成部分。顾名思义,这是一个根据当前日期时间生成的值。
举个栗子,考虑下面这组GUID值:
fda437b5-6edd-42dc-9bbd-c09d10460ad02cb56c59-ef3d-4d24-90e7-835ed5968cdc6bce82f3-5bd2-4efc-8832-986227592f2642af7078-4b9c-4664-ba01-0d492ba3bd83
请注意这组值没有任何特定顺序且本质上是随机生成的。插入100万行以这种类型为主键的值就会非常慢。
现在考虑这种假定的特殊GUID值:
00000001-a411-491d-969a-77bf40f5517500000002-d97d-4bb9-a493-cad27799936300000003-916c-4986-a363-0a9b9c95ca5200000004-f827-452b-a3be-b77a3a4c95aa
其中的第一部分已用递增的序列替换——设想从项目启动开始按毫秒计算。插入100万条数据不是很糟糕,新行会依次追加到末尾不会对现有数据造成影响。
现在我们有了基本的概念,还需要进一步了解 在各种不同的数据库系统中 GUID是如何构造的。
128-bit 的GUID主要有4部分组成,Data1, Data2, Data3, and Data4,你可以看成下面这样:
11111111-2222-3333-4444-444444444444
Data1 占4个字节, Data2 两个字节, Data3 两个字节加 Data4 8个字节(其中Data3和Data4的第一部分或多或少保留有一些版本信息).
现如今使用的有很多GUID算法,特别是在.NET 平台, 像是被当作了一个花哨的随机数生成器 (微软在过去曾将本机mac地址加入到生成GUID的运算当中, 但由于涉及到隐私问题这种方法在几年前就停止使用了). 这对我们来说是件好事, 意味着,在它(GUID)值的某部分动点手脚不太可能会影响到它的唯一性.
但不幸的是,不同的数据库处理GUID的方式也是不同的。有些(Microsoft SQL Server, PostgreSQL) 具有内置GUID类型可以储存和直接操作GUID。没有原生GUID支持的数据库通过模拟而有不同的约定。例如MySQL, 通常将GUID储存为char(36)的字符串表现形式. Oracle保存为raw bytes类型,一个GUID值为raw(16).
读取的时候的处理则更加复杂, 因为Microsoft SQL Server一个比较另类之处是它按照 GUID末尾最不重要的那6个字节来排序(即. Data4中最后6个字节)。所以,如果想在SQL Server中创建有序的GUID,我们不得不将有序部分放在最后面。大部分其他数据库会把它放在开头.
算法
从不同数据库GUID的处理方式来看,显然没有一个通用的有序GUID生成算法,我们针对不同应用程序分别对待。经过一番实验之后, 我确定了大部分为下面3中情况:
- 生成的GUID 按照字符串顺序排列
- 生成的GUID 按照二进制的顺序排列
- 生成的GUID 像SQL Server, 按照末尾部分排列
(为什么字符串顺序和二进制顺序有区别?因为在 little-endian system 环境中.NET处理GUID和string的方式并不是你想象的和其他运行.net的环境中的那样。)
‘我’根据这些区别定义了如下的枚举:
public enum SequentialGuidType
{
SequentialAsString,
SequentialAsBinary,
SequentialAtEnd
}
现在我们可以定义一个接受参数为上面枚举类型的方法去生成我们的GUID:
public Guid NewSequentialGuid(SequentialGuidType guidType)
{
...
}
但是具体要怎么来创建我们想要的有序GUID呢?就是(GUID)的哪一部分我们要保留其“随机性”、哪一部分要替换成时间戳?按照最初的 COMB 规范,针对 SQL Server,用时间戳的值替换Data4的最后6个字节。这是最简单的因为 SQL Server 就是按照GUID那6个字节的值进行排序的,通常情况这6个字节就已经足够了(这里应该是值唯一性),再加上其他10字节的随机值。
最重要的还是GUID的随机性。就像我刚所说的,我们还需要构建10字节的随机值:
var rng = new System.Security.Cryptography.RNGCryptoServiceProvider();
byte[] randomBytes = new byte[];
rng.GetBytes(randomBytes);
我们使用了 RNGCryptoServiceProvider 来生成其中的随机部分因为 System.Random 在这里有一些不足之处(它根据一些可识别的模式生成数字,例如它会在超过232 次迭代后循环而出现重复)。我们依赖其随机性就需要 RNGCryptoServiceProvider 来产生保密性强的随机数据。
(然而,这样还是相对较慢,如果你想追求极致性能的话可以考虑另一种做法——例如直接使用 Guid.NewGuid() 来产生 byte[] 数据。‘我’通常不这样做 因为 Guid.NewGuid()本身并不能保证其随机性,还是使用据我所知比较可靠做法。)
Okay,随机值部分我们已经有了,剩下的就是用时间戳去替换排序的部分。我们使用6字节的时间戳,它根据什么得来呢?很明显可以使用 DateTime.Now (或者如 Rich Andersen 指出的使用 DateTime.UtcNow 有更好的性能)转换为6字节的整型。它的Ticks属性很诱人:能得到一个从January 1, 0001 A.D.至今的100毫微秒间隔数。但它仍然有一些问题。
首先,因为其Ticks属性返回一个64-bit的值但我们只需要48bit,我们必须丢掉2字节,剩下的48bit有用的100毫微秒的时间间隔周期不到一年就会溢出。很多应用程序的使用寿命会超过一年 这样会毁了我们的最初愿望,我们需要使用时间不太精确的来测量。
另一个难题是 DateTime.UtcNow 的精确度太低。如这篇文章所描述的,它的值可能更新间隔为10毫秒。(可能在某些系统中会稍微频繁点,但我们依赖这个。)
好消息是,将这两个结合起来问题可以相互抵消:由于长度限制不能使用整个Ticks值,所以我们拿来除以1000然后将末尾48bits作为时间戳。‘我’使用毫秒是因为,即使 DateTime.UtcNow 在某些系统中的准确度只有10毫秒左右,将来会提高,期待。减少精确度之后我的时间戳溢出重复大约会在公元5800年之后,相信对大多数应用程序来说这已经足够了。
在我们继续之前提醒一下:使用精确度为1毫秒的时间戳意味着在GUID生成非常快的时候时间戳是有可能重复的,这时候就不会有顺序。这在某些程序中可能很常见,事实上‘我’尝试了一些替代方法,像使用高准确度的 System.Diagnostics.Stopwatch ,或者将时间戳和一个‘计数器’结合来试图保证在时间戳未更新是也能有顺序。然而经测试发现这样做并没有明显差异,即使一次性生成10个甚至100个guid也可能会呈现出同样的时间戳。这也符合 Jimmy Nilsson 在他的COMB中的测试结果。考虑到这一点,就不再在这里纠结了.
代码如下:
long timestamp = DateTime.UtcNow.Ticks / 10000L;
byte[] timestampBytes = BitConverter.GetBytes(timestamp);
现在时间戳我们有了,然而我们是从一个数字中通过 BitConverter 获得字节的,还需要考虑字节顺序:
if (BitConverter.IsLittleEndian)
{
Array.Reverse(timestampBytes);
}
我们有了生成GUID需要的随机字节部分和时间戳字节部分。剩下的就是拼接它们了。在支持的数据库类型 SequentialGuidType 数量这一点上,我们得量力而为。 SequentialAsBinary 和 SequentialAsString的时候时间戳排在前面, SequentialAtEnd 相反。
byte[] guidBytes = new byte[]; switch (guidType)
{
case SequentialGuidType.SequentialAsString:
case SequentialGuidType.SequentialAsBinary:
Buffer.BlockCopy(timestampBytes, , guidBytes, , );
Buffer.BlockCopy(randomBytes, , guidBytes, , );
break; case SequentialGuidType.SequentialAtEnd:
Buffer.BlockCopy(randomBytes, , guidBytes, , );
Buffer.BlockCopy(timestampBytes, , guidBytes, , );
break;
}
到目前为止一切顺利;但现在我们走进了.net framework的一个怪癖区域,它不仅是将GUID当成一个byte序列组,出于某种原因,它还认为GUID是一个包含一个Int32、两个Int16及8byte的struct。换句话说,它认为Data1是Int32、Data2和Data3是Int16、Data4是Byte[8]。
这对我们来说意味着什么?..主要问题有字节得重新排序,由于.net认为它处理的是数字,我们得补偿little-endian system ——但是!——时间戳在前面的时候,只为应用程序将GUID值转换为一个字符串(时间戳在末尾的不重要[因为Data4不会被当作数字]不需要作任何处理)
这就是上面提到的将GUID作为字符串和二进制有区别的原因。[将GUID]作为字符串存储的数据库,ORM框架或应用程序会使用 ToString() 来生成 SQL INSERT 语句,意思是我们需要改进字节存储顺序问题。[将GUID]当作二进制数据存储的数据库,可能会使用 Guid.ToByteArray() 插入,我们不需要修正。因此,我们最后再加上:
if (guidType == SequentialGuidType.SequentialAsString &&
BitConverter.IsLittleEndian)
{
Array.Reverse(guidBytes, , );
Array.Reverse(guidBytes, , );
}
现在使用参数为byte[]的构造函数返回GUID:
return new Guid(guidBytes);
使用
要使用我们的方法,首先得确定我们使用的是那种数据库及ORM框架,为了方便,下面是一些常见的数据库类型,可能与你应用程序的实际情况有出入:
| Database | GUID Column | SequentialGuidType Value |
| Microsoft SQL Server | uniqueidentifier | SequentialAtEnd |
| MySQL | char(36) | SequentialAsString |
| Oracle | raw(16) | SequentialAsBinary |
| PostgreSQL | uuid | SequentialAsString |
| SQLite | varies | varies |
(SQLite没有GUID类型字段,但有类似功能的扩展,然而根据 BinaryGUID 传参的不同,内部可能存储为16字节长度的二进制数据或长度36的text,所以这里没有一个统一方案)。
这里有一些该方法生成的样本数据。
第一个 NewSequentialGuid(SequentialGuidType.SequentialAsString) :
39babcb4-e446-4ed5-4012-2e27653a9d1339babcb4-e447-ae68-4a32-19eb8d91765d39babcb4-e44a-6c41-0fb4-21edd4697f4339babcb4-e44d-51d2-c4b0-7d8489691c70
如上,其中前6个字节(前2部分)是排序部分,剩下的是随机值。将这样的值插入将GUID当作字符串的数据库(如MySQL)时相对与无序GUID性能会有显著提升。
接下来是 NewSequentialGuid(SequentialGuidType.SequentialAtEnd) :
a47ec5e3-8d62-4cc1-e132-39babcb4e47a939aa853-5dc9-4542-0064-39babcb4e47c7c06fdf6-dca2-4a1a-c3d7-39babcb4e47dc21a4d6f-407e-48cf-656c-39babcb4e480
排序的末尾的6个字节,其余是随机部分。‘我’不明白为什么SQL Server的 uniqueidentifier 是这个样子,但这样做同样也没什么问题。
最后是 NewSequentialGuid(SequentialGuidType.SequentialAsBinary) :
b4bcba39-58eb-47ce-8890-71e7867d67a5b4bcba39-5aeb-42a0-0b11-db83dd3c635bb4bcba39-6aeb-4129-a9a5-a500aac0c5cdb4bcba39-6ceb-494d-a978-c29cef95d37f
当我们 ToString() 之后再看是发现某些东西出错了:前面的两部分‘调换’了(因为前面提到字符串二进制问题),如果插入的是字符串字段(MySQL),性能不会有任何提升。
问题产生的原因是使用了 ToString()方法。上面4组值如果是使用 Guid.ToByteArray() 转换为16字符串的话:
39babcb4eb5847ce889071e7867d67a539babcb4eb5a42a00b11db83dd3c635b39babcb4eb6a4129a9a5a500aac0c5cd39babcb4eb6c494da978c29cef95d37f
这是大多数ORM框架针对Oracle数据库所作的处理,你会发现,这样做之后,排序功能又有作用了。
回顾一下,我们现在有一个方法可以针对3中不同的数据库(将GUID储存为字符串MySQL, 可能有SQLite;作为二进制数据的Oracle, PostgreSQL;以及有另类储存方案的Microsoft SQL Server)生成有序的GUID值。
后面我们还可以扩展我们的方法,自动检测数据库类型,或者通过 DbConnection 判断,但可能会取决于我们应用程序所使用的ORM框架,留给你们自由发挥。
对比数据【如今各数据库版本变迁,实际数据效果可能相差很大,个人对这些性能测试不感兴趣】
选了4个常用的数据库(Microsoft SQL Server 2008, MySQL 5.5, Oracle XE 11.2, and PostgreSQL 9.1)在windows7桌面系统中进行测试。
测试是通过每个数据的命令插入 GUID主键和100字符长度的text【译者注:text类型已经被nvarchar(max)代替】的 2百万行数据,首先是测试我们方法的3中不同算法,接着是 Guid.NewGuid() 最后比较int类型,图中还对比了前100w行及后面100w行分别使用的时长(毫秒):

在SQL Server中,SequentialAtEnd方式效果最好,性能很接近int,对比NewGuid()无序生成性能提升了接近75%;后面100w行稍微慢点【which is consistent with a lot of page-shuffling to maintain the clustered index as more rows get added in the middle】,其他两种方式与无序方式相差不大,说明SequentialAtEnd的方式工作良好。
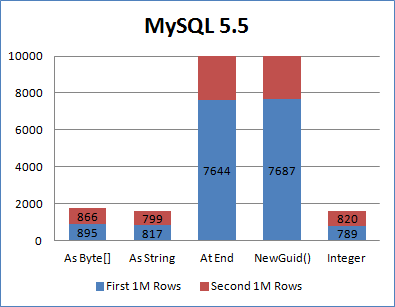
如图,无序GUID在MySql中的性能非常低,慢到我不得不砍掉图中后100w行的具体性能显示(后100w行插入比前面慢了一半);使用SequentialAsString的算法是性能接近与int,说明达到了排序的目的。
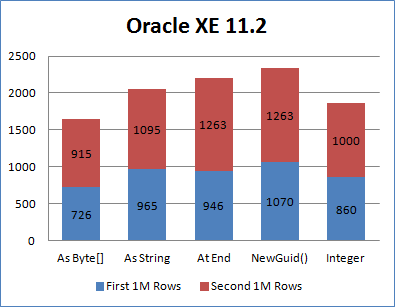
Oracle中就不那么明显了,使用raw(16)来储存GUID。我们使用 SequentialAsBinary 时最快,但即使使用无序GUID也并没有慢很多;此外有序GUID的插入还比int稍快,至少这的测试结果是这样的,我不得不怀疑Oracle是否也有某种怪癖。,,
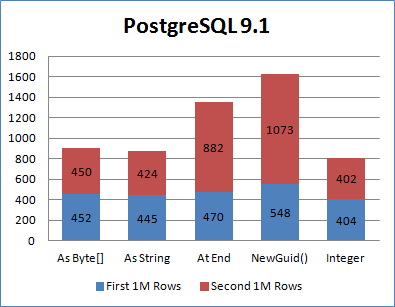
最后是 PostgreSQL,和Oracle一样也没有明显的提升,只是最快的是使用SequentialAsString,只比int慢了7.8左右,但相比无序GUID节省了近一半的时间。
其他
这里有几点需要考虑。这里重点关注了插入有序guid的性能;但是对比 Guid.NewGuid() ,创建GUID的性能消耗该怎么算呢?好吧,它确实很慢:在‘我’的系统,生成100w无序GUID需要140毫秒,但生成有序GUID需要2800毫秒——慢了20倍。
一些快速测试表明慢的主要原因是使用了 RNGCryptoServiceProvider 来生成随机数据;使用 System.Random 能降到400毫秒左右。但‘我’还是不推荐这样做 System.Random 在这里仍然有问题。当然可能会有其他比这更好的算法——诚然‘我’不是很懂随机数生成。
这点很值得注意吗?个人觉得在可接受范围。除非你的应用涉及非常频繁的插入(这种情况GUID主键不是很理想),相比有序GUID带来的好处,这点问题微不足道。
另一个问题是:6字节的时间戳占用意味着仅有10个字节的随机数据,这可能会危机唯一性。包括时间戳,是保证创建 间隔相隔几毫秒 的两个GUID唯一性——这是一个约定,即使是完全随机的GUID(如Guid.NewGuid()创建的),如果两个GUID创建时间太过接近会怎么样呢?10-byte的强加密型随机数意味着有280,1,208,925,819,614,629,174,706,176 种可能的组合。这样一来,生成重复GUID的概率微不足道。
最后一点,这种方式生成的GUID的格式并不满足 RFC 4122 规范——它们缺少版本号(通常在bit48-51位),‘我’不认为这很必要;‘我’不知道是否有数据库去真正在意这一结构,省略它多出了4位作为随机部分。当然要加上这个也很容易。
完整代码
这是这个方法的完整实现代码。有一些小的修改(如抽象静态随机生成器实例以及重构switch块):
using System;
using System.Security.Cryptography; public enum SequentialGuidType
{
SequentialAsString,
SequentialAsBinary,
SequentialAtEnd
} public static class SequentialGuidGenerator
{
private static readonly RNGCryptoServiceProvider _rng = new RNGCryptoServiceProvider(); public static Guid NewSequentialGuid(SequentialGuidType guidType)
{
byte[] randomBytes = new byte[];
_rng.GetBytes(randomBytes); long timestamp = DateTime.UtcNow.Ticks / 10000L;
byte[] timestampBytes = BitConverter.GetBytes(timestamp); if (BitConverter.IsLittleEndian)
{
Array.Reverse(timestampBytes);
} byte[] guidBytes = new byte[]; switch (guidType)
{
case SequentialGuidType.SequentialAsString:
case SequentialGuidType.SequentialAsBinary:
Buffer.BlockCopy(timestampBytes, , guidBytes, , );
Buffer.BlockCopy(randomBytes, , guidBytes, , ); // If formatting as a string, we have to reverse the order
// of the Data1 and Data2 blocks on little-endian systems.
if (guidType == SequentialGuidType.SequentialAsString && BitConverter.IsLittleEndian)
{
Array.Reverse(guidBytes, , );
Array.Reverse(guidBytes, , );
}
break; case SequentialGuidType.SequentialAtEnd:
Buffer.BlockCopy(randomBytes, , guidBytes, , );
Buffer.BlockCopy(timestampBytes, , guidBytes, , );
break;
} return new Guid(guidBytes);
}
}
最终代码和演示项目 https://github.com/jhtodd/SequentialGuid[^]
结论
如开头所说的,这种通用实现已经集成到各种重量级框架中;这里已经不是最新的,‘我’的目的是说明实现的方法及原理,根据不同的数据库环境加以调整以适应具体需求。
一点点的不断努力尝试,就有可能实现适用于任何数据库的有序GUID生成方法。
使用有序GUID:提升其在各数据库中作为主键时的性能的更多相关文章
- Mysql数据库中的计数器表实时更新
如果某个应用中存在计数器,例如网站的总访问量.用户的粉丝数.文件下载数等等.如果相关应用在Mysql数据库的表中保存计数器,在更新计数器的时候可能会碰到并发问题.例如在web应用中,记录网站的点击次数 ...
- 用Java向数据库中插入大量数据时的优化
使用jdbc向数据库插入100000条记录,分别使用statement,PreparedStatement,及PreparedStatement+批处理3种方式进行测试: public void ex ...
- springboot集成jpa,在postgresql数据库中创建主键自增表
依赖文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http:/ ...
- Entity Framework code first设置不在数据库中生成外键
你现在用的EF是什么版本?我用EF6,你可以重写SqlServerMigrationSqlGenerator的生成外键和更新外键的方法,把不需要的表都过滤掉不就ok了? public class Ex ...
- 多数据库有序GUID
背景 常见的一种数据库设计是使用连续的整数为做主键,当新的数据插入到数据库时,由数据库自动生成.但这种设计不一定适合所有场景. 随着越来越多的使用Nhibernate.EntityFramework等 ...
- 针对多类型数据库,集群数据库的有序GUID
一.背景 常见的一种数据库设计是使用连续的整数为做主键,当新的数据插入到数据库时,由数据库自动生成.但这种设计不一定适合所有场景. 随着越来越多的使用Nhibernate.EntityFramewor ...
- 有序GUID
背景 常见的一种数据库设计是使用连续的整数为做主键,当新的数据插入到数据库时,由数据库自动生成.但这种设计不一定适合所有场景. 随着越来越多的使用Nhibernate.EntityFramework等 ...
- 数据库中GUID的生成
GUID, 即Globally Unique Identifier(全球唯一标识符) 也称作 UUID(Universally Unique IDentifier) . GUID是一个通过特定算法产生 ...
- 从集合的无序性看待关系型数据库中的"序"
本文目录:1.集合的特征2.集合的无序性3.表中记录的无序性4.集合的"序"和物理存储顺序之间的关系5.查询结果(虚拟表)的无序性.随机性6.为什么总是强调"无序&quo ...
随机推荐
- Java 必须掌握的 20+ 种 Spring 常用注解
Spring部分 1.声明bean的注解 @Component 组件,没有明确的角色 @Service 在业务逻辑层使用(service层) @Repository 在数据访问层使用(dao层) @C ...
- 运用java反射机制获取实体方法报错,java.lang.NoSuchMethodException: int.<init>(java.lang.String)
错误的原因是我的Student实体,成员变量数据类型,使用了int基本数据类型,改成Integer包装类型即可.
- Hadoop2-HDFS学习笔记之入门(不含YARN及MR的调度功能)
架构 Hadoop整体由HDFS.YARN.MapReduce三大部分组成,推荐架构参考:https://www.cnblogs.com/zhjh256/p/10573684.html. 注:2.x的 ...
- oracle网络服务之beq协议和SDU优化(性能提升可达30%)
oracle网络服务之beq协议和SDU优化(性能提升可达30%) 12.3.1 BEQ协议 如果Oracle数据库服务端和客户端在同一台机器上,可以使用BEQ连接,BEQ连接采用进程间直接通信,不 ...
- day 06
深浅拷贝 # 值拷贝:应用场景最多ls = [1, 'abc', [10]]ls1 = ls # ls1直接将ls中存放的地址拿过来# ls内部的值发生任何变化,ls1都会随之变化ls2 = l ...
- kali-通过获取路由器pin码套取无线网络密码shell脚本
直接上脚本吧, 我做个笔记. #************************************************************************* # > Fil ...
- 2018年-2019年第二学期第二周C#学习个人总结
在本学期的第二周,我们又开始了C#的学习.在星期一的C#课上时,我们学了this关键字的用法其中包括1.this访问属性2.this访问成员方法3.this访问构造方法.在this访问属性中通过thi ...
- 移动端开发注意事项——meta、rem以及弹性盒
移动端开发注意事项——meta.rem以及弹性盒 随着人们对移动端的依赖程度的增强,前端开发对移动端的需求也越来越强烈.那么,在移动端开发中,有哪些事项是需要注意的呢? meta标签 在常规的pc端开 ...
- Python3 tkinter基础 TK title 设置窗体的标题
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- windows cannot find powershell.exe windows 7
This can happen when the environment variables are missing an entry for Powershell. $env:path must i ...