【速读】——Shangxuan Tian——【ICCV2017】WeText_Scene Text Detection under Weak Supervision
Shangxuan Tian——【ICCV2017】WeText_Scene Text Detection under Weak Supervision
目录
- 作者和相关链接
- 文章亮点
- 方法介绍
- 方法细节
- 实验结果
- 总结与收获
作者和相关链接
- 作者

文章亮点
- 用半监督和无监督来学习字符分类器,解决字符标注数据量少的问题
- 用regression的思路来学习字符分类器,而且是把proposal + text/non-text classification整合在一个网络中学习(这一点没有第一点亮)
方法介绍
- 检测流程
用SSD检测字符(文章的亮点在于如何训练这个SSD)
- 用TextFlow的图模型把字符连成单词输出
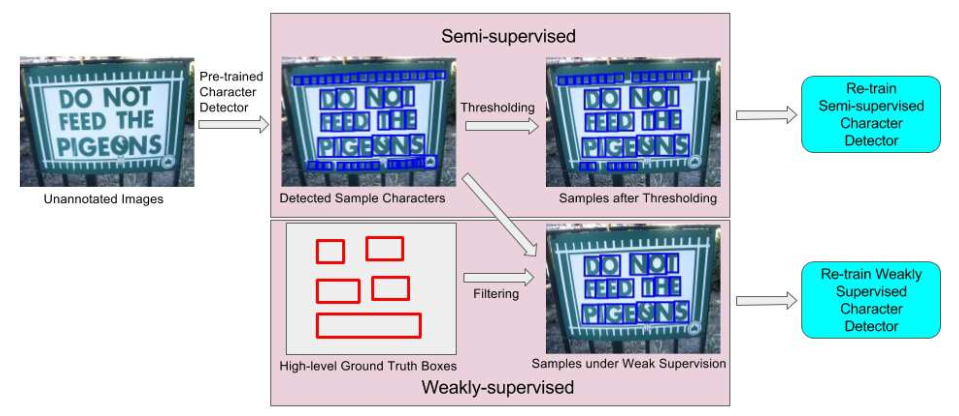
Figure 2: The framework of the proposed WeText system: A “light” supervised model is pre-trained using a small amount of annotated character image set. The light model is then applied to an unannotated dataset to search for more character samples which are combined with the small annotated dataset to train a semi-supervised model. Under certain weak annotations, better character samples can be searched to train a semi-supervised model
- 训练SSD的半监督方法
用一个小数据集(记为D)采用监督的方式训练一个light的base model(记为M)
用M跑一遍没有标注的大数据集(记为R),将其中分数大于阈值(0.5)的样本作为正样本(记为数据集P)
用数据集D+数据集P训练新的model(记为M’)
- 训练SSD的弱监督方法
用一个小数据集(记为D)采用监督的方式训练一个light的base model(记为M)
用M跑一遍有单词标注信息的大数据集(记为R’),将其中分数大于阈值(0.2)且与单词标注GT有重叠(水平和竖直IOU阈值0.8)的样本作为正样本(记为数据集P’)
用数据集D+数据集P’训练新的model(记为M’’)
方法细节
- 几种SSD模型效果对比

Figure 4: Comparison of different character detectors. Images in the top row from left to right are the input image and output of the baseline detector. Images in the bottom row from left to right are outputs of “COCO-Text Semi” and “COCO-Text Weakly” detectors, respectively. The thickness of the box boundary lines indicates the detection confidence
- Training
- Base model:ICDAR2013的字符集
- FORU: FORU_Semi为半监督,FORU_Weakly为弱监督,FORU_GT为完全监督(FORU本身有字符集标注信息,COCO-Text上没有,故没有COCO-Text_GT)。FORU_GT的目的在于验证用半监督和弱监督的方法也可以达到几乎和完全监督的效果是一样的(FORU_GT算是算法的精度上限),证明其半监督和弱监督的有效性;
- COCO_Text: 由于COCO-Text的样本集比FORU大,所以实验证明了无监督数据越多,效果越好;
实验结果
- 速度说明
- Nvidia Titan X GPU
- ICDAR2013:190ms-SSD模型,130ms-text line model,总的320ms/每张图
- ICDAR13
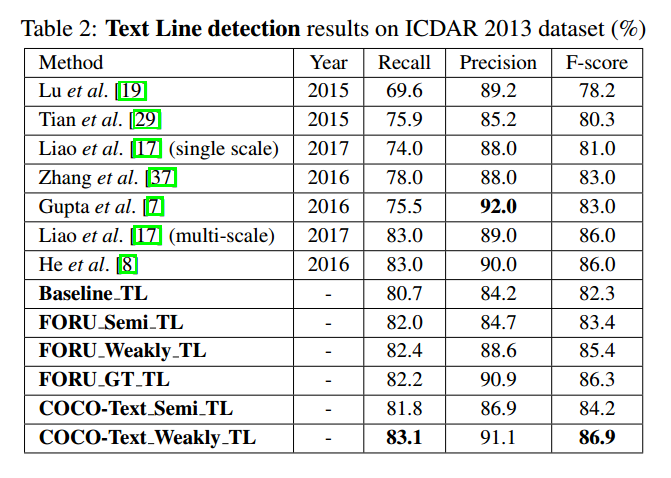
- SVT

总结与收获
- 这篇文章最大亮点无疑是用弱监督来扩增训练数据的思想,非常有参考价值,所以虽然点少但是也中ICCV。但是文中没有太多训练细节,比如在新的数据库上是重新train还是在原base model上fine-tune的,以及SSD的anchor设置细节之类的。
- 不看亮点,单看检测方法,其缺点在于:第一,速度比较慢;第二,只能处理水平的,无法处理多方向的;第三,由于采用了character-based的pipeline,导致必须加上text flow里的图模型来合并文本线。这种思路不但需要两个分离的模型,速度降低,也会因为分步累计误差,且无法端到端训练。且第二点也是因为采用这种pipeline导致的,实际上要将character合并成多方向的text line也是可以的,但是不能用text flow里的,而是需要设计新的算法来替换(这个也蛮有难度的)。
【速读】——Shangxuan Tian——【ICCV2017】WeText_Scene Text Detection under Weak Supervision的更多相关文章
- 【论文速读】Fangfang Wang_CVPR2018_Geometry-Aware Scene Text Detection With Instance Transformation Network
Han Hu--[ICCV2017]WordSup_Exploiting Word Annotations for Character based Text Detection 作者和代码 caffe ...
- 【论文速读】Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping
Chuhui Xue_ECCV2018_Accurate Scene Text Detection through Border Semantics Awareness and Bootstrappi ...
- 【论文速读】Yuliang Liu_2017_Detecting Curve Text in the Wild_New Dataset and New Solution
Yuliang Liu_2017_Detecting Curve Text in the Wild_New Dataset and New Solution 作者和代码 caffe版代码 关键词 文字 ...
- 【论文速读】Pan He_ICCV2017_Single Shot Text Detector With Regional Attention
Pan He_ICCV2017_Single Shot Text Detector With Regional Attention 作者和代码 caffe代码 关键词 文字检测.多方向.SSD.$$x ...
- 论文速读(Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection)
Chuhui Xue--[arxiv2019]MSR_Multi-Scale Shape Regression for Scene Text Detection 论文 Chuhui Xue--[arx ...
- 【论文速读】XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection
XiangBai_CVPR2018_Rotation-Sensitive Regression for Oriented Scene Text Detection 作者和代码 caffe代码 关键词 ...
- 论文速读(Yongchao Xu——【2018】TextField_Learning A Deep Direction Field for Irregular Scene Text)
Yongchao Xu--[2018]TextField_Learning A Deep Direction Field for Irregular Scene Text Detection 论文 Y ...
- 【论文速读】Shitala Prasad_ECCV2018】Using Object Information for Spotting Text
Shitala Prasad_ECCV2018]Using Object Information for Spotting Text 作者和代码 关键词 文字检测.水平文本.FasterRCNN.xy ...
- 【论文速读】Sheng Zhang_AAAI2018_Feature Enhancement Network_A Refined Scene Text Detector
Sheng Zhang_AAAI2018_Feature Enhancement Network_A Refined Scene Text Detector 作者 关键词 文字检测.水平文字.Fast ...
随机推荐
- 重新学习Java的开始~
安装jdk的步骤及解释已经在这篇文章中详细阐述了,如下: http://www.cnblogs.com/godtrue/p/4338323.html 1.如何安装库源文件--摘自coreJava 库源 ...
- HTML5_图片合成_刮刮卡
刮刮卡(图片合成) 定义: globalCompositeOperation 属性,设置或返回如何将源图像 将 myCanvas 的背景图设置为一张图片,(刮开后显示) // 目标图像(已有的,外面一 ...
- scrapy流程
- oracle的用户管理
创建用户 在Oracle中创建用户需要用到dba,普通用户无法创建 > create user 用户名 identified by 密码; * 密码必须以英文开头,不然是创建不起来的! * 如果 ...
- Multi-Projector Based Display Code ---- ModelViewer
Overview Model viewer is another application we provided for large display. It is designed for viewi ...
- 简述移动端开发前端和app间的关系
<p>前端页面嵌套进app内部,一般有时候会进行一些交互,类似于前端页面请求后台接口一样,通常会起一个前端开发人员和app开发人员会相互协定一个协议;双方就协议而言去进行请求接口和返回数据 ...
- ldap/sldap
给新建的账户赋权限也是通过修改配置文件/etc/openldap/slapd.conf来实现,具体的增加的内容如下: 如上面示例中就定义了两个用户,一个是只读用户cn=bbs,dc=361way,dc ...
- keras,tensorflow,numpy,jupyter
docker-tensorflow:https://segmentfault.com/a/1190000015053704 pip install scipy pip install keras do ...
- 无法登陆mysql user用户
- mysql5.7.17版本升级源码方式及恢复主主复制
版本升级--自测 从库 ------------ 停止主从复制 stop slave 全库备份 mysqldump -u root -p -S mysql.sock --all-databases&g ...