【Spark篇】---SparkSQL on Hive的配置和使用
一、前述
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
二、具体配置
1、在Spark客户端配置Hive On Spark
在Spark客户端安装包下spark-1.6.0/conf中创建文件hive-site.xml:
配置hive的metastore路径
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>
2、启动Hive的metastore服务
hive --service metastore
3、启动zookeeper集群,启动HDFS集群。
4、启动SparkShell 读取Hive中的表总数,对比hive中查询同一表查询总数测试时间。
./spark-shell
--master spark://node1:7077,node2:7077
--executor-cores 1
--executor-memory 1g
--total-executor-cores 1
import org.apache.spark.sql.hive.HiveContext
val hc = new HiveContext(sc)
hc.sql("show databases").show
hc.sql("user default").show
hc.sql("select count(*) from jizhan").show
可以发现性能明显提升!!!
注意:
如果使用Spark on Hive 查询数据时,出现错误:

找不到HDFS集群路径,要在客户端机器conf/spark-env.sh中设置HDFS的路径:
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
三、读取Hive中的数据加载成DataFrame
1、HiveContext是SQLContext的子类,连接Hive建议使用HiveContext。
2、由于本地没有Hive环境,要提交到集群运行,提交命令:
/spark-submit
--master spark://node1:7077,node2:7077
--executor-cores 1
--executor-memory 2G
--total-executor-cores 1
--class com.bjsxt.sparksql.dataframe.CreateDFFromHive
/root/test/HiveTest.jar
java代码:
SparkConf conf = new SparkConf();
conf.setAppName("hive");
JavaSparkContext sc = new JavaSparkContext(conf);
//HiveContext是SQLContext的子类。
HiveContext hiveContext = new HiveContext(sc);
hiveContext.sql("USE spark");
hiveContext.sql("DROP TABLE IF EXISTS student_infos");
//在hive中创建student_infos表
hiveContext.sql("CREATE TABLE IF NOT EXISTS student_infos (name STRING,age INT) row format delimited fields terminated by '\t' ");
hiveContext.sql("load data local inpath '/root/test/student_infos' into table student_infos"); hiveContext.sql("DROP TABLE IF EXISTS student_scores");
hiveContext.sql("CREATE TABLE IF NOT EXISTS student_scores (name STRING, score INT) row format delimited fields terminated by '\t'");
hiveContext.sql("LOAD DATA "
+ "LOCAL INPATH '/root/test/student_scores'"
+ "INTO TABLE student_scores");
/**
* 查询表生成DataFrame
*/
DataFrame goodStudentsDF = hiveContext.sql("SELECT si.name, si.age, ss.score "
+ "FROM student_infos si "
+ "JOIN student_scores ss "
+ "ON si.name=ss.name "
+ "WHERE ss.score>=80"); hiveContext.sql("DROP TABLE IF EXISTS good_student_infos"); goodStudentsDF.registerTempTable("goodstudent");
DataFrame result = hiveContext.sql("select * from goodstudent");
result.show(); /**
* 将结果保存到hive表 good_student_infos
*/
goodStudentsDF.write().mode(SaveMode.Overwrite).saveAsTable("good_student_infos"); Row[] goodStudentRows = hiveContext.table("good_student_infos").collect();
for(Row goodStudentRow : goodStudentRows) {
System.out.println(goodStudentRow);
}
sc.stop();
scala代码:
val conf = new SparkConf()
conf.setAppName("HiveSource")
val sc = new SparkContext(conf)
/**
* HiveContext是SQLContext的子类。
*/
val hiveContext = new HiveContext(sc)
hiveContext.sql("use spark")
hiveContext.sql("drop table if exists student_infos")
hiveContext.sql("create table if not exists student_infos (name string,age int) row format delimited fields terminated by '\t'")
hiveContext.sql("load data local inpath '/root/test/student_infos' into table student_infos") hiveContext.sql("drop table if exists student_scores")
hiveContext.sql("create table if not exists student_scores (name string,score int) row format delimited fields terminated by '\t'")
hiveContext.sql("load data local inpath '/root/test/student_scores' into table student_scores") val df = hiveContext.sql("select si.name,si.age,ss.score from student_infos si,student_scores ss where si.name = ss.name")
hiveContext.sql("drop table if exists good_student_infos")
/**
* 将结果写入到hive表中
*/
df.write.mode(SaveMode.Overwrite).saveAsTable("good_student_infos") sc.stop()
结果:
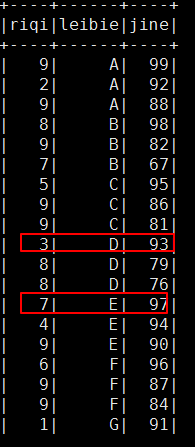
可以看到分组内有序,组间并不是有序的!!!!
【Spark篇】---SparkSQL on Hive的配置和使用的更多相关文章
- hive on spark VS SparkSQL VS hive on tez
http://blog.csdn.net/wtq1993/article/details/52435563 http://blog.csdn.net/yeruby/article/details/51 ...
- [Spark]Spark-sql与hive连接配置
一.在Mysql中配置hive数据库 创建hive数据库,刷新root用户权限 create database hive; grant all on *.* to root@'; flush priv ...
- Spark之 SparkSql整合hive
整合: 1,需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置. 2,如果Hive的元数据存放在Mysql中,我们还需 ...
- spark on yarn模式下配置spark-sql访问hive元数据
spark on yarn模式下配置spark-sql访问hive元数据 目的:在spark on yarn模式下,执行spark-sql访问hive的元数据.并对比一下spark-sql 和hive ...
- SparkSQL和hive on Spark
SparkSQL简介 SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-h ...
- Hive On Spark和SparkSQL
SparkSQL和Hive On Spark都是在Spark上实现SQL的解决方案.Spark早先有Shark项目用来实现SQL层,不过后来推翻重做了,就变成了SparkSQL.这是Spark官方Da ...
- 【Spark篇】---SparkSQL初始和创建DataFrame的几种方式
一.前述 1.SparkSQL介绍 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制. SparkSQL支持查询原 ...
- SparkSQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- SparkSQL与Hive on Spark
SparkSQL与Hive on Spark的比较 简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapR ...
随机推荐
- jquery插件之一些小链接
1.验证 验证的插件: http://parsleyjs.org/ http://jqueryvalidation.org/2.前端UI 首页动态图片的插件:http://bxslider.com/ ...
- 学习使人快乐8--Maven
一.maven基操: MAVEN依赖之 坐标: 二.MAVEN依赖 type:依赖的类型,比如是jar包还是war包等 默认为jar,表示依赖的jar包 optional:标记依赖是否可选.默认值fa ...
- 10_27_unittest
接口测试的本质 就是测试类里面的函数. 单元测试的本质 测试函数 代码级别 单元测试框架 unittest 接口 pytest web 功能测试: 1.写用例 ----> TestCase ...
- 服务器、IP地址和域名之间有什么关系?
一.服务器 服务器其实就像我们的家用电脑一样,也有主板.CPU.内存.硬盘.电源等,但是由于它们处理问题的不同,服务器更像一台加强的家用电脑,服务器是为展网络业务而存放.处理数据的,所以服务器一般是存 ...
- Luogu P3381 (模板题) 最小费用最大流
<题目链接> 题目大意: 给定一张图,给定条边的容量和单位流量费用,并且给定源点和汇点.问你从源点到汇点的最带流和在流量最大的情况下的最小费用. 解题分析: 最小费用最大流果题. 下面的是 ...
- hdu1201 java
题意: 求某人从出生到18岁生日所经过的天数.如果这个人没有18岁生日,就输出-1. 思路: 通过毫秒值计算天数. 利用:来自https://www.cnblogs.com/xiohao/p/5294 ...
- PBRT笔记(10)——体积散射
体散射处理过程 3个影响参与介质在环境中的辐射度分布的主要因素: 吸收:减少光能,并将其转化为别的能量,例如热量. 发光:由光子发射光能至环境中. 散射:由于粒子碰撞,使得一个方向的辐射度散射至其他方 ...
- HCNA(华为)_DHCP篇
在大型的企业网络中,会有大量的主机或设备需要获取IP地址等网络参数.如果采用手工配置,工作量大 且不好管理,如果有用户擅自修改网络参数,还有可能会造成IP地址冲突等问题.使用动态主机配置协DHCP 来 ...
- angular1.3 video
video标签动态获取播放链接是出现 Error: $interpolate:interr Interpolation Error Error: $sce:insecurl Processing of ...
- TypeScript-封装
class People { private _name: string; age: number; print() { return this._name + ":" + thi ...