一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode
很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样。文章Secondary Namenode - What it really do? (需FQ)写的很通俗易懂,现将其翻译如下:
Secondary NameNode:它究竟有什么作用?
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一。从它的名字上看,它给人的感觉就像是NameNode的备份。但它实际上却不是。
很多Hadoop的初学者都很疑惑,Secondary NameNode究竟是做什么的,而且它为什么会出现在HDFS中。
因此,在这篇文章中,我想要解释下Secondary NameNode在HDFS中所扮演的角色。
从它的名字来看,你可能认为它跟NameNode有点关系。没错,你猜对了。因此在我们深入了解Secondary NameNode之前,我们先来看看NameNode是做什么的。
NameNode
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
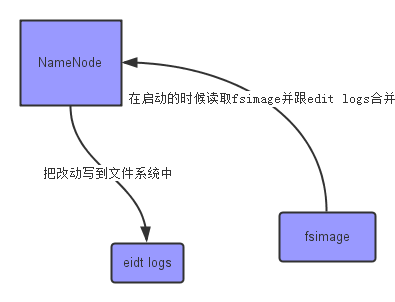
上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的。这里有两个不同的文件:
fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。
但是在生产集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。
在这种情况下就会出现下面一些问题:
edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
NameNode的重启会花费很长时间,因为有很多改动[笔者注:在edit logs中]要合并到fsimage文件上。
如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。
这跟Windows的恢复点是非常像的,Windows的恢复点机制允许我们对OS进行快照,这样当系统发生问题时,我们能够回滚到最新的一次恢复点上。
现在我们明白了NameNode的功能和所面临的挑战 - 保持文件系统最新的元数据。那么,这些跟Secondary NameNode又有什么关系呢?
Secondary NameNode
SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
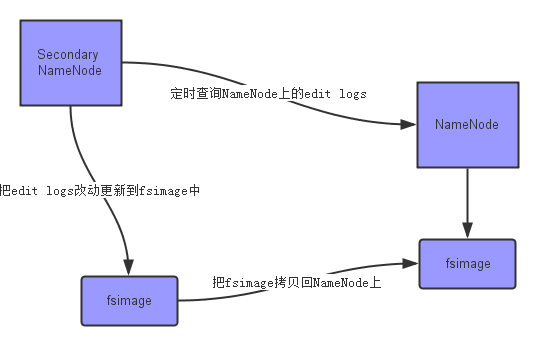
上面的图片展示了Secondary NameNode是怎么工作的。
首先,它定时到NameNode去获取edit logs,并更新到fsimage上。[笔者注:Secondary NameNode自己的fsimage]
一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。
现在,我们明白了Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。
所以从现在起,让我们养成一个习惯,称呼它为检查点节点吧。
这篇文章基本上已经清楚的介绍了Secondary NameNode的工作以及为什么要这么做。
最后补充一点细节,是关于NameNode是什么时候将改动写到edit logs中的?
这个操作实际上是由DataNode的写操作触发的,当我们往DataNode写文件时,DataNode会跟NameNode通信,告诉NameNode什么文件的第几个block放在它那里,NameNode这个时候会将这些元数据信息写到edit logs文件中。
NameNode HA与Secondary NameNode
在hadoop2.0之前,namenode只有一个,存在单点问题(虽然hadoop1.0有secondarynamenode,checkpointnode,buckcupnode这些,但是单点问题依然存在),在hadoop2.0引入了HA机制。
hadoop2.0的HA机制官方介绍了有2种方式,一种是NFS(Network File System)方式,另外一种是QJM(Quorum Journal Manager)方式。
2 基本原理
hadoop2.0的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。
两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。
active namenode和standby namenode之间通过NFS或者JN(journalnode,QJM方式)来同步数据。
active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到NFS或者JN中。
standby namenode定期的检查,从NFS或者JN把最近的edit文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage,合并完成之后会通知active namenode获取这个新fsimage。
active namenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。
这样,保持了active namenode和standby namenode的数据的实时同步,standby namenode可以随时切换成active namenode(譬如active namenode挂了)。
而且还有一个原来hadoop1.0的secondarynamenode,checkpointnode,buckcupnode的功能:合并edits文件和fsimage文件,使fsimage文件一直保持更新。
所以启动了hadoop2.0的HA机制之后,secondarynamenode,checkpointnode,buckcupnode这些都不需要了。
3 NFS方式
NFS作为active namenode和standby namenode之间数据共享的存储。active namenode会把最近的edits文件写到NFS,而standby namenode从NFS中把数据读过来。
这个方式的缺点是,如果active namenode或者standby namenode有一个和NFS之间网络有问题,则会造成他们之前数据的同步出问题。
4 QJM(Quorum Journal Manager )方式
QJM的方式可以解决上述NFS容错机制不足的问题。active namenode和standby namenode之间是通过一组journalnode(数量是奇数,可以是3,5,7...,2n+1)来共享数据。
active namenode把最近的edits文件写到2n+1个journalnode上,只要有n+1个写入成功就认为这次写入操作成功了,然后standby namenode就可以从journalnode上读取了。
可以看到,QJM方式有容错的机制,可以容忍n个journalnode的失败。
5 主备节点的切换
active namenode和standby namenode可以随时切换。当active namenode挂掉后,也可以把standby namenode切换成active状态,成为active namenode。
可以人工切换和自动切换。人工切换是通过执行HA管理的命令来改变namenode的状态,从standby到active,或者从active到standby。
自动切换则在active namenode挂掉的时候,standby namenode自动切换成active状态,取代原来的active
namenode成为新的active namenode,HDFS继续正常工作。
主备节点的自动切换需要配置zookeeper。active namenode和standby namenode把他们的状态实时记录到zookeeper中,zookeeper监视他们的状态变化。
当zookeeper发现active namenode挂掉后,会自动把standby namenode切换成active namenode。
6 实战tips
- QJM方式有明显的优点,一是本身就有fencing的功能,二是通过多个journal节点增强了系统的健壮性,所以建议在生成环境中采用QJM的方式。
- journalnode消耗的资源很少,不需要额外的机器专门来启动journalnode,可以从hadoop集群中选几台机器同时作为journalnode。
一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系的更多相关文章
- XSS钓鱼某网约车后台一探究竟,乘客隐私暴露引发思考
i春秋作家:onls辜釉 最近的某顺风车命案,把网约车平台推上了风口浪尖,也将隐私信息管理.审查的讨论面进一步扩大.这让我不禁联想起自己今年春节的遭遇,当时公司放假准备回家过年,我妈给我推荐了一个在我 ...
- FromHandle临时对象一探究竟
我们在调用CWnd::GetDlgItem()函数时,MSDN告诉我们:The returned pointer may be temporary and should not be stored f ...
- 存储系统设计——NVMe SSD性能影响因素一探究竟
目录1 存储介质的变革 2 NVME SSD成为主流 2.1 NAND FLASH介质发展 2.2 软件层面看SSD——多队列技术 2.3 深入理解SSD硬件 3 影响NVME SSD的性能因素 3. ...
- 图像原始格式(YUV444 YUV422 YUV420)一探究竟
前段时间搞x264编码测试,传参的时候需要告诉编码器我的原始数据格式是什么,其中在x264.h头文件中定义了如下一堆类型. /* Colorspace type */ #define X264_CSP ...
- Android AIDL 一探究竟
AIDL ---(Android Interface Definition Language)Android接口定义语言 简述: 1.什么时候使用? 通信方式 使用场景 AIDL IPC .多个应用程 ...
- UI前端开发都是做什么的以及html、css、php、js等究竟是神马关系
第一个问题: 1.UI,是视觉方面的呈现.一个网页首先由UI完成整体设计,然后把每一个模块切图,例如组件.logo.版块等.常用工具:PS,AI,DW. 2.前端,是将UI的设计代码化,因为计算机无法 ...
- 一探究竟:善用 MaxCompute Studio 分析 SQL 作业
头疼的问题 MaxCompute 用户一个常见的问题是:同一个周期任务,为什么最近几天比之前慢了很多?或者为什么之前都能按时产出的作业最近经常破线? 通常来说,引起作业执行变慢的原因有:quota 组 ...
- 多线程进阶——JUC并发编程之CountDownLatch源码一探究竟
1.学习切入点 JDK的并发包中提供了几个非常有用的并发工具类. CountDownLatch. CyclicBarrier和 Semaphore工具类提供了一种并发流程控制的手段.本文将介绍Coun ...
- Secondary NameNode究竟是做什么的
Secondary NameNode:它究竟有什么作用? 在hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一.从它的名字上看,它给人的感觉就像是NameNode的备 ...
随机推荐
- [Leetcode]674. Longest Continuous Increasing Subsequence
Given an unsorted array of integers, find the length of longest continuous increasing subsequence. E ...
- 不在models.py中的models
概述 如何让你定义的model不在models.py中 在app的models目录中的models 你新建一个app后这个models.py就会自动建立,里面只有几行代码.那么如果是一个中大型项目,每 ...
- centos系统安装第三方源EPEL
epel没安装呗 相当于扩展型软件仓库,EPEL (Extra Packages for Enterprise Linux,企业版Linux的额外软件包) 是Fedora小组维护的一个软件仓库项目,为 ...
- selinux基本概念
TE模型 主体划分为若干组,称为域 客体划分为若干组,每个组称为一个类型 DDT(Domain Definition Table,域定义表,二维),表示域和类型的对应访问权限,权限包括读写执行 一 ...
- javascript基础修炼(5)—Event Loop(Node.js)
开发者的javascript造诣取决于对[动态]和[异步]这两个词的理解水平. 一. 一道考察异步知识的面试题 题目是这样的,要求写出下面代码的输出: setTimeout(() => { co ...
- Linux 桌面双击运行脚本
创建桌面文件 touch myapp.desktop 编辑此文件写入一下内容 [Desktop Entry] Name = myapp Exec = /usr/bin/xxxx/xxx.sh Icon ...
- c#源码的执行过程
我想也许要写些东西,记录我做程序员的日子吧 ================================================ 要讲到C#源码的执行过程 首先要提下程序集,因为Clr并不 ...
- [Go] golang原子函数锁住共享资源
1.atomic包里的几个函数以及sync包里的mutex类型,提供了解决方案2.原子函数能够以很底层的加锁机制来同步访问整型变量和指针3.atomic.AddInt64(&counter, ...
- 20190321-HTML基本结构
目录 1.HTML概念 超文本标记语言 2.HTML版本 HTML HTML5 3.HTML基本结构 基本结构 元素.标签.属性 4.HTML常用标签 内容 1.HTML概念 HTML(HyperTe ...
- jsp基础语言-jsp动作
jsp动作是一组jsp内置的标签,用来控制jsp的行为,执行一些常用的jsp页面动作.通过jsp动作实现使用多行java代码能够实现的效果,即对常用的jsp功能进行抽象与封装. jsp共有七种标准的“ ...