星型数据仓库olap工具kylin介绍
星型数据仓库olap工具kylin介绍
数据仓库是目前企业级BI分析的重要平台,尤其在互联网公司,每天都会产生数以百G的日志,如何从这些日志中发现数据的规律很重要. 数据仓库是数据分析的重要工具, 每个大公司都花费数百万每年的资金进行数据仓库的运维.
本文介绍一个基于hadoop的数据仓库, 它基于hadoop(HIVE, HBASE)水平扩展的特性, 客服传统olap受限于关系型数据库数据容量的问题. Kylin是ebay推出的olap星型数据仓库的开源实现.
首先请安装Kylin, 和它的运行环境(Hadoop, yarn, hive, hbase). 如果安装成功, 登陆(http://<KYLIN_HOST>:7070/), 用户名:ADMIN, 密码(KYLIN). 安装过程请参考(http://kylin.incubator.apache.org/download/, 注意下载编译后的二进制包, 免去很多编译烦恼).
在创建数据仓库前, 我们先聊一下, 什么是数据仓库.
从业务过程的角度考虑, 信息系统可以划分为两个主要类别, 一类用于支持业务过程的执行, 代表作品是mysql; 另一类用于支持业务过程的分析, 代表作品是hive, 还有就是今天的主角kylin.
首先, 数据仓库的设计
下图展示了一个简单的基于订单流程中事实和维度的星型模型.
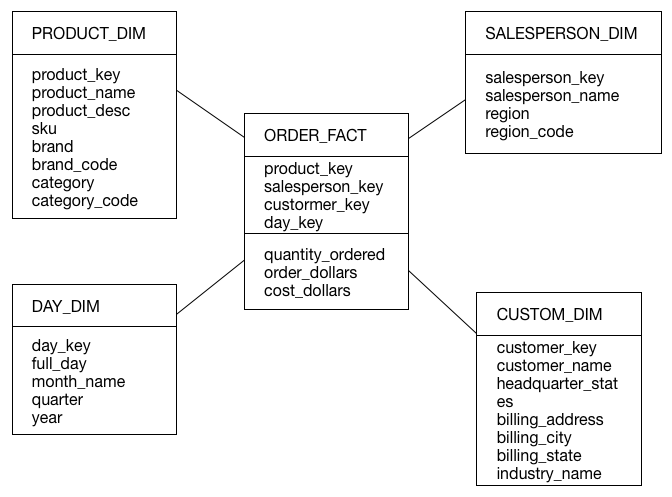
这是一个典型的星型结构, 订单的事实表有3个度量值(messures)(订单数量, 订单金额, 和订单成本); 另外有4个度量维度(dimession), 分别是时间, 产品, 销售员, 客户. 这里时间以天为单位, 这里注意day_key必须是(YYYY-MM-DD)格式(这是kylin的规定).
其次, 根据数据仓库的设计创建hive表
1. 创建事实表并插入数据
DROP TABLE IF EXISTS DEFAULT.fact_order ; create table DEFAULT.fact_order (
time_key string,
product_key string,
salesperson_key string,
custom_key string,
quantity_ordered bigint,
order_dollars bigint,
cost_dollars bigint )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
load data local inpath 'fact_order.csv' overwrite into table DEFAULT.fact_order;
fact_order.csv
2015-05-01,pd001,sp001,ct001,100,101,51
2015-05-01,pd001,sp002,ct002,100,101,51
2015-05-01,pd001,sp003,ct002,100,101,51
2015-05-01,pd002,sp001,ct001,100,101,51
2015-05-01,pd003,sp001,ct001,100,101,51
2015-05-01,pd004,sp001,ct001,100,101,51
2015-05-02,pd001,sp001,ct001,100,101,51
2015-05-02,pd001,sp002,ct002,100,101,51
2015-05-02,pd001,sp003,ct002,100,101,51
2015-05-02,pd002,sp001,ct001,100,101,51
2015-05-02,pd003,sp001,ct001,100,101,51
2015-05-02,pd004,sp001,ct001,100,101,51
2. 创建天维度表day_dim
DROP TABLE IF EXISTS DEFAULT.dim_day ; create table DEFAULT.dim_day (
day_key string,
full_day string,
month_name string,
quarter string,
year string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE; load data local inpath 'dim_day.csv' overwrite into table DEFAULT.dim_day;
dim_day.csv
2015-05-01,2015-05-01,201505,2015q2,2015
2015-05-02,2015-05-02,201505,2015q2,2015
2015-05-03,2015-05-03,201505,2015q2,2015
2015-05-04,2015-05-04,201505,2015q2,2015
2015-05-05,2015-05-05,201505,2015q2,2015
3. 创建售卖员的维度表salesperson_dim
DROP TABLE IF EXISTS DEFAULT.dim_salesperson ; create table DEFAULT.dim_salesperson (
salesperson_key string,
salesperson string,
salesperson_id string,
region string,
region_code string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE; load data local inpath 'dim_salesperson.csv' overwrite into table DEFAULT.dim_salesperson;
dim_salesperson.csv
sp001,hongbin,sp001,beijing,10086
sp002,hongming,sp002,beijing,10086
sp003,hongmei,sp003,beijing,10086
4. 创建客户维度 custom_dim
DROP TABLE IF EXISTS DEFAULT.dim_custom ; create table DEFAULT.dim_custom (
custom_key string,
custom_name string,
custorm_id string,
headquarter_states string,
billing_address string,
billing_city string,
billing_state string,
industry_name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE; load data local inpath 'dim_custom.csv' overwrite into table DEFAULT.dim_custom;
dim_custom.csv
ct001,custom_john,ct001,beijing,zgx-beijing,beijing,beijing,internet
ct002,custom_herry,ct002,henan,shlinjie,shangdang,henan,internet
5. 创建产品维度表并插入数据
DROP TABLE IF EXISTS DEFAULT.dim_product ; create table DEFAULT.dim_product (
product_key string,
product_name string,
product_id string,
product_desc string,
sku string,
brand string,
brand_code string,
brand_manager string,
category string,
category_code string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE; load data local inpath 'dim_product.csv' overwrite into table DEFAULT.dim_product;
dim_product.csv
pd001,Box-Large,pd001,Box-Large-des,large1.0,brand001,brandcode001,brandmanager001,Packing,cate001
pd002,Box-Medium,pd001,Box-Medium-des,medium1.0,brand001,brandcode001,brandmanager001,Packing,cate001
pd003,Box-small,pd001,Box-small-des,small1.0,brand001,brandcode001,brandmanager001,Packing,cate001
pd004,Evelope,pd001,Evelope_des,large3.0,brand001,brandcode001,brandmanager001,Pens,cate002
这样一个星型的结构表在hive中创建完毕, 实际上一个离线的数据仓库已经完成, 它包含一个主题, 即商品订单.
关于商品订单的统计需求可以使用hive命令产生. 比如:
1. 统计20150501到20150502所有的订单数.
Hive> select dday.full_day, sum(quantity_ordered) from fact_order as fact inner join dim_day as dday on fact.time_key == dday.day_key and dday.full_day >= "2015-05-01" and dday.full_day <= "2015-05-02" group by dday.full_day order by dday.full_day;
2015-05-01 600
2015-05-02 600
2. 统计20150501到20150502各个销售员的销售订单数
select dday.full_day, dsp.salesperson_key, sum(quantity_ordered) from fact_order as fact
inner join dim_day as dday on fact.time_key == dday.day_key
inner join dim_salesperson as dsp on fact.salesperson_key == dsp.salesperson_key
where dday.full_day >= "2015-05-01" and dday.full_day <= "2015-05-02"
group by dday.full_day, dsp.salesperson_key
order by dday.full_day;
2015-05-01 sp003 100
2015-05-01 sp002 100
2015-05-01 sp001 400
2015-05-02 sp003 100
2015-05-02 sp002 100
2015-05-02 sp001 400
然后,导入kylin数据仓库中
kylin在hive的基础上仓库olap数据cube, 完成实时数据仓库服务的任务. kylin在hive的基础上完成:
1. 将星型数据库部署在hbase上实现实时的查询服务
2. 提供restful查询接口
3. 集成BI
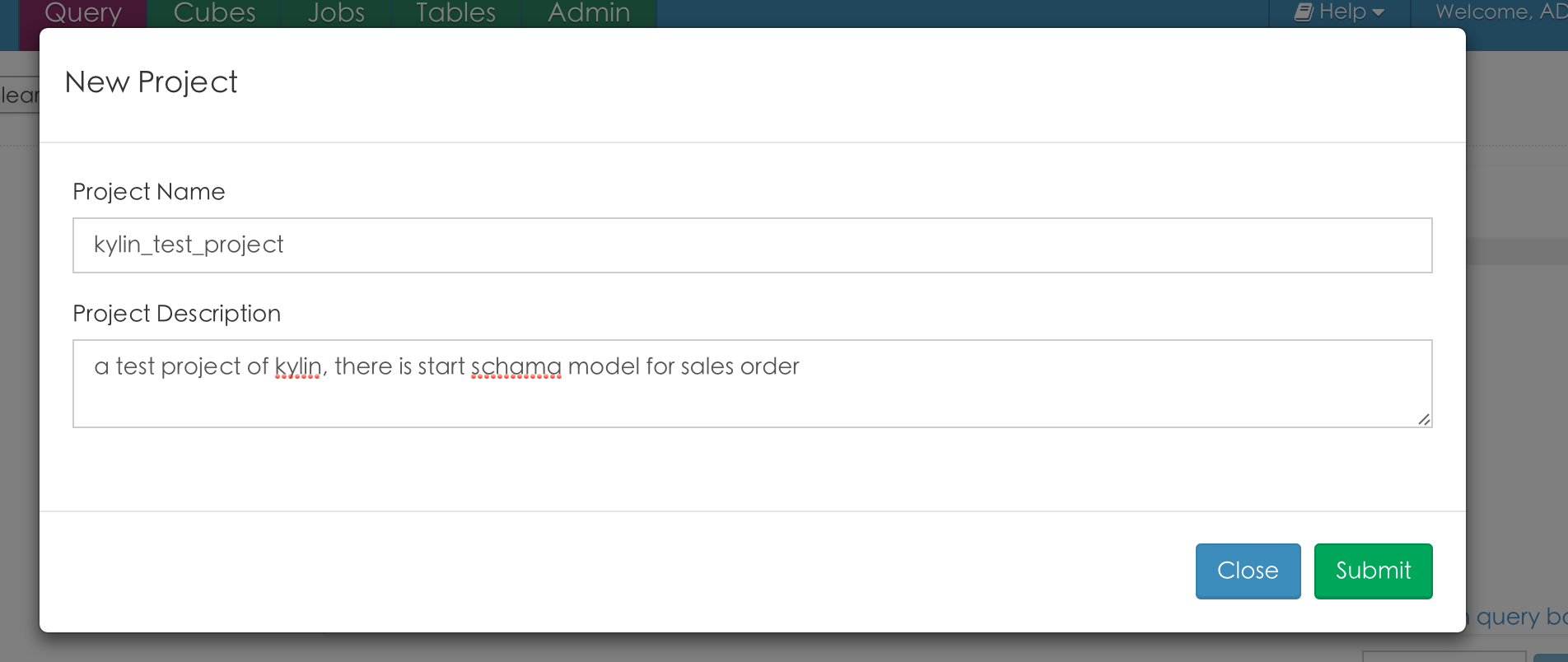
首先, 创建一个数据仓库工程(kylin_test_project)
其次, 点击tables标签,点击"load hive table"按钮, 同步上述的所有hive表
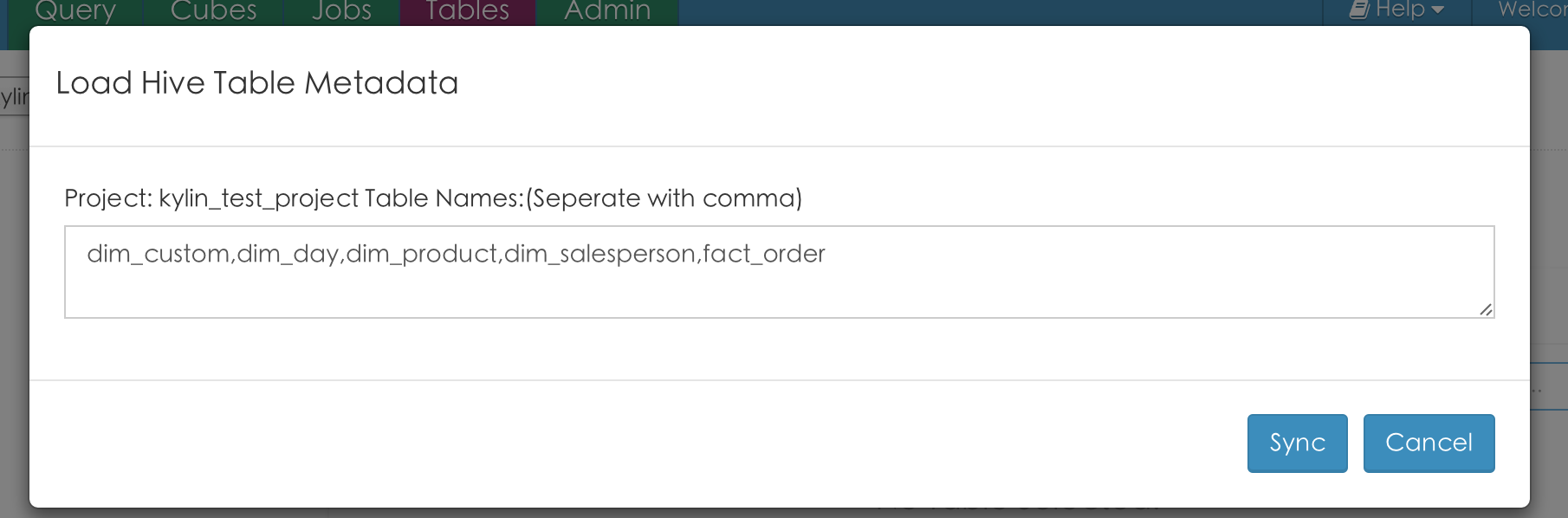
完成hive表和kylin的同步.
接着, 简历kylin的数据cube
点击cube 和新增cube按钮.
1. 命名cube order_cube
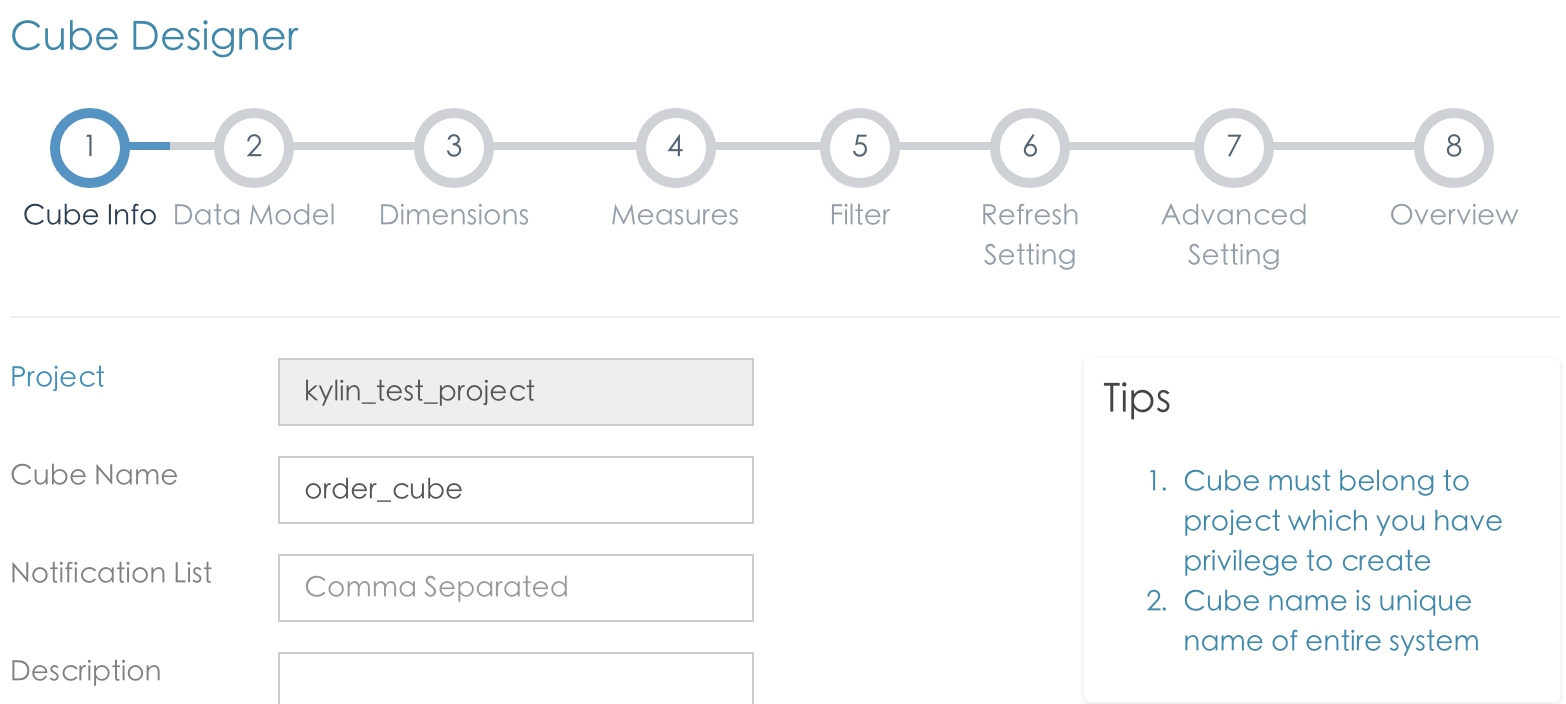
2. 增加fact 和 dim 表
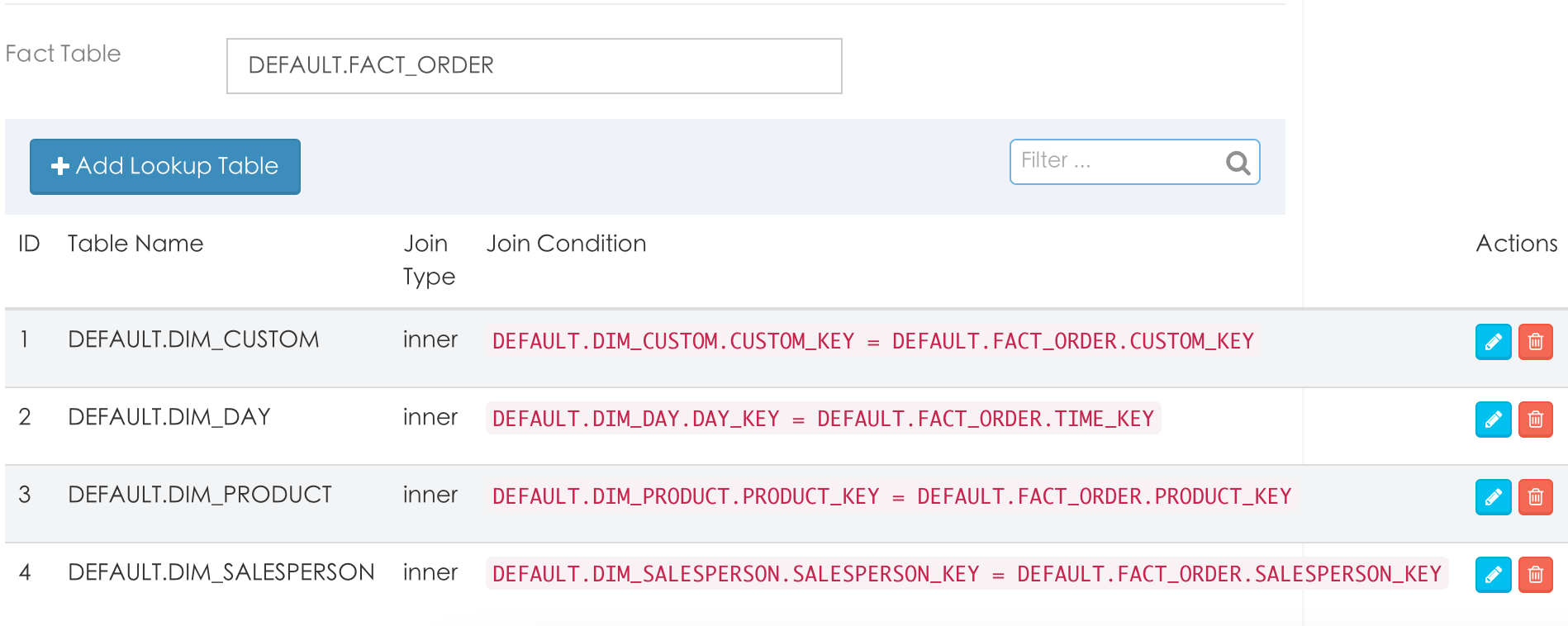
3. 增加维度

4. 增加mesure值
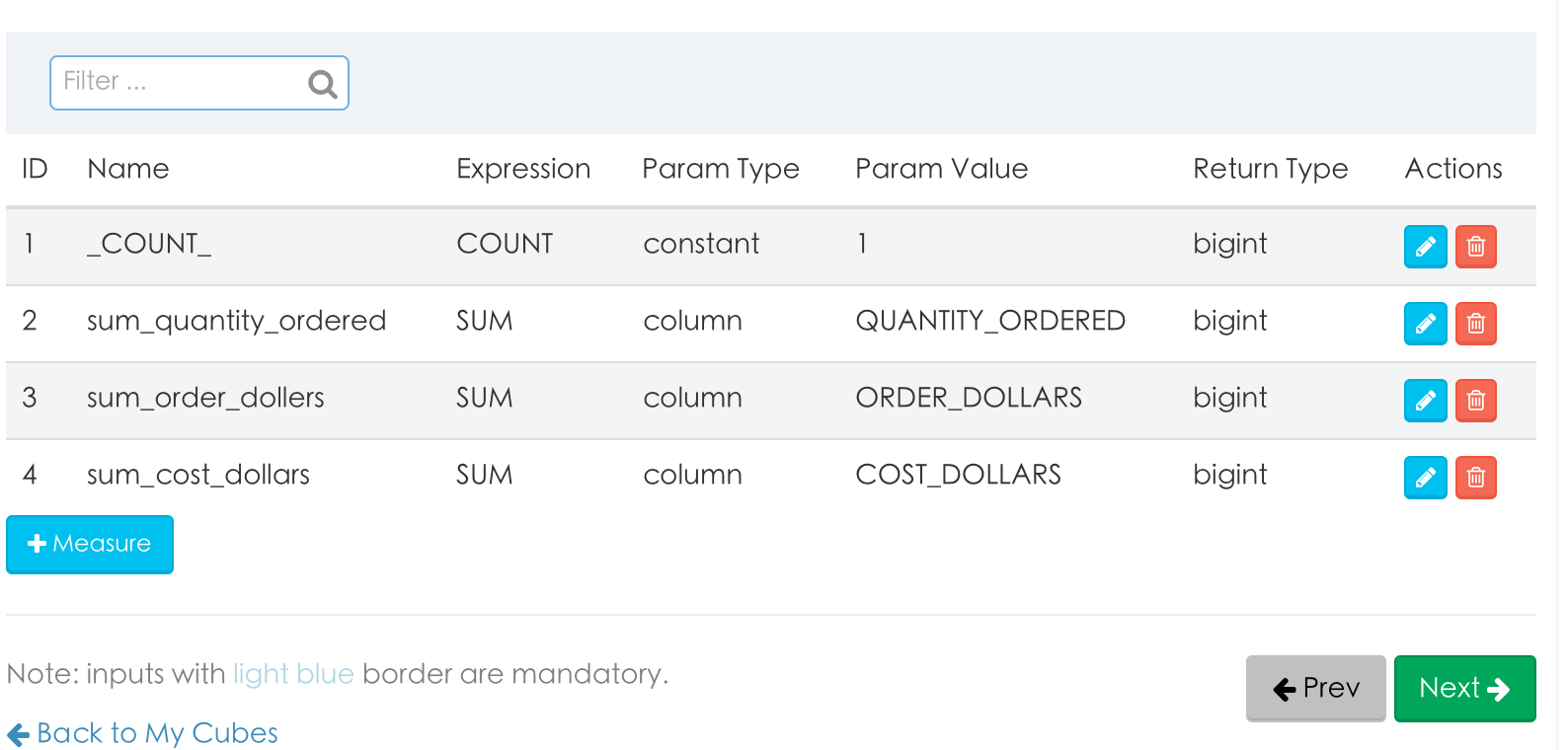
5. 不用选filter条件
6. 选择开始开始时间
7. 完成
然后, build cube
可以在jobs中查看build状态. build过程实际上是把cube存到hbase中, 方便快速检索.
星型数据仓库olap工具kylin介绍的更多相关文章
- 星型数据仓库olap工具kylin介绍和简单使用示例
本文转载自:https://www.cnblogs.com/hsydj/p/4515057.html 星型数据仓库olap工具kylin介绍 星型数据仓库olap工具kylin介绍 数据仓库是目前企业 ...
- OLAP引擎——Kylin介绍(很有用)
转:http://blog.csdn.net/yu616568/article/details/48103415 Kylin是ebay开发的一套OLAP系统,与Mondrian不同的是,它是一个MOL ...
- 转: OLAP引擎——Kylin介绍
本文转自:http://blog.csdn.net/yu616568/article/details/48103415 ,如有侵犯,立刻删除. Kylin是ebay开发的一套OLAP系统,与Mond ...
- 浅淡数据仓库(二)星型模式与OLAP多维数据库
在关系数据库管理系统中实现的维度模型称为星型模型模式,因为其结构类似星型结构.在多为数据库环境中实现的维度模型通常称为联机分析处理(OLAP)多维数据库
- Kylin 新定位:分析型数据仓库
亲爱的各位社区朋友: Apache Kylin 在 2014 年 10 月开源并加入 Apache 软件基金会的孵化器,一年后从孵化器毕业成为 Apache 顶级项目.从第一天起,Kylin 的标语是 ...
- 《BI那点儿事》数据仓库建模:星型模式、雪片模式
数据仓库建模 — 星型模式Example of Star Schema 数据仓库建模 — 雪片模式Example of Snowflake Schema 节省存储空间 一定程度上的范式 星形 vs.雪 ...
- FocusBI:租房分析&星型模型
微信公众号:FocusBI关注可了解更多的商业智能.数据仓库.数据库开发.爬虫知识及沪深股市数据推送.问题或建议,请关注公众号发送消息留言;如果你觉得FocusBI对你有帮助,欢迎转发朋友圈或在文章末 ...
- 四大OLAP工具选型浅析
OLAP(在线分析处理)这个名词是在1993年由E.F.Codd提出来的,只是,眼下市场上的主流产品差点儿都是在1993年之前就已出来,有的甚至已有三十多年的历史了.OLAP产品不少,本文将主要涉及C ...
- 用了星型转换的sql跑了5小时--->5mins的过程
=================START================================ BI数据仓库环境里面跑着一个crontab job,一旦sql运行超过4hours,就会接 ...
随机推荐
- EC笔记:第4部分:18、接口正确使用,不易被误用
好的接口容易被正确使用,不易被误用 考虑以下函数: void func(int year,int month,int day){ //一些操作 } 这个函数看似合理,因为参数的名字已经暴露了它的用途. ...
- Python 基础之三条件判断与循环
If……else 基本结构: If condition: do something else: do something 或者 If condition: do something elif cond ...
- Python3.5安装及opencv安装
Python安装注意事项(版本3.5,系统windows)1.安装好Python后将D:\Program Files\Python.D:\Program Files\Python\Scripts加入P ...
- JavaWeb之XML详解
XML语言 什么是XML? XML是指可扩展标记语言(eXtensible Markup Language),它是一种标记语言,很类似HTML.它被设计的宗旨是传输数据,而非显示数据. XML标签没有 ...
- jquery 点击查看更多箭头变化,文字变化,超出带滚动条。
从网上好了好久,没找到自己要的,自己写了一下. <!DOCTYPE html> <html> <head> <meta charset="utf-8 ...
- JDBC数据库访问操作的动态监测 之 Log4JDBC
log4jdbc是一个JDBC驱动器,能够记录SQL日志和SQL执行时间等信息.log4jdbc使用SLF4J(Simple Logging Facade)作为日志系统. 特性: 1.支持JDBC3和 ...
- Android开发案例 - 欢迎界面
本文详细描述了如何实现如下图中的微信启动界面. 该类启动界面的特点是在整个Application的生命周期里, 它只会出现在第一次进入应用时, 即便按回退键到桌面之后. 使用该类启动界面的应用还有: ...
- 【代码笔记】iOS-实现网络图片的异步加载和缓存
代码: - (void)viewDidLoad { [super viewDidLoad]; // Do any additional setup after loading the view. se ...
- swift学习笔记4——扩展、协议
之前学习swift时的个人笔记,根据github:the-swift-programming-language-in-chinese学习.总结,将重要的内容提取,加以理解后整理为学习笔记,方便以后查询 ...
- 1-3 - C#语言习惯 - 推荐使用查询语法而不是循环
C#语言中并不缺少控制程序流程的结构,for.while.do-while和foreach等都可以做到这点. 历史上所有计算机语言设计者都不曾遗漏这些重要的循环控制结构. 不过我们还有一个更好的方式: ...