[LeetCode] Cheapest Flights Within K Stops K次转机内的最便宜的航班
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a price w.
Now given all the cities and fights, together with starting city src and the destination dst, your task is to find the cheapest price from src to dst with up to k stops. If there is no such route, output -1.
Example 1:
Input:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 1
Output: 200
Explanation:
The graph looks like this:
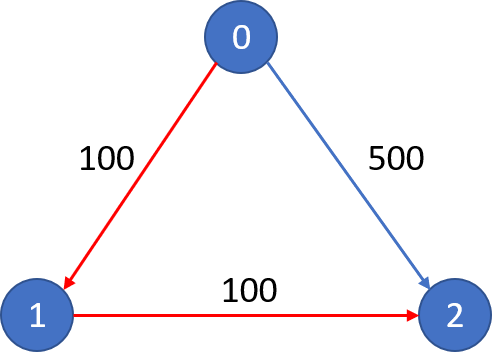
The cheapest price from city0to city2with at most 1 stop costs 200, as marked red in the picture.
Example 2:
Input:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 0
Output: 500
Explanation:
The graph looks like this:
The cheapest price from city0to city2with at most 0 stop costs 500, as marked blue in the picture.
Note:
- The number of nodes
nwill be in range[1, 100], with nodes labeled from0ton- 1. - The size of
flightswill be in range[0, n * (n - 1) / 2]. - The format of each flight will be
(src,dst, price). - The price of each flight will be in the range
[1, 10000]. kis in the range of[0, n - 1].- There will not be any duplicated flights or self cycles.
这道题给了我们一些航班信息,包括出发地,目的地,和价格,然后又给了我们起始位置和终止位置,说是最多能转K次机,让我们求出最便宜的航班价格。那么实际上这道题就是一个有序图的遍历问题,博主最先尝试的递归解法由于没有做优化,TLE了,实际上我们可以通过剪枝处理,从而压线过OJ。首先我们要建立这个图,选取的数据结构就是邻接链表的形式,具体来说就是建立每个结点和其所有能到达的结点的集合之间的映射,然后就是用DFS来遍历这个图了,用变量cur表示当前遍历到的结点序号,还是当前剩余的转机次数K,访问过的结点集合visited,当前累计的价格out,已经全局的最便宜价格res。在递归函数中,首先判断如果当前cur为目标结点dst,那么结果res赋值为out,并直接返回。你可能会纳闷为啥不是取二者中较小值更新结果res,而是直接赋值呢?原因是我们之后做了剪枝处理,使得out一定会小于结果res。然后判断如果K小于0,说明超过转机次数了,直接返回。然后就是遍历当前结点cur能到达的所有结点了,对于遍历到的结点,首先判断如果当前结点已经访问过了,直接跳过。或者是当前价格out加上到达这个结点需要的价格之和大于结果res的话,那么直接跳过。这个剪枝能极大的提高效率,是压线过OJ的首要功臣。之后就是标记结点访问,调用递归函数,以及还原结点状态的常规操作了,参见代码如下:
解法一:
class Solution {
public:
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K) {
int res = INT_MAX;
unordered_map<int, vector<vector<int>>> m;
unordered_set<int> visited{{src}};
for (auto flight : flights) {
m[flight[]].push_back({flight[], flight[]});
}
helper(m, src, dst, K, visited, , res);
return (res == INT_MAX) ? - : res;
}
void helper(unordered_map<int, vector<vector<int>>>& m, int cur, int dst, int K, unordered_set<int>& visited, int out, int& res) {
if (cur == dst) {res = out; return;}
if (K < ) return;
for (auto a : m[cur]) {
if (visited.count(a[]) || out + a[] > res) continue;
visited.insert(a[]);
helper(m, a[], dst, K - , visited, out + a[], res);
visited.erase(a[]);
}
}
};
下面这种解法是用BFS来做的,还是来遍历图,不过这次是一层一层的遍历,需要使用queue来辅助。前面建立图的数据结构的操作和之前相同,BFS的写法还是经典的写法,但需要注意的是这里也同样的做了剪枝优化,当当前价格加上新到达位置的价格之和大于结果res的话直接跳过。最后注意如果超过了转机次数就直接break,参见代码如下:
解法二:
class Solution {
public:
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K) {
int res = INT_MAX, cnt = ;
unordered_map<int, vector<vector<int>>> m;
queue<vector<int>> q{{{src, }}};
for (auto flight : flights) {
m[flight[]].push_back({flight[], flight[]});
}
while (!q.empty()) {
for (int i = q.size(); i > ; --i) {
auto t = q.front(); q.pop();
if (t[] == dst) res = min(res, t[]);
for (auto a : m[t[]]) {
if (t[] + a[] > res) continue;
q.push({a[], t[] + a[]});
}
}
if (cnt++ > K) break;
}
return (res == INT_MAX) ? - : res;
}
};
再来看使用Bellman Ford算法的解法,关于此算法的detail可以上网搜帖子看看。核心思想还是用的动态规划Dynamic Programming,最核心的部分就是松弛操作Relaxation,也就是DP的状态转移方程。这里我们使用一个二维DP数组,其中dp[i][j]表示最多飞i次航班到达j位置时的最少价格,那么dp[0][src]初始化为0,因为飞0次航班的价格都为0,转机K次,其实就是飞K+1次航班,我们开始遍历,i从1到K+1,每次dp[i][src]都初始化为0,因为在起点的价格也为0,然后即使遍历所有的航班x,更新dp[i][x[1]],表示最多飞i次航班到达航班x的目的地的最低价格,用最多飞i-1次航班,到达航班x的起点的价格加上航班x的价格之和,二者中取较小值更新即可,参见代码如下:
解法三:
class Solution {
public:
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K) {
vector<vector<int>> dp(K + , vector<int>(n, 1e9));
dp[][src] = ;
for (int i = ; i <= K + ; ++i) {
dp[i][src] = ;
for (auto x : flights) {
dp[i][x[]] = min(dp[i][x[]], dp[i - ][x[]] + x[]);
}
}
return (dp[K + ][dst] >= 1e9) ? - : dp[K + ][dst];
}
};
我们可以稍稍优化下上面解法的空间复杂度,使用一个一维的DP数组即可,具体思路没有啥太大的区别,参见代码如下:
解法四:
class Solution {
public:
int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int K) {
vector<int> dp(n, 1e9);
dp[src] = ;
for (int i = ; i <= K; ++i) {
vector<int> t = dp;
for (auto x : flights) {
t[x[]] = min(t[x[]], dp[x[]] + x[]);
}
dp = t;
}
return (dp[dst] >= 1e9) ? - : dp[dst];
}
};
类似题目:
参考资料:
https://leetcode.com/problems/cheapest-flights-within-k-stops/discuss/115596/c++-8-line-bellman-ford
LeetCode All in One 题目讲解汇总(持续更新中...)
[LeetCode] Cheapest Flights Within K Stops K次转机内的最便宜的航班的更多相关文章
- [LeetCode] 787. Cheapest Flights Within K Stops K次转机内的最便宜航班
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a pri ...
- LeetCode 787. Cheapest Flights Within K Stops
原题链接在这里:https://leetcode.com/problems/cheapest-flights-within-k-stops/ 题目: There are n cities connec ...
- 【LeetCode】787. Cheapest Flights Within K Stops 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 方法一:DFS 方法二:BFS 参考资料 日期 题目 ...
- [Swift]LeetCode787. K 站中转内最便宜的航班 | Cheapest Flights Within K Stops
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a pri ...
- [LeetCode] 787. Cheapest Flights Within K Stops_Medium tag: Dynamic Programming, BFS, Heap
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a pri ...
- 787. Cheapest Flights Within K Stops
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a pri ...
- 【力扣leetcode】-787. K站中转内最便宜的航班
题目描述: 有 n 个城市通过一些航班连接.给你一个数组 flights ,其中 flights[i] = [fromi, toi, pricei] ,表示该航班都从城市 fromi 开始,以价格 p ...
- Leetcode 703. 数据流中的第K大元素
1.题目要求 设计一个找到数据流中第K大元素的类(class).注意是排序后的第K大元素,不是第K个不同的元素. 你的 KthLargest 类需要一个同时接收整数 k 和整数数组nums 的构造器, ...
- LeetCode:数组中的第K个最大元素【215】
LeetCode:数组中的第K个最大元素[215] 题目描述 在未排序的数组中找到第 k 个最大的元素.请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素. 示例 1: ...
随机推荐
- [再寄小读者之数学篇](2014-06-22 不等式 [中国科学技术大学2011年高等数学B考研试题])
证明不等式: $$\bex 1+x\ln\sex{x+\sqrt{1+x^2}}>\sqrt{1+x^2},\quad x>0. \eex$$ 证明: 令 $x=\tan t,\ 0< ...
- Kotlin 的优缺点
从Android 7.0开始,谷歌使用的API从Oracle JDK切换到了open JDK,这对于谷歌来说是一个艰难的决定.对于开发者来说,却倍感兴奋,这意味着长期的官司问题也许就此结束,Andro ...
- Python面试题目之Python函数默认参数陷阱
请看如下一段程序: def extend_list(v, li=[]): li.append(v) return li list1 = extend_list(10) list2 = extend_l ...
- [51nod1965]奇怪的式子
noteskey 怎么说,魔性的题目...拿来练手 min_25 正好...吧 首先就是把式子拆开来算贡献嘛 \[ANS=\prod_{i=1}^n \sigma_0(i)^{\mu(i)} \pro ...
- ansible 使用记录
copy: ansible server -m copy -a 'src=/etc/ansible/port/iptables dest=/etc/sysconfig/iptables owner=r ...
- 【原创】运维基础之Docker(3)搭建私有仓库
下载并启动registry $ docker pull registry$ docker run --name my_registry -d -p 5000:5000 -v /var/lib/regi ...
- HTML5 图片下载
1. 概述 1.1 说明 在项目过程中,有时候需要下载某一展示图片,html5中定义了<a> download属性,download属性规定被下载的超链接目标,该属性可以设置一个值来规定下 ...
- verilog 仿真时读取txt文件
:]data; initial begin # clk =; clk = ~clk; end initial begin # rst=; # rst=; end :]data_sin[:]; //// ...
- Niagara workbench (Basic )
1.the basic information about workbench Last saved station open in the workbench or opened another ...
- bzoj 3277
十分之恶心的后缀自动机 (其实是水题,但是我太弱了...) 首先,有一个预备知识:bzoj 2780https://blog.csdn.net/lleozhang/article/details/89 ...