Scrapy爬虫错误日志汇总
1、数组越界问题(list index out of range)

原因:第1种可能情况:list[index]index超出范围,也就是常说的数组越界。
第2种可能情况:list是一个空的, 没有一个元素,进行list[0]就会出现该错误,这在爬虫问题中很常见,比如有个列表爬下来为空,统一处理就会报错。
解决办法:从你的网页内容解析提取的代码块中找找看啦(人家比较习惯xpath + 正则),加油 ~
---------------------------------------------------华丽的分隔符------------------------------------------------------------
2、http状态代码没有被处理或不允许(http status code is not handled or not allowed)

原因:第1种情况:就是你的http状态码没有被识别,需要在settings.py中添加这个状态码信息,相当于C语言中的#define预处理宏定义命令吧
第2种情况:403是网页状态码,表示访问拒绝或者禁止访问。应该是你触发到网站的反爬虫机制了。
解决办法:如果是第1种情况,在你的setting.py中,添这么一句短小精悍的话就OK了,紧接着就等着高潮吧您呐:HTTPERROR_ALLOWED_CODES = [403]
如果是第2种情况,a.伪造报文头部user-agent(网上有详细教程不用多说)
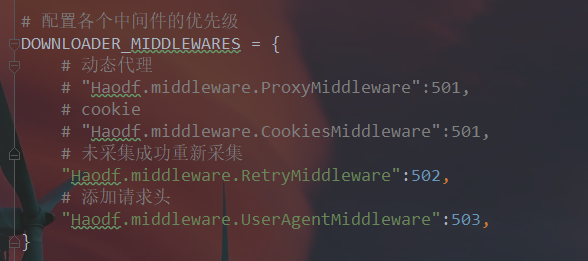
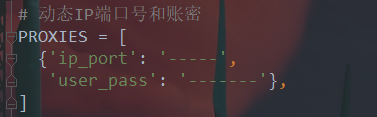
b.使用可用代理ip,如果你的代理不可用也会访问不了
c.是否需要帐户登录,使用cookielib模块登录帐户操作
如果以上方法还是不行,那么你的ip已被拉入黑名单静止访问了。等一段时间再操作。如果等等了还是不行的话:
d.使用phatomjs或者selenium模块试试。
还不行使用别的scrapy爬虫框架看看。
以上都不行,说明这网站反爬机制做的很好,爬不了了,没法了,不过我觉得很少有这种做得很好的网站
---------------------------------------------------华丽的分隔符------------------------------------------------------------
此篇文章持续更新,未完待续....
欢迎大家留下自己的问题,互相讨论,互相学习,互相总结,,,,
Scrapy爬虫错误日志汇总的更多相关文章
- Python2.7集成scrapy爬虫错误解决
运行报错: NotSupported: Unsupported URL scheme 'https':.... 解决方法:降低对应package的版本 主要是scrapy和pyOpenSSL的版本 具 ...
- Scrapy爬虫框架示意图汇总
- scrapy爬虫,cmd中执行日志中显示了爬取的内容,但是运行时隐藏日志后(运行命令后添加--nolog),就没有输出结果了
cmd下执行scrapy爬虫程序,不报错也没有输出,解决方案 想要执行parse能够在cmd看到parse函数的执行结果: 解决方法: settings.py 中设置 ROBOTSTXT_OBEY ...
- scrapy爬虫框架setting模块解析
平时写爬虫的时候并不需要设置setting里所有的参数,今天心血来潮,花了点时间查了一下setting模块创建后自动写入的所有参数的含义,记录一下. 模块相关说明信息 # -*- coding: ut ...
- scrapy框架的日志等级和请求传参, 优化效率
目录 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 请求传参 如何提高scripy的爬取效率 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 在使 ...
- liunx系统下crontab定时启动Scrapy爬虫程序
定时启动爬虫 # 查看命令得绝对路径 # which scrapy # cd到爬虫得项目目录下 + scrapy命令得绝对路径 + 启动命令 */5 * * * * cd /opt/mafengwo/ ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 基于scrapy爬虫的天气数据采集(python)
基于scrapy爬虫的天气数据采集(python) 一.实验介绍 1.1. 知识点 本节实验中将学习和实践以下知识点: Python基本语法 Scrapy框架 爬虫的概念 二.实验效果 三.项目实战 ...
随机推荐
- django+javascrpt+python实现私有云盘代码
丁丁:由于篇幅有限,这里暂时只展示python后端代码,前端js代码后面上传,有需要的也可以留言私信我. 1.view.py 使用用户.部门.公司等相关账号的创建,已经个人,部门账号的冻结,删除,相关 ...
- unittest中常用的几个断言
a.相等 (a==b)内容一样,类型一致 from init import * import unittest class Baidu_Title(Info): def test_baidu_titl ...
- python os.walk()方法--遍历当前目录的方法
前记:有个奇妙的想法并想使用代码实现,发现了一个坑,百度了好久也没发现的"填坑"的文章~~~~~~~~~ 那就由我来填 os.walk()支持相对路径 例如 os.walk(&qu ...
- 20190108C++MFC error 2065 未定义XX原因以及解决方式
今天写界面的时候,明明直接在rc和reourse.h里面加了控件下面是rc和reourse.h照片 编辑的时候一直报错,找了很久发现是新定义的控件有两处定义,定义到其他工程里了所以才会这样,把其他工程 ...
- Lua学习----零碎知识点
Jit(just in time) 动态即时编译,边运行时边编译---->lua (主要是面向进程) Aot(ahead of time) 静态提前编译,运行前编译---->C#(主要是面 ...
- 动态添加echarts
本次只贴js和jsp代码 jsp只需添加一个div即可, <div class="fLayout-right-box"> <hy:layoutArea width ...
- 一·PTA实验作业
本周要求挑选3道题目写设计思路,调试过程.设计思路用伪代码描述.题目选做要求: 顺序表选择一题(6-2,6-3,7-1选一题) 单链表选择一题(6-1不能选) 有序表选择一题 一.题目 6-3 jmu ...
- Windows10获取VS管理员权限总是很烦人
之前在Windows 7中,只要关闭了UAC,给当前账户管理员权限,任何程序都会以管理员身份启动.现在,在Windows 10上就行不通了.而VS又需要管理员权限才能使用附加调试等一些功能.虽然我们可 ...
- TCP协议学习总结(上)
在计算机领域,数据的本质无非0和1,创造0和1的固然伟大,但真正百花齐放的还是基于0和1之上的各种层次之间的组合(数据结构)所带给我们人类各种各样的可能性.例如TCP协议,我们的生活无不无时无刻的站在 ...
- 1.4 The usage of plug-in
Once upon a time, we once thought naively that Android plug-in was intended to add new features or a ...