利用yarn capacity scheduler在EMR集群上实现大集群的多租户的集群资源隔离和quota限制
转自:https://m.aliyun.com/yunqi/articles/79700
背景
使用过hadoop的人基本都会考虑集群里面资源的调度和优先级的问题,假设你现在所在的公司有一个大hadoop的集群,有很多不同的业务组同时使用。但是A项目组经常做一些定时的BI报表,B项目组则经常使用一些软件做一些临时需求。那么他们肯定会遇到同时提交任务的场景,这个时候到底如何分配资源满足这两个任务呢?是先执行A的任务,再执行B的任务,还是同时跑两个?
目前一些使用EMR的大公司,会使用一个比较大的集群,来共公司内部不同业务组的人共同使用,相对于使用多个小集群,使用大的集群一方面可以达到更高的最大性能,根据不同业务的峰谷情况来调度从而获得更高的资源利用里,降低总成本。另外一个方面,能够更好地在不同的业务组之间实现资源的共享和数据的流动。下面结合EMR集群,介绍一下如何进行大集群的资源quota管控。
yarn默认提供了两种调度规则,capacity scheduler和fair scheduler。现在使用比较多的是capacity scheduler。具体的实现原理和调度源码可以google一下capacity scheduler。
什么是capacity调度器
Capacity调度器说的通俗点,可以理解成一个个的资源队列。这个资源队列是用户自己去分配的。比如我大体上把整个集群分成了queue1queue2两个队列,queue1是给一个业务组使用queue2给另外一个业务组使用。如果第一个业务组下面又有两个方向,那么还可以继续分,比如专门做BI的和做实时分析的。那么队列的分配就可以参考下面的树形结构:
root
------default[20%]
------q1[60%]
|---q1.q11[70%]
|---q1.q12[30%]
------q2[20%]整个集群的queue必须挂在root下面。分成三个queue:default,q1和q2。三个队列使用集群资源的quota配比为:20%,60%,20%。default这个queue是必须要存在的。
虽然有了这样的资源分配,但是并不是说提交任务到q2里面,它就只能使用20%的资源,即使剩下的80%都空闲着。它也是能够实现(通过配置),只要资源实在空闲状态,那么q2就可以使用100%的资源。但是一旦其它队列提交了任务,q2就需要在释放资源后,把资源还给其它队列,直到达到预设de配比值。粗粒度上资源是按照上面的方式进行,在每个队列的内部,还是按照FIFO的原则来分配资源的。
capacity调度器特性
capacity调度器具有以下的几个特性:
- 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
容量保证,队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源。 - 安全,每个队列又严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
- 弹性分配,空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
- 多租户租用,通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。
- 操作性,yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。还提供给管理员界面,来显示当前的队列状况。管理员可以在运行时,添加一个队列;但是不能删除一个队列。管理员还可以在运行时暂停某个队列,这样可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了stopped,那么就不能向他或者子队列上提交任务了。
capacity调度器的配置
登录EMR集群master节点,编辑配置文件:/etc/emr/hadoop-conf/capacity-scheduler.xml
这里先贴出来完整的比较复杂一点的配置,后面再详细说明:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>Maximum number of applications that can be pending and running.</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.25</value>
<description>Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications.</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>The ResourceCalculator implementation to be used to compare Resources in the scheduler. The default i.e. DefaultResourceCalculator only uses Memory while DominantResourceCalculator uses dominant-resource to compare multi-dimensional resources such as Memory, CPU etc.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,q1,q2</value>
<description>The queues at the this level (root is the root queue).</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.queues</name>
<value>q11,q12</value>
<description>The queues at the this level (root is the root queue).</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>20</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.capacity</name>
<value>60</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q2.capacity</name>
<value>20</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.q11.capacity</name>
<value>70</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.q11.maximum-capacity</name>
<value>90</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.q11.minimum-user-limit-percent</name>
<value>25</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.q12.capacity</name>
<value>30</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.q12.user-limit-factor</name>
<value>0.7</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q2.user-limit-factor</name>
<value>0.4</value>
<description>Default queue user limit a percentage from 0.0 to 1.0.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q2.maximum-capacity</name>
<value>100</value>
<description>The maximum capacity of the default queue.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.state</name>
<value>RUNNING</value>
<description>The state of the default queue. State can be one of RUNNING or STOPPED.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q2.state</name>
<value>RUNNING</value>
<description>The state of the default queue. State can be one of RUNNING or STOPPED.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.acl_submit_applications</name>
<value>*</value>
<description>The ACL of who can submit jobs to the default queue.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q2.acl_submit_applications</name>
<value>*</value>
<description>The ACL of who can submit jobs to the default queue.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.acl_administer_queue</name>
<value>*</value>
<description>The ACL of who can administer jobs on the default queue.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q2.acl_administer_queue</name>
<value>*</value>
<description>The ACL of who can administer jobs on the default queue.</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>Number of missed scheduling opportunities after which the CapacityScheduler attempts to schedule rack-local containers. Typically this should be set to number of nodes in the cluster, By default is setting approximately number of nodes in one rack which is 40.</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value/>
<description>A list of mappings that will be used to assign jobs to queues The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]* Typically this list will be used to map users to queues, for example, u:%user:%user maps all users to queues with the same name as the user.</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
<description>If a queue mapping is present, will it override the value specified by the user? This can be used by administrators to place jobs in queues that are different than the one specified by the user. The default is false.</description>
</property>
</configuration>在hadoop帐号下,执行命令刷新一下queue配置:/usr/lib/hadoop-current/bin/yarn rmadmin -refreshQueues
然后打开hadoop ui,就能看到效果: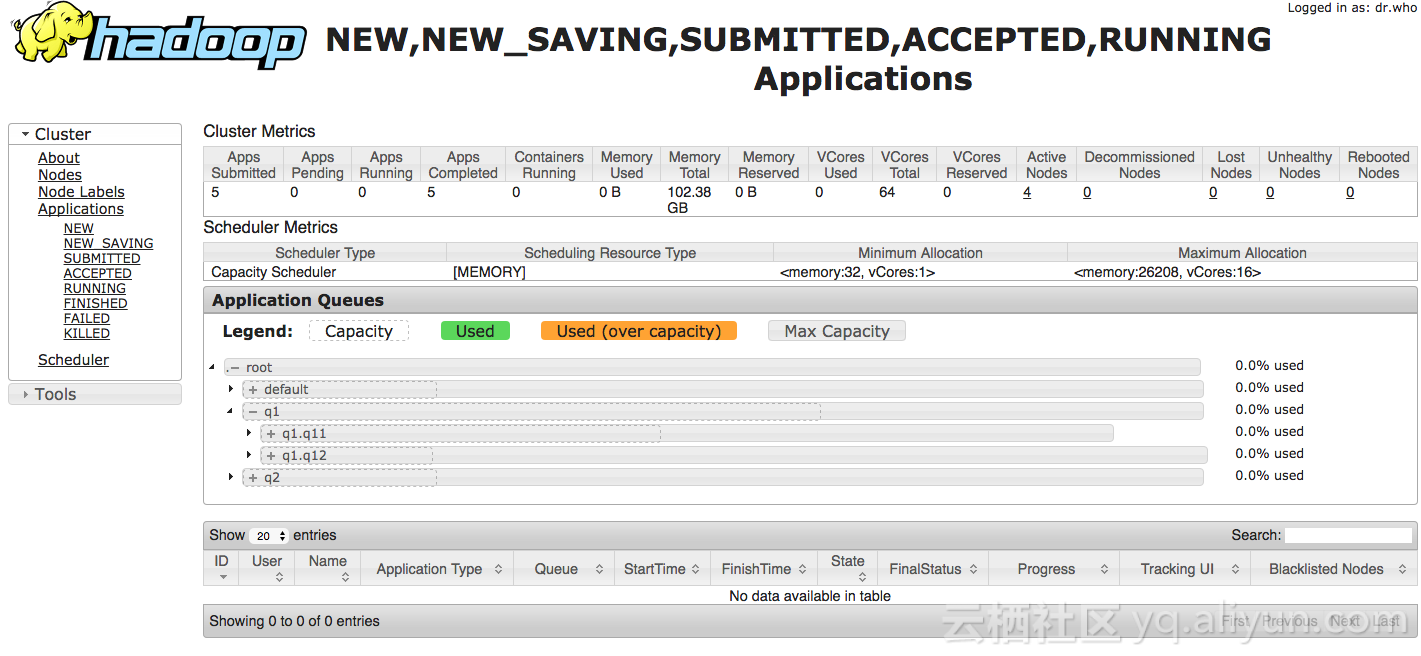
参数说明
- 队列属性:
yarn.scheduler.capacity.${quere-path}.capacity - 例如下面的配置,表示共三个大的queue,default,q1,q2,q1下面又分了两个queue q11,q12。
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,q1,q2</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.queues</name>
<value>q11,q12</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>- 下面的配置设置每个queue的资源quota配比:
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>20</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.capacity</name>
<value>60</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q2.capacity</name>
<value>20</value>
<description>Default queue target capacity.</description>
</property>- 设置q1大队列下面的两个小队列的资源quota配比:
<property>
<name>yarn.scheduler.capacity.root.q1.q11.capacity</name>
<value>70</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.q1.q12.capacity</name>
<value>30</value>
<description>Default queue target capacity.</description>
</property>- 下面的配置表示,q1.q11这个queue,能够使用q1所有资源的最大比例,q1.q11分配的资源原本是占q1总资源的70%(见上面配置),但是如果q1里面没有其它作业在跑,都是空闲的,那么q11是可以使用到q1总资源的90%。但是如果q1里面没有这么多空闲资源,q11
只能使用到q1总资源的70%:
<property>
<name>yarn.scheduler.capacity.root.q1.q11.maximum-capacity</name>
<value>90</value>
<description>Default queue target capacity.</description>
</property>- 下面的配置表示q1.q11里面的作业的保底资源要有25%,意思是说,q1下面的总资源至少还要剩余25%,q11里面的作业才能提上来,如果q1下面的总资源已经小于25%了,那么往q11里面提作业就要等待:
<property>
<name>yarn.scheduler.capacity.root.q1.q11.minimum-user-limit-percent</name>
<value>25</value>
<description>Default queue target capacity.</description>
</property>另外一些比较重要的ACL配置:
- yarn.scheduler.capacity.root.q1.acl_submit_applications 表示哪些user/group可以往q1里面提作业;
- yarn.scheduler.capacity.queue-mappings 这个比较强大,可以设定user/group和queue的映射关系,格式为[u|g]:[name]:queue_name*
操作示例
本文使用的EMR集群配置: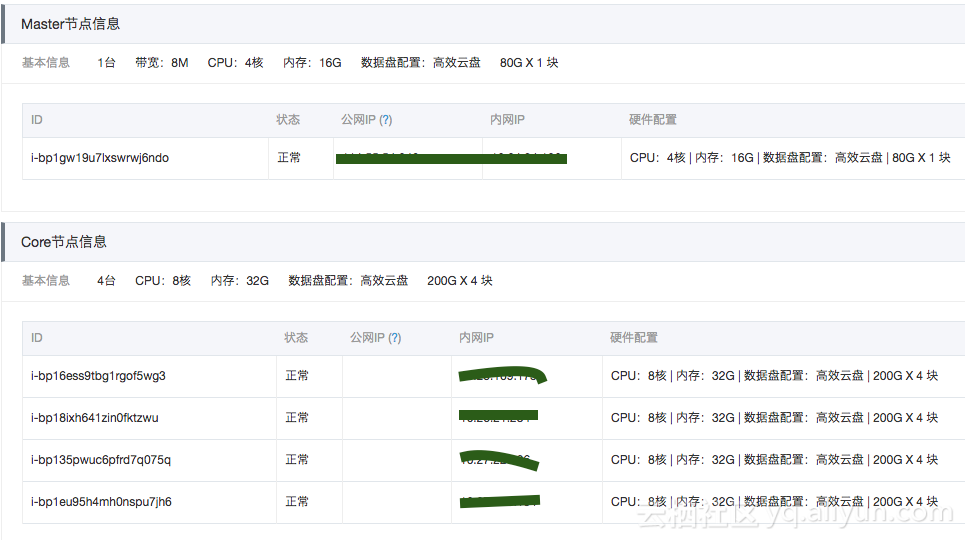
- 注意,如果不指定queue,则默认往default提交:
hadoop jar /usr/lib/hadoop-current/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=100000000000 /HiBench/Wordcount/Input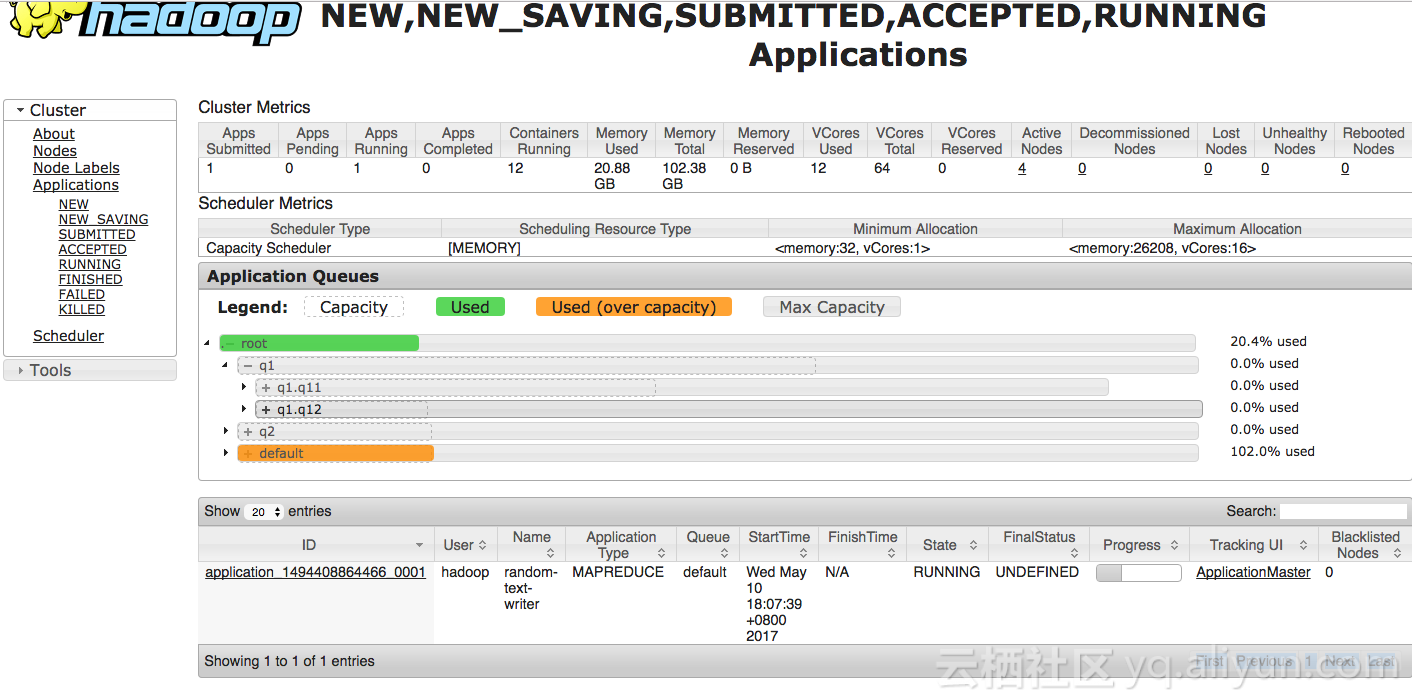
- 如果指定一个不存在的queue,则会报错
hadoop jar /usr/lib/hadoop-current/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=100000000000 -D mapreduce.job.queuename=notExist /HiBench/Wordcount/Input3Caused by: org.apache.hadoop.yarn.exceptions.YarnException: Failed to submit application_1494398749894_0010 to YARN : Application application_1494398749894_0010 submitted by user hadoop to unknown queue: notExist- 再往default里面提交job,发现作业等待,因为default的20% quota已经用完。
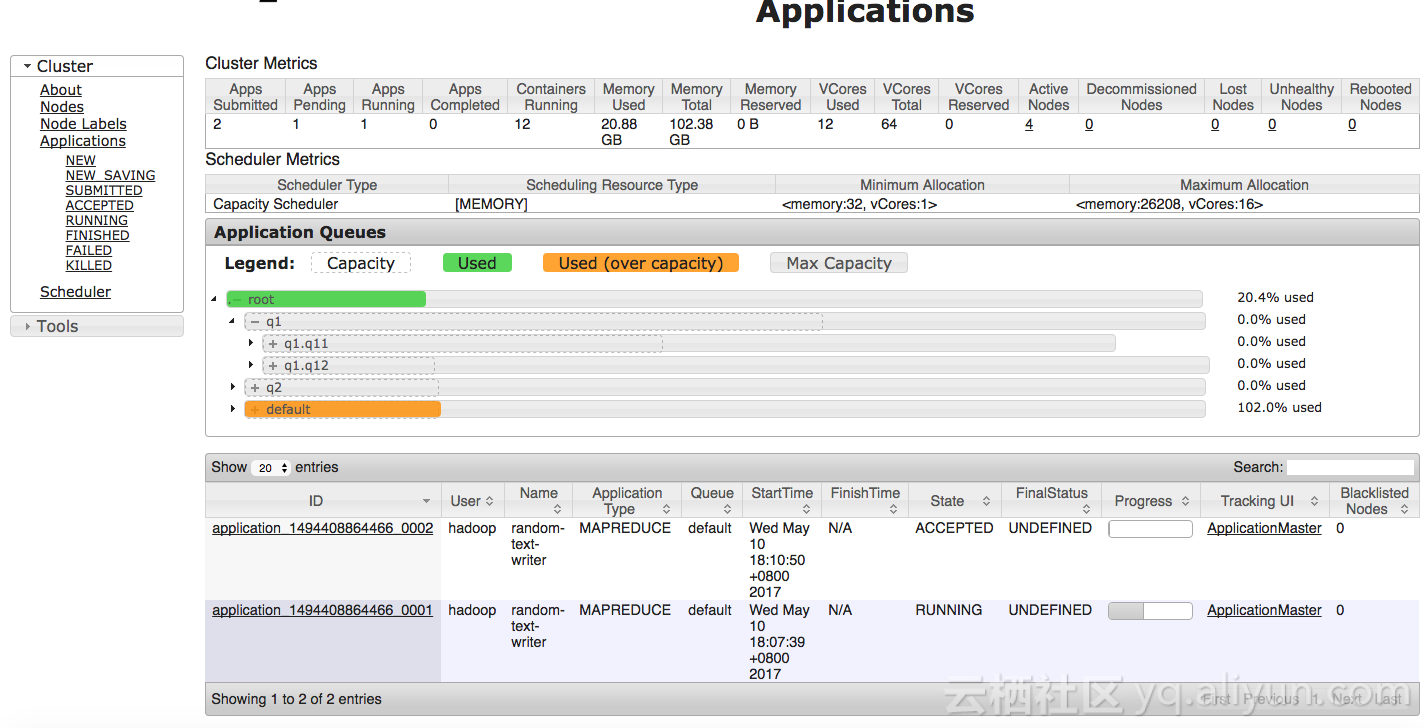
- 然后往q2里面提交一个作业:
hadoop jar /usr/lib/hadoop-current/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=100000000000 -D mapreduce.job.queuename=q2 /HiBench/Wordcount/Input3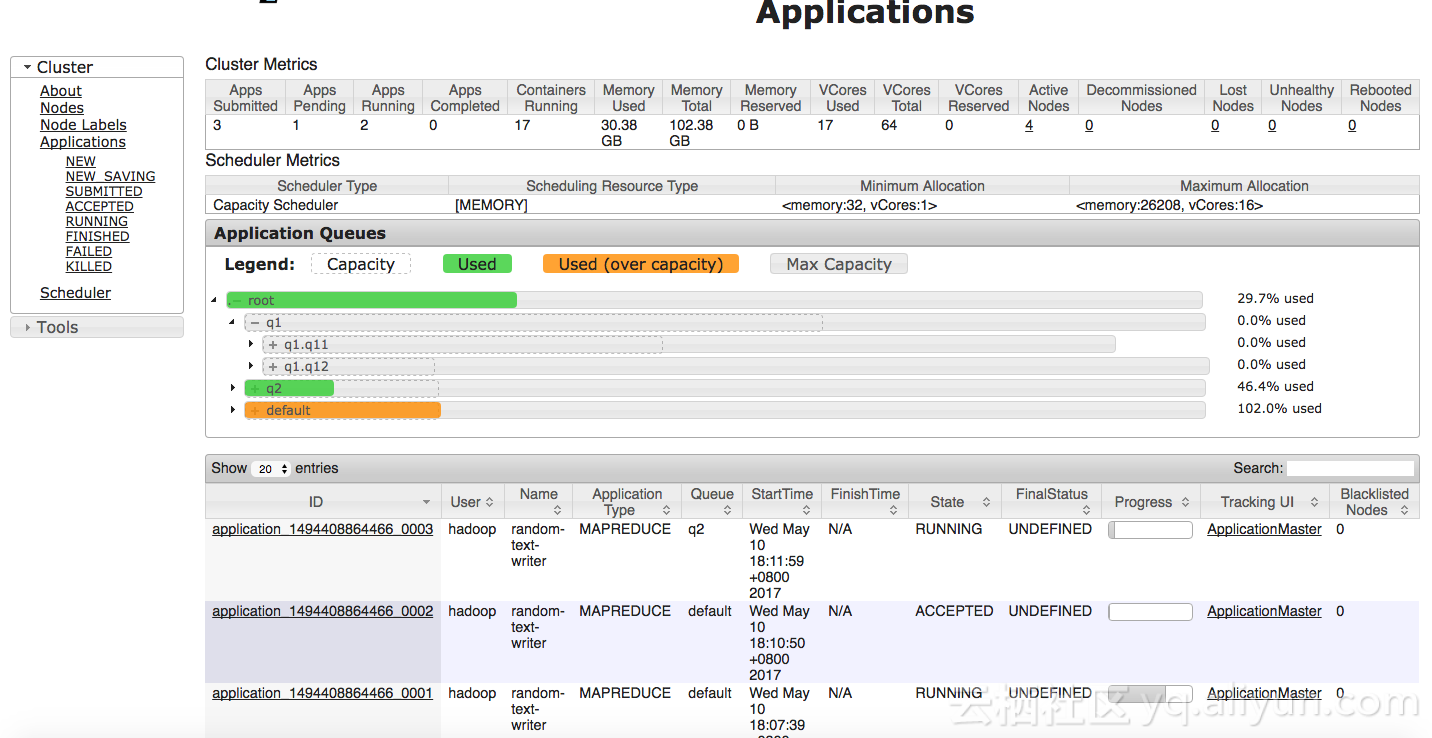
设置了q2单个作业不能超过q2总队列资源的40%,可以看到只用到50%多,尽管还有其它map在等待,也是不会占用更大资源。当然,这里不是非常精确,跟集群总体配置和每个map占用的资源有关,一个map占用的资源可以看成最小单元,一个map占用的资源不一定正好到达设定的比例,有可能会超过一点。
- 往q1.q12里面提交job
hadoop jar /usr/lib/hadoop-current/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=100000000000 -D mapreduce.job.queuename=q12 /HiBench/Wordcount/Input4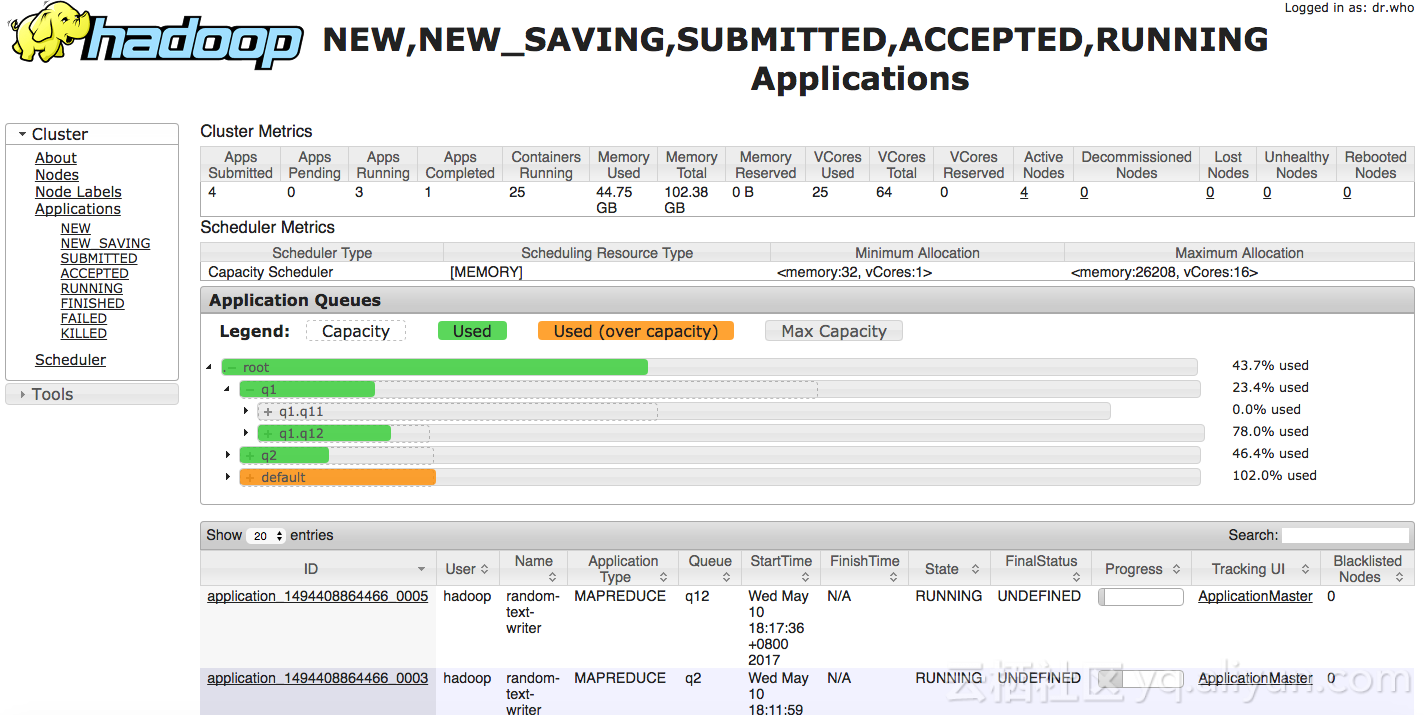
可以看到,q12也设置了yarn.scheduler.capacity.root.q1.q12.user-limit-factor为0.7,可以看到只占用了q12的78%。
- 往q11里面提交一个作业,会发现它直接占满了q11,是因为q11设置了yarn.scheduler.capacity.root.q1.q11.maximum-capacity为90%,即q11能占到q1总资源的90%。
hadoop jar /usr/lib/hadoop-current/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=100000000000 -D mapreduce.job.queuename=q11 /HiBench/Wordcount/Input5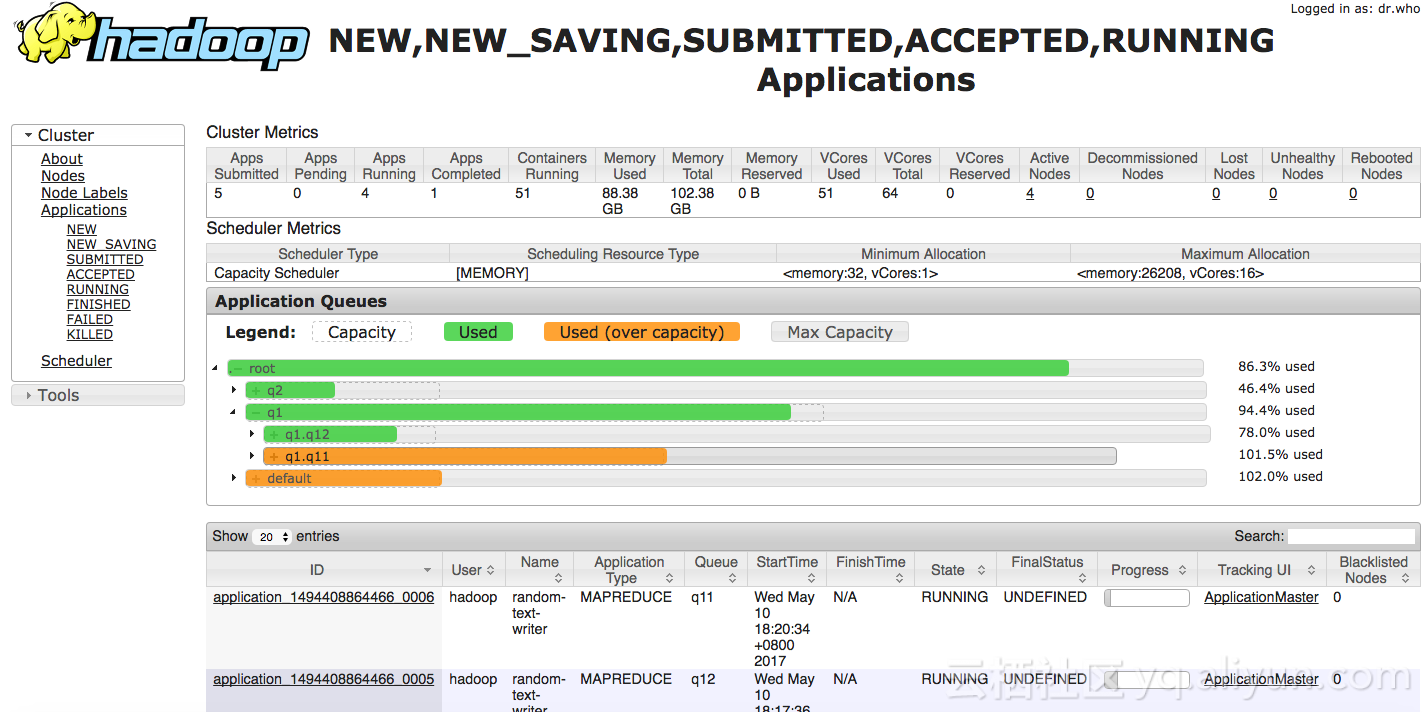
通过上面的例子,可以看到yarn的capacity scheduler还是很强大的,可以实现对集群资源的控制和优先级调度。以上例子中使用了hadoop作业,指定queue的参数为-D mapreduce.job.queuename=${queue-name},如果是spark作业,可以用--queue ${queue-name}指定。以上作业的提交方式可以直接在EMR控制台的作业中设置。
利用yarn capacity scheduler在EMR集群上实现大集群的多租户的集群资源隔离和quota限制的更多相关文章
- <Yarn> <Capacity Scheduler> <Source Code>
Yarn capacity scheduler 首先要知道, [Attention: RM有两个组件,其中Scheduler完全就只是负责资源的分配:ApplicationsManager则负责接受a ...
- Hadoop Yarn Capacity Scheduler
Capacity 调度器配置 <property> <name>yarn.resourcemanager.scheduler.class<name> <val ...
- hadoop 把mapreduce任务从本地提交到hadoop集群上运行
MapReduce任务有三种运行方式: 1.windows(linux)本地调试运行,需要本地hadoop环境支持 2.本地编译成jar包,手动发送到hadoop集群上用hadoop jar或者yar ...
- Hadoop的三种调度器FIFO、Capacity Scheduler、Fair Scheduler(转载)
目前Hadoop有三种比较流行的资源调度器:FIFO .Capacity Scheduler.Fair Scheduler.目前Hadoop2.7默认使用的是Capacity Scheduler容量调 ...
- Hadoop Yarn内存资源隔离实现原理——基于线程监控的内存隔离方案
注:本文以hadoop-2.5.0-cdh5.3.2为例进行说明. Hadoop Yarn的资源隔离是指为运行着不同任务的“Container”提供可独立使用的计算资源,以避免它们之间相互干扰.目 ...
- YARN资源调度策略之Capacity Scheduler
背景 yarn默认使用的是最简单的FIFO调度器,即一个default队列,所有用户共享,分配资源也是先到先得,没有优先级之分.有时一两个任务就把资源全占了,其他任务吃不到资源造成饥饿,显然这样的资源 ...
- YARN的Fair Scheduler和Capacity Scheduler
关于Scheduler YARN有四种调度机制:Fair Schedule,Capacity Schedule,FIFO以及Priority: 其中Fair Scheduler是资源池机制,进入到里面 ...
- 012 Spark在IDEA中打jar包,并在集群上运行(包括local模式,standalone模式,yarn模式的集群运行)
一:打包成jar 1.修改代码 2.使用maven打包 但是目录中有中文,会出现打包错误 3.第二种方式 4.下一步 5.下一步 6.下一步 7.下一步 8.下一步 9.完成 二:在集群上运行(loc ...
- 有关python numpy pandas scipy 等 能在YARN集群上 运行PySpark
有关这个问题,似乎这个在某些时候,用python写好,且spark没有响应的算法支持, 能否能在YARN集群上 运行PySpark方式, 将python分析程序提交上去? Spark Applicat ...
随机推荐
- 清北澡堂 Day2 下午 一些比较重要的数论知识整理
1.欧拉定理 设x1,x2,.....,xk,k=φ(n)为1~n中k个与n互质的数 结论一:axi与axj不同余 结论二:gcd(axi,n)=1 结论三:x1,x2,...,xk和ax1,ax2, ...
- 【并发编程】【JDK源码】CAS与synchronized
线程安全 众所周知,Java是多线程的.但是,Java对多线程的支持其实是一把双刃剑.一旦涉及到多个线程操作共享资源的情况时,处理不好就可能产生线程安全问题.线程安全性可能是非常复杂的,在没有充足的同 ...
- 关于vue的域名重定向和404
//创建路由对象并配置路由规则 let router = new VueRouter({ routes:[ {path:'/',redirect:{name:"index"}}, ...
- centos中编译安装nginx+mysql +php(未完)
参考地址:http://www.cnblogs.com/htian/p/5728599.html 去官网找到PCRE,并下载http://www.pcre.org/wget ftp://ftp.csx ...
- Pandas系列(十)-转换连接详解
目录 1. 拼接 1.1 append 1.2 concat 2. 关联 2.1 merge 2.2 join 数据准备 # 导入相关库 import numpy as np import panda ...
- Eclipse之JSP页面的使用
Eclipse之JSP页面的使用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用Eclipse创建JSP文件 1>.点击new file,选择jsp File 2&g ...
- 17、 利用扇贝网:https://www.shanbay.com/, 做个测单词的小工具。
先说下,我可以说完全没有看题目要求,我只看了下扇贝网的单词测试工具就开始编码了,写出来的代码尽可能的模仿了网站上的效果. 因为把问题搞复杂了,在这个练习上耽误了很长时间,最后都不想写了,所以代码有些混 ...
- EffectiveC++ 第3章 资源管理
我根据自己的理解,对原文的精华部分进行了提炼,并在一些难以理解的地方加上了自己的"可能比较准确"的「翻译」. Chapter 3 资源管理 条款13: 以对象管理资源 有时即使你顺 ...
- pip 安装问题
同时安装了Python2 和Python3的情况下,由于我的电脑默认的是使用Python3,pip的时候直接就安装在3上了,为了让2也安装,办法之一就是在安装python2的路径下比如,D:\Anac ...
- sessionStorage数组、对象的存储和读取
一个对象的demo如下: var obj = { name:"name", age:18, love:"美女" } sessionStorage.setItem ...