Lucene 08 - 什么是Lucene的相关度排序 + Java API调整相关度
1 什么是相关度
概念: 相关度指两个事物之间的关联关系(相关性). Lucene中指的是搜索关键词(Term)与搜索结果之间的相关性. 比如搜索bookname域中包含java的图书, 则根据java在bookname中出现的次数和位置来判断结果的相关性.
2 相关度评分
Lucene对查询关键字和索引文档的相关度进行打分, 得分越高排序越靠前.
(1) Lucene的打分方法: Lucene在用户进行检索时根据实时搜索的关键字计算分值, 分两步:
① 计算出词(Term)的权重;
② 根据词的权重值, 计算文档相关度得分.
(2) 什么是词的权重?
通过索引部分的说明, 易知索引的最小单位是Term(索引词典中的一个词). 搜索也是从索引域中查询Term, 再根据Term找到文档. **Term对文档的重要性称为Term的权重. **
(3) 影响Term权重的因素有两个:
① Term Frequency(tf): **指这个Term在当前的文档中出现了多少次. tf 越大说明越重要. **
词(Term)在文档中出现的次数越多, 说明此词(Term)对该文档越重要, 如"Lucene"这个词, 在文档中出现的次数很多, 说明该文档可能就是讲Lucene技术的.
② Document Frequency(df): **指有多少个文档包含这个Term. df 越大说明越不重要. **
比如: 在某篇英文文档中, this出现的次数很多, 能说明this重要吗? 不是的, 有越多的文档包含此词(Term), 说明此词(Term)越普通, 不足以区分这些文档, 因而重要性越低.
3 相关度设置
Lucene通过设置关键词Term的权重(boost)值, 影响相关度评分, 从而影响搜索结果的排序.
3.1 更改相关度的需求
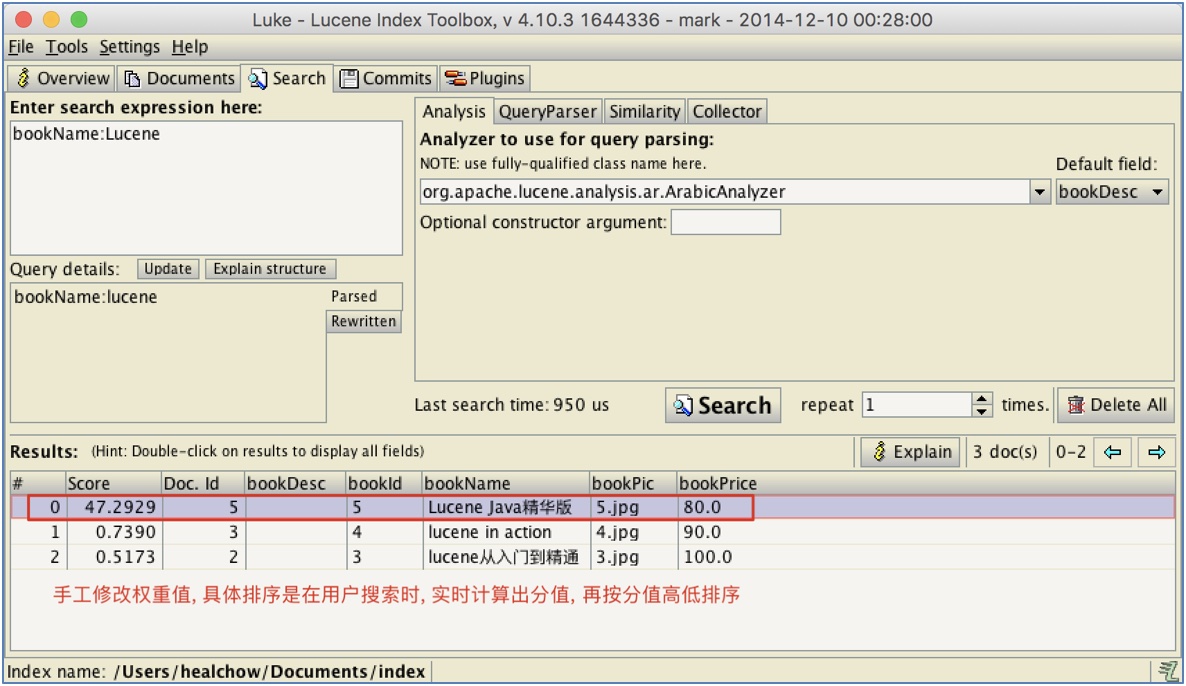
出版社做了广告推广: 收到广告费之后, 将《Lucene Java精华版》排到第一.

3.2 实现需求-设置广告
/**
* 相关度排序, 通过修改索引库的方式, 修改需要更改的图书的权重
*/
@Test
public void updateIndexBoost() throws IOException {
// 1.建立分析器对象(Analyzer), 用于分词
Analyzer analyzer = new IKAnalyzer();
// 2.建立索引库配置对象(IndexWriterConfig), 配置索引库
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_4_10_4, analyzer);
// 3.建立索引库目录对象(Directory),指定索引库位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 4.建立索引库操作对象(IndexWriter), 操作索引库
IndexWriter writer = new IndexWriter(directory,iwc);
// 5.建立文档对象(Document)
Document doc = new Document();
// 5 Lucene Java精华版 80 5.jpg
doc.add(new StringField("bookId", "5", Store.YES));
TextField nameField = new TextField("bookName", "Lucene Java精华版", Store.YES);
// 设置权重值为100. 默认是1
nameField.setBoost(100f);
doc.add(nameField);
doc.add(new FloatField("bookPrice", 80f, Store.YES));
doc.add(new StoredField("bookPic","5.jpg"));
// 6.建立更新条件对象(Term)
Term term = new Term("bookId", "5");
// 7.使用IndexWriter对象,执行更新
writer.updateDocument(term, doc);
// 8.释放资源
writer.close();
}
// 或在创建索引时即修改权重:
// 打个广告: 收到钱之后, 将《Lucene Java精华版》排到第一
// 5 Lucene Java精华版 80 5.jpg
TestField bookNameField = new TextField("bookName", book.getBookname(), Store.YES);
if (book.getId() == 5) {
// 设置权重值为100. 默认是1
bookNameField.setBoost(100f);
}
document.add(bookNameField);
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Lucene 08 - 什么是Lucene的相关度排序 + Java API调整相关度的更多相关文章
- ElasticSearch排序Java api简单Demo
代码: String time1 = ConstValue.GetCurrentDate(); SortBuilder sortBuilder = SortBuilders.fieldSort(&qu ...
- (四)Lucene——搜索和相关度排序
1. 搜索 1.1 创建查询对象的方式 通过Query子类来创建查询对象 Query子类常用的有:TermQuery.NumericRangeQuery.BooleanQuery 特点:不能输入luc ...
- Lucene系列二:Lucene(Lucene介绍、Lucene架构、Lucene集成)
一.Lucene介绍 1. Lucene简介 最受欢迎的java开源全文搜索引擎开发工具包.提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言).Lucene的目的是为软件开发人 ...
- 使用Lucene的java api 写入和读取索引库
import org.apache.commons.io.FileUtils;import org.apache.lucene.analysis.standard.StandardAnalyzer;i ...
- Lucene 04 - 学习使用Lucene的Field(字段)
目录 1 Field的特性 2 常用的Field类型 3 常用的Field种类使用 3.1 准备环境 3.2 需求分析 3.3 修改代码 3.4 重新建立索引 1 Field的特性 Document( ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- Lucene系列三:Lucene分词器详解、实现自己的一个分词器
一.Lucene分词器详解 1. Lucene-分词器API (1)org.apache.lucene.analysi.Analyzer 分析器,分词器组件的核心API,它的职责:构建真正对文本进行分 ...
- ElasticSearch6.0 Java API 使用 排序,分组 ,创建索引,添加索引数据,打分等(一)
ElasticSearch6.0 Java API 使用 排序,分组 ,创建索引,添加索引数据,打分等 如果此文章对你有帮助,请关注一下哦 1.1 搭建maven 工程 创建web工程 ...
- 第08章 ElasticSearch Java API
本章内容 使用客户端对象(client object)连接到本地或远程ElasticSearch集群. 逐条或批量索引文档. 更新文档内容. 使用各种ElasticSearch支持的查询方式. 处理E ...
随机推荐
- PCB差分线学习
问:何为差分信号? 答:通俗地说,就是驱动端发送两个等值.反相的信号,接收端通过比较这两个电压的差值来判断逻辑状态“0”还是“1”. 问:差分线的优势在哪? 答:差分信号和普通的单端信号走线相比,最明 ...
- Open-Domain QA -paper
Open-domain QA Overview The whole system is consisted with Document Retriever and Document Reader. T ...
- C++入门笔记(二)变量和基本类型
变量和基本类型 一.基本内置类型 1.除去布尔类型和扩展的字符型外,其他整型可以分为带符号的和无符号的. 2.与其他整型不同,字符型被分为了三种:char.signed char 和 unsigned ...
- [CF1093E]Intersection of Permutations
[CF1093E]Intersection of Permutations 题目大意: 给定两个长度为\(n(n\le2\times10^5)\)的排列\(A,B\).\(m(m\le2\times1 ...
- Mem系列函数介绍及案例实现
昨天导师甩给我们一个项目案例,让我们自己去看一看熟悉一下项目内容,我看到了这个项目里面大量使用memset(sBuf,0,sizeof(sBuf));这一块内存填充的代码,于是回想起以前查过Mem ...
- Linux服务器运维基本命令
========Linux 服务器常用命令================ cd / 根目录cd ../ 上级目录 ls 列出文件目录 clear 清空控制台tar cvzf name.C ...
- VS中自定义类模版
以下为vs2017 专业版,安装目录在D盘 安装路径: D:\Program Files (x86)\Microsoft Visual Studio\\Professional\Common7\IDE ...
- for循环语句/命名函数
for(1.表达式1;2.表达式2;3.表达式3){ 4.循环体语句; } 先执行1,在执行2表达式,如果2的表达式为false的话直接退出循环, 如果2的表达式结果为true,执行4,执行3,执行2 ...
- 约瑟夫环问题 --链表 C语言
总共有m个人在圆桌上,依次报名,数到第n个数的人退出圆桌,下一个由退出人下一个开始继续报名,循环直到最后一个停止将编号输出 #include <stdio.h>#include <s ...
- maven_SSM集成的demo
一.集成spring 二.集成springMVC 三.集成mybatis 1. pom.xml <?xml version="1.0" encoding="UTF- ...