ES 31 - 从0开始搭建Elasticsearch生产集群
开始之前:
关于ES单机服务的部署, 可参考博文: ES 02 - 部署Elasticsearch单机服务 + 部署中的常见问题
关于集群的服务配置建议, 可以参考上一篇博文: ES 30 - Elasticsearch生产集群的服务器配置建议
1 配置环境
1.1 服务器IP映射
配置服务器IP地址与主机名称的映射, 方便维护与迁移.
服务器IP 映射的主机名 172.16.22.131 es-1 172.16.22.132 es-2 172.16.22.133 es-3 依次编辑三台服务器的
/etc/hosts文件, 添加映射内容:[root@localhost ~]# vim /etc/hosts # 添加下述内容:
172.16.22.131 es-1
172.16.22.132 es-2
172.16.22.133 es-3
1.2 配置各节点的ssh免密通信
Elasticsearch集群中各个节点之间需要通信, 配置免密通信是必须的.
参考博文 Linux - 配置SSH免密登录 - “ssh-keygen”的基本用法 完成相关免密通信的配置.
1.3 安装JDK并配置环境变量
学习使用ES的前提是成功安装JDK —— 很基础的一项步骤, 这里省略.
此处学习演示所用的JDK版本为:
[root@localhost ~]# java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
2 部署单节点服务
请参照博文 ES 02 - 部署Elasticsearch单机服务 + 部署中的常见问题 进行操作, 如果过程中遇到不可知的问题, 可在评论区留言, 博主会在看到后的第一时间回复.
与部署单机服务不同的地方 —— 修改配置文件/data/elk-6.6.0/es-node/config/elasticsearch.yml:
# 大约17行, 修改集群名称, 同一个集群中此名称必须相同, 才能组成一个逻辑集群:
cluster.name: heal_es
# 大约23行, 修改节点名称, 可以设置为与主机名称相同:
node.name: es-1
# 大约55行, 指定可通过外部服务器访问本地ES服务:
network.host: 0.0.0.0
# 并指定访问的端口号, 默认是9200, 为了防止冲突, 这里修改为9301:
http.port: 9301
# 大约68行, 指定初始的主机列表, 用来在新节点启动时执行发现功能:
discovery.zen.ping.unicast.hosts: ["es-1", "es-2", "es-3"]
注意: 修改完配置后, 先不要启动服务, 所有节点中的安装包都整理完毕, 再依次启动.
—— 因为ES服务一旦启动, 就会在${ES_HOME}/data/下生成集群数据, 包括节点id、节点锁(node lock)等, 不同节点的这些数据都不同, 如果相同则会导致启动异常.
3 部署集群服务
(1) 将配置好的安装包分发到节点es-2和es-3上:
# 切换回root用户
[elastic@localhost data]$ su root
Password:
# 输入密码后, 分发安装包:
[root@localhost data]# scp -r elk-6.6.0/ es-2:/data
[root@localhost data]# scp -r elk-6.6.0/ es-3:/data
(2) 向es-2和es-3中添加elastic用户和组, 并修改文件权限:
[root@localhost data]# useradd elastic -s /bin/bash
[root@localhost data]# chown -R elastic:elastic /data/elk-6.6.0/
(3) 修改es-2和es-3节点的配置文件:
同样的, 修改elasticsearch.yml文件, 这时只修改node名称即可:
[root@localhost ~]# vim /data/elk-6.6.0/es-node/config/elasticsearch.yml
# 大约23行, 修改节点名称, 可以设置为与主机名称相同. 分别修改为es-2和es-3
node.name: es-...
(4) 如有必要-删除从es-1拷贝而来的data目录下的文件:
如果在从es-1节点分发安装包时, 已经启动了es-1上的ES服务, 那么还要删除es-2和es-3节点中${ES_HOME}/data/下的所有文件, 防止后续启动失败.
4 启动集群中的所有节点
4.2 启动各个节点中的ES服务
启动顺序没有要求:
# 切换为elastic用户:
[root@localhost ~]# su elastic
# 进入到启动命令所在的目录:
[elastic@localhost root]$ cd /data/elk-6.6.0/es-node/bin/
# 后台启动服务:
[elastic@localhost bin]$ sh elasticsearch -d
4.2 查看集群状态
(1) 只启动一个节点时的集群状态:
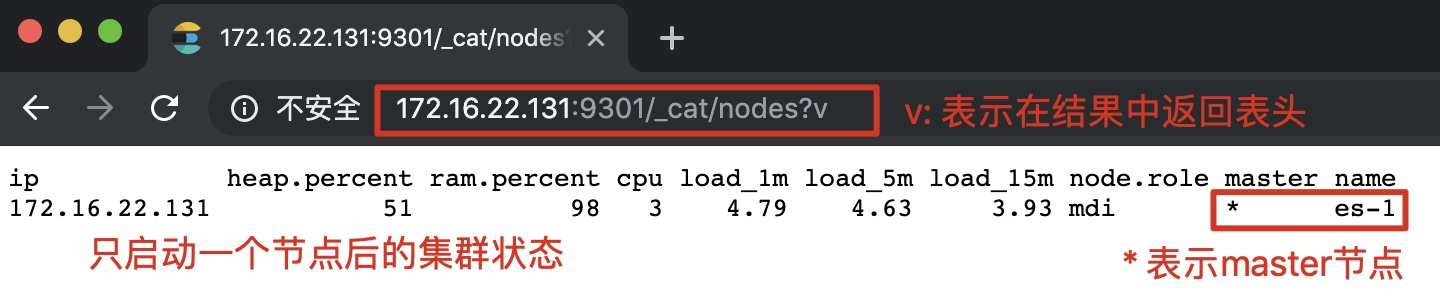
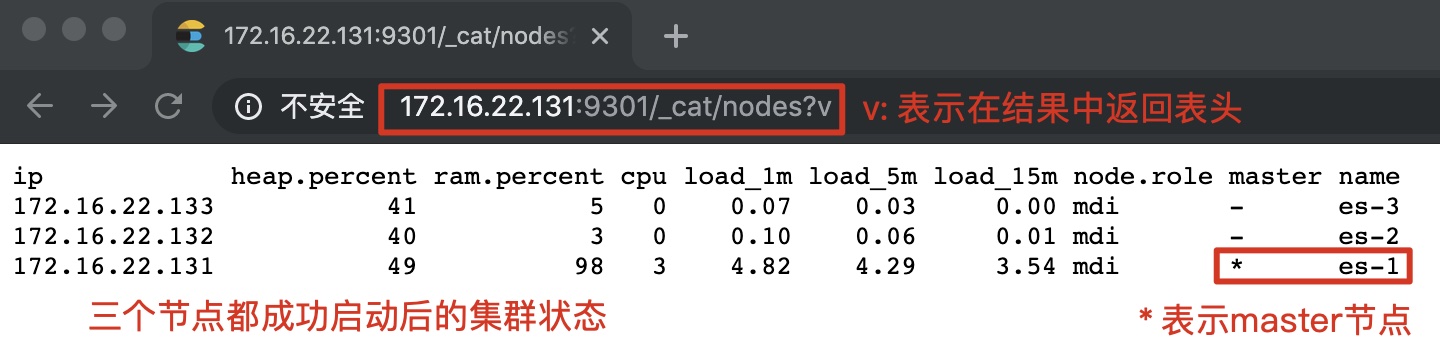
(2) 启动全部节点后的集群状态:
5 常见问题及解决方法
5.1 新节点不能加入集群
(1) 问题描述:
启动集群中的第二、三个节点时可能出现下述异常中的一种:
① 获取node lock失败:
[2019-06-24T22:04:06,665][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [es-3] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: failed to obtain node locks, tried [[/data/elk-6.6.0/es-node/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:163) ~[elasticsearch-6.6.0.jar:6.6.0]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:150) ~[elasticsearch-6.6.0.jar:6.6.0]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86) ~[elasticsearch-6.6.0.jar:6.6.0]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:124) ~[elasticsearch-cli-6.6.0.jar:6.6.0]
at org.elasticsearch.cli.Command.main(Command.java:90) ~[elasticsearch-cli-6.6.0.jar:6.6.0]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:116) ~[elasticsearch-6.6.0.jar:6.6.0]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:93) ~[elasticsearch-6.6.0.jar:6.6.0]
... 6 more
② 加入集群的请求发送失败:
# 节点[es-3]向master节点[es-1]发送加入集群的请求失败.
[es-3] failed to send join request to master [{es-1}{jcmbr9dgRgaAWUE7xq5xAw}{wxvCc19lQvmc3xmcRHdbqA}{172.16.22.131}{172.16.22.131:9300}{ml.machine_memory=134908342272, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true}], reason [RemoteTransportException[[es-1][172.16.22.131:9300][internal:discovery/zen/join]]; # 内部原因是: 节点id相同, 但并不是同一个节点实例.
nested: IllegalArgumentException[can't add node {es-3}{jcmbr9dgRgaAWUE7xq5xAw}{WXjlsD1zTWCm6YaWAAUoOg}{172.16.22.133}{172.16.22.133:9300}{ml.machine_memory=135220408320, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true}, found existing node {es-1}{jcmbr9dgRgaAWUE7xq5xAw}{wxvCc19lQvmc3xmcRHdbqA}{172.16.22.131}{172.16.22.131:9300}{ml.machine_memory=134908342272, xpack.installed=true, ml.max_open_jobs=20, ml.enabled=true} with the same id but is a different node instance]; ]
(2) 问题分析:
节点二、三的安装包都是从节点一分发而来的, 由于分发时节点一已经启动, 其${ES_HOME}/data/目录下已生成node相关的数据, 这些数据应该由当前节点自动生成, 不能共用. 如果这些数据相同就会出现上述异常.
(3) 问题解决:
删除节点二、三的数据目录${ES_HOME}/data/下的所有文件, 然后重新启动即可.
5.2 反序列化失败
(1) 问题说明:
节点启动过程中抛出如下错误:
org.elasticsearch.transport.RemoteTransportException: Failed to deserialize exception response from stream
(2) 问题分析:
各个Elasticsearch节点中的服务所使用的JDK版本不一致, 在 ES 30 - Elasticsearch生产集群的服务器配置建议 的第5节5 JVM的参数配置中有相关说明:
ES中用到了很多与JVM版本相关的特性, 比如本地序列化机制 (包括IP地址、异常信息等等), 而JVM在不同的minor版本中可能会修改序列化机制, 版本不同可能会导致序列化异常.
(3) 问题解决:
更换JDK版本, 并更新环境变量配置, 保证各节点使用的JDK版本一致.
5.3 其他问题
更多问题可以参考博文: ES 02 - 部署Elasticsearch单机服务 + 常见问题的解决 中第5节内容5 常见问题及解决方法.
版权声明
出处: 博客园 马瘦风的博客(https://www.cnblogs.com/shoufeng)
感谢阅读, 如果文章有帮助或启发到你, 点个[好文要顶
ES 31 - 从0开始搭建Elasticsearch生产集群的更多相关文章
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- ES 30 - Elasticsearch生产集群的配置建议
目录 1 服务器的内存 2 服务器的CPU 3 服务器的磁盘 4 集群的网络 5 集群的节点个数 6 JVM的参数设置 7 集群的数据量 8 总结 在生产环境中, 要保证服务在各种极限情况下的稳定和高 ...
- 【原创】《从0开始学Elasticsearch》—集群健康和索引管理
内容目录 1.搭建Kibana2.集群健康3.索引操作 1.搭建Kibana 正如<Kibana 用户手册>中所介绍,Kibana 是一款开源的数据分析和可视化平台,因此我们可以借助 Ki ...
- 【记录】centOS 搭建logstash +docker搭建elasticsearch伪集群+kibana链接集群elasticsearch节点
[注意]本文主要用于自我记录,注释较少. 安装logstash 1.上传logstash-6.4.3.tar.gz到服务中 2.tar –zxvf logstash-6.4.3.tar.gz 3.cd ...
- ELK介绍及搭建 Elasticsearch 分布式集群
上:https://blog.51cto.com/zero01/2079879 下:https://blog.51cto.com/zero01/2082794
- Elasticsearch系列---生产集群部署(上)
概要 本篇开始介绍Elasticsearch生产集群的搭建及相关参数的配置. ES集群的硬件特性 我们从开始编程就接触过各种各样的组件,而每种功能的组件,对硬件要求的特性都不太相同,有的需要很强的CP ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- Kafka 0.9+Zookeeper3.4.6集群搭建、配置,新Client API的使用要点,高可用性测试,以及各种坑 (转载)
Kafka 0.9版本对java client的api做出了较大调整,本文主要总结了Kafka 0.9在集群搭建.高可用性.新API方面的相关过程和细节,以及本人在安装调试过程中踩出的各种坑. 关于K ...
- centos7搭建ELK Cluster集群日志分析平台(一):Elasticsearch
应用场景: ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平 ...
随机推荐
- Python的工具包[2] -> matplotlib图像绘制 -> matplotlib 库及使用总结
matplotlib图像绘制 / matplotlib image description 目录 关于matplotlib matplotlib库 补充内容 Figure和AxesSubplot的生 ...
- Python的支持工具[1] -> 可执行文件生成工具[0] -> pyinstaller
pyinstaller pyinstaller安装方式: pip install pyinstaller 使用方法: cmd –> cd dictionary –> pyinstaller ...
- 洛谷—— P3908 异或之和
https://www.luogu.org/problemnew/show/P3908 题目描述 求1 \bigoplus 2 \bigoplus\cdots\bigoplus N1⨁2⨁⋯⨁N 的值 ...
- 前端常用面试题目及答案-HTML&CSS篇
1. 行内元素和块级元素有哪些? 行内元素: 123456789101112131415161718192021222324252627 <a> //标签可定义锚 <ab ...
- [CTSC2016]时空旅行(线段树+凸包)
应该是比较套路的,但是要A掉仍然不容易. 下面理一下思路,思路清楚了也就不难写出来了. 0.显然y,z坐标是搞笑的,忽略即可. 1.如果x不变,那么直接set即可解决. 2.考虑一个空间和询问x0,通 ...
- COCOS2d 标准 android.MK
LOCAL_PATH := $(call my-dir) include$(CLEAR_VARS) LOCAL_MODULE := game_shared PP_CPPFLAGS := -frtti ...
- Vue 基础的开发环境
本期节目将手把手教你去 NPM 市场买最新鲜的食材,只为搭配 小鲜肉 Vue 下厨. 既然它是当红小鲜肉,我想有必要写一篇文章来帮助大家配置好 Vue 的生产环境,我给它的总体评价是“简单却不失优雅, ...
- IdHTTPServer(indy10)开发REST中间件
IdHTTPServer(indy10)开发REST中间件 浏览器通过“get”方式查询数据URL样例:http://127.0.0.1:7777/query?sql=select * from t1 ...
- appium Parameters were incorrect
raise exception_class(value) selenium.common.exceptions.WebDriverException: Message: Parameters were ...
- 级联关系(内容大部分来自JavaEE轻量型解决方案其余的是我的想法)
1. 级联关系 在Hibernate程序中持久化的对象之间会通过关联关系互相引用.对象进行保存.更新和删除等操作时,有时需要被关联的对象也执行相应的操作,如:假设需要关联关系的主动方对象执行操作时,被 ...