Python读写操作Excel模块_xlrd_xlwt_xlutils
Python 读写操作Excel —— 安装第三方库(xlrd、xlwt、xlutils、openpyxl)
如果仅仅是要以表单形式保存数据,可以借助 CSV 格式(一种以逗号分隔的表格数据格式)进行处理,Excel 也支持此格式。但标准的 Excel 文件(xls/xlsx)具有较复杂的格式,并不方便像普通文本文件一样直接进行读写,需要借助第三方库来实现。
常用的库是 python-excel 系列:
xlrd、xlwt、xlutils、openpyxl
• xlrd - 读取 Excel 文件
• xlwt - 写入 Excel 文件
• xlutils - 操作 Excel 文件的实用工具,如复制、分割、筛选等
• openpyxl - 操作xlsx后缀的excel,实践发现 xlrd、xlwt、xlutils 可以读写操作xlsx文件,但是实际保存后打不开,修改后缀为xls后方可正常打开,而程序是完成了正常的读写操作,只是人为不能正常打开文件,所以这里要增加一个新的模块。
本文仅对xlrd、xlwt、xlutils进行介绍。
安装excel处理模块
(以下属性或方法并非全部,需要更多属性请参看文档;建议先参考文末Demo,再深入了解)
xlrd
WorkBook(class) 由xlrd.open_work("example.xls")返回:获取工作薄
常用方法:
nsheets:返回sheets数量
sheet_names:返回sheet名称列表
sheets:返回sheet列表
sheet_by_index(sheetx):按工作薄索引索引号提取sheet
sheet_by_name(sheet_name):按工作薄名称名称提取sheet
Sheet(class) 由WorkBook相关方法返回:对获取的工作薄进行操作
常用方法:
name:返回sheet名
nrows:返回行数
ncols:返回列数
cell(rowx,colx):返回第rows行colx列的单元格
cell_type(rowx,colx):返回单元格数据类型
cell_value(rows,colx):返回单元格数值,如获取合并单元格的内容,rows为行开始索引,colx为列索引
col(colx):获取第colx列所有单元格组成的列表
col_slice(colx,start_rowx=0,end_rowx=None):返回第colx列指定单元格组成的列表
col_types(colx,start_rowx=0,end_rowx=None):返回第colx列指定单元格数值类型组成的列表
col_values(colx,start_rowx=0,end_rowx=None):返回第colx列指定单元格数值组成的列表
row同样有col的各项操作,此处略去
Cell(class) 由Sheet object(s)相关方法返回:对单元格进行操作
ctype:一个int型变量,对应不同的数值类型,0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
value:单元格的值
xlwt
Workbook(class) 由xlwt.Workbook()返回:创建的临时工作表
常用方法:
encoding:编码方案
add_sheet(sheet_name):添加sheet,工作薄名称为sheet_name
get_sheet(Sheet_name):按名称选择对应sheet
save(file_name):保存,这个操作是必须的,否则表格不能被保存
Worksheet(class) 由Workbook object相关方法返回:对工作薄中单元格等操作
常用方法:
write(rows,colx,cell_value,style):编辑单元格,style表示单元格样式
write_merge(x, x + h, y, w + y, string, sytle):x表示行,y表示列,w表示跨列个数,h表示跨行个数,string表示要写入的单元格内容。
insert_bitmap(img, x, y, x1, y1, scale_x=0.8, scale_y=1):img表示要插入的图像地址,x表示行,y表示列,x1表示相对原来位置向下偏移的像素,y1表示相对原来位置向右偏移的像素,scale_x表示相对原图宽的比例,scale_y表示相对原图高的比例
row(rowx).write(colx,cell_value,style):编辑行
flush_row_data():减少内存压力,flush之前行不可再修改
col(colx),write(rows,cell_value,style):编辑列
easyxf(function):创建XFStyle instance,格式控制(xlwt.XFStyle())
(加粗为默认格式,以下所列并非全部)
element attribute value
font - bold - True or False
- colour - {colour}
- italic - True or False
- name - name of the font, Arial
- underline - True or False
alignment - direction - general, lr, rl
- horizontal - general, left, center, right, filled
- vertical - bottom, top, center, justified, distributed
- shrink_to_fit - True or False
bolders - left - an integer width between 0 and 13
- right - an integer width between 0 and 13
- top - an integer width between 0 and 13
- bottom - an integer width between 0 and 13
- diag - an integer width between 0 and 13
- left_colour - {colour}*, automatic colour
- right_colour - {colour}*, automatic colour
- ...
pattern - back_color - {colour}*, automatic colour
- fore_colour - {colour}*, automatic colour
- pattern - none, solid, fine_dots, sparse_dots
{colous}*: black, (dark_)(light_)blue, gold, (dark_)(light_)green, ivory, lavender,
(light_)orange, pink, (dark_)red, rose, violet, white, (dark_)(light_)yellow, ...
xlutils
常用方法:
copy:将xlrd.Book转为xlwt.Workbook
styles:读取xlrd.Workbook的每一个单元格的style
display:简单而安全地呈现xlrd读取的数据
filter:拆分与整合多个xls文件
margins:查看表格稀疏程度
save:列化xlrd.Book,转存为xls
实例:
一:xlrd读表数据模块
读取excel中数据有两种方法,假设有如下表格
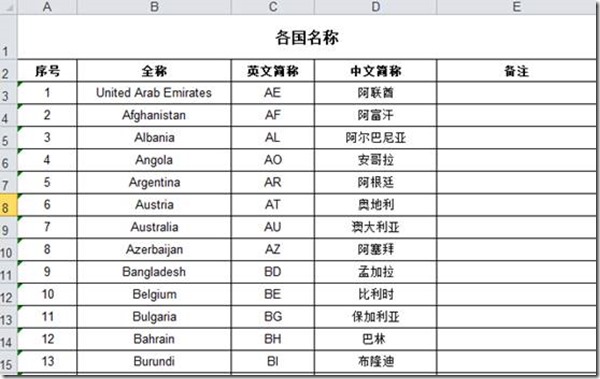
要求:读取excel数据,取第2行以下的数据,然后取每行前13列的数据
方法一:
import xlrd
workbook = xlrd.open_workbook('city.xls')
sheet = workbook.sheets()[0] #因为只有一个工作薄,我这里就直接用所以为0的工作薄了
nrows = sheet.nrows #获取工作薄的行数
for i in range(nrows):
if i<2: #取第2行以下的数据
continue
print(sheet.row_values(i)[1:]) #打印行数据
方法二:
import xlrd
workbook = xlrd.open_workbook('city.xls')
sheet_names = workbook.sheet_names() ##抓取所有sheet页的名称
#print(sheet_names)
# workbook_sheet = workbook.sheet_by_name('sheet1') #通过工作薄名称获取工作薄
# workbook_sheet = workbook.sheet_by_index(0) #通过索引获取工作薄
workbook_sheet = workbook.sheets()[0] #通过索引获取工作薄
num_rows = workbook_sheet.nrows #获取工作薄的行数
for i in range(num_rows):
if i<2: #取第2行以下的数据
continue
print(workbook_sheet.row_values(i)[1:]) #打印行数据
num_cols = workbook_sheet.ncols #获取工作薄的列数
for j in range(num_cols): #遍历列数并打印列据
print(workbook_sheet.col_values(j))
#获取单元格数据
for rown in range(num_rows):
for coln in range(num_cols):
cell = workbook_sheet.cell_value(rown,coln)
print(cell)
'''#获取单元格数据的其他写法:(实际中多行注释不显示)
for rown in range(num_rows):
for coln in range(num_cols):
cell = workbook_sheet.cell(rown,coln).value #方法1
print(cell)
cell = workbook_sheet.row(rown)[coln].value #方法2
print(cell)
cell = workbook_sheet.col(coln)[rown].value #方法3
print(cell)
#获取单元格中值的类型,类型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
cell_type = workbook_sheet.cell_type(rown,coln)
print(cell_type)'''
二、xlwt写表数据模块
要求:新建excel文件并写入数据
import xlwt #创建workbook和sheet对象
workbook = xlwt.Workbook() #注意Workbook的开头W要大写
sheet1 = workbook.add_sheet('sheet1')
sheet2 = workbook.add_sheet('sheet2') #向sheet工作薄中写入数据
sheet1.write(0,0,'1') #单元格写数据
sheet1.write(0,1,'中国')
sheet1.write(0,2,'China')
#批量写数据
list1 = [[2,'澳大利亚','Australia'],[3,'比利时','Belgium'],[4,'保加利亚','Bulgaria']]
i = 1
for j in list1:
for x in range(len(j)):
sheet1.write(i,x,j[x])
i += 1 #设计样式,并应用样式
style = xlwt.XFStyle() #初始化样式
font = xlwt.Font()#为样式创建字体
font.name = 'Times New Roman'
font.bold = True
font.underline =True
style.font = font #设置样式的字体
sheet1.write(6,0,'some bold Times text',style)#使用样式 first_col = sheet1.col(0) #列的样式也可进行设置
first_col.width = 256*20 workbook.save('xlwt_t.xls') #保存该excel文件,有同名文件时直接覆盖
三、xlutils模块修改表格
向已有excel文件中写入数据
import xlrd
import xlutils.copy rb = xlrd.open_workbook('xlwt_t.xls',formatting_info=True)#打开一个workbook,formatting_info为保留原样式
wb = xlutils.copy.copy(rb)
ws = wb.get_sheet(0) #获取sheet对象,通过sheet_by_index()获取的sheet对象没有write()方法
ws.write(8,0,'changed1!')
ws.write_merge(7,8,0,3,'changed2!') #写入数据,并合并单元格
wb.add_sheet('sheet6')#添加sheet页
wb.save('xlwt_t.xls')#利用保存时同名覆盖达到修改excel文件的目的,注意未被修改的内容保持不变
Python读写操作Excel模块_xlrd_xlwt_xlutils的更多相关文章
- Python 读写操作Excel —— 安装第三方库(xlrd、xlwt、xlutils、openpyxl)
数据处理是 Python 的一大应用场景,而 Excel 则是最流行的数据处理软件.因此用 Python 进行数据相关的工作时,难免要和 Excel 打交道. 如果仅仅是要以表单形式保存数据,可以借助 ...
- 转 Python - openpyxl 读写操作Excel
Python - openpyxl 读写操作Excel openpyxl特点 openpyxl(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间 ...
- Python“文件操作”Excel篇(上)
大家好,我们今天来一起探索一下用Python怎么操作Excel文件.与word文件的操作库python-docx类似,Python也有专门的库为Excel文件的操作提供支持,这些库包括xlrd.xlw ...
- Python Pandas操作Excel
Python Pandas操作Excel 前情提要 ☟ 本章使用的 Python3.6 Pandas==0.25.3 项目中需要用到excel的文件字段太多 考虑到后续字段命名的变动以及中文/英文/日 ...
- Python - openpyxl 读写操作Excel
openpyxl特点 openpyxl(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易 注意:如果文字编码是“gb2312” 读取后就会显 ...
- Python【操作EXCEL文件】
#Python中,对EXCEL文件的读写操作需要安装.导入几个第三方模块#xlrd模块:只能读取EXCEL文件,不能进行写操作#xlwt模块:只能进行写操作,但是不能是覆盖写操作(也就是修改Excel ...
- python 3 操作 excel
看到一篇很好的python读写excel方式的对比文章: 用Python读写Excel文件 关于其他版本的excel,可以通过他提供的链接教程进行学习. XlsxWriter: https://git ...
- Python之操作Excel、异常处理、网络编程
知识补充: 1.falsk模块中一些方法总结 import flask from flask import request,jsonify server = flask.Flask(__name__) ...
- xlwt:python的写excel模块
最近工作时碰到了将数据导出,生成一个excel表,对其中的部分数据进行统计,并给其中部分符合条件的数据添加对应的背景颜色的功能需求,于是乎,对Python中写excel的模块xlwt研究了一下,在工作 ...
随机推荐
- 线段树教做人系列(2)HDU 4867 XOR
题意:给你一个数组a,长度为.有两种操作.一种是改变数组的某个元素的值,一种是满足某种条件的数组b有多少种.条件是:b[i] <= a[i],并且b[1]^b[2]...^b[n] = k的数组 ...
- 安装nodemon热启动
1.安装: cnpm i nodemon -g 2.执行 nodemon .\launch.js .\config_preview\ .\launch.js 为我要启动的脚本文件 .\config_p ...
- C++ 面向对象: I/O对象的应用
1. 补充完整从text.txt文件读取数据后,再写入in.txt文件.2. 完成从text.txt文件读取数据后,进行排序,再写入in.txt文件.数据量自行设定.3. 请解决在主程序文件中加载多个 ...
- 面试题:struts 拦截器和过滤器
拦截器和过滤器的区别 过滤器是servlet规范中的一部分,任何java web工程都可以使用. 拦截器是struts2框架自己的,只有使用了struts2框架的工程才能用. 过滤器在url-patt ...
- Windows系统 安装 Qt 5.7.0
Windows系统 安装 Qt 5.7.0 我们的电脑系统:Windows 10 64位 Qt5 软件:Qt 5. 7. 0 下载 Qt 5.7.0 软件 在这个网站里面,下载:Qt 5.7.0 fo ...
- DesertWind TopCoder - 1570
传送门 分析 首先我们要知道为了情况最坏,无论你到哪,一定会在你前往绿洲的最短路上的那片沙子上刮风,所以这个点到绿洲的最短路即为他相连的点中到绿洲距离最短的距离+3和次短的距离+1的最小值,具体实现见 ...
- php 函数追踪扩展 phptrace
php 函数追踪扩展 phptrace 介绍 phptrace 是一个低开销的用于跟踪.分析 php 运行情况的工具. 它可以跟踪 php 在运行时的函数调用.请求信息.执行流程.并且提供有过滤器.统 ...
- delphi xe6 调用java GPS的方法
如果用xe6自带的LocationSensor控件,默认优先使用网络位置,网络位置定位精度不准确,不能满足高精度定位的要求.但xe6自带的LocationSensor控件不能指定网络定位优先还是GPS ...
- sqlserver清楚文本中的换行符
REPLACE(@string,CHAR(13)+CHAR(10),char(32))
- go语言的信号及其应用
一.signal包 1.Notify函数 func Notify(c chan<- os.Signal, sig ...os.Signal) 说明:Notify函数让signal包将输入信号转发 ...