《Effective Java》第4章 类和接口
第13条:使类和成员的可访问性最小化
第一规则很简单:尽可能地使每个类或者成员不被外界访问。换句话说。应该使用与你正在编写的软件的对应功能相一致的、尽可能最小的访问级别。
对于顶层的(非嵌套的)类和接口,只有两种可能的访问级别:包级私有的(package-private)和公有的(public)。如果你用public修饰符声明了顶层类或者接口,那它就是公有。否则,它将是包级私有的。如果类或者接口能够被做成包级私有的,它就应该被做成包级私有的。通过把类或者接口做成包级私有,它实际上成了这个包的实现的一部分,而不是该包导出的API的一部分,在以后的发行版本中,可以对它进行修改、替换,或者删除,而无需担心会影响到现有的客户端程序。如果你把它做成公有的,你就有责任永远支持它,以保持它们的兼容性。
如果一个包级私有的顶层类(或者接口)只是在某一个类的内部被用到,就应该考虑使它成为唯一使用它的那个类的私有嵌套类(见第22条)。这样可以将它的可访问范围从包中的所有类缩小到了使用它的那个类。然而,降低不必要公有类的可访问性,比降低包级私有的顶层类的更重要得多: 因为公有类是包的API的一部分,而包级私有的顶层类则已经是这个包的实现的一部分。
对于成员(域、方法、嵌套类和嵌套接口)有四种可能的访问级别,下面按照可访问性的递增顺序罗列出来:
- 私有的(private)——只有在声明该成员的顶层类内部才可以访问这个成员。
- 包级私有的(package-private)——声明该成员的包内部的任何类都可以访问这个成员。从技术上讲,它被称为“缺省(default)访问级别”,如果没有为成员指定访问修饰符,就采用这个访问级别。
- 受保护的(protected)——声明该成员的类的子类可以访问这个成员(但有一些限制[JLS, 6.5.2]),并且,声明该成员的包内部的任何类也可以访问这个成员。
- 公有的(public)——在任何地方都可以访问该成员。
包含会有可变域的类并不是线程安全的。
如果final域包含可变对象的引用,它便具有非final域的所有缺点。虽然引用本身不能被修改,但是它所引用的对象却可以被修改——这会导致灾难性的后果。
注意,长度非零的数组总是可变的,所以,类具有公有的静态final数组域,或者返回这种城的访问方法,这几乎总是错误的。
要注意,许多IDE会产生返回指向私有数组域的引用的访问方法,这样就会产生这个问题。修正这个问题有两种方法。可以使公有数组变成私有的,井增加一个公有的不可变列表:

另一种方法是,可以使数组变成私有的,井添加一个公有方法,它返回私有数组的一个备份:
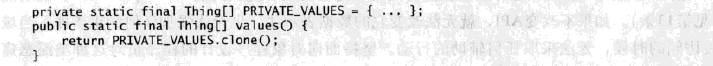
除了公有静态final域的特殊情形之外,公有类都不应该包含公有域。并且要确保公有静态final域所引用的对象都是不可变的。
第16条: 复合优先于继承
与方法调用不同的是,继承打破了封装性。超类的实现有可能会随着发行版本的不同而有所变化,如果真的发生了变化,子类可能会遭到破坏,即使它的代码完全没有改变。
导致子类脆弱的一个相关的原因是,它们的超类在后续的发行版本中可以获得新的方法。
如果超类在后续的发行版本中获得了一个新的方法,井且不幸的是,你给子类提供了一个签名相同但返回类型不同的方法,那么这样的子类将无法通过编译。
幸运的是,有一种办法可以避免前面提到的所有问题。不用扩展现有的类,而是在新的类中增加一个私有域,它引现有类的一个实例。这种设计被称做“复合(composition) " ,因为现有的类变成了新类的一个组件。新类中的每个实例方法都可以调用被包含的现有类实例中对应的方法,并返回它的结果。这被称为转发(forwarding),新类中的方法被称为转发方法(forwarding method )。这样得到的类将会非常稳固,它不依赖于现有类的实现细节。
只有当子类真正是超类的子类型(subtype)时,才适合用继承。换句话说,对于两个类A和B,只有当两者之间确实存在“is-a”关系的时候,类B才应该扩展类A。如果答案是否定的,通常情况下,B应该包含A的一个私有实例,并且暴露一个较小的、较简单的API: A本质上不是B的一部分,只是它的实现细节而已。
如果在适合于使用复合的地方使用了继承,则会不必要地暴露实现细节。
第17条: 要么为继承而设计,并提供文档说明,要么就禁止继承
为了继承而进行的设计不仅仅涉及自用模式的文档设计。为了使程序员能够编写出更加有效的子类,而无需承受不必要的痛苦,类必须通过某种形式提供适当的钩子(hook),以便能够进入到它的内部工作流程中,这种形式可以是精心选择的受保护的(protected)方法,也可以是受保护的域,后者比较少见。
对于为了继承而设计的类,唯一的刚试方法就是编写于类。
为了允许继承,类还必须遵守其他一些约束。构造器决不能调用可被覆盖的方法,无论是直接调用还是间接调用。如果违反了这条规则,很有可能导致程序失败。超类的构造器在子类的构造器之前运行,所以,子类中覆盖版本的方法将会在子类的构造器运行之前就先被调用。
这个问题的最佳解决方案是,对于那些并非为了安全地进行子类化而设计和编写文档的类,要禁止子类化。有两种办法可以禁止子类化。比较容易的办法是把这个类声明为final的。另一种办法是把所有的构造器都变成私有的,或者包级私有的,并增加一些公有的静态工厂来替代构造器。
第18条: 接口优于抽象类
- 现有的类可以很容易被更新,以实现新的接口。
- 接口是定义mixin〔混合类型)的理想选择。
- 接口允许我们构造非层次结构的类型框架。
虽然接口不允许包含方法的实现,但是,使用接口来定义类型并不妨碍你为程序员提供实现上的帮助。通过对你导出的每个重要接口都提供一个抽象的骨架实现(skeletal implementation )类,把接口和抽象类的优点结合起来。接口的作用仍然是定义类型,但是骨架实现类接管了所有与接口实现相关的工作。
实现了这个接门的类可以把对于接口方法的调用,转发到个内部私有类的实例上,这个内部私有类扩展了骨架实现类。这种方法被称作模拟多重继承(simulated multiple inheritance)。关于多重继承可以参考“参考资料【1】”。
第19条:接口只用于定义类型
常童接口模式是对接口的不良使用。
如果要导出常量,可以有几种合理的选择方案。如果这些常量与某个现有的类或者接口紧密相关,就应该把这些常量添加到这个类或者接口中。如果这些常量最好被看作枚举类型的成员,就应该用枚举类型(enum type)(见第30条)来导出这些常量。否则,应该使用不可实例化的工具类(utility class)(见第4条)来导出这些常量。
第20条:类层次优于标签类
标签类:考虑下面这个类,它能够表示圆形或者矩形:
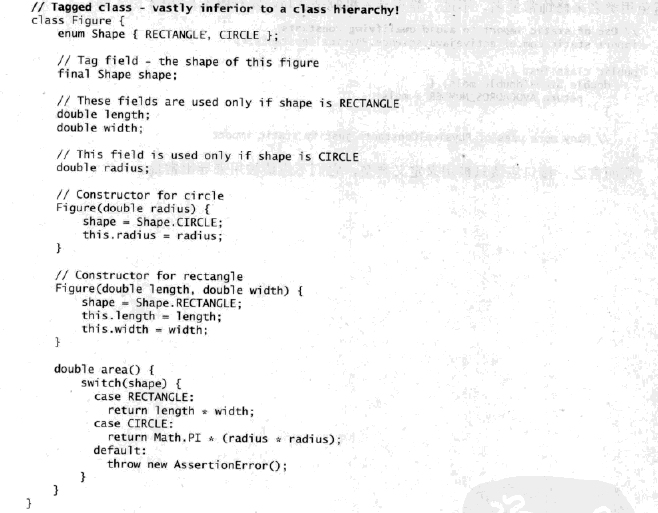
这种标签类(tagged class)有着许多缺点。它们中充斥着样板代码,包括枚举声明、标签域以及条件语句。由于多个实现乱七八槽地挤在了单个类中,破坏了可读性。内存占用也增加了,因为实例承担着属于其他风格的不相关的域。
标签类过于冗长、容易出错,并且效率低下。标签类正是类层次的一种简单的仿效。
为了将标签类转变成类层次,首先要为标签类中的每个方法都定义一个包含抽象方法的抽象类,这每个方法的行为都依赖于标签值。接下来,为每种原始标鉴类都定义根类的具体子类。

第21条: 用函数对象表示策略
Java没有提供函数指针,但是可以用对象引用实现同样的功能。调用对象上的方法通常是执行该对象(that object)上的某项操作。然而,我们也可能定义这样一种对象,它的方法执行其他对象(other objects)(这些对象被显式传递给这些方法)上的操作。如果一个类仅仅导出这样的一个方法,它的实例实际上就等同于一个指向该方法的指针。这样的实例被称为函数对象(function object)。例如,考虑下面的类:

指向StringLengthCamparator对象的引用可以被当作是一个指向该比较器的“函数指针(function pointer)",可以在任意一对字符串上被调用。换句话说,StringLengthCamparator实例是用于字符串比较操作的具体策略(concrete strategy)。
作为典型的具体策略类,StringLengthCamparator类是无状态的(stateless):它没有域,所以。这个类的所有实例在功能上都是相互等价的。因此,它作为一个Singleton是非常合适的,可以节省不必要的对象创建开销(见第3条和第5条):


简而言之,函数指针的主要用途就是实现策略( Strategy )模式。为了在Java中实现这种模式,要声明一个接口来表示该策略,并且为每个具体策略声明一个实现了该接口的类。当一个具体策略只被使用一次时,通常使用匿名类来声明和实例化这个具体策略类。当一个具体策略是设计用来重复使用的时候。它的类通常就要被实现为私有的静态成员类,并通过公有的静态final域被导出,其类型为该策略接口。
第22条: 优先考虑静态成员类
非静态成员类的每个实例都隐含着与外围类的一个外围实例(enclosing instance)相关联。
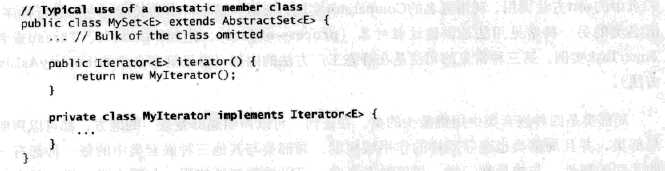
作静态成员类的一种常见用法是定义一个Adapter[Gamma95, p.139],它允许外部类的实例被看作是另一个不相关的类的实例。例如,Map接口的实现往往使用非静态成员类来实现它们的集合视图(collection view),这些集合视图是由Map的keySet, entrySet和Values方法返回的。同样地,诸如Set和List这种集合接口的实现往往也使用非静态成员类来实现它们的迭代器(iterator):
私有静态成员类的一种常见用法是用来代表外围类所代表的对象的组件。例如,考虑一个Map实例,它把键(key)和值(value)关联起来。许多Map实现的内部都有一个Entry对象,对应于Map中的每个键值对。虽然每个entry都与一个Map关联,但是entry上的方法(getKey,getValue和setValue)并不需要访问该Map。因此,使用非静态成员来表示entry是很浪费的:私有的静态成员类是最佳的选择。如果不小心漏掉了entry声明中的static修饰符,该Map仍然可以工作,但是每个entry中将会包含一个指向该Map的引用,这样就浪费了空间和时间。
由于匿名类出现在表达式当中,它们必须保持简短—大约10行或者更少些——否则会影响程序的可读性。
匿名类的一种常见用法是动态地创建函数时象(funCtivn object,见第21t条)
匿名类的另一种常见用法是创建过程对象(process object),比如Runnable, Thread或者TimerTask实例。
第三种常见的用法是在静态工厂方法的内部。
参考资料
【1】java提高篇(九)—–实现多重继承 http://www.cnblogs.com/chenssy/p/3389027.html
《Effective Java》第4章 类和接口的更多相关文章
- [Effective Java]第四章 类和接口
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- Effective Java 读书笔记之三 类和接口
一.使类和成员的可访问性最小化 1.尽可能地使每个类或者成员不被外界访问. 2.实例域决不能是共有的.包含公有可变域的类不是线程安全的. 3.除了公有静态final域的特殊情形之外,公有类都不应该包含 ...
- 《Effective Java 2nd》第4章 类和接口
目录 第13条: 使类和成员的可访问性最小化 第14条:在公有类中使用访问方法而非公有域 第15条:使可变性最小化 第16条:复合优先于继承 第17条:要么为继承而设计,并提供文档说明,要么就禁止继承 ...
- EFFECTIVE JAVA 第十一章 系列化
EFFECTIVE JAVA 第十一章 系列化(将一个对象编码成一个字节流) 74.谨慎地实现Serializable接口 *实现Serializable接口付出的代价就是大大降低了“改变这个类 ...
- IEnumerator<TItem>和IEnumerator Java 抽象类和普通类、接口的区别——看完你就顿悟了
IEnumerable 其原型至少可以说有15年历史,或者更长,它是通过 IEnumerator 来定义的,而后者中使用装箱的 object 方式来定义,也就是弱类型的.弱类型不但会有性能问题,最主要 ...
- [Java读书笔记] Effective Java(Third Edition) 第 4 章 类和接口
第 15 条: 使类和成员的可访问性最小化 软件设计基本原则:信息隐藏和封装. 信息隐藏可以有效解耦,使组件可以独立地开发.测试.优化.使用和修改. 经验法则:尽可能地使每个类或者成员不被外界访问 ...
- [Effective Java]第七章 方法
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- [Effective Java]第五章 泛型
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- Effective Java 第三版——38. 使用接口模拟可扩展的枚举
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
随机推荐
- UVA - 10723 Alibaba (dp)
给你两个长度不超过30的字符串序列,让你找到一个最短的字符串,使得给定的两个字符串均是它的子序列(不一定连续),求出最短长度以及符合条件的解的个数. 定义状态(a,b,c)为当前字符串长度为a,其中包 ...
- [SPOJ10707]Count on a tree II
luogu 题意 给定一个n个节点的树,每个节点表示一个整数,问u到v的路径上有多少个不同的整数. sol 也就是路径数颜色.树上莫队板子题. 我这种分块的姿势貌似是假的. 所以跑的是最慢的QAQ. ...
- CH5702 Count The Repetitions[倍增dp]
http://contest-hunter.org:83/contest/0x50%E3%80%8C%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92%E3%80%8D%E4%B ...
- 基于 WebSocket 的 MQTT 移动推送方案
WebSphere MQ Telemetry Transport 简介 WebSphere MQ Telemetry Transport (MQTT) 是一项异步消息传输协议,是 IBM 在分析了他们 ...
- 基于人脸识别+IMDB-WIFI+Caffe的性别识别
本文用记录基于Caffe的人脸性别识别过程.基于imdb-wiki模型做finetune,imdb-wiki数据集合模型可从这里下载:https://data.vision.ee.ethz.ch/cv ...
- 分布式爬虫搭建系列 之一------python安装及以及虚拟环境的配置及scrapy依赖库的安装
python及scrapy框架依赖库的安装步骤: 第一步,python的安装 在Windows上安装Python 首先,根据你的Windows版本(64位还是32位)从Python的官方网站下载Pyt ...
- 如何配置nagios监控SUN(富士通)MX000系列服务器的XSCF
配置环境说明 192.168.3.80-XSCF地址 192.168.2.80-solaris操作系统IP地址 (nagios客户端) 192.168.2.120-nagios服务器端 check_x ...
- 常用Oracle分析函数详解
学习步骤:1. 拥有Oracle EBS demo 环境 或者 PROD 环境2. copy以下代码进 PL/SQL3. 配合解释分析结果4. 如果网页有点乱请复制到TXT中查看 /*假设一个经理代表 ...
- leetcode328
/** * Definition for singly-linked list. * public class ListNode { * public int val; * public ListNo ...
- Delphi Android 询问框
Delphi Android 询问框 http://community.embarcadero.com/blogs/entry/xe7-dialog-box-methods-support-anony ...