spark streaming的应用
今天我们讲spark streaming的应用,这个是实时处理的,类似于Storm以及Flink相关的知识点,
说来也巧,今天的自己也去听了关于Flink的相关的讲座,可惜自己没有听得特别清楚,好像是
spark streaming与flink是竞争关系,好了,我们进入今天的主题吧
1.一般会做用户画像的差不多集中在两个行业,电商以及广告行业
一般根据现实给这个人打上一个标签,在根据标签来确定画像
2.如果一个人不登录,怎样确定这个人的详情
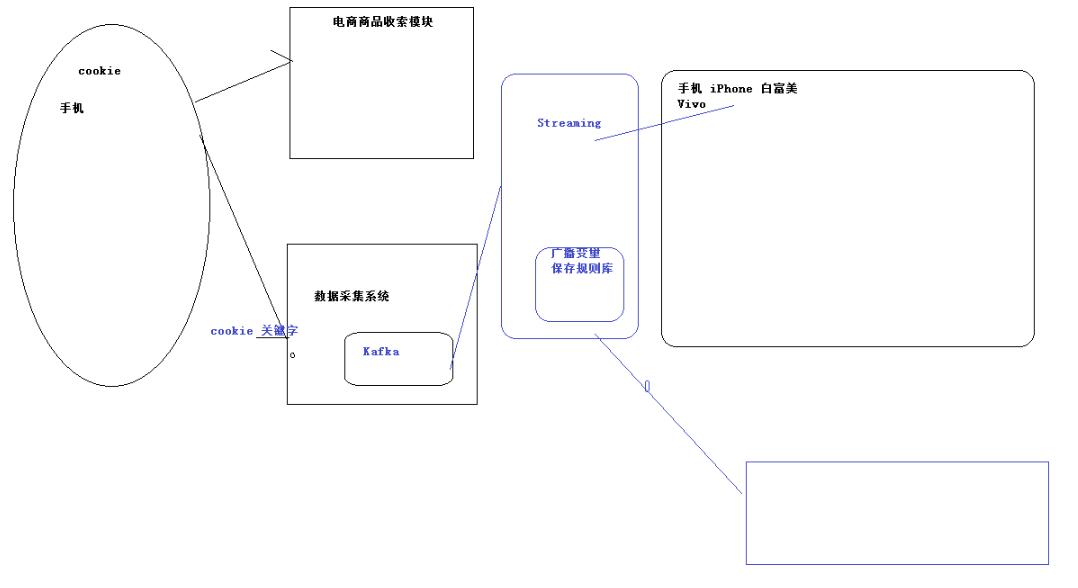
这个就是spark streaming的应用
nc -lk 8888 这个端口可以一直发送数据
请记住,spark中产生的rdd,可能会由于某种意外的原因,从而这个计算可能就要重新开始计算,
但是假如我们设置了checkpoint(如果多个进程同时开始的话,我们可以搞一个共享存储)的时候,
就可以保存这个值,当再一次出现意外的时候,就可以从恢复的这个值重新读取
对于map来说,可以map(),同时也可以map{},这样的两种表达形式,不过当我们写成了case()的
这种形式,则我们必须使用map的大括号的这种形式了,后文附带代码
package cn.wj.spark.day09
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* Created by WJ on 2017/1/18.
*/
object StateFulWordCount {
//Seq这个批次某个单词的次数
//Option[Int]:以前的结果
//(hello,1),(hello,1),(tom,1)
//(hello,Seq(1,1)),(tom,Seq(1))
//此时x=>String(Key的值),y=>Seq[Int](当前的这个value的值),z=>Option[Int],这个代表的是以前的value的值
val updateFunc = (iter:Iterator[(String,Seq[Int],Option[Int])]) =>{
iter.flatMap{case(x,y,z) => Some(y.sum+z.getOrElse()).map(m =>(x,m))}
}
def main(args: Array[String]): Unit = {
LoggerLevels.setStreamingLogLevels()
//StreamingContext
val conf = new SparkConf().setAppName("StreamingContext").setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setCheckpointDir("/tmp/ck")
// sc.setCheckpointDir("hdfs://192.168.109.136:9000/person/myfile")
val ssc = new StreamingContext(sc,Seconds())
val ds = ssc.socketTextStream("192.168.109.136",)
//updateStateByKey:这个方法的意思是说将每一次的partition都进行一次累计
val result = ds.flatMap(_.split(" ")).map((_,)).updateStateByKey(updateFunc,new HashPartitioner(sc.defaultParallelism),true)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
其中,LoggerLevels.setStreamingLogLevels()这个是设置日志文件的显示情况的,是让打出来的日志更清晰,
如果没必要,可以删除的。
首先我们在linux里面向8888端口发送信息:
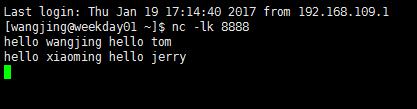
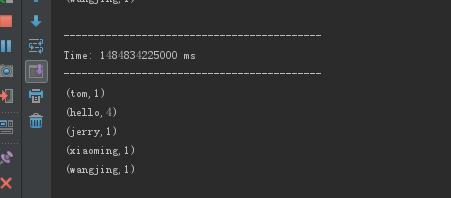
然后启动项目,这个时候就可以看见这个效果了(可以叠加的spark streaming)
spark streaming的应用的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- spark streaming kafka example
// scalastyle:off println package org.apache.spark.examples.streaming import kafka.serializer.String ...
- Spark Streaming中动态Batch Size实现初探
本期内容 : BatchDuration与 Process Time 动态Batch Size Spark Streaming中有很多算子,是否每一个算子都是预期中的类似线性规律的时间消耗呢? 例如: ...
- Spark Streaming源码解读之No Receivers彻底思考
本期内容 : Direct Acess Kafka Spark Streaming接收数据现在支持的两种方式: 01. Receiver的方式来接收数据,及输入数据的控制 02. No Receive ...
- Spark Streaming架构设计和运行机制总结
本期内容 : Spark Streaming中的架构设计和运行机制 Spark Streaming深度思考 Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行 ...
- Spark Streaming中空RDD处理及流处理程序优雅的停止
本期内容 : Spark Streaming中的空RDD处理 Spark Streaming程序的停止 由于Spark Streaming的每个BatchDuration都会不断的产生RDD,空RDD ...
- Spark Streaming源码解读之State管理之UpdataStateByKey和MapWithState解密
本期内容 : UpdateStateByKey解密 MapWithState解密 Spark Streaming是实现State状态管理因素: 01. Spark Streaming是按照整个Bach ...
随机推荐
- ajax提交 返回值为undefined
easyui form 表单提交成功,但是返回值为undefined,原因是返回值不是json格式,是字符串的格式,那么解决办法就是把其转化成json格式 示例: $(function () { / ...
- 微信公众平台开发——helloworld
威信公众平台有两种模式:编辑模式 和 开发模式. 普通的功能可以通过编辑模式来搞定.开发模式具有更多的功能.让我们来使用开发模式开发helloword吧 步骤如下: 1.先注册一个公众号(https: ...
- Azure进阶攻略 | 你的程序也能察言观色?这个真的可以有!
前段时间有个网站曾经火爆微博和朋友圈:颜龄机器人.只要随便上传一张包含人面孔的照片,这个网站就可以分析图片,并判断照片中人物的年龄.化妆.美颜 P 图.帽子墨镜之类的配饰,几乎都没法影响这个网站的检测 ...
- mysql:用cmd启动mysql服务被拒绝原因
原因是命令行的权限不够,需要以管理员模式运行,然后输入net start mysql 即可启动mysql服务
- 国外统计学课程主页Statistical Books, Manuals and Journals
国外统计学课程主页Statistical Books, Manuals and Journalshttp://statpages.info/javasta3.html
- 【转】如何手动添加Android Dependencies包
在ADT16 之前可以在工程里面做关联,eclipse会在工程上自动添加ReferenceLibrary.新版本的ADT修改了第三方jar的导入方式,只需要在工程目录下新建libs文件夹,注意是lib ...
- P1089 津津的储蓄计划
题目描述 津津的零花钱一直都是自己管理.每个月的月初妈妈给津津300300元钱,津津会预算这个月的花销,并且总能做到实际花销和预算的相同. 为了让津津学习如何储蓄,妈妈提出,津津可以随时把整百的钱存在 ...
- aop 和castle 的一些 学习文章
https://www.cnblogs.com/zhaogaojian/p/8360363.html
- iterm2配置项
1. 启动终端Terminal2. 进入当前用户的home目录 输入cd ~3. 创建.bash_profile 输入touch .bash_profile 在导入并应用完颜色方案之后,通 ...
- Ubuntu 12.04 the system is running in low-graphics mode
1.出现问题如图所示: 2.解决方案: Ctrl + Alt + F1 df -h 输入密码,到了这一步,也是可以使用terminal,那么没有图形界面也是可以的 cd /etc/X11 sudo c ...