Hadoop WordCount单词计数原理
计算文件中出现每个单词的频数
输入结果按照字母顺序进行排序

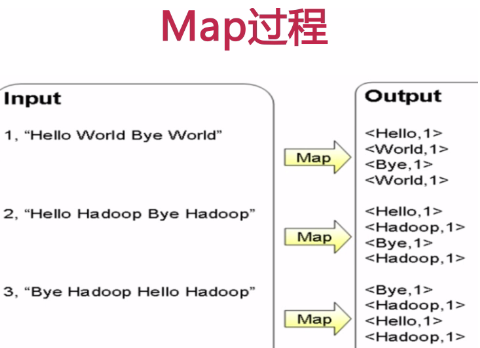
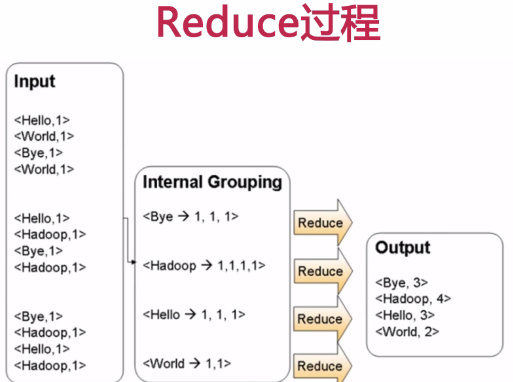
- 编写WordCount.java 包含Mapper类和Reducer类
- 编译WordCount.java javac -classpath
- 打包jar -cvf WordCount.jar classes/*
- 提交作业
- hadoop jar WordCount.jar WordCount input output
Hadoop WordCount单词计数原理的更多相关文章
- hadoop笔记之MapReduce的应用案例(WordCount单词计数)
MapReduce的应用案例(WordCount单词计数) MapReduce的应用案例(WordCount单词计数) 1. WordCount单词计数 作用: 计算文件中出现每个单词的频数 输入结果 ...
- 第一个Hadoop程序-单词计数
上一篇配置了Hadoop,本文将测试一个Hadoop的小案例 hadoop的Wordcount程序是hadoop自带的一个小的案例,是一个简单的单词统计程序,可以在hadoop的解压包里找到,如下: ...
- Spark本地环境实现wordCount单词计数
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6814778610788860424/ 编写类似MapReduce的案例-单词统计WordCount 要统计的文件为 ...
- Hadoop分布环境搭建步骤,及自带MapReduce单词计数程序实现
Hadoop分布环境搭建步骤: 1.软硬件环境 CentOS 7.2 64 位 JDK- 1.8 Hadoo p- 2.7.4 2.安装SSH sudo yum install openssh-cli ...
- Hadoop: 单词计数(Word Count)的MapReduce实现
1.Map与Reduce过程 1.1 Map过程 首先,Hadoop会把输入数据划分成等长的输入分片(input split) 或分片发送到MapReduce.Hadoop为每个分片创建一个map任务 ...
- 大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言: 根据前面的几篇博客学习,现在可以进行MapReduce学习了.本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分 ...
- Spark: 单词计数(Word Count)的MapReduce实现(Java/Python)
1 导引 我们在博客<Hadoop: 单词计数(Word Count)的MapReduce实现 >中学习了如何用Hadoop-MapReduce实现单词计数,现在我们来看如何用Spark来 ...
- MapReduce之单词计数
最近在看google那篇经典的MapReduce论文,中文版可以参考孟岩推荐的 mapreduce 中文版 中文翻译 论文中提到,MapReduce的编程模型就是: 计算利用一个输入key/value ...
- 单词计数-MapReduceJob
pom文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3. ...
随机推荐
- Echarts一个页面加载多个图表及图表自适应
Echarts一个页面加载多个图表及图表自适应 模块化加载 //入口 require.config({ paths: { echarts: 'http://echarts.baidu.com/buil ...
- c版基于链表的插入排序(改进版)
1. [代码][C/C++]代码 /** * @todo c版基于链表的插入排序 * @author Koma **/#include<stdio.h>#include<st ...
- Codeforces 509F Progress Monitoring:区间dp【根据遍历顺序求树的方案数】
题目链接:http://codeforces.com/problemset/problem/509/F 题意: 告诉你遍历一棵树的方法,以及遍历节点的顺序a[i],长度为n. 问你这棵树有多少种可能的 ...
- Linux学习过程中的简单命令
1.su su- 与 sudo (1) 普通用户和root转换:su 用户名或root 不知道root密码的情况下:普通 -> root:sudo su roo ...
- PL/SQL学习笔记_02_游标
在 PL/SQL 程序中,对于处理多行记录的事务经常使用游标来实现. 为了处理 SQL 语句, ORACLE 必须分配一片叫上下文( context area )的区域来处理所必需的信息,其中包括要处 ...
- leetcode 231 Power of Two(位运算)
Given an integer, write a function to determine if it is a power of two. 题解:一次一次除2来做的话,效率低.所以使用位运算的方 ...
- bzoj1059ZJOI2017矩阵游戏
小Q是一个非常聪明的孩子,除了国际象棋,他还很喜欢玩一个电脑益智游戏——矩阵游戏.矩阵游戏在一个N *N黑白方阵进行(如同国际象棋一般,只是颜色是随意的).每次可以对该矩阵进行两种操作:行交换操作:选 ...
- 【Google】非下降数组
转自九章算法公众号 题目描述 给出包含n个整数的数组,你的任务是检查它是否可以通过修改至多一个元素变成非下降的.一个非下降的数组array对于所有的i(1<=i<n)满足array[i-1 ...
- 系列文章--AJAX技术系列总结
各种AJAX方法的使用比较 用ASP.NET写个SQLSERVER的小工具 写自己的ASP.NET MVC框架(下) 写自己的ASP.NET MVC框架(上) 用Asp.net写自己的服务框架 ...
- Java中Calendar常用方法总结
//获取当前时刻yyyy-MM-dd HH:mm:ss Calendar calendar = Calendar.getInstance(); SimpleDateFormat sdf = new S ...