redis系列:主从复制
1 简介
这篇文章主要讲述Redis的主从复制功能。会依次从环境搭建、功能测试和原理分析几个方面进行介绍。
2 准备工作
服务器架构图如下
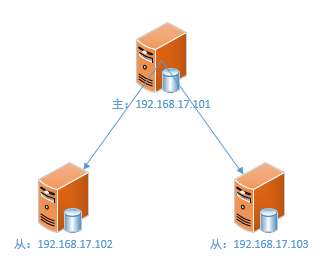
启动主服务器101,使用info replication命令查看状态,可以看到role为master(也就是角色为主主服务器),connected_salaves的值为0(从服务器数量为0)

接下来用修改配置文件的方式将102机器加入的主从复制当中
然后再用命令的方式同样将103机器加入的主从复制当中。
2.1 用修改配置文件的方式将102机器加入到主从
ip地址为192.168.17.102的机器的Redis配置文件增加slaveof 192.168.17.101 6379
启动102的redis,状态如下
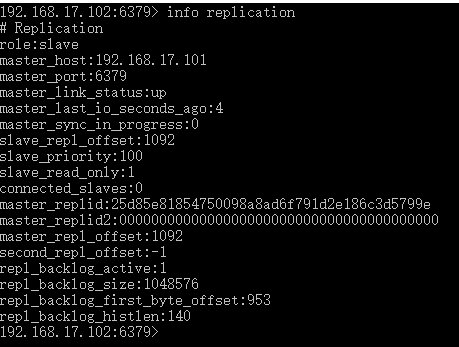
可以看到role变为slave(角色为从服务器),master_host(主服务器IP地址)为192.168.17.101,master_port(主服务器端口)为6379。
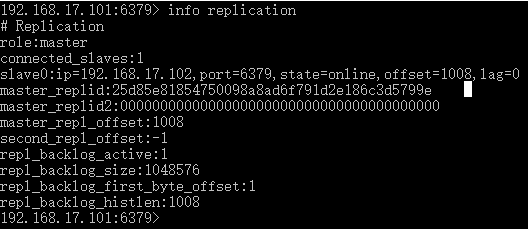
此时101主服务器的主从状态如下,可以看到connected_salaves的值变为1,以及增加了一行slave0(从服务器的状态)
2.2 用命令的方式将103机器加入到主从
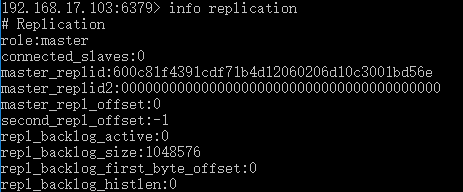
未执行slaveof命令的主从状态如下
开始执行slaveof命令
192.168.17.103:6379> slaveof 192.168.17.101 6379
OK
再次查看状态,可以看到角色已经变成从服务器
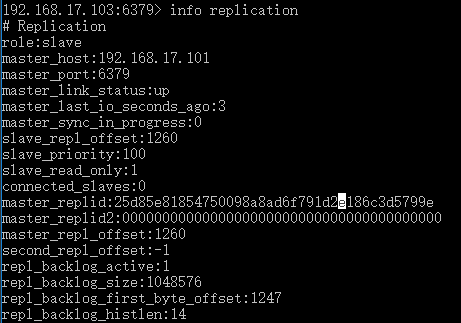
现在再来看看主服务器的状态,可以看到从服务器数量变成2,又多了一条从服务器的信息
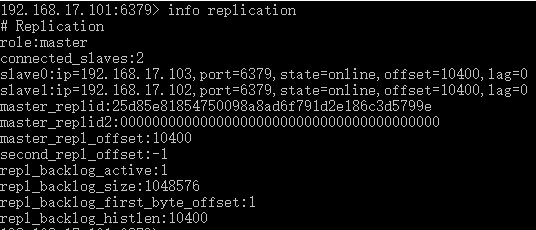
到这里主从环境就搭好了,现在来测试一波
2.3 测试
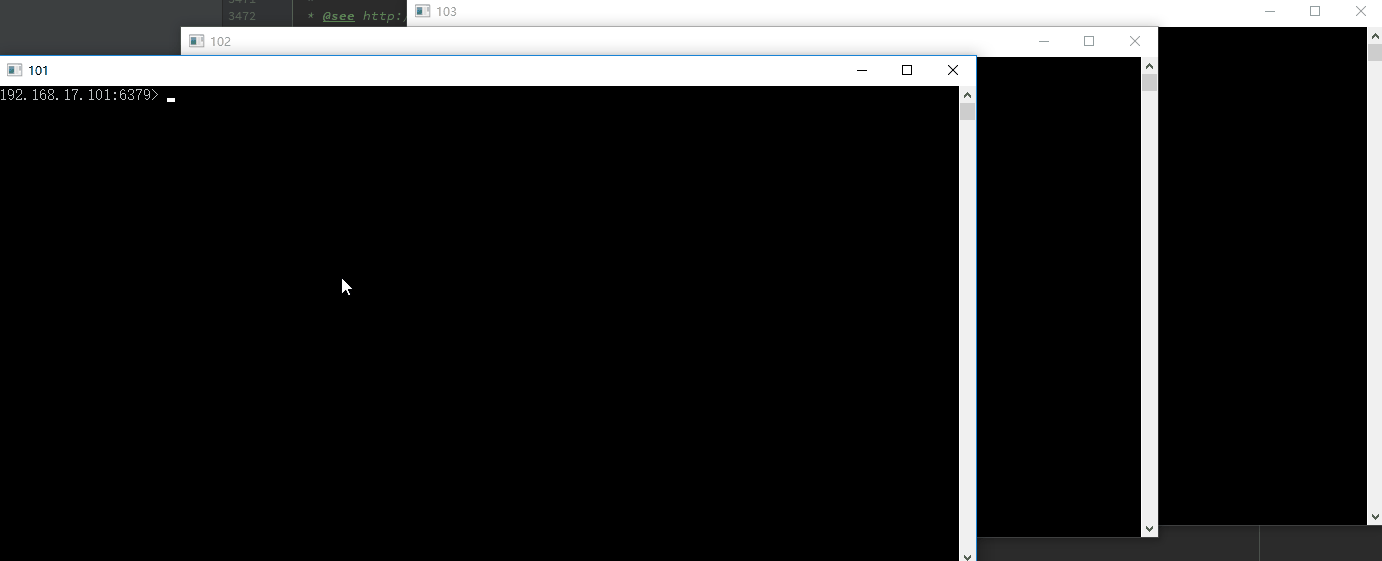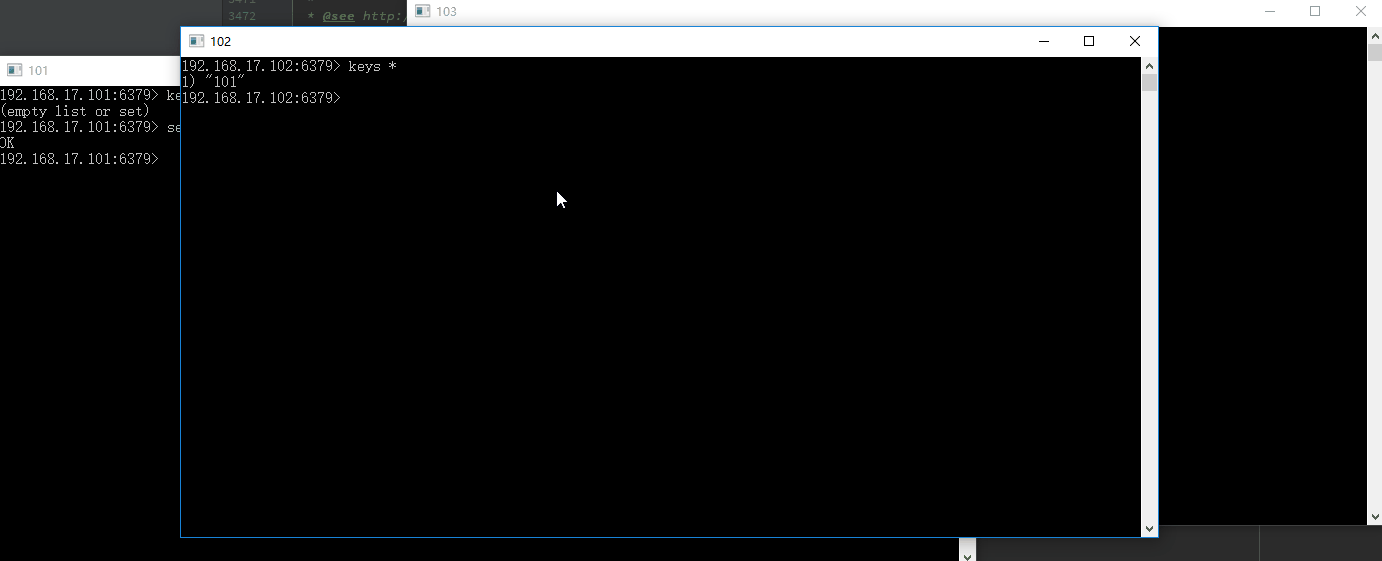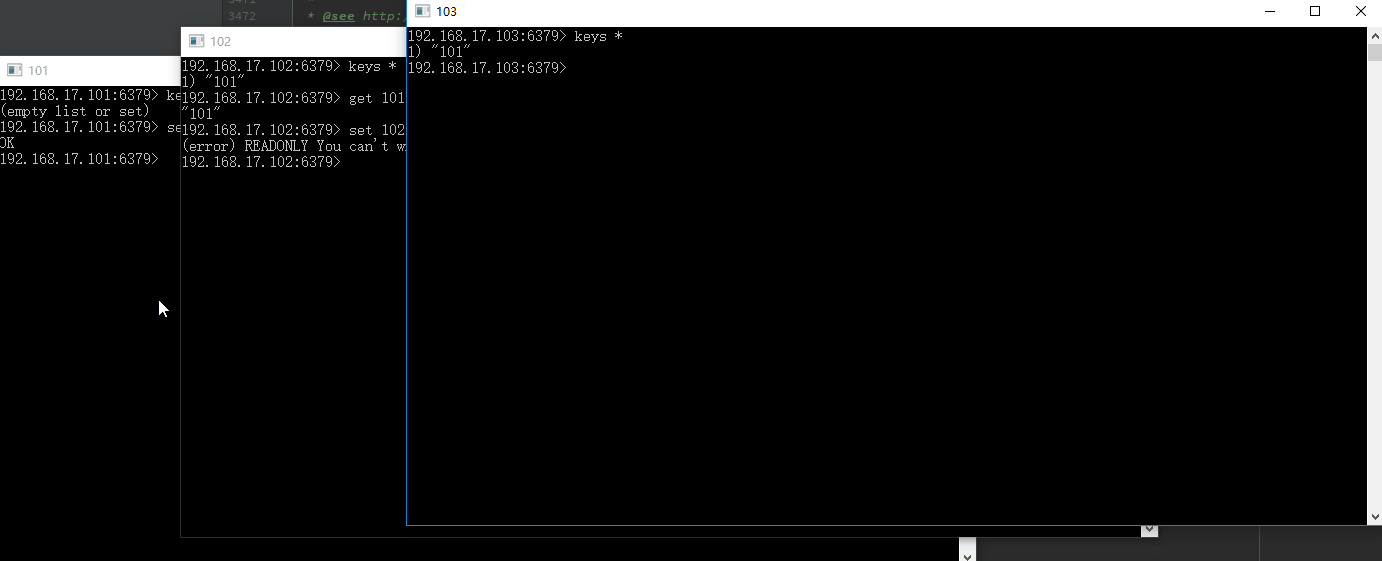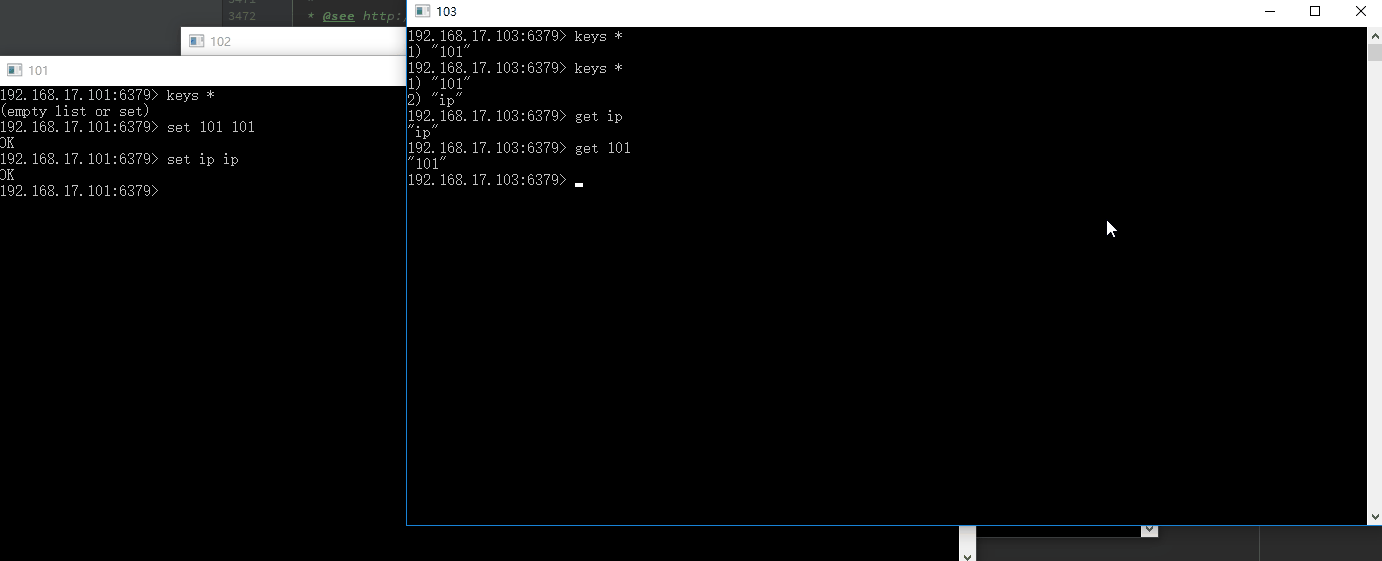
现在主服务器101输入命令
192.168.17.101:6379> set 101 101
OK
然后在从服务器102上查看所有的键,发现有键101,接着设置键102
192.168.17.102:6379> keys *
1) "101"
192.168.17.102:6379> get 101
"101"
192.168.17.102:6379> set 102 102
(error) READONLY You can't write against a read only slave.
发现出现错误(error) READONLY You can't write against a read only slave. 后面在讲述出错原因
现在在从服务器103上查看所有的键,发现也有101
192.168.17.103:6379> keys *
1) "101"
再向主服务器101输入命令
192.168.17.101:6379> set ip ip
OK
然后到从服务器103上查看所有的键
192.168.17.103:6379> keys *
1) "101"
2) "ip"
可以看到多了一个键,说明主服务的数据同步到了从服务器上,操作过程看下图
2.4 其他
2.4.1 (error) READONLY You can't write against a read only slave.
出现错误(error) READONLY You can't write against a read only slave. 是因为
从节点默认是只读的,如需修改可以再配置文件中修改下面这个属性
slave-read-only yes
2.4.2 主服务器设置密码
当主服务设置密码时,配置文件需要增加如需参数
masterauth <master-password>
3 实现原理
当我在从服务器103上输入slaveof命令时,出现如下日志

总的来说主从复制功能的详细步骤可以分为7个步骤:
- 设置主服务器的地址和端口
- 建立套接字连接
- 发送PING命令
- 身份验证
- 发送端口信息
- 同步
- 命令传播
接下来分别叙述每个步骤
3.1设置主服务器的地址和端口
主从复制的第一步就是设置主服务器的地址和端口,当输入slaveof命令或者在配置文件中配置信息时,从服务器会将主服务器的ip地址和端口号保存到服务器状态的属性里面。
3.2 建立套接字连接
在slaveof命令执行之后,从服务器会根据设置的ip和端口,向主服务器简历socket连接。
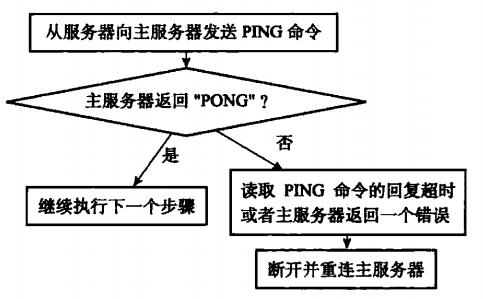
3.3 发送PING命令
socket连接成功后,从服务器会发送一PING命令给主服务器。
这时候PING命令可以检查socket的读写状态是否正常,还可以检查主服务器能否正常处理命令请求。
从服务器在发送PING命令时可能遇上的情况如下图
3.4 身份验证
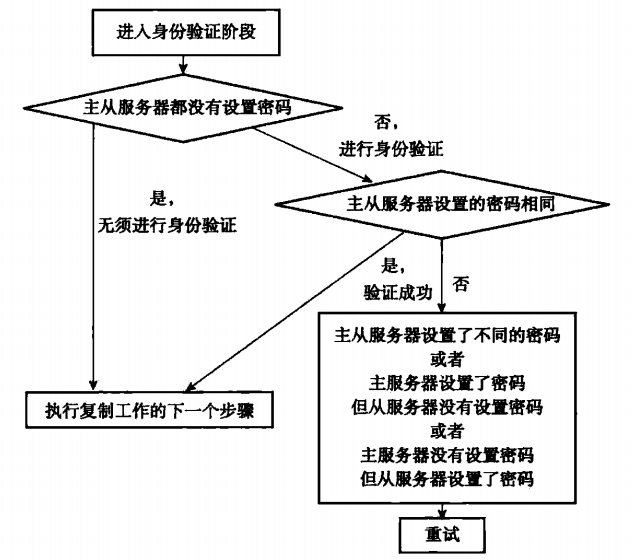
从服务器收到主服务器的PONG回复后,会检查从服务器是否设置masterauth,设置则进行身份验证,未设置则跳过该步骤。从服务器在身份验证时可能遇上的情况如下
3.5 发送端口信息
身份验证通过后,从服务器会向主服务器发送自己的监听端口号。主服务器收到之后会将端口号记录到从服务器对应的状态属性中。在主服务器调用info replication可以看到从服务器的port,如下
3.6 同步
发送端口信息之后,从服务器会向主服务器发送PSYNC命令,执行同步操作,并将自己的数据库同步至主服务器数据库当前的状态。
同步这块内容会在后面详细描述
3.7 命令传播
当完成同步操作之后,主从服务器便会进入命令传播阶段。这时候主从服务器的数据是一致的,当主服务器有新的写命令时,会将改命令发送给从服务器,从服务器接收命令并执行便可以保证与主服务器的数据保持一致。
那么Redis是如何保证主从服务器一致处于连接状态以及命令是否丢失?
答:命令传播阶段,从服务器会利用心跳检测机制定时的向主服务发送消息。
从服务器发送的命令如下
REPLCONF ACK <replication_offset>
replication_offset表示从服务器当前的复制偏移量
接下来看看心跳机制
3.7.1 心跳检测机制
心跳检测机制的作用有三个:
- 检查主从服务器的网络连接状态
- 辅助实现min-slaves选项
- 检测命令丢失
3.7.1.1 检查主从服务器的网络连接状态
主服务器信息中可以看到所属的从服务器的连接信息,state表示从服务器状态,offset表示复制偏移量,lag表示延迟值(几秒之前有过心跳检测机制)
3.7.1.2 辅助实现min-slaves选项
Redis.conf配置文件中有下方两个参数
# 未达到下面两个条件时,写操作就不会被执行
# 最少包含的从服务器
# min-slaves-to-write 3
# 延迟值
# min-slaves-max-lag 10
如果将两个参数的注释取消,那么如果从服务器的数量少于3个,或者三个从服务器的延迟(lag)大于等于10秒时,主服务器都会拒绝执行写命令。
3.7.1.3 检测命令丢失
在从服务器的连接信息中可以看到复制偏移量,如果此时主服务器的复制偏移量与从服务器的复制偏移量不一致时,主服务器会补发缺失的数据。
4 同步原理
同步分为全量重同步和部分重同步。那么是什么决定采取全量重同步还是部分重同步操作?
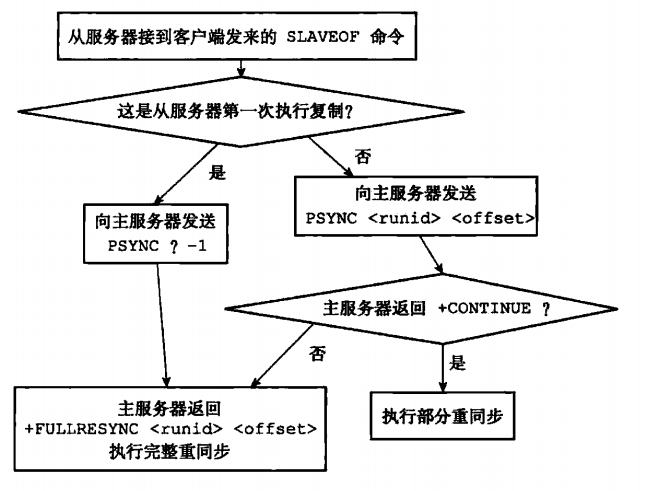
4.1 全量重同步
全量重同步的步骤如下
- 主节点收到从服务器的全量重同步请求时,主服务器便开始执行bgsave命令,同时用一个缓冲区记录从现在开始执行的所有写命令。
- 当主服务器的bgsave命令执行完毕后,会将生成的RDB文件发送给从服务器。从服务器接收到RDB文件时,会将数据文件保存到硬盘,然后加载到内存中。
- 主服务器将缓冲区所有缓存的命令发送到从服务器,从服务器接收并执行这些命令,将从服务器同步至主服务器相同的状态。
4.2 部分重同步
要想了解部分重同步的步骤,需要先了解部分重同步所需要的几个属性
- 复制偏移量
- 复制缓冲区
- 运行ID
4.2.1 复制偏移量
从主服务器的复制信息可以看到从服务器slave0和slave1都有一个参数offset,这个参数就是从服务器的复制偏移量。master_repl_offset这个参数就是主服务器的偏移量。如下图
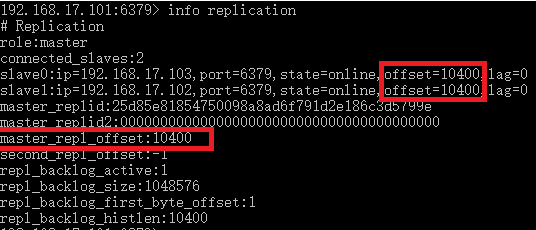
主服务器的复制偏移量保存向从服务器发送过的字节数据。
从服务器的复制偏移量保存着从主服务器接收的字节数据。
通过对比主服务器和从服务器的复制偏移量就可以知道命令是否丢失,丢失则补发复制偏移量相差的字节命令。
那么这些字节数据是存放在哪里的呢?
4.2.2 复制缓冲区
这些字节数据都是存放在主服务器的复制缓冲区里的。复制缓冲区是一个固定长度(fixed-size)先进先出(FIFO)的队列,默认大小为1MB。默认大小可以对下方的参数进行修改
# repl-backlog-size 1mb
那么复制缓冲区的数据是什么时候加入进去的呢?
答:在命令传播阶段,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区。
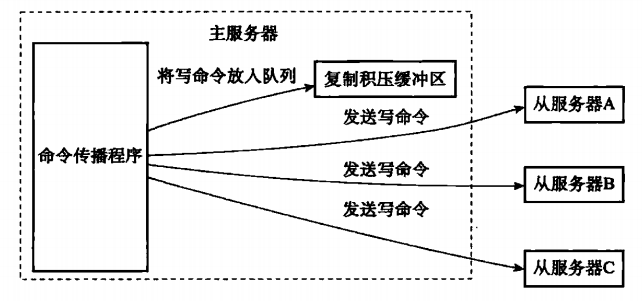
复制缓冲区里面会保存着一部分最传播的写命令和每个字节相应的复制偏移量。
由于复制缓冲区的大小是有限制的,所以保存的数据也是有限制的。如果从服务器与主服务器的复制偏移量相差的数据大于复制缓冲去存储的数据时,同样不会执行部分重同步。
举个例子,主服务器的复制偏移量为20000、缓冲区能保存的数据只有5000,从服务器的复制偏移量为10000。这时从服务器与主服务器复制偏移量10000,而缓冲区只有5000,那么还是会执行全量重同步。如果相差的复制偏移量小于5000,才会执行部分重同步。
4.2.3 运行ID
每个Redis服务器启动时,都会有自动生成自己的运行ID。
当从服务器对主服务器进行初次复制时,主服务器会发送自己的运行ID给从服务器。
当从服务器断线重连时,会将之前主服务器的运行ID发送给当前连接的主服务器。这时候会出现下面两种情况
- 运行ID和主服务器一致,主服务器可以尝试执行部分重同步操作。
- 运行ID和主服务器不一致,说明之前连接的主服务器与这次连接不同,开始执行全量重同步操作。
5 相关配置
################################# REPLICATION #################################
# slaveof <主服务器ip> <主服务器端口>
# slaveof <masterip> <masterport>
# masterauth <主服务器Redis密码>
# masterauth <master-password>
# 当slave丢失master或者同步正在进行时,如果发生对slave的服务请求
# yes则slave依然正常提供服务
# no则slave返回client错误:"SYNC with master in progress"
slave-serve-stale-data yes
# 指定slave是否只读
slave-read-only yes
# 无硬盘复制功能
repl-diskless-sync no
# 无硬盘复制功能间隔时间
repl-diskless-sync-delay 5
# 从服务器发送PING命令给主服务器的周期
# repl-ping-slave-period 10
# 超时时间
# repl-timeout 60
# 是否禁用socket的NO_DELAY选项
repl-disable-tcp-nodelay no
# 设置主从复制容量大小,这个backlog 是一个用来在 slaves 被断开连接时存放 slave 数据的 buffer
# repl-backlog-size 1mb
# master 不再连接 slave时backlog的存活时间。
# repl-backlog-ttl 3600
# slave的优先级
slave-priority 100
# 未达到下面两个条件时,写操作就不会被执行
# 最少包含的从服务器
# min-slaves-to-write 3
# 延迟值
# min-slaves-max-lag 10
结语
主从的配置文件:[https://github.com/rainbowda/learnWay/tree/master/learnRedis/replication,有需要可以下载。
Redis的主从复制功能就介绍到这里了。虽然说主从解决了读写分离,读数据的负载均衡,但是一旦某个节点出现故障,不能自动回复,主从切换等功能。所以就有了哨兵的功能。
redis系列:主从复制的更多相关文章
- redis系列--主从复制以及redis复制演进
一.前言 在之前的文章已经详细介绍了redis入门基础已经持久化相关内容包括redis4.0所提供的混合持久化. 通过持久化功能,Redis保证了即使在服务器宕机情况下数据的丢失非常少.但是如果这台服 ...
- redis系列-主从复制
redis自身提供了主从的机制,通过配置可以实现服务的备份(Master->Slave). 配置项 slaveof <masterip> <masterport> mas ...
- redis系列--深入哨兵集群
一.前言 在之前的系列文章中介绍了redis的入门.持久化以及复制功能,如果不了解请移步至redis系列进行阅读,当然我也是抱着学习的知识分享,如果有什么问题欢迎指正,也欢迎大家转载.而本次将介绍哨兵 ...
- Redis系列(四):Redis的复制机制(主从复制)
本篇博客是Redis系列的第4篇,主要讲解下Redis的主从复制机制. 本系列的前3篇可以点击以下链接查看: Redis系列(一):Redis简介及环境安装 Redis系列(二):Redis的5种数据 ...
- Redis系列八:redis主从复制和哨兵
一.Redis主从复制 主从复制:主节点负责写数据,从节点负责读数据,主节点定期把数据同步到从节点保证数据的一致性 1. 主从复制的相关操作 a,配置主从复制方式一.新增redis6380.conf, ...
- 四、redis系列之主从复制与哨兵机制
1. 绪言 在现实应用环境中,出于数据容量.容灾.性能等因素的考虑,往往不会只使用一台服务器,而是使用集群的方式.Redis 中也有类似的维持一主多从的方式提高 Redis 集群的高可用性的方案,而其 ...
- redis系列之------主从复制
什么是主从复制 Redis的主从复制机制是指可以让从服务器(slave)能精确复制主服务器(master)的数据,如下图所示: 或者 主从复制的方式和工作原理 工作方式: Redis主从复制主要 ...
- 实现Redis的主从复制配置
实现Redis的主从复制配置比较简单,而且容易明白. 下图是要配置的主从复制结构图: 1.说明 Redis主从复制中一个主服务可以有多个从服务,一个从服务可以有多个从服务. 配置比较简单,只需要更改r ...
- Redis系列(九)--几道面试题
这里只是一点面试题,想了解更多,可以查看本人的Redis系列:https://www.cnblogs.com/huigelaile/category/1461895.html 1.Redis和Memc ...
- Redis系列总结--这几点你会了吗?
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 前面几篇已经对Redis中几个关键知识点做了介绍,本篇主要对Redis系列做一下总结以及对Redis中常见面试 ...
随机推荐
- 剑指offer之 二叉搜索树的后续遍历序列
题目描述: 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果.如果是则输出Yes,否则输出No.假设输入的数组的任意两个数字都互不相同. public class Solution { ...
- 使用MapReduce将HDFS数据导入Mysql
使用MapReduce将Mysql数据导入HDFS代码链接 将HDFS数据导入Mysql,代码示例 package com.zhen.mysqlToHDFS; import java.io.DataI ...
- 分享知识-快乐自己:揭秘HBase
揭秘HBase: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce 六):揭秘HBa ...
- javascript通用参数判断
//判断value是小于等于max的数字function isNumberMax(value, max){ if(!isNumber(value) || !isNumber(max)){ ...
- node.js+express+jade系列二:rotue路由的配置
页面的访问最常见的是get和post两种,无论是get请求还是post请求express自动判断执行app.get或app.post 1:app.get(名称,路径)或app["get&qu ...
- 我理解的关于Vue.nextTick()的正确使用
什么是Vue.nextTick() 官方文档解释如下: 在下次 DOM 更新循环结束之后执行延迟回调.在修改数据之后立即使用这个方法,获取更新后的 DOM. 我理解的官方文档的这句话的侧重点在最后那半 ...
- JAVA堆内存和栈内存初步了解
一.堆内存和栈内存 程序运行时内存分配有三种:静态存储分配,栈式存储分配,堆式存储分配 1.静态存储分配: 在程序编译时就可以确定数据目标在运行时所需要的内存,因此在编译时就为其分配固定大小的内存. ...
- Debian for ARM
/************************************************************************* * Debian for ARM * 说明: * ...
- Agc017_E Jigsaw
传送门 题目大意 有$n$块拼图,每一块都由左中右三个部分组成,每块拼图中间部分是高为$H$的长方形,对于第$i$块品推左侧是高为$A_i$距离底部为$C_i$的长方体,右侧是高位$B_i$距底部为$ ...
- ACdream1430SETI(后缀自动机)
问题: Amateur astronomers Tom and Bob try to find radio broadcasts of extraterrestrial civilizations i ...