转:InnoDB多版本(MVCC)实现简要分析
InnoDB多版本(MVCC)实现简要分析
基本知识
假设对于多版本(MVCC)的基础知识,有所了解。InnoDB为了实现多版本的一致读,采用的是基于回滚段的协议。
行结构
InnoDB表数据的组织方式为主键聚簇索引。由于采用索引组织表结构,记录的ROWID是可变的(索引页分裂的时候,Structure Modification Operation,SMO),因此二级索引中采用的是(索引键值, 主键键值)的组合来唯一确定一条记录。
无论是聚簇索引,还是二级索引,其每条记录都包含了一个DELETED BIT位,用于标识该记录是否是删除记录。除此之外,聚簇索引记录还有两个系统列:DATA_TRX_ID,DATA_ROLL_PTR。DATA _TRX_ID表示产生当前记录项的事务ID;DATA _ROLL_PTR指向当前记录项的undo信息。
聚簇索引行结构(与多版本一致读有关的部分,DELETED BIT省略):

二级索引行结构:
从聚簇索引行结构,与二级索引行结构可以看出,聚簇索引中包含版本信息(事务号+回滚指针),二级索引不包含版本信息,二级索引项的可见性如何判断?下面将会给出。
Read View
InnoDB默认的隔离级别为Repeatable Read (RR),可重复读。InnoDB在开始一个RR读之前,会创建一个Read View。Read View用于判断一条记录的可见性。Read View定义在read0read.h文件中,其中最主要的与可见性相关的属性如下:
dulint low_limit_id; /* 事务号 >= low_limit_id的记录,对于当前Read View都是不可见的 */
dulint up_limit_id; /* 事务号 < up_limit_id ,对于当前Read View都是可见的 */
ulint n_trx_ids; /* Number of cells in the trx_ids array */
dulint* trx_ids; /* Additional trx ids which the read should
not see: typically, these are the active
transactions at the time when the read is
serialized, except the reading transaction
itself; the trx ids in this array are in a
descending order */
dulint creator_trx_id; /* trx id of creating transaction, or
(0, 0) used in purge */
简单来说,Read View记录读开始时,所有的活动事务,这些事务所做的修改对于Read View是不可见的。除此之外,所有其他的小于创建Read View的事务号的所有记录均可见。可见包括两层含义:
记录可见,且Deleted bit = 0;当前记录是可见的有效记录。
记录可见,且Deleted bit = 1;当前记录是可见的删除记录。此记录在本事务开始之前,已经删除。
测试方法:
–create table and index
create table test (id int primary key, comment char(50)) engine=InnoDB;
create index test_idx on test(comment);
–Insert
insert into test values(1, ‘aaa’);
insert into test values(2, ‘bbb’);
–update primary key
update test set id = 9 where id = 1;
–update non-primary key with different value
update test set comment = ‘ccc’ where id = 9;
–update non-primary key with same value
update test set comment = ‘bbb’ where id = 2 and comment = ‘bbb’;
–read隔离级别
repeatable read(RR)
测试结果
update primary key
代码调用流程:
ha_innobase::update_row -> row_update_for_mysql -> row_upd_step -> row_upd -> row_upd_clust_step -> row_upd_clust_rec_by_insert -> btr_cur_del_mark_set_clust_rec -> row_ins_index_entry
简单来说,就是将cluster index的旧记录标记位删除;插入一条新纪录。该语句执行完之后,数据结构如下:

版本仍旧存储在聚簇索引之中,其DATA_TRX_ID被设置为1811,Deleted bit设置为1,undo中记录了前镜像的事务id = 1809。新版本DATA_TRX_ID也为1811。通过此图,还可以发现,虽然新老版本是一条记录,但是在聚簇索引中是通过两条记录来标识的。同时,由于更新了主键,二级索引也需要做相应的更新(二级索引中包含主键项)。
update non-primary key(diff value)
更新comment字段,代码调用流程与上面有部分不同,可以自行跟踪,此处省略。更新操作执行完之后,索引结构变更如下:
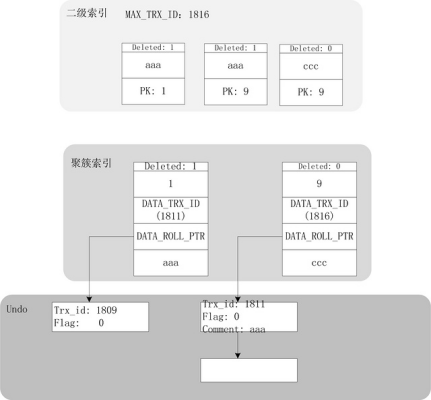
从上图可见,更新二级索引的键值时,聚簇索引本身并不会产生新的记录项,而是将旧版本信息记录在undo之中。与此同时,二级索引将会产生新的索引项,其PK值保持不变,指向聚簇索引的同一条记录。细心的读者可能会发现,二级索引页面中有一个MAX_TRX_ID,此值记录的是更新二级索引页面的最大事务ID。通过MAX_TRX_ID的过滤,INNODB能够实现大部分的辅助索引覆盖性扫描(仅仅扫描辅助索引,不需要回聚簇索引)。具体过滤方法,将在后面的内容中给出。
update non-primary key(same value)
最后一个测试用例,是更新comment项为同样的值。在我的测试中,更新之后的索引结构如下:
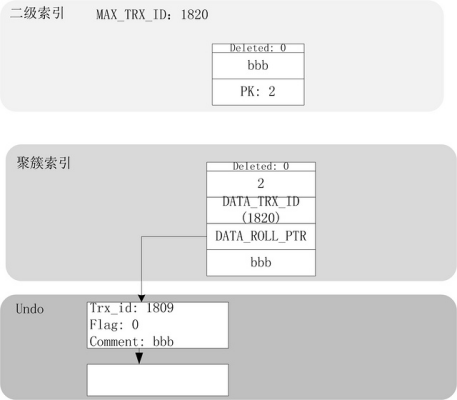
聚簇索引仍旧会更新,但是二级索引保持不变。
总结
无论是聚簇索引,还是二级索引,只要其键值更新,就会产生新版本。将老版本数据deleted bti设置为1;同时插入新版本。
对于聚簇索引,如果更新操作没有更新primary key,那么更新不会产生新版本,而是在原有版本上进行更新,老版本进入undo表空间,通过记录上的undo指针进行回滚。
对于二级索引,如果更新操作没有更新其键值,那么二级索引记录保持不变。
对于二级索引,更新操作无论更新primary key,或者是二级索引键值,都会导致二级索引产生新版本数据。
聚簇索引设置记录deleted bit时,会同时更新DATA_TRX_ID列。老版本DATA_TRX_ID进入undo表空间;二级索引设置deleted bit时,不写入undo。
可见性判断
主键查找
select * from test where id = 1;
针对测试1,如果1811(DATA_TRX_ID) < read_view.up_limit_id,证明被标记为删除的记录1可见。删除可见 -> 无记录返回。
针对测试1,如果1811(DATA_TRX_ID) >= read_view.low_limit_id,证明被标记为删除的记录1不可见,通过DATA_ROLL_PTR回滚记录,得到DATA_TRX_ID = 1809。如果1809可见,则返回记录(1,aaa);否则无记录返回。
针对测试1,如果up_limit_id,low_limit_id都无法判断可见性,那么遍历read_view中的trx_ids,依次对比事务id,如果在DATA_TRX_ID在trx_ids数组中,则不可见(更新未提交)。
select * from test where id = 9;
针对测试2,如果1816可见,返回(9,ccc)。
针对测试2,如果1816不可见,通过DATA_ROLL_PTR回滚到1811,如果1811可见,返回(9, aaa)。
针对测试2,如果1811不可见,无结果返回。
select * from test where id > 0;
针对测试1,索引中,满足条件的同一记录,有两个版本(版本1,delete bit =1)。那么是否会一条记录返回两次呢?必定不会,这是因为pk = 1的可见性与pk = 9的可见性是一致的,同时pk = 1是标记了deleted bit的版本。如果事务ID = 1811可见。那么pk = 1 delete可见,无记录返回,pk = 9返回记录;如果1811不可见,回滚到1809可见,那么pk = 1返回记录,pk = 9回滚后无记录。
总结:
通过主键查找记录,需要配合read_view,记录DATA_TRX_ID,记录DATA_ROLL_PTR指针共同判断。
read_view用于判断当前记录是否可见(判断DATA_TRX_ID)。DATA_ROLL_PTR用于将当前记录回滚到前一版本。
非主键查找
select comment from test where comment > ‘ ‘;
针对测试2,二级索引,当前页面的最大更新事务MAX_TRX_ID = 1816。如果MAX_TRX_ID < read_view.up_limit_id,当前页面所有数据均可见,本页面可以进行索引覆盖性扫描。丢弃所有deleted bit = 1的记录,返回deleted bit = 0 的记录;此时返回 (ccc)。(row_select_for_mysql ->lock_sec_rec_cons_read_sees)
针对测试2,二级索引,如果当前页面不能满足MAX_TRX_ID < read_view.up_limit_id,说明当前页面无法进行索引覆盖性扫描,此时需要针对每一项,到聚簇索引中判断可见性。回到测试2,二级索引中有两项pk = 9 (一项deleted bit = 1,另一个为0),对应的聚簇索引中只有一项pk= 9。如何保证通过二级索引过来的同一记录的多个版本,在聚簇索引中最多只能被返回一次?如果当前事务id 1811可见。二级索引pk = 9的记录(两项),通过聚簇索引的undo,都定位到了同一记录项。此时,InnoDB通过以下的一个表达式,来保证来自二级索引,指向同一聚簇索引记录的多个版本项,有且最多仅有一个版本将会返回数据:
if (clust_rec
&& (old_vers || rec_get_deleted_flag(
rec,dict_table_is_comp(sec_index->table)))
&& !row_sel_sec_rec_is_for_clust_rec(rec, sec_index, clust_rec, clust_index))
满足if判断的所有聚簇索引记录,都直接丢弃,以上判断的逻辑如下:
需要回聚簇索引扫描,并且获得记录
聚簇索引记录为回滚版本,或者二级索引中的记录为删除版本
聚簇索引项,与二级索引项,其键值并不相等
为什么满足if判断,就可以直接丢弃数据?用白话来说,就是我们通过二级索引记录,定位聚簇索引记录,定位之后,还需要再次检查聚簇索引记录是否仍旧是我在二级索引中看到的记录。如果不是,则直接丢弃;如果是,则返回。
根据此条件,结合查询与测试2中的索引结构。可见版本为事务1811.二级索引中的两项pk = 9都能通过聚簇索引回滚到1811版本。但是,二级索引记录(ccc,9)与聚簇索引回滚后的版本(aaa,9)不一致,直接丢弃。只有二级索引记录(aaa,9)保持一致,直接返回。
总结:
二级索引的多版本可见性判断,需要通过聚簇索引完成。
二级索引页面中保存了MAX_TRX_ID,可以快速判断当前页面中,是否所有项均可见,可以实现二级索引页面级别的索引覆盖扫描。一般而言,此判断是满足条件的,保证了索引覆盖扫描 (index only scan)的高效性。
二级索引中的项,需要与聚簇索引中的可见性进行比较,保证聚簇索引中的可见项,与二级索引中的项数据一致。
疑问
在http://blogs.InnoDB.com/wp/2011/04/mysql-5-6-multi-threaded-purge/中,作者提到,InnoDB的purge操作,是通过遍历undo来实现对于标记位deleted项的回收的。如果二级索引本身标记deleted位不记录undo,那么这个回收操作如何完成?还是说purge是通过解析redo来完成回收的?(根据下面对于purge的流程分析,此问题已解决)
Purge流程
Purge功能:
InnoDB由于要支持多版本协议,因此无论是更新,删除,都只是设置记录上的deleted bit标记位,而不是真正的删除记录。后续这些记录的真正删除,是通过Purge后台进程实现的。Purge进程定期扫描InnoDB的undo,按照先读老undo,再读新undo的顺序,读取每条undo record。对于每一条undo record,判断其对应的记录是否可以被purge(purge进程有自己的read view,等同于进程开始时最老的活动事务之前的view,保证purge的数据,一定是不可见数据,对任何人来说),如果可以purge,则构造完整记录(row_purge_parse_undo_rec)。然后按照先purge二级索引,最后purge聚簇索引的顺序,purge一个操作生成的旧版本完整记录。
一个完整的purge函数调用流程如下:
row_purge_step->row_purge->trx_purge_fetch_next_rec->row_purge_parse_undo_rec
->row_purge_del_mark->row_purge_remove_sec_if_poss
->row_purge_remove_clust_if_poss
总结:
purge是通过遍历undo实现的。
purge的粒度是一条记录上的一个操作。如果一条记录被update了3次,产生3个old版本,均可purge。那么purge读取undo,对于每一个操作,都会调用一次purge。一个purge删除一个操作产生的old版本(按照操作从老到新的顺序)。
purge按照先二级索引,最后聚簇索引的顺序进行。
purge二级索引,通过构造出的索引项进行查找定位。不能直接针对某个二级页面进行,因为不知道记录的存放page。
对于二级索引设置deleted bit为不需要记录undo,因为purge是根据聚簇索引undo实现。因此二级索引deleted bit被设置为1的项,没有记录undo,仍旧可以被purge。
purge是一个耗时的操作。二级索引的purge,需要search_path定位数据,相当于每个二级索引,都做了一次index unique scan。
一次delete操作,IO翻番。第一次IO是将记录的deleted bit设置为1;第二次的IO是将记录删除。
--此文章转载自登博的博客,由于链接已经找不到,这里给大家分享。
转:InnoDB多版本(MVCC)实现简要分析的更多相关文章
- InnoDB多版本(MVCC)实现简要分析(转载)
http://hedengcheng.com/?p=148 基本知识 假设对于多版本(MVCC)的基础知识,有所了解.InnoDB为了实现多版本的一致读,采用的是基于回滚段的协议. 行结构 InnoD ...
- InnoDB多版本(MVCC)实现简要分析
转载自:http://hedengcheng.com/?p=148 基本知识 假设对于多版本(MVCC)的基础知识,有所了解.InnoDB为了实现多版本的一致读,采用的是基于回滚段的协议. 行结构 I ...
- MySQL InnoDB下关于MVCC的一个问题的分析
这个是网友++C++在群里问的一个关于MySQL的问题,本篇文章实验测试环境为MySQL 5.6.20,事务隔离级别为REPEATABLE-READ ,在演示问题前,我们先准备测试环境.准备一个测 ...
- Google发布SSLv3漏洞简要分析报告
今天上午,Google发布了一份关于SSLv3漏洞的简要分析报告.根据Google的说法,该漏洞贯穿于所有的SSLv3版本中,利用该漏洞,黑客可以通过中间人攻击等类似的方式(只要劫持到的数据加密两端均 ...
- 14.3 InnoDB Multi-Versioning InnoDB 多版本
14.3 InnoDB Multi-Versioning InnoDB 多版本 InnoDB 是一个多版本的存储引擎,它保持信息关于改变的数据老版本的信息, 为了支持事务功能比如并发和回滚. 这些信息 ...
- 14.2.2 InnoDB Multi-Versioning InnoDB 多版本
14.2.2 InnoDB Multi-Versioning InnoDB 多版本: InnoDB 是一个多版本的存储引擎: 它保留信息关于改变数据的老版本,为了支持事务功能 比如并发和回滚. 这些信 ...
- InnoDB多版本
InnoDB是一个多版本的存储引擎:为了支持事务的一些特性诸如并发和回滚,它保持着被修改行的旧版本信息.这些信息被存储在一个被叫做“回滚段”的表空间中(跟Oracle中的回滚段类似).InnoDB在回 ...
- Mysql加锁过程详解(5)-innodb 多版本并发控制原理详解
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- (转)innodb 多版本并发控制原理详解
转自:https://blog.csdn.net/aoxida/article/details/50689619 多版本并发控制技术已经被广泛运用于各大数据库系统中,如Oracle,MS SQL Se ...
随机推荐
- ElasticSearch入门常用命令
基于开源项目MyAlice智能客服学习ElasticSearch https://github.com/hpgary/MyAlice/wiki/%E7%AC%AC01%E7%AB%A0%E5%AE%8 ...
- 解决Android7.1.1中无法打开/data目录的问题
声明:本技巧借鉴https://segmentfault.com/a/1190000008416511这个大神的文章 一.复制android Sdk安装目录的platform-tools路径: 二.w ...
- XML文件解析-DOM4J方式和SAX方式
最近遇到的工作内容都是和xml内容解析相关的. 1图片数据以base64编码的方式保存在xml的一个标签中,xml文件通过接口的方式发送给我,然后我去解析出图片数据,对图片进行进一步处理. 2.xml ...
- b树的实现(c++)
转自:http://blog.chinaunix.net/uid-20196318-id-3030529.html B树的定义 假设B树的度为t(t>=2),则B树满足如下要求:(参考算法导论) ...
- js的set和get
'use strict' class Student { constructor(_name,age){ this.name = _name; this.age = age; } set name(_ ...
- Redis简介 & 与Memcache的区别
redis 是一个基于内存的高性能key-value数据库. Reids的特点 Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操 ...
- 防止php重复提交表单更安全的方法
Token.php <?php /* * Created on 2013-3-25 * * To change the template for this generated file go t ...
- Java面试题上
1.面向对象的特征有哪些方面?答:面向对象的特征主要有以下几个方面:- 抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面.抽象只关注对象有哪些属性和行为,并不关注这些 ...
- 10-THREE.JS perspective透视摄像机和orthographic正交摄像机区别
<!DOCTYPE html> <html> <head> <title></title> <script src="htt ...
- OpenCV那个版本的比较好用、稳定,参考资料也较多的
2.4.8.上opencv官网就能下载到,对应不同版本的VS有编译好的文件. 2.4以后的变化不大.所以你可以百度opencv,有中文网站,上面有详细的说明.如果是在windows系统的话,可以使用v ...