大数据学习——关于hive中的各种join
准备数据
2,b
3,c
4,d
7,y
8,u 2,bb
3,cc
7,yy
9,pp
建表:
create table a(id int,name string)
row format delimited fields terminated by ','; create table b(id int,name string)
row format delimited fields terminated by ',';
导入数据:
load data local inpath '/root/hivedata/a.txt' into table a;
load data local inpath '/root/hivedata/b.txt' into table b;
inner join 只打印能匹配上的数据,没有匹配上的不输出
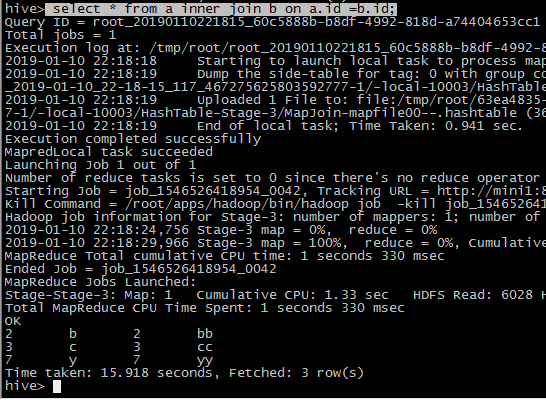
select * from a inner join b on a.id =b.id;
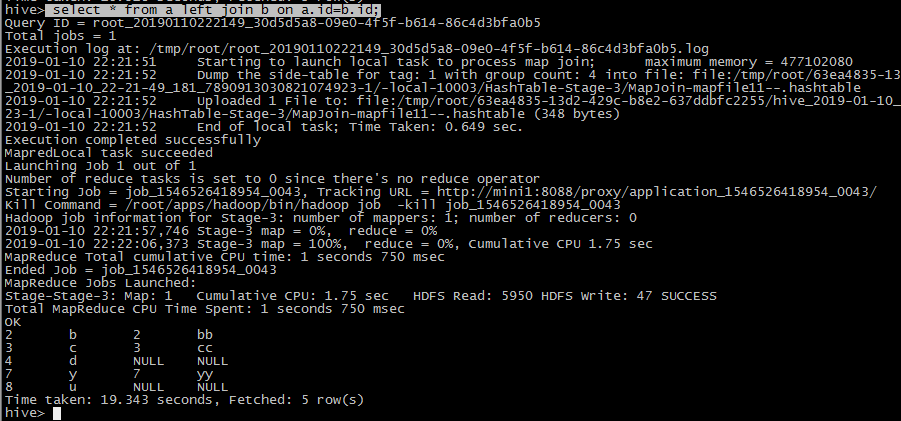
left join
select * from a left join b on a.id=b.id;
right join
select * from a right join b on a.id=b.id;

full outer join
select * from a full outer join b on a.id=b.id;

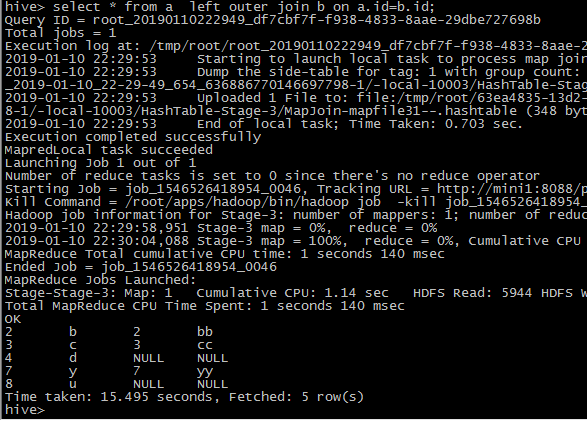
left outer join
left semi join
select * from a left semi join b on a.id=b.id;
相当于
select * from a where a.id exists(select b.id from b); 在hive中效率极低

大数据学习——关于hive中的各种join的更多相关文章
- 大数据学习之Scala中main函数的分析以及基本规则(2)
一.main函数的分析 首先来看我们在上一节最后看到的这个程序,我们先来简单的分析一下.有助于后面的学习 object HelloScala { def main(args: Array[String ...
- 大数据学习笔记——Hive完整部署流程
Hive详细部署教程 此篇博客承接上篇Hadoop和Zookeeper的部署教程,将会详细地对HIve的部署做一个整理,Hive相当于是封装在HDFS和Mapreduce上的一套sql引擎,只需要安装 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
随机推荐
- 总结 - 常见的JavaScript兼容性问题
添加事件的方法 (元素, 绑定的事件类型, 事件触发的方法) addHandler: function (element, type, handler) { if (element.addEventL ...
- h5-23-百度地图api
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name ...
- Linux下文件权限的设置
文件/目录权限设置命令:chmod 这是Linux系统管理员最常用到的命令之一,它用于改变文件或目录的访问权限.该命令有两种用法: 用包含字母和操作符表达式的文字设定法 ) 其语法格式为:chmod ...
- RHEL 6.5-----MFS
主机名 IP 安装服务 master 192.168.30.130 mfsmaster.mfsmetalogger node-1 192.168.30.131 chunkserver n ...
- js 判断客户端系统
function detectOS() { var sUserAgent = navigator.userAgent; var isWin = (navigator.platform == " ...
- void运算符
void是一元运算符,它出现在操作数之前,操作数可以是任意类型,操作数会照常计算,但忽略计算结果并返回undefined.由于void会忽略操作数的值,因此在操作数具有副作用的时候使用void来让程序 ...
- array_keys
<?php$array = array(0 => 100, "color" => "red");print_r(array_keys($arr ...
- python中的get函数
>>> a={1:'a',2:'b'}>>> print a.get(1)a>>> print a.get(3)None
- Javaweb学习笔记8—DBUtils工具包
今天来讲javaweb的第8阶段学习. DBUtils技术,DBUtils是我们操作数据库很常用的功能,虽然后期使用都是它的封装结果,但是也需要掌握. 老规矩,首先先用一张思维导图来展现今天的博客内容 ...
- iTOP-iMX6开发板Android系统下LVDS和HDMI双屏异显方法
迅为iMX6 开发板 android 系统下 LVDS 和 HDMI 双屏异显的使用过程. 注意,iTOP-iMX6 开发板的 android 系统想要实现对 LVDS 和 HDMI 双屏异显功能的支 ...