python爬虫学习,使用requests库来实现模拟登录4399小游戏网站。
1.首先分析请求,打开4399网站。
右键检查元素或者F12打开开发者工具。然后找到network选项,
这里最好勾选perserve log 选项,用来保存请求日志。这时我们来先用我们的账号密码登陆一下,然后查看一下截获的请求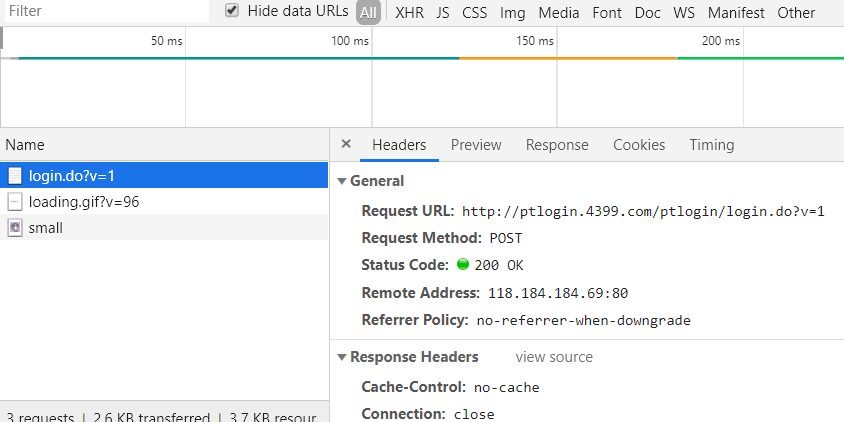
可以很清楚的看到这里有个login,而且这个请求是post请求,下拉查看一下Form data,也就是表单数据
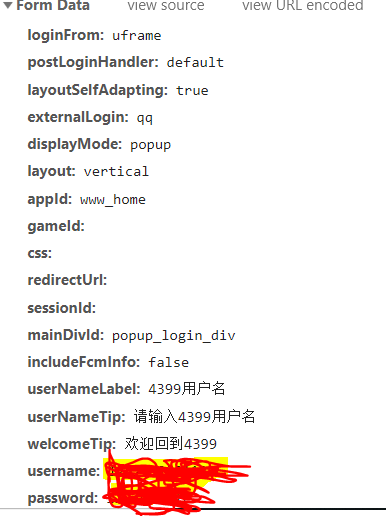
可以很清楚的看到我们的刚才登录发送给服务器的表单数据,更重要的是,除了uername和password之外,所有的数据都是一成不变的,这意味着我们不需要解析网页的源码获得信息,只需要把用户名和密码提交上去就行,下面开始构建我们的代码。
import requests
#模拟登陆4399 成功 一定要灵活运用session()这个好东西
#这是我们要提交的表单
data={
'loginFrom':'uframe',
'postLoginHandler':'default',
'layoutSelfAdapting':'true',
'externalLogin':'qq',
'displayMode':'popup',
'layout':'vertical',
'appId':'www_home',
'mainDivId':'popup_login_div',
'includeFcmInfo':'false',
'userNameLabel':'4399用户名',
'userNameTip':'请输入4399用户名',
'welcomeTip':'欢迎回到4399',
'username':'',
'password':''
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
url='http://ptlogin.4399.com/ptlogin/login.do?v=1'
session=requests.Session()
res=session.post(url=url,data=data,headers=headers)
res2=session.get(url='http://u.4399.com/user/info',headers=headers) #成功登陆以后,查看我们的用户数据
#这里把我们的请求结果保存到文件
f=open('4399.html','wb')
f.write(res2.content)
f.close()
运行起来,然后查看我们保存的html文件,
模拟登录成功! 这就是我们个人用户信息的源代码。
这个例子主要讲了requests 的post方法,用于post请求,还有很重要的session,用于维持会话,希望这个例子对大家能有所帮助,谢谢,
python爬虫学习,使用requests库来实现模拟登录4399小游戏网站。的更多相关文章
- Python爬虫学习1: Requests模块的使用
Requests函数库是学习Python爬虫必备之一, 能够帮助我们方便地爬取. Requests: 让HTTP服务人类. 本文主要参考了其官方文档. Requests具有完备的中英文文档, 能完全满 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 芝麻HTTP: Python爬虫利器之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- python爬虫之一:requests库
目录 安装requtests requests库的连接异常 HTTP协议 HTTP协议对资源的操作 requests库的7个主要方法 request方法 get方法 网络爬虫引发的问题 robots协 ...
- PYTHON 爬虫笔记三:Requests库的基本使用
知识点一:Requests的详解及其基本使用方法 什么是requests库 Requests库是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库,相比u ...
- Python爬虫的开始——requests库建立请求
接下来我将会用一段时间来更新python爬虫 网络爬虫大体可以分为三个步骤. 首先建立请求,爬取所需元素: 其次解析爬取信息,剔除无效数据: 最后将爬取信息进行保存: 今天就先来讲讲第一步,请求库re ...
- python爬虫#网络请求requests库
中文文档 http://docs.python-requests.org/zh_CN/latest/user/quickstart.html requests库 虽然Python的标准库中 urlli ...
- 【python爬虫】用requests库模拟登陆人人网
说明:以前是selenium登陆取cookie的方法比较复杂,改用这个 """ 用requests库模拟登陆人人网 """ import r ...
- 网络爬虫入门:你的第一个爬虫项目(requests库)
0.采用requests库 虽然urllib库应用也很广泛,而且作为Python自带的库无需安装,但是大部分的现在python爬虫都应用requests库来处理复杂的http请求.requests库语 ...
随机推荐
- (图论)51NOD 1264 线段相交
给出平面上两条线段的两个端点,判断这两条线段是否相交(有一个公共点或有部分重合认为相交). 如果相交,输出"Yes",否则输出"No". 输入 第1行:一个 ...
- Java 反射机制详解(上)
一.什么是反射 JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意方法和属性:这种动态获取信息以及动态调用对象方法的功能称为java ...
- java启动参数一
java启动参数共分为三类: 其一是标准参数(-),所有的JVM实现都必须实现这些参数的功能,而且向后兼容: 其二是非标准参数(-X),默认jvm实现这些参数的功能,但是并不保证所有jvm实现都满足, ...
- synchronized(2)修饰方法之:普通方法
synchronized方法 [同一个对象的该方法一次只有一个线程可以访问,该对象的其它同步方法也被阻塞] 方法声明时使用,放在范围操作符(public等)之后,返回类型声明(void等)之前.这时, ...
- ambari集群里如何正确删除历史修改记录(图文详解)
不多说,直接上干货! 答:这些你想删除的话得得去数据库里删除,最好别删除 . 现在默认就是使用好的配置 欢迎大家,加入我的微信公众号:大数据躺过的坑 人工智 ...
- sdut1650I-Keyboard(dp)
链接 题目大意就相当于 跟你一串字符串 让你截成k段 使总体的值最小 想法是递归的 递归太慢 可以转换为递推的 这样就有可以推出状态方程 dp[i][j] = max(dp[i][j],dp[i-1] ...
- .NET通过字典给类赋值
/// <summary> /// /// </summary> /// <typeparam name="T"></typeparam& ...
- SpringBoot 2.x (2):请求和传参
其实请求和传参这些知识属于SpringMVC 不过这也属于必须掌握的知识,巩固基础吧 GET请求: 以第一篇文章自动的方式创建SpringBoot项目: 然后新建Controller: package ...
- iOS 中集成百度echarts3.0
突然项目中要用到图表,所以就用了百度的echarts,然后就是网上搜了一下,由于本人的JS不是很熟悉,但是研究了一下还是做出来了,其实也不是很难 最后做的效果大概如下图这种,由于界面上没调整,所以粗糙 ...
- turn协议的工作原理
Allocate请求 客户端通过发送Allocate请求给STUN服务器,从而让STUN服务器为A用户开启一个relay端口. a) 客户端A向STUN Port发送Allocate请求(图中 ...